Flink on Yarn部署
1.Flink 编译
这部分官方文档已经描述的很清楚,先下载源代码,再进行编译,直接下载二进制的不一定能符合你的需求。
git clone https://github.com/apache/flink
mvn clean install -DskipTests -Pvendor-repos -Dhadoop.version=2.6.0-cdh5.10.2等待大概20分钟左右,编译完成会有一个新目录build-target ,那就是生成的二进制包。
build-target flink-core flink-fs-tests flink-queryable-state flink-shaded-hadoop flink-yarn pom.xml
docs flink-dist flink-java flink-quickstart flink-state-backends flink-yarn-tests README.md
flink-annotations flink-docs flink-jepsen flink-runtime flink-streaming-java LICENSE target
flink-clients flink-end-to-end-tests flink-libraries flink-runtime-web flink-streaming-scala licenses tools
flink-connectors flink-examples flink-mesos flink-scala flink-table licenses-binary
flink-container flink-filesystems flink-metrics flink-scala-shell flink-tests NOTICE
flink-contrib flink-formats flink-optimizer flink-shaded-curator flink-test-utils-parent NOTICE-binary2. Flink on yarn部署
1)修改好配置文件,其他的master, slaves实际上不需要配置,没有意义了,job manager是由yarn随机选取一台机器来启动application master获得的,也就是说,所有的node manager都有可能是job manage。 我特意试过yarn.appmaster.rpc.address 这个参数,以为可以指定application master启动的地址,从实际情况来看,不生效。
jobmanager.rpc.address: 10.40.2.93
jobmanager.rpc.port: 6123
jobmanager.heap.size: 1024m
#web.tmpdir: hdfs:///tsczbdnndev1.trinasolar.com:8020/flink/flink-web
web.upload.dir: /data/flink/flink-web
taskmanager.heap.size: 8192m
taskmanager.numberOfTaskSlots: 8
parallelism.default: 2
#fs.default-scheme: hdfs://tsczbdnndev1.trinasolar.com:8020
high-availability: zookeeper
high-availability.storageDir: hdfs:///flink/ha/
high-availability.zookeeper.quorum: 10.40.2.94:2181,10.40.2.95:2181,10.40.2.96:2181
high-availability.cluster-id: /default_ns
# high-availability.zookeeper.client.acl: open
high-availability.jobmanager.port: 50030
state.backend: filesystem
state.checkpoints.dir: hdfs:///flink/checkpoints
state.savepoints.dir: hdfs:///flink/savepoints
state.backend.incremental: true
#web.address: 0.0.0.0
rest.port: 8082
web.submit.enable: true
web.timeout: 20000
# io.tmp.dirs: /tmp
taskmanager.memory.preallocate: true
# classloader.resolve-order: child-first
taskmanager.network.memory.fraction: 0.1
taskmanager.network.memory.min: 64mb
taskmanager.network.memory.max: 4gb
security.kerberos.login.use-ticket-cache: true
security.kerberos.login.keytab: /tmp/flink.keytab
security.kerberos.login.principal: [email protected]
#high-availability.zookeeper.client.acl: creator
#security.kerberos.login.contexts: Client,KafkaClient
jobmanager.archive.fs.dir: hdfs:///flink/completed-jobs/
historyserver.web.address: 0.0.0.0
historyserver.web.port: 8083
historyserver.archive.fs.dir: hdfs:///flink/completed-jobs/
historyserver.archive.fs.refresh-interval: 10000
#yarn.appmaster.rpc.address: tsczbddndev2.trinasolar.com
yarn.maximum-failed-containers: 99999
yarn.reallocate-failed: true
yarn.application-attempts: 10
fs.overwrite-files: true
fs.output.always-create-directory: true2) 拷贝Flink包到所有Yarn 服务器上,包括RM和AM即可,所有包的用户及组建议保持一致,以免莫名出错。比如:
Caused by: java.nio.file.AccessDeniedException: /data/flink
at sun.nio.fs.UnixException.translateToIOException(UnixException.java:84)
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:102)
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:107)
at sun.nio.fs.UnixFileSystemProvider.createDirectory(UnixFileSystemProvider.java:384)
at java.nio.file.Files.createDirectory(Files.java:674)
at java.nio.file.Files.createAndCheckIsDirectory(Files.java:781)
at java.nio.file.Files.createDirectories(Files.java:767)
at org.apache.flink.runtime.rest.RestServerEndpoint.checkAndCreateUploadDir(RestServerEndpoint.java:440)
at org.apache.flink.runtime.rest.RestServerEndpoint.createUploadDir(RestServerEndpoint.java:424)
at org.apache.flink.runtime.rest.RestServerEndpoint.(RestServerEndpoint.java:105)
at org.apache.flink.runtime.webmonitor.WebMonitorEndpoint.(WebMonitorEndpoint.java:181)
at org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint.(DispatcherRestEndpoint.java:67)
at org.apache.flink.runtime.rest.SessionRestEndpointFactory.createRestEndpoint(SessionRestEndpointFactory.java:54)
at org.apache.flink.runtime.entrypoint.component.AbstractDispatcherResourceManagerComponentFactory.create(AbstractDispatcherResourceManagerComponentFactory.java:131)
... 9 more 上面错误就是说找不到/data/flink, 这是因为我故意测试不拷贝包到这台机器,一旦启动job Manager到这台机器,就肯定报错了。
3)随便选取一台机器,我一般习惯在RM上启动yarn-session.sh
./bin/yarn-session.sh -n 10 -tm 1024 -s 4 -nm FlinkOnYarnSession -d4)查看job manager地址,上面提过,application master实际就是job manager,所以我们只要从yarn web ui 找到flink的application master即可,然后点击日志进去,就可以看到实际的地址,如下就是job manager.
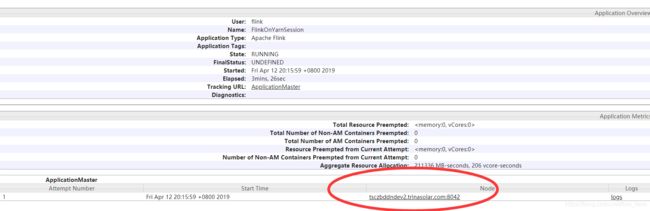
3. Flink on yarn有2种部署模式:
1) yarn-session.sh启动后台进程, 这种方式会在YARN启动一个application master,实际上这就是job manager, 原文如下:
The example invocation starts a single container for the ApplicationMaster which runs the Job Manager.
The session cluster will automatically allocate additional containers which run the Task Managers when jobs are submitted to the cluster从上文的意思,task manager是等你提交JOB的时候再启动。提交一个JOB试试:
[root@tsczbddndev2 flink]# bin/flink run examples/batch/WebLogAnalysis.jar
Setting HADOOP_CONF_DIR=/etc/hadoop/conf because no HADOOP_CONF_DIR was set.
2019-04-12 20:43:46,938 INFO org.apache.hadoop.security.UserGroupInformation - Login successful for user [email protected] using keytab file /tmp/flink.keytab
2019-04-12 20:43:47,353 WARN org.apache.hadoop.hdfs.shortcircuit.DomainSocketFactory - The short-circuit local reads feature cannot be used because libhadoop cannot be loaded.
Starting execution of program
Executing WebLogAnalysis example with default documents data set.
Use --documents to specify file input.
Executing WebLogAnalysis example with default ranks data set.
Use --ranks to specify file input.
Executing WebLogAnalysis example with default visits data set.
Use --visits to specify file input.
Printing result to stdout. Use --output to specify output path.
(69,url_16,34)
(41,url_39,33)
(48,url_46,37)
Program execution finished
Job with JobID 521cdff64adbe2ed106d0f9a187cf854 has finished.
Job Runtime: 131 ms
Accumulator Results:
- efce599938bf3248fed5bc5f102df9c6 (java.util.ArrayList) [3 elements]2)single job mode
这种模式在你提交JOB的时候再去申请资源,可以理解每个JOB都有自己的job manager, task manager,,一旦JOB完成,进程也就退出了,不会占用任何资源了。
./bin/flink run -m yarn-cluster ./examples/batch/WordCount.jar与yarn-session不同的是,需要指定 -m yarn-cluster。如下图,我们实际已经有了yarn-session后台进程,但是通过single job提交方式会生成一个新的application master

4. Flink on Yarn HA
Maximum Application Master Attempts (yarn-site.xml)
You have to configure the maximum number of attempts for the application masters for your YARN setup in yarn-site.xml:
yarn.resourcemanager.am.max-attempts
4
The maximum number of application master execution attempts.
The default for current YARN versions is 2 (meaning a single JobManager failure is tolerated).上面使用you have to configure已经表明,要启用HA必须修改这个参数,我试过保留默认值2,去切换 job manager,发现无法成功,具体原因暂时不清楚。
下面我们来试试切换HA:
1)先检查当前job manager的地址,按照上述办法去 yarn web ui查看application master地址,并kill -9 11393,
[root@tsczbddndev2 flink]# jps
11393 YarnSessionClusterEntrypoint
28034
28434
20499 -- process information unavailable
13284 Jps
31124 PrestoServer
1509 NodeManager
6375 AzkabanExecutorServer
27880 QuorumPeerMain
30635 Bootstrap2)检查新的application master地址

从上面的红圈来看,重新启动了一个job manager,地址也换了,通过OS命令确认,4082进程就是新的 job manager:
[root@tsczbddndev3 ~]# jps
4082 Bootstrap
5122 YarnSessionClusterEntrypoint
27283 -- process information unavailable
5397 Jps
27096 -- process information unavailable
11288 -- process information unavailable
19049 -- process information unavailable
30809 QuorumPeerMain
31387
2268 PrestoServer
30988
24349 NodeManager