谷歌HDR+研读(二)
谷歌HDR+研读(一)
4对齐框架
在我们的高分辨率流水线中,对齐包括从我们突发的每个交替(非参考)帧到所选参考帧的密集对应。这种通信问题已经得到充分研究,解决方案包括光流[Horn和Schunk 1981;卢卡斯和卡纳德1981],它在光滑性和亮度恒定性假设下进行迭代优化,最近的技术使用补丁或特征描述符来构建和“密集”稀疏对应[Liu et al。 2011; Brox和Malik 2011],或者使用图像矫正和直接推理几何和遮挡[Yamaguchi et al。 2014。在计算机视觉文献中,光学流量技术主要通过建立基准的质量来评估[Baker et al。 2011; Menze和Geiger 2015]。因此,大多数技术都会生成高质量的通信信息,但是在提交时,计算成本很高,KITTI光流基准[Menze and Geiger 2015]的前5项技术需要每Mpix 1.7到107分钟在桌面环境中。
不幸的是,我们对速度,内存和功耗的严格限制几乎排除了所有这些技术。但是,由于我们的合并程序(第5节)对于小的和粗略的对齐错误都很强大,我们可以构建一个简单的算法来满足我们的要求。就像视频压缩系统一样[Wiegand et al。 2003],我们的方法旨在平衡计算成本和通信质量。我们的对齐算法在移动设备上每Mpix 24毫秒运行。我们使用类似于[Lewis 1995]的频域加速度方法以及精心的工程来实现这一性能。
参考帧选择 为了解决由手和场景运动引起的模糊,根据基于原始输入的绿色通道中的梯度的简单度量,我们选择参考帧为突发子集中最锐利的帧。这遵循被称为幸运成像的一般策略[Joshi and Cohen 2010]。为了最小化感知的快门时滞,我们从脉冲串的前3帧中选择参考帧。
处理原始图像 因为我们的输入包含拜耳原始图像,所以对齐会带来特殊的挑战。原始图像的四个颜色平面欠采样,使对齐成为不适合的问题。尽管我们可以对输入进行去马赛克,以估计每个像素的RGB值,但即使在所有突发帧上使用低质量的去马赛克,运行起来也会非常昂贵。我们通过估计位移只能达到2个像素的倍数来绕过这个问题。受此约束的位移具有取代拜耳样品具有重合颜色的便利特性。实际上,我们的方法将欠采样问题推迟到我们的合并阶段,其中由于混叠而引起的图像不匹配被视为与任何其他形式的未对齐相同。我们通过平均2×2块Bayer RGGB样本来实施该策略,以便我们调整降采样的3 Mpix灰度图像而不是12 Mpix原始图像。
分层对齐 为了将替代帧与我们的参考帧对齐,我们在下采样到灰色原始输入的四级高斯金字塔上执行从粗到精的对齐。如图5所示,我们使用来自较粗糙比例的对齐作为初始猜测,为每个金字塔等级生成基于图块的对齐。每个参考图块的对齐方式是最小化以下距离度量的偏移量,以将其与备用图像中的候选图块相关联:
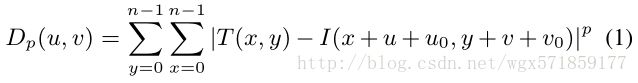
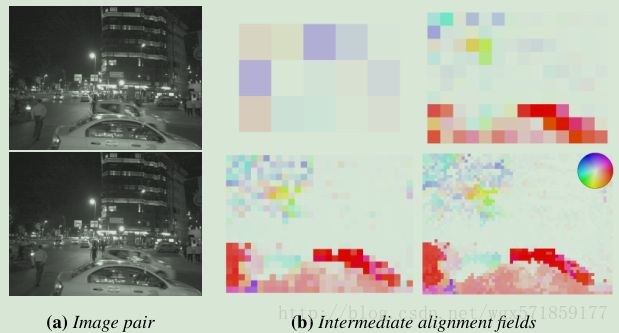
图5:(a)一对3 Mpix灰度图像。 (b)我们多尺度对齐的中间和最终输出,色调和饱和度表示位移的方向和大小(见插图色环)。 在最好的金字塔级别(右下角),图块为32×32像素,最大位移为64像素。 饱和颜色的大区域表明分层算法是必不可少的; 我们的方法支持高达169像素的位移。 尽管我们的位移包含错误,但它们便于计算并且足够准确,可用作我们合并阶段的输入。
在我们的方法中,我们对等式1中的抽取,色块大小,搜索半径以及标准的选择做出了许多启发式决策。一个关键决定是根据金字塔尺度进行不同的对齐。特别是,在粗尺度下,我们计算子像素对齐,最小化L2残差,并使用大的搜索半径。亚像素对齐在粗尺度上是有价值的,因为它增加了初始化的准确性并允许积极的金字塔决定。在我们金字塔最好的规模下,我们改为计算像素级别的对齐,最小化L1残差,并将自己限制在一个小的搜索范围内。这里只需要像素级对齐,因为我们当前的合并过程不能使用子像素对齐。更详细的解释这些决定,再加上描述如何用暴力实施快速计算D1,可以在补充中找到。
4.1快速子像素L2对齐
在粗尺度下,因为我们使用更大的搜索半径,所以只计算方程1将会非常昂贵。我们用算法技术解决这个问题,以更有效地计算D2。类似于可以加速归一化互相关的方式[Lewis 1995],方程1的L2版本可以用盒式滤波器和卷积来计算:
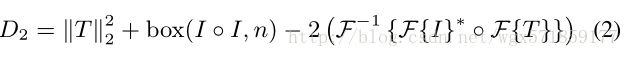
计算出D2后,识别最小化位移误差的整数位移(u,v)是便宜的。为了产生运动的亚像素估计,我们将一个二元多项式拟合到(u,v)周围的3×3窗口,并找出该多项式的最小值。这改善了拟合两个可分离函数的标准方法[Stone et al。通过避免假设运动独立地受限于各自的轴。在形式上,我们近似于:
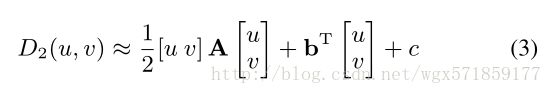
c是标量。我们构造一个加权最小二乘问题
将多项式拟合到以(u,v)为中心的D2的3×3补丁。求解这个系统相当于把D2的内积乘以一组6个3×3滤波器,这些滤波器是在补充中导出的,每个滤波器对应于(A,b,c)中的一个自由参数。该过程类似于[Farneba¨ck2002]的多项式展开法。一旦我们恢复了二次方的参数,它的最小值通过完成平方来完成:

向量μ表示必须添加到我们的整数位移(u,v)中的子像素转换。
5合并帧
连拍摄影的关键前提是我们可以通过结合随着时间的多个场景观察来实现降噪。但是,为了在摄影应用中有用,我们的合并方法必须对齐失败时很有用。如图6所示,虽然对齐对于帮助补偿相机和物体运动很重要,但我们不能单独依靠对齐,这可能会由于各种原因(例如遮挡,非刚性运动或照明变化)而失败。
考虑到我们的性能目标,我们开发了一种合并方法,该方法基于对输入切片进行操作的成对频域时间滤波器,可以对未对齐进行强健的处理。在我们的设置中,引用中的每个图块都与从每个替换帧中获取的一个图块合并,对应于我们的对齐结果。我们的方法通常使用来自Bayer原始输入颜色平面的16×16瓦片,但对于非常黑暗的场景,低频噪声可能令人反感,我们使用32×32瓦片代替。
我们的方法从频域视频消噪技术中获得灵感,这些技术可以在3D叠加匹配图像补丁上运行[Kokaram 1993; Bennett和McMillan 2005; Dabov等人2007年a]。特别是Kokaram [1993]提出了一个经典的变体在3D DFT域进行维纳滤波,衰减较小的系数更可能是噪声。 V-BM3D [Dabov et al。 2007a]采用了类似的方法,将维纳滤波器和类似运算符重新解释为有利于稀疏性的“收缩”运算符,该稀疏性是变换域中自然图像的统计特性。该系列的技术对未对准很有效,因为对于给定的空间频率,任何不能归因于预期噪声水平的参考失配都将被抑制。
最近的傅里叶连拍累积方法[Delbracio和Sapiro 2015]使用类似的原理,但是在整个连拍中结合频率内容更积极,以减少由于长时间曝光造成的运动模糊。在极端情况下,这种方法包括在突发中获取每个空间频率的最大值。我们认为保留参考框架的运动模糊作为摄影的一个有用特征。而且,我们将曝光不足和幸运成像组合在一起使不必要的运动模糊变得不那么常见。
虽然我们的合并方法继承了频域去噪的好处,但它以几种方式偏离了以前的方法。首先,因为我们处理原始图像,所以我们有一个简单的模型来描述图像中的噪点。这通过让我们更可靠地区分对齐失败和噪声来提高鲁棒性。其次,我们不是在时间维上应用DFT或其他正交变换,而是使用更简单的成对过滤器,将每个替代帧独立地合并到参考帧上。虽然这种方法为良好对齐的图像牺牲了一些降噪功能,但通过对齐失败来计算和降级会更便宜(参见图7)。第三,由于该滤波器仅在时间维上运行,我们在单独的后处理步骤中运行空间去噪,应用于2D DFT。第四,我们将滤镜独立应用于拜耳原始图像的颜色平面,然后将滤波后的结果重新解释为新的拜耳图像。这种方法虽然简单但却令人惊讶,但即使我们忽略拜耳解样采样,也几乎没有退化。在下文中,我们将详细介绍这些要点并讨论可能导致极端情况的工件。
噪声模型和平铺近似 因为我们使用拜耳原始数据,所以噪声对于每个像素都是独立的,并且采用简单的,与信号相关的形式。特别是,对于x的信号电平,噪声方差σ可以表示为Ax + B,接着是光子计数的泊松分布物理过程[Healey和Kondepudy 1994]。参数A和B仅取决于我们直接控制的镜头的模拟和数字增益设置。为了验证这种传感器噪声模型,我们凭经验测量了噪声如何随着不同的信号电平和增益设置而变化。
在应用我们滤波的变换域中,直接使用信号相关模型的噪声是不切实际的,因为DFT需要表示完整的协方差矩阵。尽管可以通过对输入应用方差稳定变换来解决这个问题[Majekitalo and Foi 2013],但为了提高计算效率,我们将噪声逼近为给定图块内的独立信号。对于每个图块,我们通过使用单个值(即图块中样本的均方根(RMS))评估我们的噪声模型来计算方差。使用RMS可将信号估计值偏向较亮的图像内容。对于低对比度瓷砖,这与使用平均值相似;高对比度瓷砖将被更积极地过滤,就好像它们具有更高的平均信号电平。
强大的成对时间合并 我们的合并方法在空间频率域上的图像瓦片上运行。 对于一个给定的参考瓦片,我们在该脉冲串上组装一组相应的瓦片,每帧一个,并且计算它们各自的2D DFT作为Tz(ω),其中ω=(ωx,ωy)表示空间频率,z是帧索引 ,并且在不失一般性的情况下,我们以0帧为参考。
如果我们的方法与其他基于频率的去噪方法不同,则我们在时间维度上对帧进行配对处理。 为了建立直觉,在时间维度上合并的简单方法是计算每个频率系数的平均值。 这种天真的平均滤波器可以被认为是表达对去噪参考帧的估计:
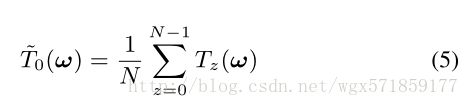
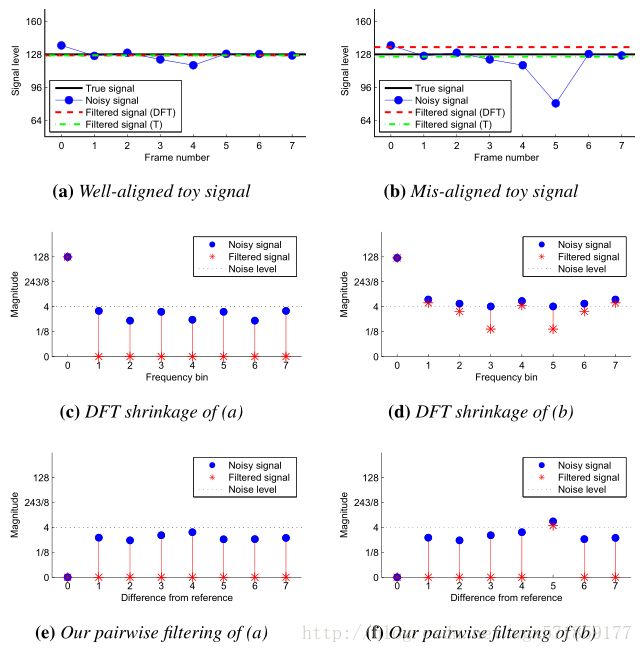
虽然这在对齐成功的情况下表现良好,但对于对齐失败并不稳健(参见图6c)。 由于2D DFT是线性的,因此该滤波器实际上等同于空间域中的时间平均值。
为了增加鲁棒性,我们改为构造类似于等式5的表达式,但是包含了一个滤波器,可以让我们控制交替帧的贡献:
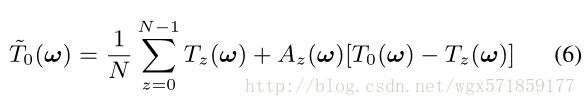
对于给定的频率,Az控制我们将交替帧z合并到最终结果与返回参考帧的程度。 这个总和的主体可以被重写为(1-Az)•Tz + Az•T0 以强调Az在Tz和T0之间控制线性。 由于每个替代帧的贡献是基于每个频率进行调整的,所以对齐失败可能是部分的,因为一个空间频率的被拒绝图像内容不会破坏其他频率。
我们现在剩下的任务是定义Az以衰减与参考不匹配的频率系数。 特别是,当Tz与T0的差异归因于噪声时,我们希望Tz对合并结果作出贡献,当Tz由于对齐不良或其他问题而不同于T0时,Tz的贡献将被抑制。 换句话说,Az是一个缩小操作符。 我们对Az的定义是经典Wiener滤波器的变体:
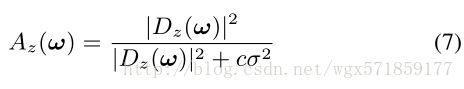
其中Dz(ω)= T0(ω)-Tz(ω),噪声方差σ2由我们的噪声模型提供,并且c是考虑到Dz构造中的噪声方差的缩放的常数并且包括进一步的调谐 因素(在我们的实施中,固定为8)增加了噪声降低,但以一些鲁棒性为代价。 Dz的构造将2D DFT样本的数量的噪声方差缩放n倍,对于窗函数(稍后描述)为1/42的因子,并且将其定义为2的因子作为两个瓦片的差异。 我们尝试了几种可选的缩小算子,如硬阈值和软阈值[Donoho 1995],并且发现这种滤波器可以在降噪强度和视觉伪像之间提供最佳平衡。
我们发现我们的成对时间算子产生比完整3D DFT更高质量的图像,特别是在对齐失败的情况下。 如图7所示,单个不良对齐的框架使整个DFT变换域非稀疏,导致收缩算子拒绝来自所有交替帧的贡献,而不是仅差对齐的贡献。 相比之下,我们的临时操作员独立评估每个替代帧的贡献,让我们在对齐失败时更优雅地降级。 我们的时态滤波还具有计算更便宜并且需要更少内存的优点。 在进行下一步之前,可以计算并丢弃每个替代帧的贡献。
合并拜耳原料。请注意,到目前为止,我们已经按照单通道图像展示了我们的合并算法。但是,如上所述,我们的输入和输出都包含拜耳镶嵌原始图像。我们的设计以最简单的方式处理原始图像:我们使用常见的局部平移对齐方式独立合并Bayer图像的每个平面,并且我们不使用拜耳平面中比像素级更精确的对齐方式。调整到更高的精度将需要对齐和合并的插值,这将显着增加计算成本。虽然我们的方法是快速有效的,但它不如多帧去马赛克算法(例如[Farsiu et al.2006])复杂,旨在恢复丢失拜耳欠采样的高频内容。
由于拜耳色彩平面欠采样4倍,人们可能悲观地认为75%的帧会被平均拒绝,从而影响去噪。虽然我们的鲁棒滤波器确实会拒绝不符合我们的噪声模型的锯齿图像内容,但这种拒绝只发生在每个DFT bin的基础上,并且混叠问题可能局限于DFT bin的子集。在图6中可以观察到相同的行为,尽管对齐不良(图6c,底部),但我们的鲁棒时间滤波器能够在不引入任何可见重影的情况下显着降低噪声(图6d,底部)。
重叠瓷砖 我们的合并方法在每个空间维度上重叠一半的瓷砖上进行操作。通过在重叠的瓷砖之间平滑地混合,我们避免了在瓷砖边界处的视觉上令人讨厌的不连续性。此外,我们必须将窗函数应用于切片,以避免在DFT域中操作时出现边缘伪影。对于0≤x 伪影。我们观察到由这个系统产生的几类伪影。首先,如图8所示,该滤波器往往无法抑制强烈高对比度特征周围的噪声。这是高对比度特征在空间DFT域中具有非稀疏表示的结果,降低了空间去噪的有效性。
其次,因为我们的缩放功能从未完全拒绝对齐不良的瓷砖,所以有时会出现轻微的重影伪影,如图9所示。根据我们的经验,这些重影伪影很微妙,并且很难与运动模糊区分开来。
最后,我们的滤波器偶尔会产生通常与频域滤波器相关的振铃伪影。虽然振铃通过我们的窗口化方法大大缓解,但在具有挑战性的情况下,特别是在通过精加工管道中的锐化和其他步骤进行放大之后,可以看到分类吉布斯现象。在邻近的低对齐的剪辑高光区域中,最常见的是铃声,这些高光显示出高时空对比度。根据我们的经验,响铃对大多数场景的视觉效果可以忽略不计。