ndarray的拼接方法,np.stack和np.vstack,np.hstack,np.concatenate
np.stack
在numpy中的数组拼接方法,常见的有以下几个np.stack和np.vstack,np.hstack,np.concatenate,其中np.stack可能是最不好理解的理解的那一个,那么就先来看看它.
np.stack的作用是沿新轴加入一系列数组,这句话有两个重点,
一是沿新轴,而这个新轴是哪个轴,需要我们自行指定,不指定的话默认是最里边的轴.
二是加入数组,所以,运用这个方法的时候,新生成的数组时会比用来进行拼接的原数组多一个维度.
举个例子:
import numpy as np #导入numpy库
生成两个数组
arr1 = np.arange(10).reshape(2,5)
arr2 = np.arange(10,20).reshape(2,5)
arr1
arr2
返回结果
array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]])
array([[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]])
用np.stack进行拼接的结果直接截图展示一下,不是我偷懒不想再敲一遍代码,而是截图更直观一点:

ndarray的一个难点恐怕就是数它的轴了,我在图中标注出了哪些是外边的轴,哪些是第二个轴,哪些是最里边的轴,有一个比较简单的方法来判断这些轴,就是观察一下方括号,方括号数量越多的轴,越是在外层的轴,在这个例子中,最外侧的轴有两层方括号,从外边数第二个轴有一层方括号,这里还好一点,最难理解的是最里边的轴,最后来看一下最内侧的轴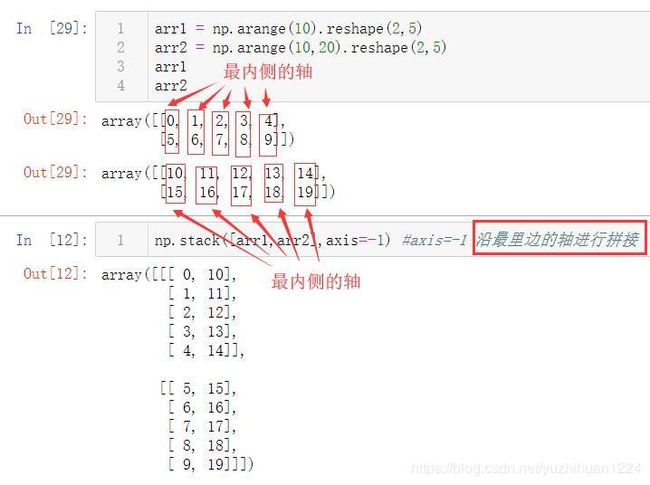
到了最内侧的轴,已经没有方括号包裹着了,赤裸裸的元素本身,最内侧的0和5是一个轴,10和15是一个轴,按轴拼接,就是0和10拼到一起,5和15拼到一起.
以上是我对np.stack方法和ndarray轴的理解,如有错误还请指正.大boss解决掉了,我们来看一下小虾米们
np.vstack,np.hstack,np.concatenate
虽然vstack和hstack这两个词里边都含有stack,但是呢很奇怪的是他俩的性质和stack一点都不像,看起来倒是和concatenate更亲近一点,这三个拼接方法,都不会增加拼接后新生成数组的维度
vstack:垂直堆栈数组(行方式)
hstack:水平排列数组(列方式)
concatenate:沿现有轴加入一系列数组,至于是想按行拼接还是按列拼接,可自行进行参数设置
这里我真的是想偷个懒直接上截图了,靴靴

这三个方法的拼接效果是不是直观又明显,一点都不费脑子.