百度飞桨-python小白逆袭大神7天打卡营-完结心得-Rick
先说感受
前提:人是小白,刚进B站,发现飞桨,跟进学习。
回顾这7天的打卡营,学习氛围很好,在学习过程中遇到问题,随时都可以在群里向大佬们请教,助教也会及时出来给我们小白指导,给乐于助人的大佬和老师们点个赞!

打卡营的学习方式为:直播+录播+作业+答疑
在每天的中午都会放出当天要学习的课程内容与相关练习作业,每天晚上8点准时开始直播讲课,在B站搜百度飞桨就可以看到了。关键的是班主任是个声音超好听的小姐姐,直播听起来就舒服好吗,网友推荐班主任可以去当程序员鼓励师了hhhh
收获
收获按每天的课程作业来讲吧
day1 python基础
人生苦短,我选python。
既然是python小白逆袭大神营,那么第一课肯定是python啦,在第一天的课程里,班主任和我们讲述什么是人工智能,人工智能的发展趋势以及从哪入手人工智能。
当天作业为:
1.python打印9*9乘法表
2.python遍历查找特定名称文件
知识点:for循环的使用,os.walk()的使用
# os.walk()遍历出所有文件并放在三个元组里(dirpath, dirnames, filenames)
result = []
def all_path(dirname, file_name): # 输入路径名和要查找的文件名
# os.walk()遍历出所有文件并放在三个元组里(dirpath, dirnames, filenames)
#分别表示遍历的路径名,该路径下的目录列表和该路径下文件列表
for maindir, subdir, file_name_list in os.walk(dirname):
# 再遍历一遍所有文件名
for f in file_name_list:
# 把(路径名+文件名)拼接起来才是我们要的路径
apath = os.path.join(maindir, f)
# 匹配要寻找的文件re.search(要匹配的名称,被匹配的文件)
if re.search(file_name, f):
result.append(apath)
day2 《青春有你2》选手信息爬取
给小姐姐打call!!
第二天的课程内容为python爬虫实践,将爬取青春有你2选手的信息和图片,本小白只听过爬虫,从没实践过,没想到第二天就要实战了,“就像是一场梦,醒了很久还是很感动~”

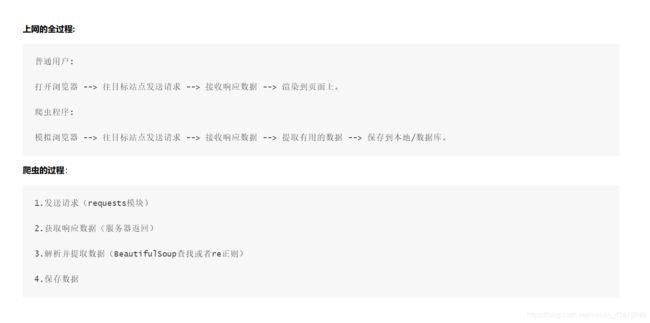
这次案例,知道了爬虫的流程,要用到的两个库:request库和BeatifulSoup库
reques库——发送请求
BeautifulSoup库——解析数据
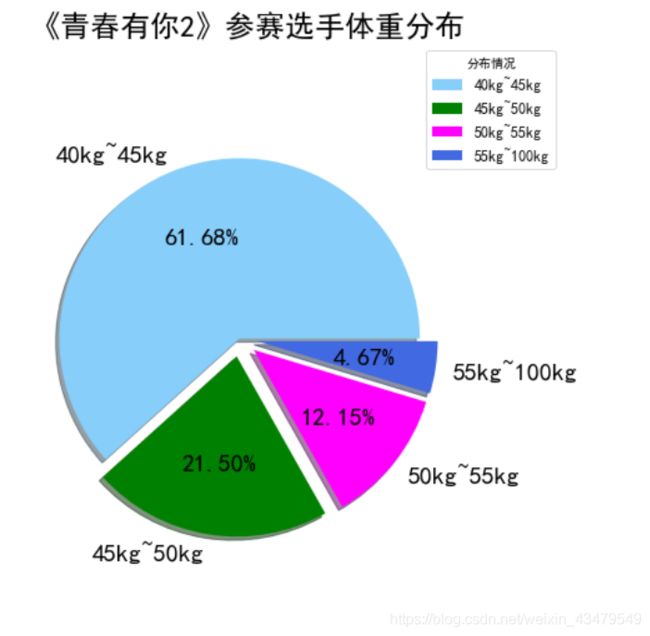
day3 《青春有你2》选手数据分析
第三天的课程内容是对昨天爬取的小姐姐数据进行分析并可视化数据。
用到matplotlib、pandas和json
最终成果如图:
day4 深度学习图像分类小姐姐
第四天的课程学习是将第二天爬取的小姐姐图片进行深度学习,并分类。
这里用到paddlehub,paddlehub是百度飞桨的工具库,里面包含了许多预训练模型,个人用户可以很方便的进行迁移学习
PaddleHub是一个深度学习模型开发工具。它基于飞桨领先的核心框架,精选效果优秀的算法,提供了百亿级大数据训练的预训练模型,方便用户不用花费大量精力从头开始训练一个模型。PaddleHub可以便捷地获取这些预训练模型,完成模型的管理和一键预测。
配合使用Fine-tune API,可以基于大规模预训练模型快速完成迁移学习,让预训练模型能更好地服务于用户特定场景的应用。
加载模型——输入数据——读取数据——训练——预测
module = hub.Module(name="resnet_v2_50_imagenet")
输入数据
from paddlehub.dataset.base_cv_dataset import BaseCVDataset
class DemoDataset(BaseCVDataset):
def __init__(self):
# 数据集存放位置
self.dataset_dir = "dataset"
super(DemoDataset, self).__init__(
base_path=self.dataset_dir,
train_list_file="train_list.txt",
validate_list_file="validate_list.txt",
test_list_file="test_list.txt",
label_list_file="label_list.txt",
)
dataset = DemoDataset()
读取数据
data_reader = hub.reader.ImageClassificationReader(
image_width=module.get_expected_image_width(),
image_height=module.get_expected_image_height(),
images_mean=module.get_pretrained_images_mean(),
images_std=module.get_pretrained_images_std(),
dataset=dataset)
配置参数(自定义)
config = hub.RunConfig(
use_cuda=False, #是否使用GPU训练,默认为False;
num_epoch=1, #Fine-tune的轮数;
checkpoint_dir="cv_finetune_turtorial_demo",#模型checkpoint保存路径, 若用户没有指定,程序会自动生成;
batch_size=10, #训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
eval_interval=1, #模型评估的间隔,默认每100个step评估一次验证集;
strategy=hub.finetune.strategy.DefaultFinetuneStrategy()) #Fine-tune优化策略;
迁移学习
input_dict, output_dict, program = module.context(trainable=True)
img = input_dict["image"]
feature_map = output_dict["feature_map"]
feed_list = [img.name]
task = hub.ImageClassifierTask(
data_reader=data_reader,
feed_list=feed_list,
feature=feature_map,
num_classes=dataset.num_labels,
config=config)
训练
run_states = task.finetune_and_eval()
预测

在这个案例中,只需要准备好要分类的图像数据,其他部分几乎不需要人工完成,几行代码即可搞定训练。
这里需要注意的是制作数据集方面,一个好的数据集对整个项目的影响十分之巨大,获取优质数据集需要花费很多精力,好的数据集+好的模型才会出好的效果!
day5 大作业
将前几天所学的知识进行结合:
1、完成爱奇艺《青春有你2》评论数据爬取:爬取任意一期正片视频下评论,评论条数不少于1000条
2、词频统计并可视化展示
3、绘制词云
4、结合PaddleHub,对评论进行内容审核
这是几天来难度最大的任务了(对小白本白来说),前几天的东西还没摸熟,今天直接来个大的。亚历山大

day6~7
最后的两天用来做作业写心得
总结
大体过程是这样的,总结一下吧,经过这几天的学习,对小白学习进步很大,通过每天的课程学习+讲解+作业,一套流程下来,小白的问题可以得到及时反馈,在摸爬滚打中对深度学习有了了解,对百度飞桨的方便程度十分惊叹,只需几行代码就可以实现一个深度学习功能,极大减少人工,使用起来十分舒心。