从0开始一步一步搭大数据集群平台,小白也能玩,超详细!!!
从零开始の大数据生活(始める!!!)
- 一、集群概况
- 二、服务器搭建
- (一)创建虚拟机
- 1.开启windows虚拟化服务
- 2.创建第一台虚拟机
- 3.克隆虚拟机
- 4.设置新用户
- 三、hadoop生态各框架安装与配置
- (一).jdk1.8安装与配置(环境准备)
- 1.下载jdk
- 2.解压安装
- 3.配置JAVA_HOME
- 4.测试是否安装成功
- 5.顺便配置下hosts文件
- (二)搭建前准备 ssh通信与shell脚本
- 1.主机间ssh通信
- 2.相关shell脚本(为了方便,不用可跳过)
- (三)hadoop2.7.2的安装与配置
- 1.下载hadoop
- 2.配置HADOOP_HOME
- 3.核心文件配置
- 4. 配置集群节点
- 5.配置完后分发到每个节点
- 6.第一次启动集群前要格式化namenode
- 7.启动集群(hadoop自带的脚本)
- 8.web界面查看
- 9.集群文件系统读写性能测试
- 10.添加lzo压缩支持
- (四)zookeeper的安装与配置
- 1.下载zookeeper
- 2.配置ZOOKEEPER_HOME
- 3.核心文件配置
- 4.启动服务
- (五)kafka的安装与配置
- (六)mysql的安装与配置
- (七)flume的安装与配置
- (八)hive的安装与配置
以下内容纯属个人学习工作总结,知识有限,有错的地方还请各位大佬指正。
一、集群概况
本集群采用3台linux服务器搭建(hadoop111、hadoop112、hadoop113),便于学习使用,生产中可自行扩展分配服务器。
二、服务器搭建
(本集群搭在windows上,采用VMware Workstation搭建3台linux服务器,若本身是linux系统可跳过此步)
(一)创建虚拟机
CentOS6.8下载链接link
提取码:nfov
1.开启windows虚拟化服务
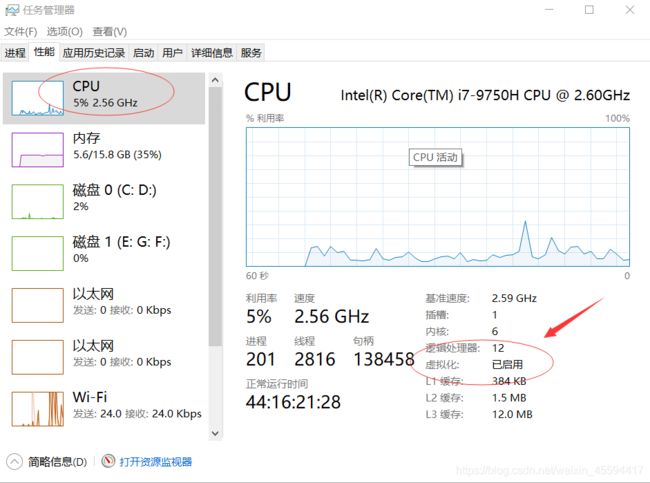
要使用VMware创建虚拟机首先要确保你的windows已经开启了虚拟化服务,任务栏->右键->任务管理器->性能->cpu,若没开启,自行百度哈。
2.创建第一台虚拟机
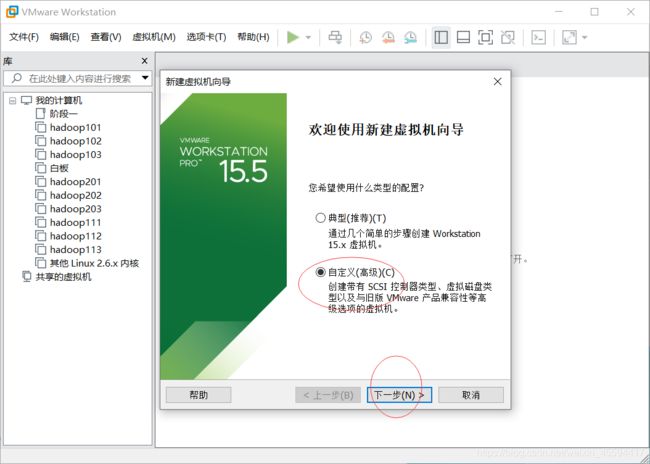
新建虚拟机,选自定义,下一步
没啥要选的,默认就行,下一步

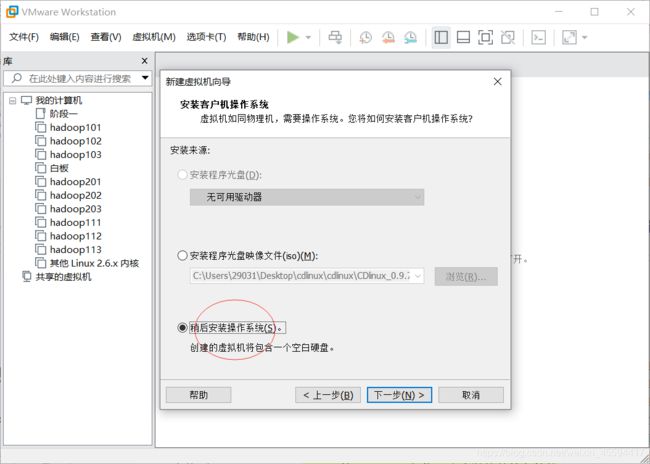
选稍后安装操作系统,因为我们待会用到自己下载的CentOs包
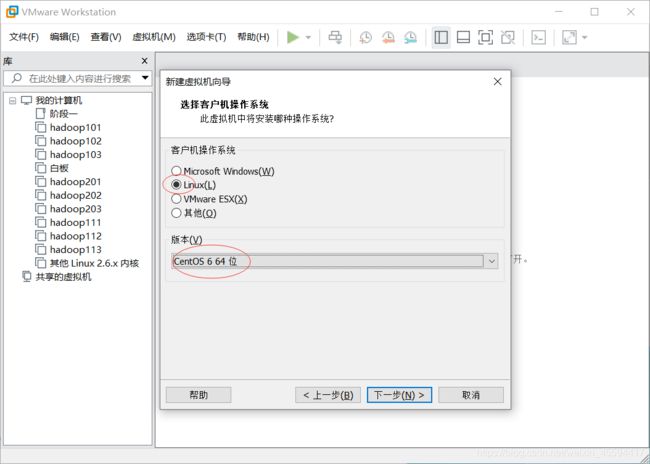
选择操作系统为linux,centOS 64位
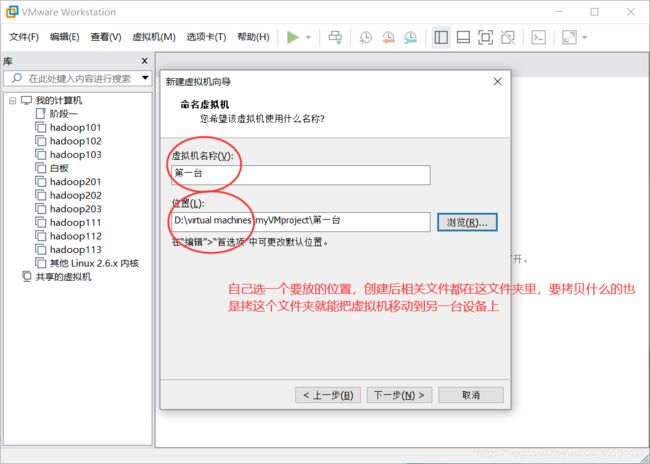
输入虚拟机的名字和存放位置,这里的名字随便取,自己认得就行
配置处理器核心数,下一步

cpu内存,我windows只有16G,三台测试机的话,我就每台给3G吧,若果你的设备内存多请随意挥洒~

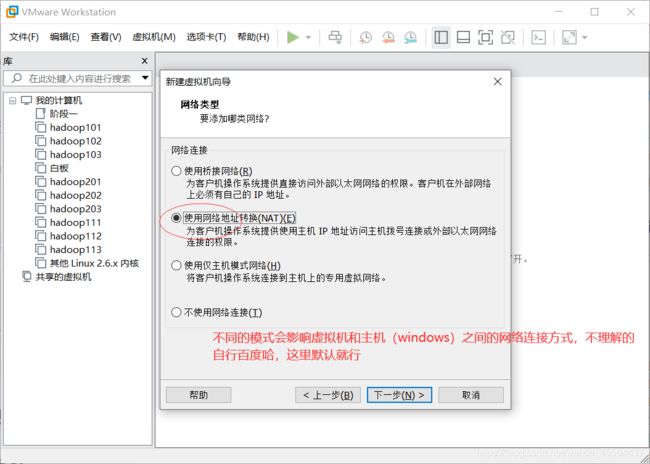
网络桥接方式,默认就行,下一步
默认,下一步
默认,下一步

创建新磁盘,下一步
输入磁盘大小,下一步

磁盘文件存放,建议放之前创建虚拟机时设置的目录
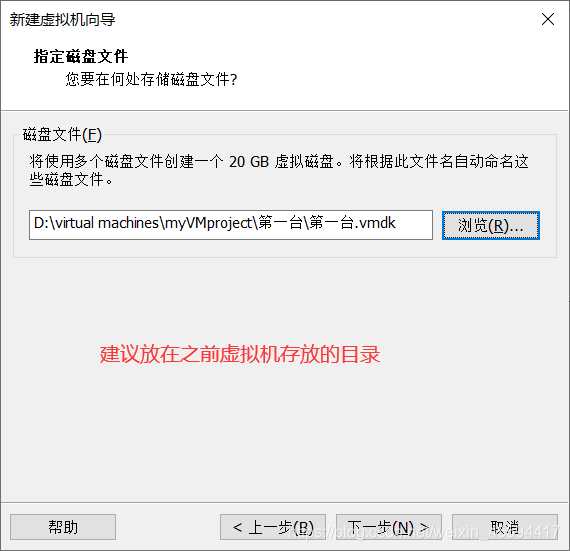
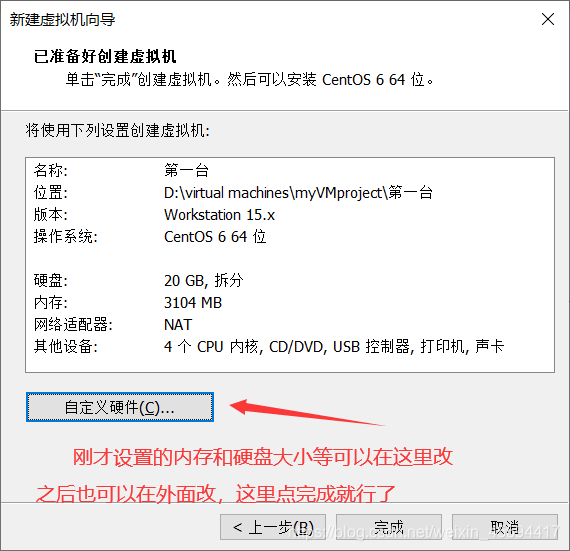
点击完成
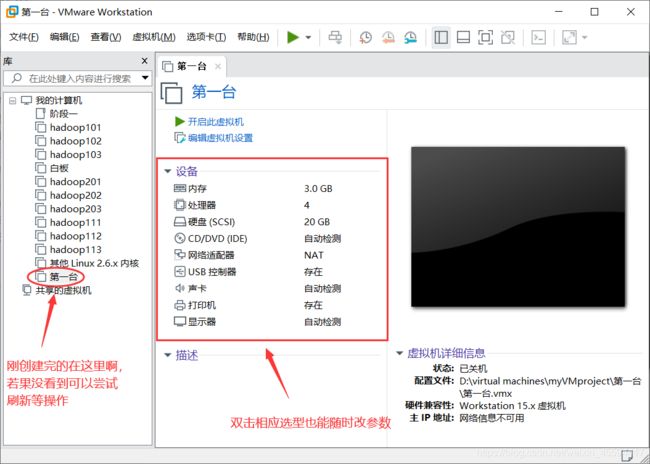
这里就可以看到新创的虚拟机了,现在还不能用,后面我们还要把自己下的centOS包放进去
双击cd,选择我们自己下载的CentOS.iso文件

看到这里正在使用文件。。。然后就可以点 开始此虚拟机 进行装系统了
点击进去,可用上下键选择,我们选第一个install or upgrade an existing system,然后enter,它就会开始安装了(鼠标点进去想要出来可以同时按crtl+alt)

校验操作系统是否完整,这里我的iso包是完整的就不检验了,skip
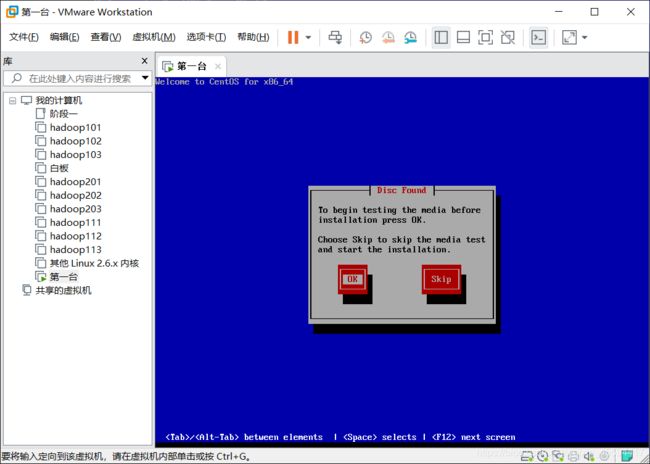
next

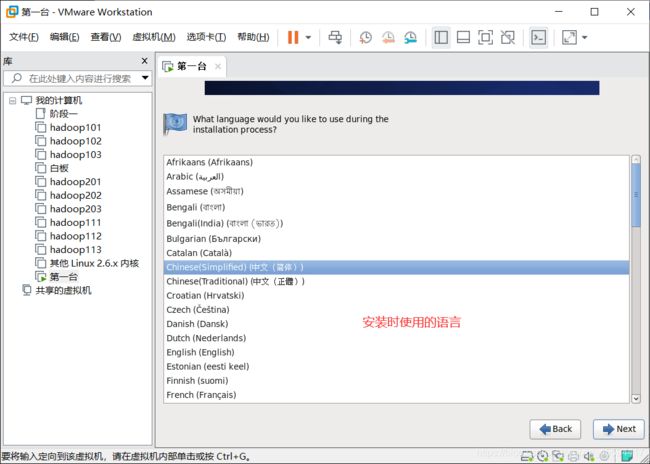
安装时使用的语言,next
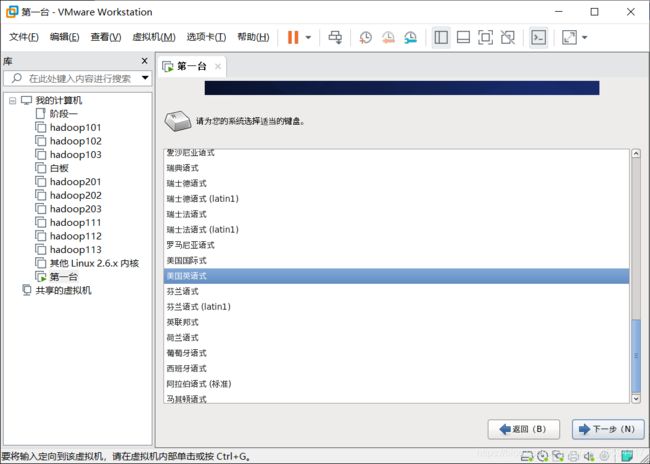
下一步
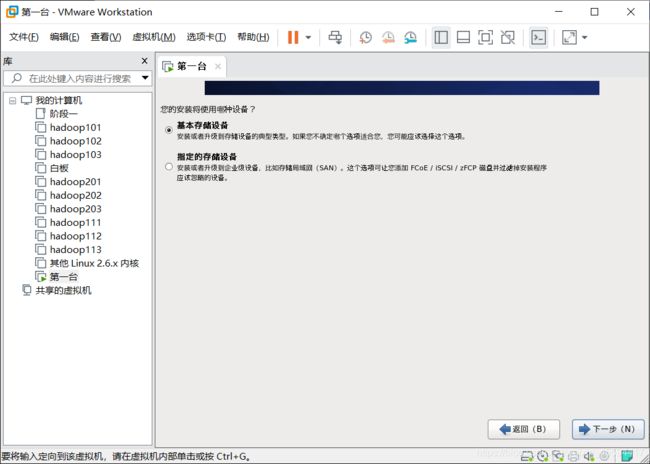
下一步
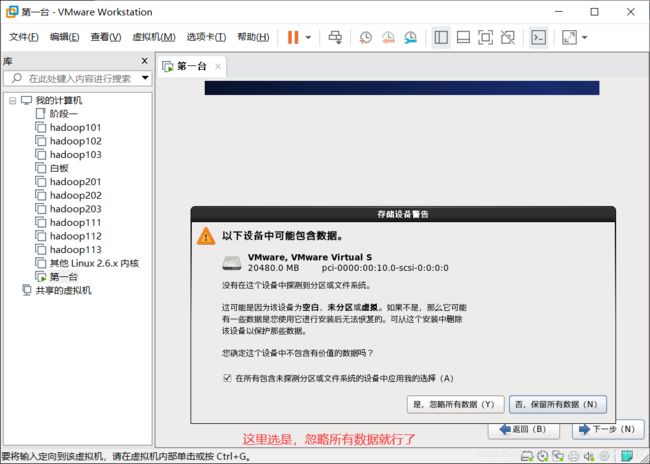
是,忽略,下一步
输入主机名,这里的主机名就是后面集群中用到的,因为我之前创建过hadoop111了,所以这里我就暂时取hadoop221

选一个时区,这里只有上海,我们就选上海了

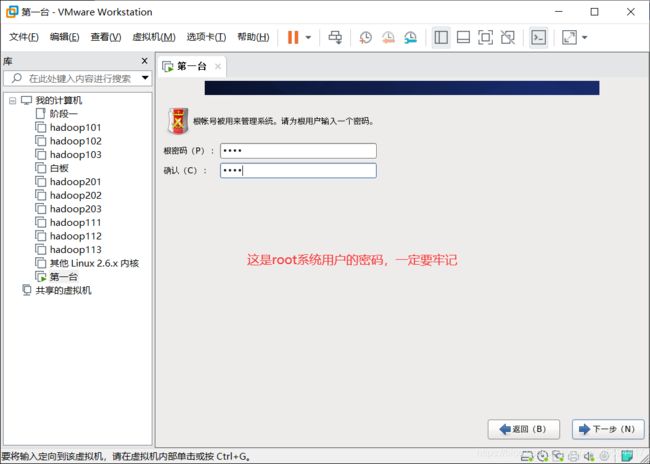
设置root系统管理员的密码,一定要牢记啊
选择自定义布局,去掉一些没必要的组件

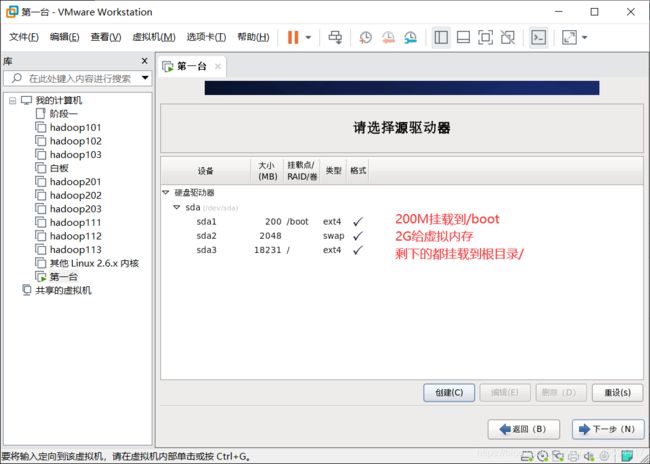
创建磁盘分区

格式化,将修改写入磁盘

下一步
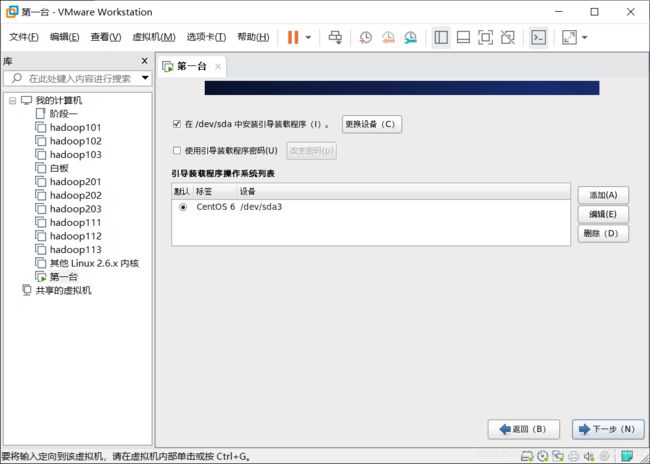
自定义布局,去掉不需要的组件
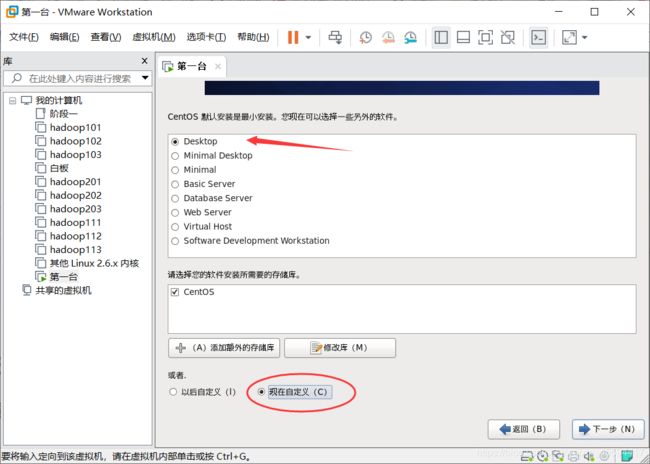
修改三个地方,1.基本系统只留‘基本’,2.应用程序留个‘互联网浏览器’就行了,3.服务器的‘服务器平台’去掉,下一步
等待中。。。
点重新引导
前进
前进,没啥好说的

这里我们先不创建用户,暂时用系统用户

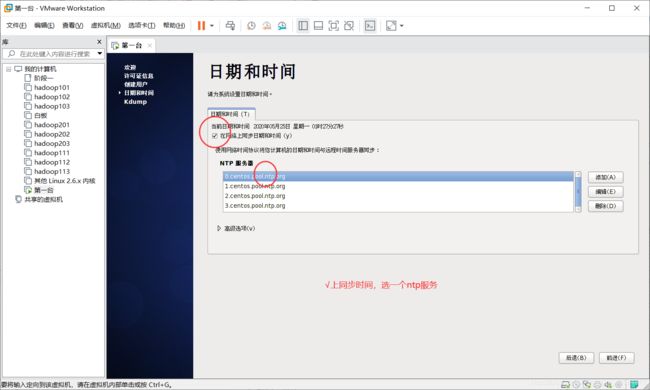
勾选同步时间,选一个NTP,前进
Kdump这是手机系统崩溃信息用的,我们就不勾了,点完成,他会叫我们重启,那就重启

激动人心的登录时刻到了,用root用户登录,密码就是刚才牢记的。
登录进来基本就完成啦,后面还有一点点小操作

为了让虚拟机(linux)能通过主机(windows)上网,我们需要对网络做一些配置
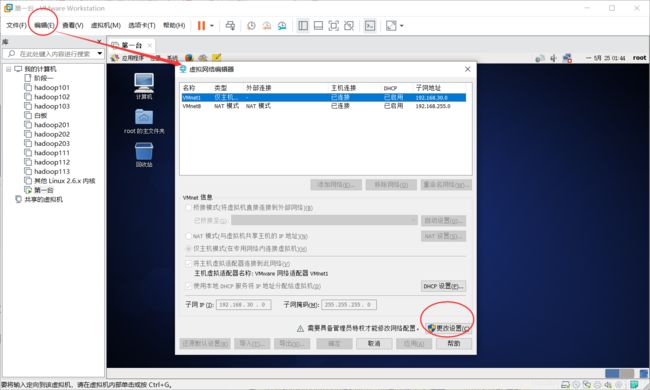
设置NAT模式,关于三种模式的区别,自行百度哈

设置hadoop221的ip

测试成功连上网络啦

最后一步,windows和linux相互ping一下,哈哈我这成功啦,到此终于装好一台了
3.克隆虚拟机
像之前一样装一台是不是挺麻烦的,所以后面我们就利用装好的虚拟机直接克隆,再改几个参数就行啦。
克隆前先确保要克隆的那台虚拟机是关机状态,右键->管理->克隆->下一步

下一步
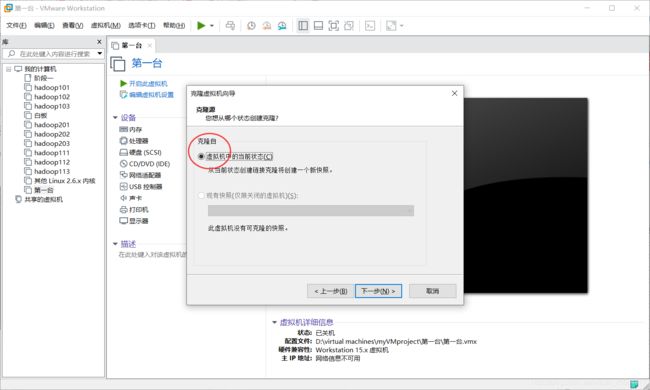
选择完整的克隆
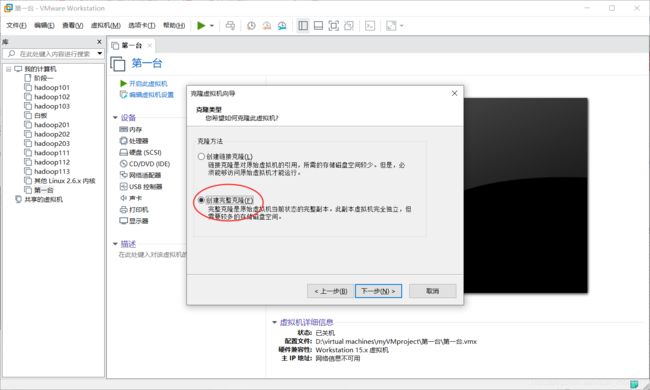
取个名字,找个地方放
等待完成。

第二台就出现啦

开机登录,现在这台新的和之前的是一模一样的,我们接下来要改几个配置
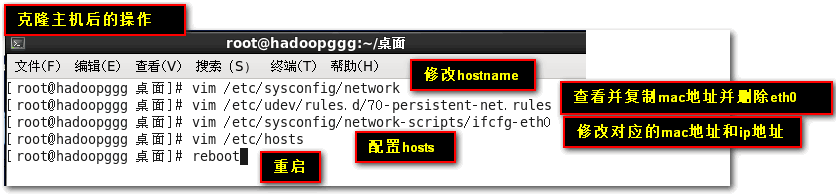
1.主机名hadoop221->hadoop222
2.ip 192.168.255.221->192.168.255.222
3.MAC地址
改完后这两台就是独立的了
linux桌面下右键->在终端中打开(linux的命令操作我就不过多介绍了)
vim /etc/sysconfig/network修改hostname为hadoop222
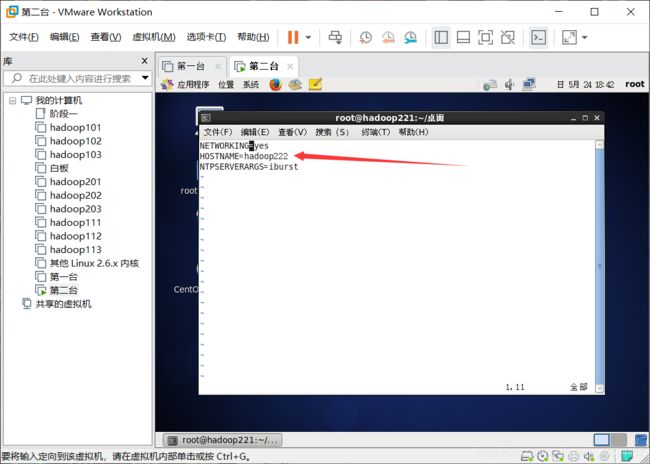
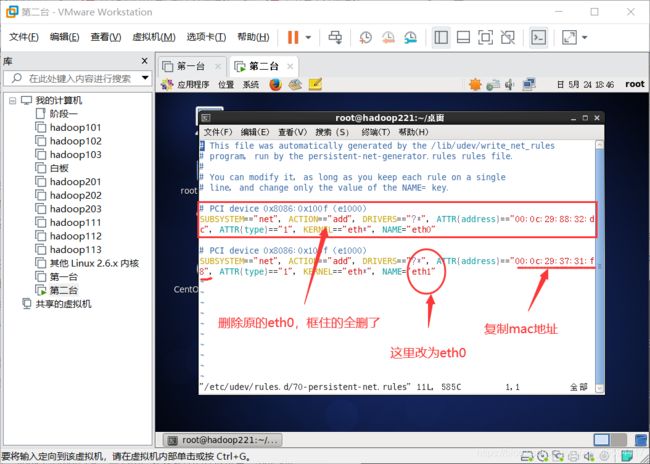
vim /etc/udev/rules.d/70-persistent-net.rules查看并复制mac地址,删除eth0
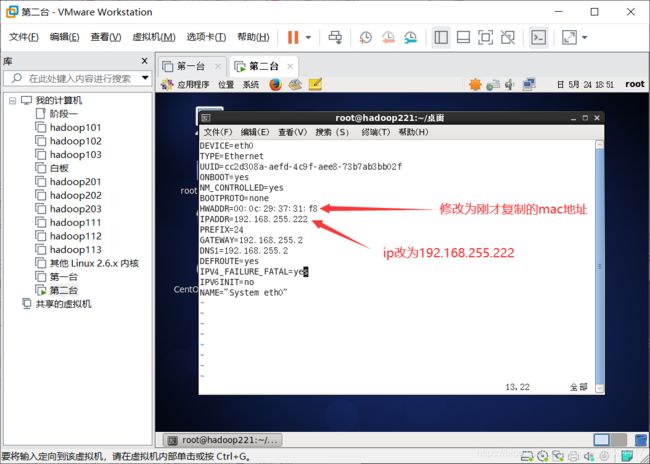
vim /etc/sysconfig/network-scripts/ifcfg-eth0修改对应的mac地址和ip
最后reboot重启就好了,也可以先配置下hosts文件(vim /etc/hosts),待会测试下看各主机能否成功ping通。
第一台也开机,哈哈,我的已经ping通啦,ok第二台也创建完成了。
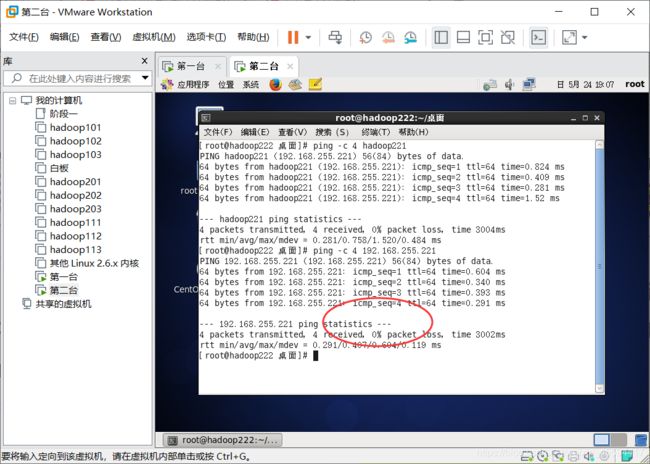
4.设置新用户
(占位)
三、hadoop生态各框架安装与配置
(一).jdk1.8安装与配置(环境准备)
链接:link
提取码:jydz
1.下载jdk
上传到/opt/soft目录下(linux下的/opt目录一般为用户安装软件的存放位置,/opt/soft和/opt/modules为自己创建的两个文件夹,一个用来放软件包,一个用来放安装(也就是解压)后的文件,下文不在赘述)
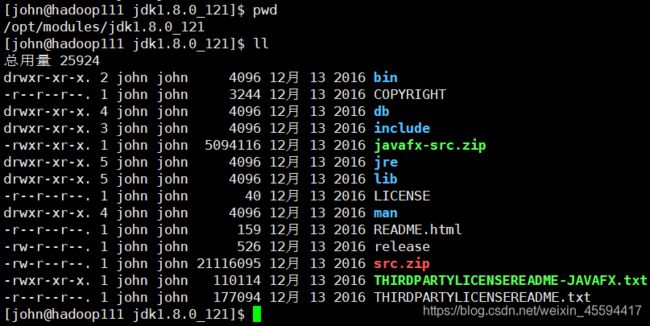
2.解压安装
直接用tar -zxvf jdk-8u121-linux-x64.tar.gz -C /opt/modules/解压到/opt/modules即安装成功
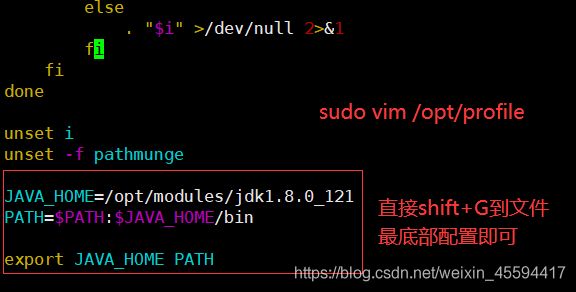
3.配置JAVA_HOME
sudo vim /etc/profile在文件中配置JAVA_HOME,这是基本,少了这个大部分的框架都不能用了。(注意修改/etc/profile文件要root全权限)
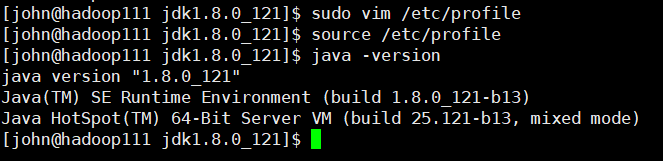
4.测试是否安装成功
刚修改完/etc/profile文件最好source /etc/profile一下,重新读取配置文件,接着java -version看是否配置成功
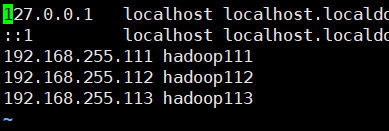
5.顺便配置下hosts文件
sudo vim /etc/hosts这里提前配置下各个服务器主机的hosts,下面就能直接引用了
(二)搭建前准备 ssh通信与shell脚本
1.主机间ssh通信
说明:为了方便各主机间的互相登录,需要通过ssh方式建立主机间的连接。
假设A主机的用户john需要以lucy的身份(lucy是B主机的用户)登录到B主机,那么需要john生成一个密匙对,一个公钥,一个私钥,john自己留有私钥,把公钥给lucy,那么B主机的home/lucy/.ssh/中的authorized_keys文件中就会有相应的信息,在经过第一次配对后,后面就能实现john免密登录B主机了(以lucy身份)。
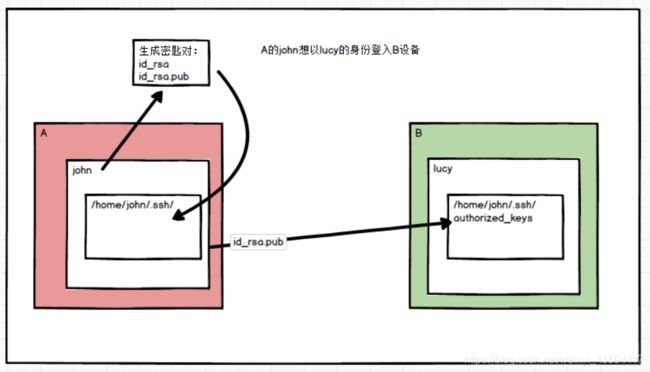
实现:主要是两个指令
ssh-keygen -t rsa
-t rsa表示用rsa的方式生成密匙对,使用这个指令会生成一个密匙对,在/home/john/.ssh/文件夹中(john使用的这个命令)

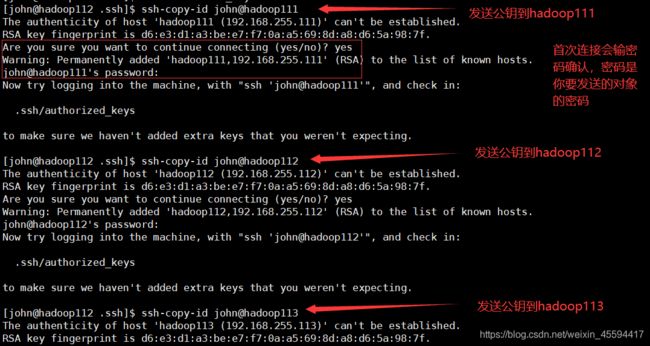
ssh-copy-id lucy@hadoop112
表示你把公钥放到了hadoop112(即上述例子中的B主机)的lucy用户下
注意:
①完成这两个指令就行了,但它实现的只是john以lucy的身份登录到了B主机,若B主机的lucy要以A主机的john身份登录到A主机,那么lucy需要重复以上步骤。
②A主机的john想以john的身份登录到A主机中,同样也要把之前生成的公钥放到A主机的john中,即ssh-copy-id john@A,所以若3台主机间需要都能互相登录需要3*3=9次copy操作。(以上指的登录都是指脚本中以ssh的方式操作其他主机)
③为了方便集群的管理与脚本的应用,本集群中的各个主机的用户都设为john,即lucy改为john,希望下面不会产生疑惑。
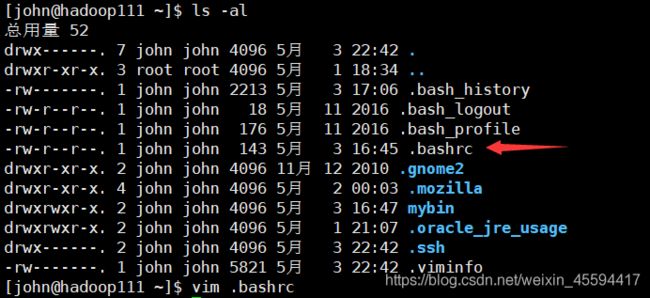
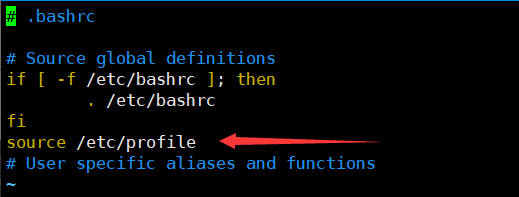
Tips: 通常脚本中都是以non-login的方式登录其他设备的,最好重新读取下/etc/profile配置文件
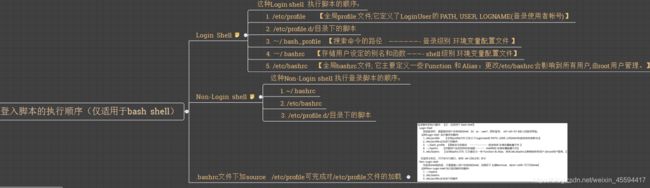
根据上图的执行顺序,我们可以把source /etc/profile写在~/.bashrc文件中,这样即使是non-login方式也会读取/etc/profile中的配置
2.相关shell脚本(为了方便,不用可跳过)
2.1 xcall 用于同时向3台主机发送同一个命令(都是以ssh的non-login方式登录)
#!/bin/bash
if(($#==0))
then
echo 请输入命令
exit
fi
echo 要执行的命令是$@
for((host=111;host<=113;host++))
do
echo ------------hadoop$host---------------
ssh hadoop$host $@
done
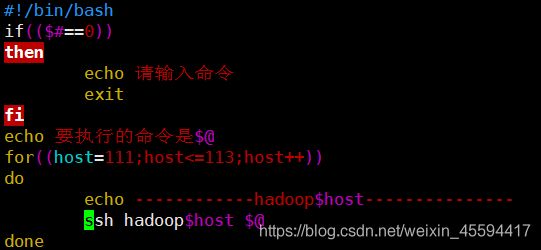
使用情况:

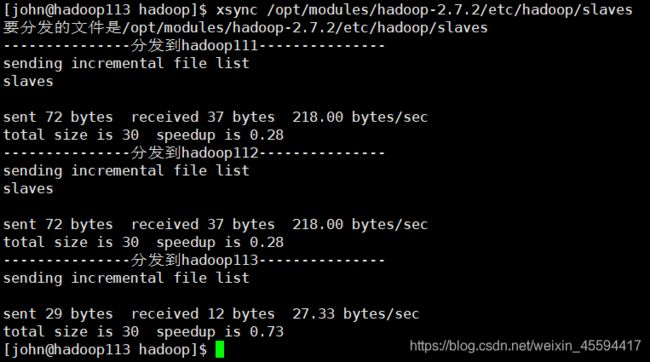
2.2 xsync 同步不同设备间的对应文件或目录,有变化的文件才会同步
#!/bin/bash
if(($#!=1))
then
echo 请输入一个文件路径
exit
fi
prename=$(cd -P `dirname $1`;pwd)
sufname=$(basename $1)
echo "要分发的文件是$prename/$sufname"
for((host=111;host<=113;host++))
do
echo ---------------分发到hadoop$host---------------
rsync -rvlt $prename/$sufname john@hadoop$host:$prename
done

使用情况:
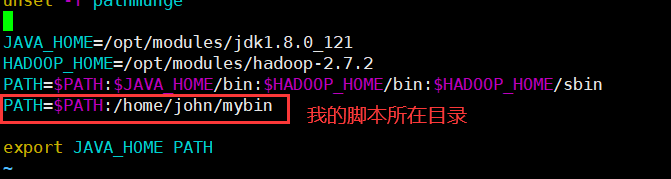
2.3 注意用户和权限,同时把脚本所在路径写在/etc/profile配置中,方便全局调用脚本
权限和用户
![]()
/etc/profile配置
sudo vim /etc/profile
(三)hadoop2.7.2的安装与配置
链接:link
提取码:1goi
1.下载hadoop
上传到/opt/soft目录下,解压到/opt/modules
tar -zxvf hadoop-2.7.2.tar.gz -C /opt/modules/,即安装完成
2.配置HADOOP_HOME
sudo vim /etc/profile在文件中配置HADOOP_HOME(后文不再赘述)

3.核心文件配置
配置hadoop四个核心文件core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml
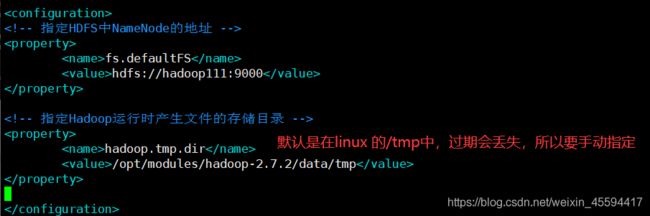
3.1 core-site.xml配置
fs.defaultFS
hdfs://hadoop111:9000
hadoop.tmp.dir
/opt/modules/hadoop-2.7.2/data/tmp
3.2 hdfs-site.xml配置
dfs.namenode.secondary.http-address
hadoop112:50090

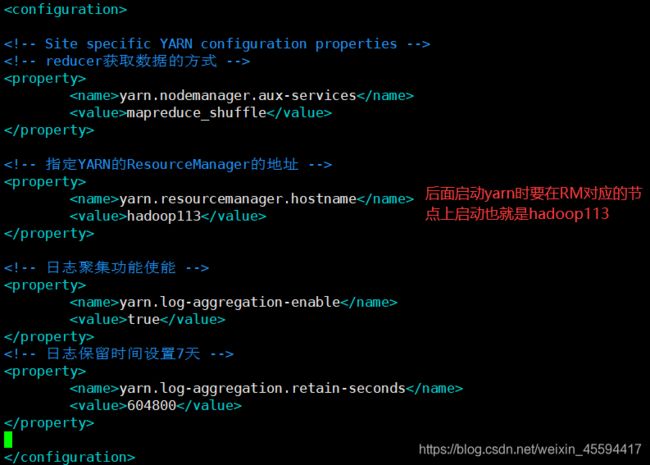
3.3 yarn-site.xml配置
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop113
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
3.4 mapred-site.xml配置
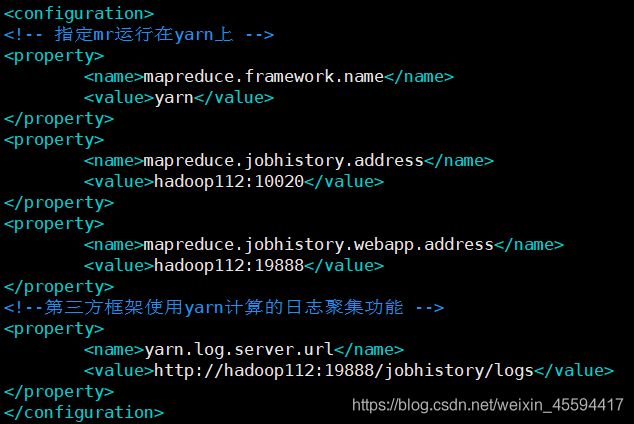
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
hadoop112:10020
mapreduce.jobhistory.webapp.address
hadoop112:19888
yarn.log.server.url
http://hadoop112:19888/jobhistory/logs
4. 配置集群节点
vim /opt/modules/hadoop-2.7.2/etc/hadoop/slaves
在slaves文件中配置每个节点的hostAdress 注意文件中不能有空格
hadoop111
hadoop112
hadoop113

5.配置完后分发到每个节点
可使用上面写的xsync脚本分发,当然你也可以自己复制粘贴。
6.第一次启动集群前要格式化namenode
namenode配在hadoop111,所以要在hadoop111执行hadoop namenode -format
格式化后相关的集群id,version信息机会在data目录中

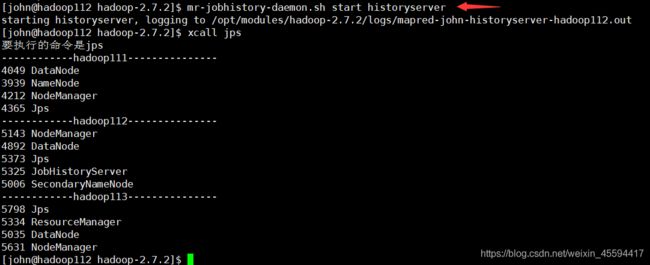
7.启动集群(hadoop自带的脚本)
start-dfs.sh
start-yarn.sh(必须在RM所在节点启动yarn)

mr-jobhistory-daemon.sh start historyserver(在哪配的历史服务器就在哪启动)
8.web界面查看
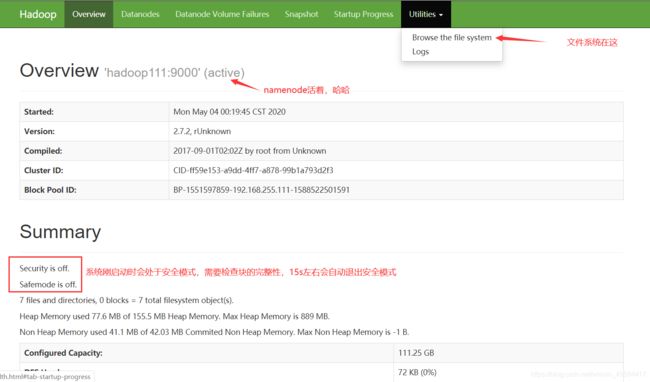
http://hadoop111:50070
我是在windows上用虚拟机搭的集群,所以windows也要配置hosts中hadoop111对应的ip地址,浏览器才能正确解析
文件系统:
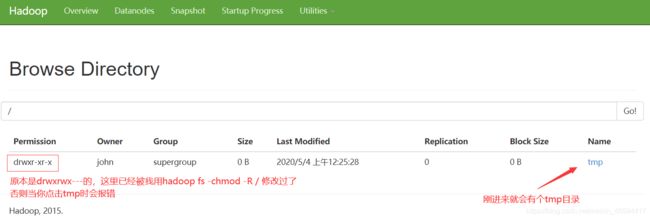
首次进来就会看见有个tmp目录,HDFS/tmp目录主要用作精简操作过程中的临时存储。 Mapreduce工件,中间数据等将保存在该目录下。 mapreduce作业执行完成后,这些文件将自动清除。如果删除此临时文件,则可能会影响当前正在运行的mapreduce作业。
刚进来时/tmp的权限是drwxrwx—,点击时会报Permission denied:user=dr.who,access=READ_EXECUTE, inode="/tmp":root:supergroup:drwxrwx—
所以我用了hadoop fs -chmod -R 755 /把 / 下的所有文件的权限都改了,这样再点击就能进入tmp目录了。
http://hadoop113:8088
进入yarn任务调度管理界面
9.集群文件系统读写性能测试
使用hadoop自带的测试工具测试:
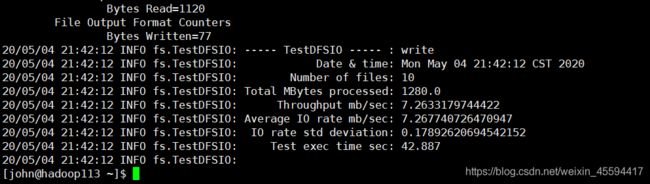
9.1 写测试,写入集群10个128MB的文件
hadoop jar /opt/modules/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.2-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB
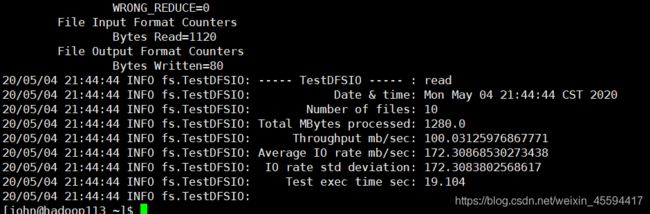
9.2 读测试,读取集群中10个128MB的文件
hadoop jar /opt/modules/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.2-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 128MB
9.3 清除测试数据
hadoop jar /opt/modules/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.2-tests.jar TestDFSIO -clean

10.添加lzo压缩支持
10.1 下载编译过的hadoop-lzo-0.4.20.jar包,将其放入/opt/modules/hadoop-2.7.2/share/hadoop/common/目录中,并分发,保证每个节点都有。
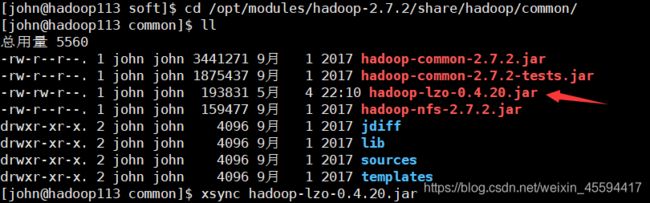
10.2 在core-site.xml中添加配置并分发到其他节点
io.compression.codecs
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
io.compression.codec.lzo.class
com.hadoop.compression.lzo.LzoCodec

10.3 重启集群测试
先创建个mytest文件,里面随便写几个单词,上传到dfs文件系统 /input(自己创建的)目录中,使用hadoop自带的测试用例统计单词个数 注意mr程序的output输出目录是自动生成的,你只能指定路径,不能手动创建!
hadoop jar /opt/modules/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount -Dmapreduce.output.fileoutputformat.compress=true -Dmapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzopCodec /input /output

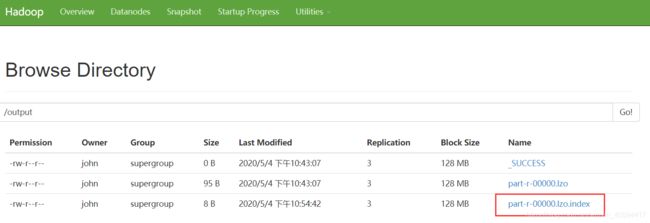
10.4 关于lzo创建索引
lzo格式文件创建索引后,作为数据输入可支持切片。
索引创建:
hadoop jar /opt/modules/hadoop-2.7.2/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /output
(四)zookeeper的安装与配置
1.下载zookeeper
上传到/opt/soft目录下,解压到/opt/modules
tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/modules/,即安装完成

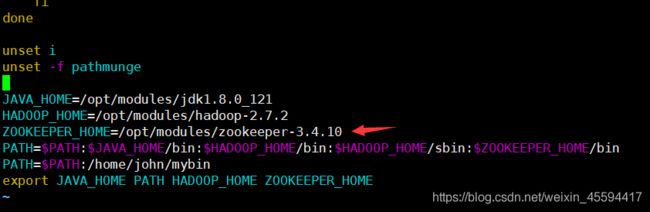
2.配置ZOOKEEPER_HOME
3.核心文件配置
3.1 将/opt/modules/zookeeper-3.4.10/conf/下的zoo_sample.cfg改名为zoo.cfg
mv /opt/modules/zookeeper-3.4.10/conf/zoo_sample.cfg zoo.cfg
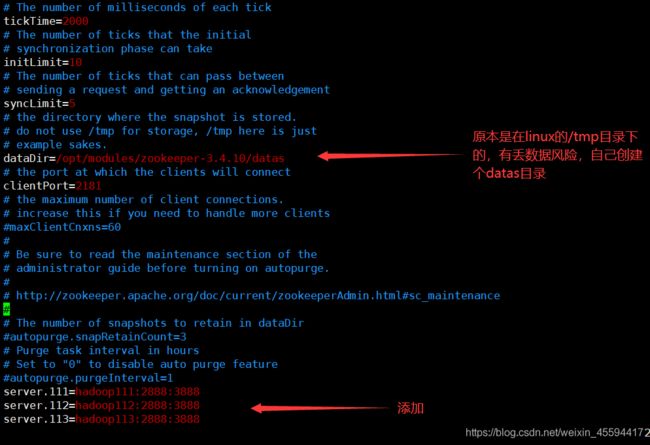
编辑zoo.cfg文件vim /opt/modules/zookeeper-3.4.10/conf/zoo.cfg
配置dataDir和server.集群信息
3.2 在/opt/modules/zookeeper-3.4.10/datas目录下创建myid文件,里面记录节点身份的id

3.3 在zkEnv.sh中修改log产生目录
vim /opt/modules/zookeeper-3.4.10/bin/zkEnv.sh

4.启动服务
记得将以上配置分发到其它节点,同时修改对应节点的myid,其它节点的ZOOKEEPER_HOME也别忘了配。
启动服务zkServer.sh start,每个节点都要启。
我就直接用xcall脚本来群起了 xcall zkServer.sh start
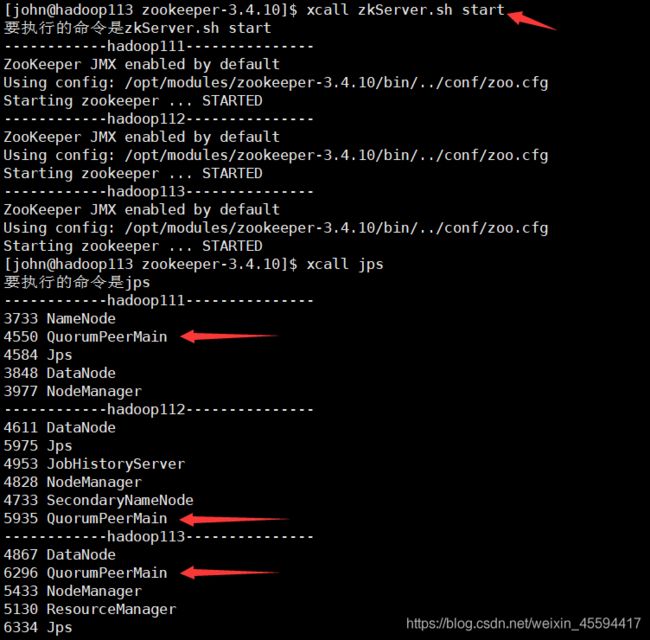
(五)kafka的安装与配置
链接:link
提取码:af7x
(六)mysql的安装与配置
链接:link
提取码:tuu5
(七)flume的安装与配置
链接:link
提取码:yoc9
(八)hive的安装与配置
链接:link
提取码:xqz8
先写到这,后面有时间再补吧。