jupyter-notebook 以yarn模式运行出现的问题及解决
jupyter-notebook 以yarn模式运行的出现的问题及解决方法
之前用pyspark虚拟机只跑了单机程序,现在想试试分布式运算。
在做之前找了书和博客来看,总是有各种各样的问题,无法成功。现在特记录一下过程:
这里一共有两个虚拟机,一个做master,一个做slave1
- 虚拟机slave1安装spark
slave1之前已经安装了hadoop,并且可以成功进行Hadoop集群运算。这里就不多说了。
将master的spark安装包复制到slave1,
(1)进入到spark/conf文件夹中,将slaves.template复制成slaves,在里面添加slave1

(2)增加路径到/etc/profile
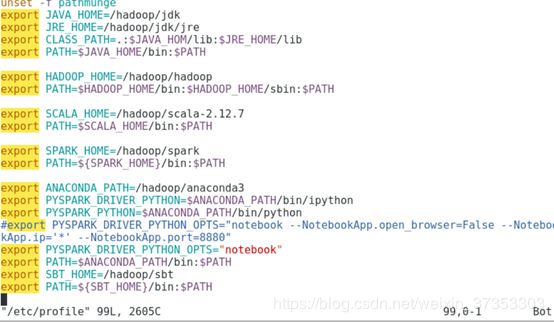
master与slave1都要做(1),(2)的步骤
-
slave1安装anaconda
可以用scp直接将master的anaconda复制过来,接下来修改/etc/profile就可。上面的图已经显示了修改的内容 -
启动,这时候遇到了好多问题
在master终端输入start-all.sh,使用jps查看,master和slave1都能正常启动
在master终端输入
HADOOP_CONF_DIR=/hadoop/hadoop/etc/hadoop PYSPARK_DRIVER_PYTHON="jupyter" PYSPARK_DRIVER_PYTHON_OPTS="notebook" MASTER=yarn-client pyspark
看资料说,如果没有在spark.env.sh中配置HADOOP_CONF_DIR,需要像上面代码在终端写出。这时候,jupyter-notebook可以成功启动,但是我在其中写入sc.master看它是何种模式运行时,却给我报了好多错误
[root@master home]#HADOOP_CONF_IR=/hadoop/hadoop/etc/hadoop PYSPARK_DRIVER_PYTHON="jupyter"
PYSPARK_DRIVER_PYTHON_OPTS="notebook" pyspark
[I 18:58:24.475 NotebookApp]
[nb_conda_kernels] enabled, 2 kernels found
[I 18:58:25.101 NotebookApp] ✓ nbpresent HTML export ENABLED
[W 18:58:25.101 NotebookApp] ✗ nbpresent PDF export DISABLED: No module named 'nbbrowserpdf'
[I 18:58:25.163 NotebookApp]
[nb_anacondacloud] enabled
[I 18:58:25.167 NotebookApp] [nb_conda] enabled
[I 18:58:25.167 NotebookApp] Serving
notebooks from local directory: /home
[I 18:58:25.167 NotebookApp] 0 active
kernels
[I 18:58:25.168 NotebookApp] The Jupyter
Notebook is running at: http://localhost:8888/
[I 18:58:25.168 NotebookApp] Use Control-C
to stop this server and shut down all kernels (twice to skip confirmation).
[I 18:58:33.844 NotebookApp] Kernel
started: c15aabde-b441-45f2-b78d-9933e6534c27
Exception in thread "main"
java.lang.Exception: When running with master 'yarn-client' either
HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the environment.
at
org.apache.spark.deploy.SparkSubmitArguments.validateSubmitArguments(SparkSubmitArguments.scala:263)
at
org.apache.spark.deploy.SparkSubmitArguments.validateArguments(SparkSubmitArguments.scala:240)
at
org.apache.spark.deploy.SparkSubmitArguments.(SparkSubmitArguments.scala:116)
at
org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:112)
at
org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
[IPKernelApp] WARNING | Unknown error in
handling PYTHONSTARTUP file /hadoop/spark/python/pyspark/shell.py:
[I 19:00:33.829 NotebookApp] Saving file at
/Untitled2.ipynb
[I 19:00:57.754 NotebookApp] Creating new
notebook in
[I 19:00:59.174 NotebookApp] Kernel
started: ebfbdfd5-2343-4149-9fef-28877967d6c6
Exception in thread "main"
java.lang.Exception: When running with master 'yarn-client' either
HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the environment.
at
org.apache.spark.deploy.SparkSubmitArguments.validateSubmitArguments(SparkSubmitArguments.scala:263)
at
org.apache.spark.deploy.SparkSubmitArguments.validateArguments(SparkSubmitArguments.scala:240)
at
org.apache.spark.deploy.SparkSubmitArguments.(SparkSubmitArguments.scala:116)
at
org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:112)
at
org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
[IPKernelApp] WARNING | Unknown error in
handling PYTHONSTARTUP file /hadoop/spark/python/pyspark/shell.py:
[I 19:01:12.315 NotebookApp] Saving file at
/Untitled3.ipynb
^C[I 19:01:15.971 NotebookApp] interrupted
Serving notebooks from local directory:
/home
2 active kernels
The Jupyter Notebook is running at:
http://localhost:8888/
Shutdown this notebook server (y/[n])? y
[C 19:01:17.674 NotebookApp] Shutdown
confirmed
[I 19:01:17.675 NotebookApp] Shutting down
kernels
[I 19:01:18.189 NotebookApp] Kernel
shutdown: ebfbdfd5-2343-4149-9fef-28877967d6c6
[I 19:01:18.190 NotebookApp] Kernel
shutdown: c15aabde-b441-45f2-b78d-9933e6534c27
通过日志显示:
Exception in thread "main" java.lang.Exception: When running with master 'yarn-client' either HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the environment.
于是配置spark.env.sh

再次运行:
[root@master conf]#
HADOOP_CONF_DIR=/hadoop/hadoop/etc/hadoop pyspark --master yarn --deploy-mode
client
[TerminalIPythonApp] WARNING | Subcommand
`ipython notebook` is deprecated and will be removed in future versions.
[TerminalIPythonApp] WARNING | You likely
want to use `jupyter notebook` in the future
[I 19:15:28.816 NotebookApp]
[nb_conda_kernels] enabled, 2 kernels found
[I 19:15:28.923 NotebookApp] ✓ nbpresent HTML export ENABLED
[W 19:15:28.923 NotebookApp] ✗ nbpresent PDF export DISABLED: No module named 'nbbrowserpdf'
[I 19:15:28.986 NotebookApp]
[nb_anacondacloud] enabled
[I 19:15:28.989 NotebookApp] [nb_conda]
enabled
[I 19:15:28.990 NotebookApp] Serving
notebooks from local directory: /hadoop/spark/conf
[I 19:15:28.990 NotebookApp] 0 active
kernels
[I 19:15:28.990 NotebookApp] The Jupyter
Notebook is running at: http://localhost:8888/
[I 19:15:28.990 NotebookApp] Use Control-C
to stop this server and shut down all kernels (twice to skip confirmation).
[I 19:15:44.862 NotebookApp] Creating new
notebook in
[I 19:15:45.742 NotebookApp] Kernel
started: 98d8605a-804a-47af-83fb-2efc8b5a3d60
Setting default log level to
"WARN".
To adjust logging level use
sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
18/11/20 19:15:48 WARN
util.NativeCodeLoader: Unable to load native-hadoop library for your
platform... using builtin-java classes where applicable
18/11/20 19:15:51 WARN yarn.Client: Neither
spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading
libraries under SPARK_HOME.
[W 19:15:55.943 NotebookApp] Timeout
waiting for kernel_info reply from 98d8605a-804a-47af-83fb-2efc8b5a3d60
18/11/20 19:16:11 ERROR spark.SparkContext:
Error initializing SparkContext.
org.apache.spark.SparkException: Yarn
application has already ended! It might have been killed or unable to launch
application master.
at
org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.waitForApplication(YarnClientSchedulerBackend.scala:85)
at
org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:62)
at
org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:173)
at
org.apache.spark.SparkContext.(SparkContext.scala:509)
at
org.apache.spark.api.java.JavaSparkContext.(JavaSparkContext.scala:58)
at
sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at
sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at
sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at
java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at
py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:247)
at
py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at
py4j.Gateway.invoke(Gateway.java:236)
at
py4j.commands.ConstructorCommand.invokeConstructor(ConstructorCommand.java:80)
at
py4j.commands.ConstructorCommand.execute(ConstructorCommand.java:69)
at
py4j.GatewayConnection.run(GatewayConnection.java:214)
at
java.lang.Thread.run(Thread.java:748)
18/11/20 19:16:11 ERROR
client.TransportClient: Failed to send RPC 7790789781121901013 to
/192.168.127.131:55928: java.nio.channels.ClosedChannelException
java.nio.channels.ClosedChannelException
at
io.netty.channel.AbstractChannel$AbstractUnsafe.write(...)(Unknown Source)
18/11/20 19:16:11 ERROR
cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: Sending
RequestExecutors(0,0,Map(),Set()) to AM was unsuccessful
java.io.IOException: Failed to send RPC
7790789781121901013 to /192.168.127.131:55928:
java.nio.channels.ClosedChannelException
at
org.apache.spark.network.client.TransportClient.lambda$sendRpc$2(TransportClient.java:237)
at
io.netty.util.concurrent.DefaultPromise.notifyListener0(DefaultPromise.java:507)
at
io.netty.util.concurrent.DefaultPromise.notifyListenersNow(DefaultPromise.java:481)
at
io.netty.util.concurrent.DefaultPromise.access$000(DefaultPromise.java:34)
at
io.netty.util.concurrent.DefaultPromise$1.run(DefaultPromise.java:431)
at
io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:399)
at
io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:446)
at
io.netty.util.concurrent.SingleThreadEventExecutor$2.run(SingleThreadEventExecutor.java:131)
at
io.netty.util.concurrent.DefaultThreadFactory$DefaultRunnableDecorator.run(DefaultThreadFactory.java:144)
at
java.lang.Thread.run(Thread.java:748)
Caused by: java.nio.channels.ClosedChannelException
at
io.netty.channel.AbstractChannel$AbstractUnsafe.write(...)(Unknown Source)
18/11/20 19:16:11 ERROR util.Utils:
Uncaught exception in thread Thread-2
org.apache.spark.SparkException: Exception
thrown in awaitResult:
at
org.apache.spark.util.ThreadUtils$.awaitResult(ThreadUtils.scala:205)
at
org.apache.spark.rpc.RpcTimeout.awaitResult(RpcTimeout.scala:75)
at
org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend.requestTotalExecutors(CoarseGrainedSchedulerBackend.scala:551)
at
org.apache.spark.scheduler.cluster.YarnSchedulerBackend.stop(YarnSchedulerBackend.scala:93)
at
org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.stop(YarnClientSchedulerBackend.scala:151)
at
org.apache.spark.scheduler.TaskSchedulerImpl.stop(TaskSchedulerImpl.scala:517)
at
org.apache.spark.scheduler.DAGScheduler.stop(DAGScheduler.scala:1652)
at
org.apache.spark.SparkContext$$anonfun$stop$8.apply$mcV$sp(SparkContext.scala:1921)
at
org.apache.spark.util.Utils$.tryLogNonFatalError(Utils.scala:1317)
at
org.apache.spark.SparkContext.stop(SparkContext.scala:1920)
at
org.apache.spark.SparkContext.(SparkContext.scala:587)
at
org.apache.spark.api.java.JavaSparkContext.(JavaSparkContext.scala:58)
at
sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at
sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at
sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at
java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at
py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:247)
at
py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at
py4j.Gateway.invoke(Gateway.java:236)
at
py4j.commands.ConstructorCommand.invokeConstructor(ConstructorCommand.java:80)
at
py4j.commands.ConstructorCommand.execute(ConstructorCommand.java:69)
at
py4j.GatewayConnection.run(GatewayConnection.java:214)
at
java.lang.Thread.run(Thread.java:748)
Caused by: java.io.IOException: Failed to
send RPC 7790789781121901013 to /192.168.127.131:55928:
java.nio.channels.ClosedChannelException
at
org.apache.spark.network.client.TransportClient.lambda$sendRpc$2(TransportClient.java:237)
at
io.netty.util.concurrent.DefaultPromise.notifyListener0(DefaultPromise.java:507)
at
io.netty.util.concurrent.DefaultPromise.notifyListenersNow(DefaultPromise.java:481)
at
io.netty.util.concurrent.DefaultPromise.access$000(DefaultPromise.java:34)
at
io.netty.util.concurrent.DefaultPromise$1.run(DefaultPromise.java:431)
at
io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:399)
at
io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:446)
at
io.netty.util.concurrent.SingleThreadEventExecutor$2.run(SingleThreadEventExecutor.java:131)
at
io.netty.util.concurrent.DefaultThreadFactory$DefaultRunnableDecorator.run(DefaultThreadFactory.java:144)
...
1 more
Caused by:
java.nio.channels.ClosedChannelException
at
io.netty.channel.AbstractChannel$AbstractUnsafe.write(...)(Unknown Source)
18/11/20 19:16:11 WARN metrics.MetricsSystem:
Stopping a MetricsSystem that is not running
18/11/20 19:16:11 WARN spark.SparkContext:
Another SparkContext is being constructed (or threw an exception in its constructor). This may indicate an error, since only one
SparkContext may be running in this JVM (see SPARK-2243). The other
SparkContext was created at:
org.apache.spark.api.java.JavaSparkContext.(JavaSparkContext.scala:58)
sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native
Method)
sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
java.lang.reflect.Constructor.newInstance(Constructor.java:423)
py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:247)
py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
py4j.Gateway.invoke(Gateway.java:236)
py4j.commands.ConstructorCommand.invokeConstructor(ConstructorCommand.java:80)
py4j.commands.ConstructorCommand.execute(ConstructorCommand.java:69)
py4j.GatewayConnection.run(GatewayConnection.java:214)
java.lang.Thread.run(Thread.java:748)
18/11/20 19:16:11 WARN yarn.Client: Neither
spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading
libraries under SPARK_HOME.
18/11/20 19:16:29 ERROR spark.SparkContext:
Error initializing SparkContext.
org.apache.spark.SparkException: Yarn
application has already ended! It might have been killed or unable to launch
application master.
at
org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.waitForApplication(YarnClientSchedulerBackend.scala:85)
at
org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:62)
at
org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:173)
at
org.apache.spark.SparkContext.(SparkContext.scala:509)
at
org.apache.spark.api.java.JavaSparkContext.(JavaSparkContext.scala:58)
at
sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at
sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at
sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at
java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at
py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:247)
at
py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at
py4j.Gateway.invoke(Gateway.java:236)
at
py4j.commands.ConstructorCommand.invokeConstructor(ConstructorCommand.java:80)
at
py4j.commands.ConstructorCommand.execute(ConstructorCommand.java:69)
at
py4j.GatewayConnection.run(GatewayConnection.java:214)
at
java.lang.Thread.run(Thread.java:748)
18/11/20 19:16:29 ERROR
client.TransportClient: Failed to send RPC 6243011927050432229 to
/192.168.127.131:59702: java.nio.channels.ClosedChannelException
java.nio.channels.ClosedChannelException
at
io.netty.channel.AbstractChannel$AbstractUnsafe.write(...)(Unknown Source)
18/11/20 19:16:29 ERROR
cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: Sending
RequestExecutors(0,0,Map(),Set()) to AM was unsuccessful
java.io.IOException: Failed to send RPC 6243011927050432229
to /192.168.127.131:59702: java.nio.channels.ClosedChannelException
at
org.apache.spark.network.client.TransportClient.lambda$sendRpc$2(TransportClient.java:237)
at
io.netty.util.concurrent.DefaultPromise.notifyListener0(DefaultPromise.java:507)
at
io.netty.util.concurrent.DefaultPromise.notifyListenersNow(DefaultPromise.java:481)
at
io.netty.util.concurrent.DefaultPromise.notifyListeners(DefaultPromise.java:420)
at
io.netty.util.concurrent.DefaultPromise.tryFailure(DefaultPromise.java:122)
at
io.netty.channel.AbstractChannel$AbstractUnsafe.safeSetFailure(AbstractChannel.java:852)
at
io.netty.channel.AbstractChannel$AbstractUnsafe.write(AbstractChannel.java:738)
at
io.netty.channel.DefaultChannelPipeline$HeadContext.write(DefaultChannelPipeline.java:1251)
at
io.netty.channel.AbstractChannelHandlerContext.invokeWrite0(AbstractChannelHandlerContext.java:733)
at
io.netty.channel.AbstractChannelHandlerContext.invokeWrite(AbstractChannelHandlerContext.java:725)
at
io.netty.channel.AbstractChannelHandlerContext.access$1900(AbstractChannelHandlerContext.java:35)
at
io.netty.channel.AbstractChannelHandlerContext$AbstractWriteTask.write(AbstractChannelHandlerContext.java:1062)
at
io.netty.channel.AbstractChannelHandlerContext$WriteAndFlushTask.write(AbstractChannelHandlerContext.java:1116)
at
io.netty.channel.AbstractChannelHandlerContext$AbstractWriteTask.run(AbstractChannelHandlerContext.java:1051)
at
io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:399)
at
io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:446)
at
io.netty.util.concurrent.SingleThreadEventExecutor$2.run(SingleThreadEventExecutor.java:131)
at
io.netty.util.concurrent.DefaultThreadFactory$DefaultRunnableDecorator.run(DefaultThreadFactory.java:144)
at
java.lang.Thread.run(Thread.java:748)
Caused by:
java.nio.channels.ClosedChannelException
at
io.netty.channel.AbstractChannel$AbstractUnsafe.write(...)(Unknown Source)
18/11/20 19:16:29 ERROR util.Utils:
Uncaught exception in thread Thread-2
org.apache.spark.SparkException: Exception
thrown in awaitResult:
at
org.apache.spark.util.ThreadUtils$.awaitResult(ThreadUtils.scala:205)
at
org.apache.spark.rpc.RpcTimeout.awaitResult(RpcTimeout.scala:75)
at
org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend.requestTotalExecutors(CoarseGrainedSchedulerBackend.scala:551)
at
org.apache.spark.scheduler.cluster.YarnSchedulerBackend.stop(YarnSchedulerBackend.scala:93)
at
org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.stop(YarnClientSchedulerBackend.scala:151)
at
org.apache.spark.scheduler.TaskSchedulerImpl.stop(TaskSchedulerImpl.scala:517)
at
org.apache.spark.scheduler.DAGScheduler.stop(DAGScheduler.scala:1652)
at
org.apache.spark.SparkContext$$anonfun$stop$8.apply$mcV$sp(SparkContext.scala:1921)
at
org.apache.spark.util.Utils$.tryLogNonFatalError(Utils.scala:1317)
at
org.apache.spark.SparkContext.stop(SparkContext.scala:1920)
at
org.apache.spark.SparkContext.(SparkContext.scala:587)
at
org.apache.spark.api.java.JavaSparkContext.(JavaSparkContext.scala:58)
at
sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at
sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at
sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at
java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at
py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:247)
at
py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at
py4j.Gateway.invoke(Gateway.java:236)
at
py4j.commands.ConstructorCommand.invokeConstructor(ConstructorCommand.java:80)
at
py4j.commands.ConstructorCommand.execute(ConstructorCommand.java:69)
at
py4j.GatewayConnection.run(GatewayConnection.java:214)
at
java.lang.Thread.run(Thread.java:748)
Caused by: java.io.IOException: Failed to
send RPC 6243011927050432229 to /192.168.127.131:59702:
java.nio.channels.ClosedChannelException
at
org.apache.spark.network.client.TransportClient.lambda$sendRpc$2(TransportClient.java:237)
at
io.netty.util.concurrent.DefaultPromise.notifyListener0(DefaultPromise.java:507)
at
io.netty.util.concurrent.DefaultPromise.notifyListenersNow(DefaultPromise.java:481)
at
io.netty.util.concurrent.DefaultPromise.notifyListeners(DefaultPromise.java:420)
at
io.netty.util.concurrent.DefaultPromise.tryFailure(DefaultPromise.java:122)
at
io.netty.channel.AbstractChannel$AbstractUnsafe.safeSetFailure(AbstractChannel.java:852)
at
io.netty.channel.AbstractChannel$AbstractUnsafe.write(AbstractChannel.java:738)
at
io.netty.channel.DefaultChannelPipeline$HeadContext.write(DefaultChannelPipeline.java:1251)
at
io.netty.channel.AbstractChannelHandlerContext.invokeWrite0(AbstractChannelHandlerContext.java:733)
at
io.netty.channel.AbstractChannelHandlerContext.invokeWrite(AbstractChannelHandlerContext.java:725)
at
io.netty.channel.AbstractChannelHandlerContext.access$1900(AbstractChannelHandlerContext.java:35)
at
io.netty.channel.AbstractChannelHandlerContext$AbstractWriteTask.write(AbstractChannelHandlerContext.java:1062)
at
io.netty.channel.AbstractChannelHandlerContext$WriteAndFlushTask.write(AbstractChannelHandlerContext.java:1116)
at
io.netty.channel.AbstractChannelHandlerContext$AbstractWriteTask.run(AbstractChannelHandlerContext.java:1051)
at
io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:399)
at
io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:446)
at
io.netty.util.concurrent.SingleThreadEventExecutor$2.run(SingleThreadEventExecutor.java:131)
at
io.netty.util.concurrent.DefaultThreadFactory$DefaultRunnableDecorator.run(DefaultThreadFactory.java:144)
...
1 more
Caused by:
java.nio.channels.ClosedChannelException
at
io.netty.channel.AbstractChannel$AbstractUnsafe.write(...)(Unknown Source)
18/11/20 19:16:29 WARN
metrics.MetricsSystem: Stopping a MetricsSystem that is not running
[IPKernelApp] WARNING | Unknown error in
handling PYTHONSTARTUP file /hadoop/spark/python/pyspark/shell.py:
[I 19:17:00.221 NotebookApp] Saving file at
/Untitled.ipynb
^C[I 19:17:03.428 NotebookApp] interrupted
Serving notebooks from local directory:
/hadoop/spark/conf
1 active kernels
The Jupyter Notebook is running at:
http://localhost:8888/
Shutdown this notebook server (y/[n])? y
[C 19:17:04.983 NotebookApp] Shutdown confirmed
[I 19:17:04.983 NotebookApp] Shutting down
kernels
[I 19:17:05.587 NotebookApp] Kernel
shutdown: 98d8605a-804a-47af-83fb-2efc8b5a3d60
这里主要出现了两个错误:
(1)
18/11/20 19:16:11 ERROR spark.SparkContext:
Error initializing SparkContext.
org.apache.spark.SparkException: Yarn
application has already ended! It might have been killed or unable to launch
application master.
(2)
Caused by: java.io.IOException: Failed to
send RPC 7790789781121901013 to /192.168.127.131:55928:
java.nio.channels.ClosedChannelException
分别将这两个错误百度下
有的说是内存不足,有的说是需要两个内核
对于内存不足,在yarn-site.xml增加两个点
就是下面图片上的最后两个点

又修改虚拟机设置给slave1增加了两个处理器,使它变成两个核
然而仍旧出现相同的错误
继续修改,中间不知道修改了什么,再次运行
出现了不一样的错误
[root@master hadoop]# pyspark --master yarn
[TerminalIPythonApp] WARNING | Subcommand
`ipython notebook` is deprecated and will be removed in future versions.
[TerminalIPythonApp] WARNING | You likely
want to use `jupyter notebook` in the future
[I 21:04:49.200 NotebookApp]
[nb_conda_kernels] enabled, 2 kernels found
[I 21:04:49.310 NotebookApp] ✓ nbpresent HTML export ENABLED
[W 21:04:49.310 NotebookApp] ✗ nbpresent PDF export DISABLED: No module named 'nbbrowserpdf'
[I 21:04:49.373 NotebookApp]
[nb_anacondacloud] enabled
[I 21:04:49.376 NotebookApp] [nb_conda]
enabled
[I 21:04:49.377 NotebookApp] Serving
notebooks from local directory: /hadoop/hadoop/etc/hadoop
[I 21:04:49.377 NotebookApp] 0 active
kernels
[I 21:04:49.377 NotebookApp] The Jupyter
Notebook is running at: http://localhost:8888/
[I 21:04:49.377 NotebookApp] Use Control-C
to stop this server and shut down all kernels (twice to skip confirmation).
[I 21:04:54.440 NotebookApp] Creating new
notebook in
[I 21:04:55.832 NotebookApp] Kernel
started: c526700a-7ee9-4bdc-9bf1-675db15d1799
SLF4J: Class path contains multiple SLF4J
bindings.
SLF4J: Found binding in
[jar:file:/hadoop/spark/jars/slf4j-log4j12-1.7.16.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in
[jar:file:/hadoop/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See
http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type
[org.slf4j.impl.Log4jLoggerFactory]
Setting default log level to
"WARN".
To adjust logging level use sc.setLogLevel(newLevel).
For SparkR, use setLogLevel(newLevel).
18/11/20 21:04:59 WARN util.NativeCodeLoader:
Unable to load native-hadoop library for your platform... using builtin-java
classes where applicable
18/11/20 21:05:02 WARN yarn.Client: Neither
spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading
libraries under SPARK_HOME.
[W 21:05:05.954 NotebookApp] Timeout
waiting for kernel_info reply from c526700a-7ee9-4bdc-9bf1-675db15d1799
18/11/20 21:06:09 WARN hdfs.DFSClient:
DataStreamer Exception
org.apache.hadoop.ipc.RemoteException(java.io.IOException):
File /user/root/.sparkStaging/application_1542716519992_0009/__spark_libs__6100798743446340760.zip
could only be replicated to 0 nodes instead of minReplication (=1). There are 1 datanode(s) running and 1 node(s)
are excluded in this operation.
at
org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:1562)
at
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:3245)
at
org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:663)
at
org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:482)
at
org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at
org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:619)
at
org.apache.hadoop.ipc.RPC$Server.call(RPC.java:962)
at
org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2040)
at
org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2036)
at
java.security.AccessController.doPrivileged(Native Method)
at
javax.security.auth.Subject.doAs(Subject.java:422)
at
org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1656)
at
org.apache.hadoop.ipc.Server$Handler.run(Server.java:2034)
at
org.apache.hadoop.ipc.Client.call(Client.java:1470)
at
org.apache.hadoop.ipc.Client.call(Client.java:1401)
at
org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232)
at
com.sun.proxy.$Proxy11.addBlock(Unknown Source)
at
org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:399)
at
sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at
java.lang.reflect.Method.invoke(Method.java:498)
at
org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187)
at
org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at
com.sun.proxy.$Proxy12.addBlock(Unknown Source)
at
org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.locateFollowingBlock(DFSOutputStream.java:1528)
at
org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:1345)
at
org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:587)
18/11/20 21:06:09 ERROR spark.SparkContext:
Error initializing SparkContext.
org.apache.hadoop.ipc.RemoteException(java.io.IOException):
File /user/root/.sparkStaging/application_1542716519992_0009/__spark_libs__6100798743446340760.zip
could only be replicated to 0 nodes instead of minReplication (=1). There are 1 datanode(s) running and 1 node(s)
are excluded in this operation.
at
org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:1562)
at
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:3245)
at
org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:663)
at
org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:482)
at
org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at
org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:619)
at
org.apache.hadoop.ipc.RPC$Server.call(RPC.java:962)
at
org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2040)
at
org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2036)
at
java.security.AccessController.doPrivileged(Native Method)
at
javax.security.auth.Subject.doAs(Subject.java:422)
at
org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1656)
at
org.apache.hadoop.ipc.Server$Handler.run(Server.java:2034)
at
org.apache.hadoop.ipc.Client.call(Client.java:1470)
at
org.apache.hadoop.ipc.Client.call(Client.java:1401)
at
org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232)
at
com.sun.proxy.$Proxy11.addBlock(Unknown Source)
at
org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:399)
at
sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at
java.lang.reflect.Method.invoke(Method.java:498)
at
org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187)
at
org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at
com.sun.proxy.$Proxy12.addBlock(Unknown Source)
at
org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.locateFollowingBlock(DFSOutputStream.java:1528)
at
org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:1345)
at
org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:587)
18/11/20 21:06:09 WARN
cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: Attempted to request
executors before the AM has registered!
18/11/20 21:06:09 WARN
metrics.MetricsSystem: Stopping a MetricsSystem that is not running
18/11/20 21:06:09 WARN spark.SparkContext:
Another SparkContext is being constructed (or threw an exception in its
constructor). This may indicate an
error, since only one SparkContext may be running in this JVM (see SPARK-2243).
The other SparkContext was created at:
org.apache.spark.api.java.JavaSparkContext.(JavaSparkContext.scala:58)
sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native
Method)
sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
java.lang.reflect.Constructor.newInstance(Constructor.java:423)
py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:247)
py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
py4j.Gateway.invoke(Gateway.java:236)
py4j.commands.ConstructorCommand.invokeConstructor(ConstructorCommand.java:80)
py4j.commands.ConstructorCommand.execute(ConstructorCommand.java:69)
py4j.GatewayConnection.run(GatewayConnection.java:214)
java.lang.Thread.run(Thread.java:748)
18/11/20 21:06:09 WARN yarn.Client: Neither
spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading
libraries under SPARK_HOME.
[I 21:06:55.876 NotebookApp] Saving file at
/Untitled.ipynb
18/11/20 21:07:16 WARN hdfs.DFSClient:
DataStreamer Exception
org.apache.hadoop.ipc.RemoteException(java.io.IOException):
File /user/root/.sparkStaging/application_1542716519992_0010/__spark_libs__8564260734942060287.zip
could only be replicated to 0 nodes instead of minReplication (=1). There are 0 datanode(s) running and 1 node(s)
are excluded in this operation.
at
org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:1562)
at
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:3245)
at
org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:663)
at
org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:482)
at
org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at
org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:619)
at
org.apache.hadoop.ipc.RPC$Server.call(RPC.java:962)
at
org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2040)
at
org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2036)
at
java.security.AccessController.doPrivileged(Native Method)
at
javax.security.auth.Subject.doAs(Subject.java:422)
at
org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1656)
at
org.apache.hadoop.ipc.Server$Handler.run(Server.java:2034)
at
org.apache.hadoop.ipc.Client.call(Client.java:1470)
at
org.apache.hadoop.ipc.Client.call(Client.java:1401)
at
org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232)
at
com.sun.proxy.$Proxy11.addBlock(Unknown Source)
at
org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:399)
at
sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at
java.lang.reflect.Method.invoke(Method.java:498)
at
org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187)
at
org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at
com.sun.proxy.$Proxy12.addBlock(Unknown Source)
at
org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.locateFollowingBlock(DFSOutputStream.java:1528)
at
org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:1345)
at
org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:587)
18/11/20 21:07:16 ERROR spark.SparkContext:
Error initializing SparkContext.
org.apache.hadoop.ipc.RemoteException(java.io.IOException):
File
/user/root/.sparkStaging/application_1542716519992_0010/__spark_libs__8564260734942060287.zip
could only be replicated to 0 nodes instead of minReplication (=1). There are 0 datanode(s) running and 1 node(s)
are excluded in this operation.
at
org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:1562)
at
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:3245)
at
org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:663)
at
org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:482)
at
org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at
org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:619)
at
org.apache.hadoop.ipc.RPC$Server.call(RPC.java:962)
at
org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2040)
at
org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2036)
at
java.security.AccessController.doPrivileged(Native Method)
at
javax.security.auth.Subject.doAs(Subject.java:422)
at
org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1656)
at
org.apache.hadoop.ipc.Server$Handler.run(Server.java:2034)
at
org.apache.hadoop.ipc.Client.call(Client.java:1470)
at
org.apache.hadoop.ipc.Client.call(Client.java:1401)
at
org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232)
at
com.sun.proxy.$Proxy11.addBlock(Unknown Source)
at
org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:399)
at
sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at
java.lang.reflect.Method.invoke(Method.java:498)
at
org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187)
at
org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at
com.sun.proxy.$Proxy12.addBlock(Unknown Source)
at
org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.locateFollowingBlock(DFSOutputStream.java:1528)
at
org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:1345)
at
org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:587)
18/11/20 21:07:16 WARN
cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: Attempted to request executors
before the AM has registered!
18/11/20 21:07:16 WARN
metrics.MetricsSystem: Stopping a MetricsSystem that is not running
[IPKernelApp] WARNING | Unknown error in
handling PYTHONSTARTUP file /hadoop/spark/python/pyspark/shell.py:
[I 21:07:36.291 NotebookApp] Saving file at
/Untitled.ipynb
[I 21:07:42.092 NotebookApp] Kernel
shutdown: c526700a-7ee9-4bdc-9bf1-675db15d1799
[W 21:07:42.095 NotebookApp] delete
/Untitled.ipynb
^C[I 21:07:46.458 NotebookApp] interrupted
Serving notebooks from local directory: /hadoop/hadoop/etc/hadoop
0 active kernels
The Jupyter Notebook is running at:
http://localhost:8888/
Shutdown this notebook server (y/[n])? y
[C 21:07:48.224 NotebookApp] Shutdown
confirmed
[I 21:07:48.225 NotebookApp] Shutting down
kernels
继续按照日志给出的信息继续寻找,
当我用
hadoop dfsadmin -report 查看一下磁盘使用情况时
Configured Capacity: 0 (0 B)
Present Capacity: 0 (0 B)
DFS Remaining: 0 (0 B)
DFS Used: 0 (0 B)
DFS Used%: NaN%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
于是重新格式化namenode,
因为上面提到hdfs,我有修改了一下hdfs-site.xml。将里面的replication值从1变到2
再一次start-all.sh,
[root@master bin]# hadoop dfsadmin -report
DEPRECATED: Use of this script to execute
hdfs command is deprecated.
Instead use the hdfs command for it.
Configured Capacity: 18238930944 (16.99 GB)
Present Capacity: 6707884032 (6.25 GB)
DFS Remaining: 6707879936 (6.25 GB)
DFS Used: 4096 (4 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Live datanodes (1):
Name: 192.168.127.131:50010 (slave1)
Hostname: slave1
Decommission Status : Normal
Configured Capacity: 18238930944 (16.99 GB)
DFS Used: 4096 (4 KB)
Non DFS Used: 11531046912 (10.74 GB)
DFS Remaining: 6707879936 (6.25 GB)
DFS Used%: 0.00%
DFS Remaining%: 36.78%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Tue Nov 20 21:26:11 CST 2018
在终端输入
pyspark --master yarn
惊喜了一下,结果出来了
