【量化笔记】Markowitz模型的python实现
Markowitz模型是关于如何选择最佳的投资组合比例的模型
Markowitz模型的数学推导见:https://blog.csdn.net/yao09605/article/details/96318367
下面写下python实现:
选取的五只股票分别是:
600004 白云机场
600015 华夏银行
600023 浙能电力
600033 福建告诉
600183 生益科技
数据可以使用tushare包获得,这里我使用的是本地保存下来的数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
stock = pd.read_table('stock.txt',sep='\t', index_col = 'Trddt')
fjgs = stock.loc[stock.Stkcd==600033,'Dretwd']
fjgs.name = 'fjgs'
zndl = stock.loc[stock.Stkcd==600023,'Dretwd']
zndl.name = 'zndl'
sykj = stock.loc[stock.Stkcd==600183,'Dretwd']
sykj.name = 'sykj'
hxyh = stock.loc[stock.Stkcd==600015,'Dretwd']
hxyh.name = 'hxyh'
byjc = stock.loc[stock.Stkcd==600004,'Dretwd']
byjc.name = 'byjc'
sh_return = pd.concat([byjc,fjgs,hxyh,sykj,zndl], axis=1)
# 累计回报率
sh_return = sh_return.dropna()
cumreturn = (1+sh_return).cumprod()
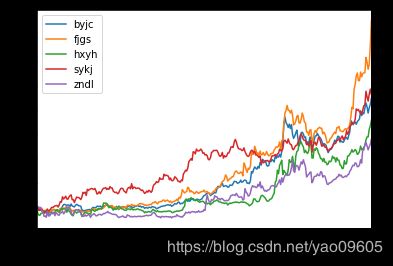
# 5只股票日收益图
sh_return.plot()
plt.title('Daily return of 5 stocks)2015-2015')
plt.legend(loc='lower center', bbox_to_anchor = (0.5,-0.3),
ncol = 5,fancybox=True, shadow=True)

# 累计收益图
cumreturn.plot()
计算最优资产比例并绘制最小方差前缘曲线
# 计算最优资产比例并绘制最小方差前缘曲线
# class MeanVariance
from scipy import linalg
class MeanVariance:
def __init__(self, returns):
self.returns = returns
#定义最小化方差的函数,求解二次规划
def minVar(self, goalRet):
covs = np.array(self.returns.cov())
means = np.array(self.returns.mean())
L1 = np.append(np.append(covs.swapaxes(0,1),[means],0),
[np.ones(len(means))],0).swapaxes(0,1)
L2 = list(np.ones(len(means)))
L2.extend([0,0])
L3 = list(means)
L3.extend([0,0])
L4 = np.array([L2,L3])
L = np.append(L1,L4,0)
results = linalg.solve(L,np.append(np.zeros(len(means)),[1,goalRet],0))
return (np.array([list(self.returns.columns), results[:-2]]))
# 定义绘制最小方差曲线函数
def frontierCurve(self):
goals = [x/500000 for x in range(-100, 4000)]
variances = list(map(lambda x: self.calVar(self.minVar(x)[1,:].astype(np.float)),goals))
plt.plot(variances, goals)
#给定个资产的比例,计算收益率均值
def meanRet(self, fracs):
meanRisky = ffn.to_returns(self.returns).mean()
assert len(meanRisky) == len(fracs), 'Length of fractions must be equal to nuber of assets'
return(np.sum(np.multiply(meanRisky, np.array(fracs))))
#给定各资产的比例,计算收益率方差
def calVar(self, fracs):
return (np.dot(np.dot(fracs, self.returns.cov()), fracs))
minVar = MeanVariance(sh_return)
minVar.frontierCurve()
横坐标是方差(风险),纵坐标是日收益率,这个可以帮助计算在期望收益率下能达到的最下方差,以及组合比例

下面以2014年的数据作为训练集,2015年的数据作为验证集,验证使用markowitz模型计算出的最佳投资组合与随机选择的100组投资组合之间的累计收益对比
train_set = sh_return[sh_return.index.str.contains('2014')]
test_set = sh_return[sh_return.index.str.contains('2015')]
#选取组合
varMinimizer = MeanVariance(train_set)
# 期望的日收益率
goal_return = 0.003
portfolio_weight = varMinimizer.minVar(goal_return)
# 计算出来的最佳投资组合
portfolio_weight
'''
array([['byjc', 'fjgs', 'hxyh', 'sykj', 'zndl'],
['-0.10970733137288002', '0.8121632841002376',
'0.34747305363072145', '0.4301821962925987',
'-0.4801112026506778']], dtype='
# 计算测试集收益率
test_return = np.dot(test_set, np.array([portfolio_weight[1,:].astype(np.float)]).swapaxes(0,1))
test_return = pd.DataFrame(test_return, index = test_set.index)
#累计收益率
test_cum_return = (1+test_return).cumprod()
# 与随机生成的组合进行比较
# 随机生成100组5个股票的随机组合
sim_weight = np.random.uniform(0,1,(100,5))
sim_weight = np.apply_along_axis(lambda x:x/sum(x), 1, sim_weight)
sim_return = np.dot(test_set, sim_weight.swapaxes(0,1))
sim_return = pd.DataFrame(sim_return, index=test_cum_return.index)
#随机选择的100中组合的累计收益率
sim_cum_return = (1+sim_return).cumprod()
#作图
plt.plot(sim_cum_return.index, sim_cum_return, color='green')
plt.plot(test_cum_return.index, test_cum_return)
可以看到随着时间的累计,没有随机的投资组合最后能超过计算出来的市场投资组合。
但由于我们是以历史数据为依据进行推断,所以无法规避公司业绩下降等其他因素的影响!
股市有风险,入市续谨慎
