Python的学习心得和知识总结(二)|Python基础(运算符、字符串)
2020年4月1日17:14:09
文章目录
- Python 运算符
- 布尔值 和 运算符
- Python布尔
- 比较运算符
- 逻辑运算符
- 同一运算符
- 运算符总结及位操作符
- Python 字符串
- 字符串编码
- 字符串创建
- 字符的转义
- 字符串拼接
- 字符串复制
- 不换行打印
- 从控制台读取字符串
- str()实现数字转字符串
- 使用[ ]来提取字符
- 字符串替换
- 字符串切片
- 字符串切割
- 字符串比较
- 可变字符串
- 字符串常用方法小结
- 查找方法
- 去除首尾
- 大小写转换
- 格式排版
- 字符串格式化{}
- 填充与对齐
- 数字格式化
今天我们主要学习一下 运算符,如下:
Python 运算符
布尔值 和 运算符
Python布尔
在Python2的时候,是没有布尔值的。是借助于0为False,1为True。到Python3的时候,这两个成了关键字,但是其实质上还是0和1。(所以他俩实质上还可以进行数字运算)
>>> a=True*3
>>> a
3
>>> b=False+4.0
>>> b
4.0
>>>
比较运算符
在Python里面,所有的比较运算符 返回1表示True;返回0表示False。当然这分别是和 特殊的变量True False等价的。这些比较运算符 如下:
- == :等于,判断对象的值是否相等
- != :不等于,判断对象的值是否不相等
- > :大于,大于成立则返回True
- < :小于,小于成立则返回True
- >=:大于等于 成立则返回True
- <=:小于等于 成立则返回True
>>> a=1
>>> b=2
>>> a==b
False
>>> a!=b
True
>>> a<b
True
>>> a>b
False
>>> a<=b
True
>>> a>=b
False
>>>
逻辑运算符
- or : 或 左为真,(不计算右边)则返回True;左为假,则返回右
- and :与 左为真,则返回右;左为假,(不计算右边)则返回False
- not :非
同一运算符
同一运算符:主要是用以比较两个对象的存储单元(实际上比较的是对象的地址)。
| 运算符 | 描述 |
|---|---|
| is | 判断两个标识符是否引用同一个对象,即:比较对象的地址(对象的ID),是否指向同一个内存地址 |
| is not | 判断两个标识符是否引用不同的对象 |
注:“==” 是判断引用变量引用对象的值是否相等(就是默认调用对象的_ _eq _ _()方法,因此效率比较低)。
>>> a=3
>>> b=3
>>> a==b
True
>>> a!=b
False
>>> a is b
True
>>> a is not b
False
>>> id(a)
140722942039776
>>> id(b)
140722942039776 #看来变量 引用的对象是同一个
>>> c=3
>>> a is c
True
>>> d = 3
>>> a is d
True
>>> e=4
>>> a is e
False
>>>
OK,大家再看一下下面这个例子:
>>> a=1024
>>> b=1024
>>> a==b
True
>>> a!=b
False
>>> a is b
False
>>> a is not b
True
>>> id(a)
1703171042064
>>> id(b)
1703171042128 #看来变量 引用的对象不是同一个
>>>
这就是需要注意的 整数缓存问题:
Python会对 比较小的整数对象(【-5,256】)进行缓存(进行重复使用),其余的整数对象没有。但是这仅仅是在命令行中执行时这么做,在Pycharm或者保存为文件 执行的时候,这个范围将会变成 【-5,任意正整数】。但是在VS2019里面,结果却如下所示:(解释器做了优化)

运算符总结及位操作符
我们上面已经讲了 + - * / // %等运算符,下面再详解一下 其他的运算符。
| 运算符 | 描述说明 |
|---|---|
| or、 and、 not | 布尔的 或 与 非 |
| is 、is not | 同一性判断,判断是否是同一个对象 |
| <、<=、 >、 >= 、!= 、== | 比较值是否相等 可以连用 |
| |、 ^ 、& | 按位的:或、异或、与 |
| << 、 >> | 移位操作 |
| ~ | 按位的翻转 |
| ** | 幂运算 |
下面是这些运算符的实例:
- 比较运算符的连用,其含义与日常理解一致
>>> a=5
>>> 3<=a<10
True
>>> a==5==1+4
True
>>>
- 位操作
>>> a=0B11001
>>> b=0B01000
>>> c=a|b #按位或
>>> c #c是0B11001 十进制就是25
25
>>> bin(c)
'0b11001'
--------------------------------------
>>> c=a&b #按位与
>>> bin(c)
'0b1000'
>>> c
8
--------------------------------------
>>> c=a^b #按位异或
>>> c
17
>>> bin(c)
'0b10001'
>>>
>>>
- 移位操作 :左移一位相当于*2;反之 /2
>>> a=1
>>> a<<3
8
>>> b=8
>>> b>>3
1
>>>
- 加法 乘法操作
>>> 3+2
5
>>> "清华大学"+"计算机科学与技术" #字符串拼接
'清华大学计算机科学与技术'
>>> "song"*2 #字符串复制
'songsong'
>>> [1,3,5,7]+[2,4,6,8,10] #列表、元组等合并
[1, 3, 5, 7, 2, 4, 6, 8, 10]
>>> [1,3,5,7]+[1,2,4,6,8,10]
[1, 3, 5, 7, 1, 2, 4, 6, 8, 10]
>>> [2,3,3]*3 #列表、元组等复制
[2, 3, 3, 2, 3, 3, 2, 3, 3]
>>>
- 复合赋值运算符的使用,可以使得程序 更加精炼简洁。
>>> a=3
>>> a+=4
>>> a
7
>>> b="song"
>>> b+="baobao"
>>> b
'songbaobao'
>>> a-=2 #相当于a=a-2 7-2=5
>>> a
5
>>> a*=2
>>> a
10
>>> a/=5
>>> a
2.0
>>> a=int(a) #这里恢复整数2
>>> a
2
>>> a**=3
>>> a
8
>>> a<<=1
>>> a
16
>>> a>>=1
>>> a
8
>>> a//=4 #这是整数的除法
>>> a
2
>>> a**=4
>>> a
16
>>> a%=5 #取余赋值
>>> a
1
>>> bin(a) #此时a=1
'0b1'
>>> a&=0b1111 #按位与赋值
>>> a
1
>>> a|=0b1111 #按位或赋值
>>> a
15
>>> a^=0b0110 #按位异或赋值
>>> a
9
>>> bin(a)
'0b1001'
>>>
注:Python没有++ --运算符
- 运算符优先级
下面的运算符的优先级从高到低,如下:

小建议:在复杂的表达式运算下,多使用()会更加准确。位运算 和 算数运算 > 比较运算 > 赋值运算 > 逻辑运算。这个在Python里面使用 就和常识一样,我们就不多说了(多使用小括号即可)。
Python 字符串
字符串编码
什么是字符串:字符序列 。在Python里面 字符串的内容是不可变的(即:无法对原有字符串做任何修改),只能将字符串的部分 复制到一个新创建的字符串里面。
注:在Python里面 是没有“字符类型的”,字符串就是一个基本类型。如 “a” 它也是一个字符串。这个单字符 也是作为一个字符串使用的。
不过说到字符串,其编码格式也是非常重要的。Python3是直接支持Unicode(可以表示世界上任何书面语言的字符),这也是其默认的。即:16位Unicode,而ASCII码是Unicode编码的子集。下面介绍两个重要的内置函数,如下:
>>> ord('A') # 把字符转化成对于的Unicode码
65
>>> ord("宋")
23435
>>> chr(66) # 把十进制数字(Unicode码)转化成对应的字符
'B'
>>> chr(23435)
'宋'
>>> chr(97)
'a'
>>>
字符串创建
可以使用单引号 或者 双引号来创建字符串,如下:
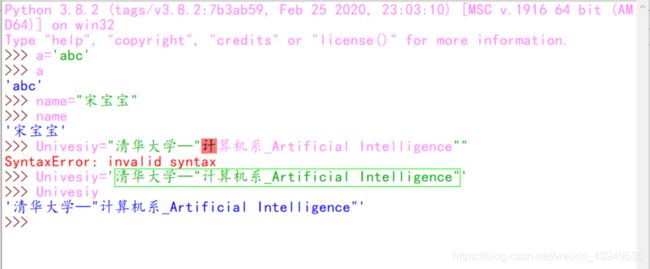
如上 我们可以使用两种引号 来实现创建字符串里面本身就使用了引号的。(不用使用转义字符)
我们还可以 使用连续的三个 “”" 或者 ‘’’,来创建多行字符串。例如:
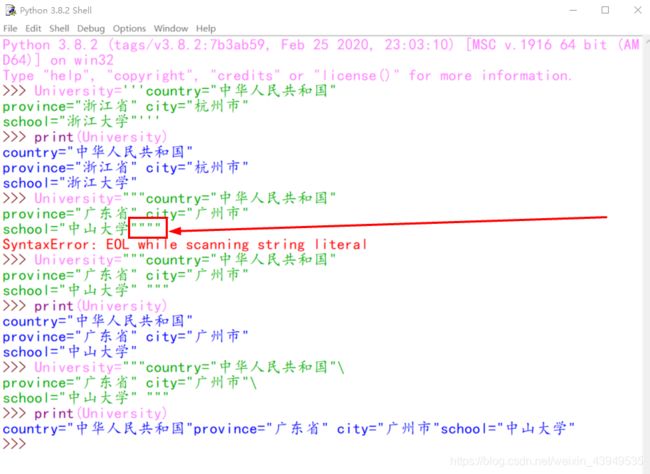
当然 Python也是允许空字符串的存在,如下:
空字符串的长度自然为0,下面介绍一下 len()函数:
>>> University="""country="中华人民共和国"\
province="广东省" city="广州市"\
school="中山大学" """
>>> print(University)
country="中华人民共和国"province="广东省" city="广州市"school="中山大学"
>>> emptystr=''
>>> emptystr
''
>>> len(emptystr)
0
>>> len(University)
56
>>>
如上,如此看来Python 和C语言不太一样的是 一个汉字竟然也是1字符.
字符的转义
转义字符 \,可以实现某些难以使用字符来表示的效果。常见的转义字符如下:
| 转义字符 | 描述 |
|---|---|
| \ 在行尾 | 表示这一行并没有结束,续到下一行 |
| \ \ | 反斜杠自身的表示 |
| \ ’ | 转义 单引号 |
| \ " | 转义 双引号 |
| \b | 退格(Backspace) |
| \n | 换行 |
| \t | 横向制表符 |
| \r | 回车 |

字符串拼接
通常情况下,我们可以使用 + 来完成多个字符串的拼接操作。需要的注意的点如下:
- 若是+ 两边都是字符串,直接拼接
- 若是+ 两边都是数字,则加法运算
- 若是+ 两边类型不同,则抛出异常
当然也可以直接将多个字面字符串放在一起,也可以实现拼接操作。
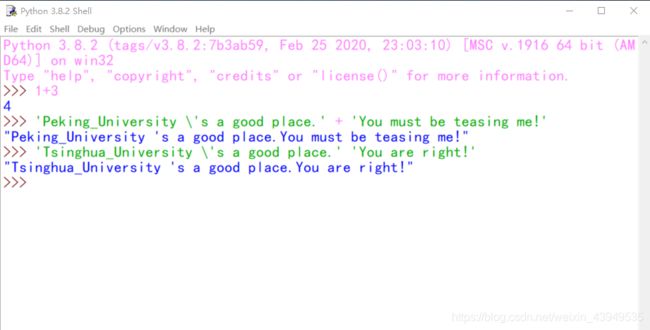
我之前也说了:即使是上面的这个拼接 它也是生成了一个新的字符串对象。
下面看一下join()函数(使用的时候 通常配合着列表一起使用 ),其作用刚好与split函数相反:用于将 一系列子字符串连接起来。如下:
>>> a=["song","baobao",'is a outstanding boy'] 列表里面存了多个对象
>>> a
['song', 'baobao', 'is a outstanding boy']
>>> "*".join(a) #用* 来作为连接符 进行填充
'song*baobao*is a outstanding boy'
>>> a
['song', 'baobao', 'is a outstanding boy']
>>> " ".join(a)
'song baobao is a outstanding boy'
>>> a
['song', 'baobao', 'is a outstanding boy']
>>> "".join(a)
'songbaobaois a outstanding boy'
>>>
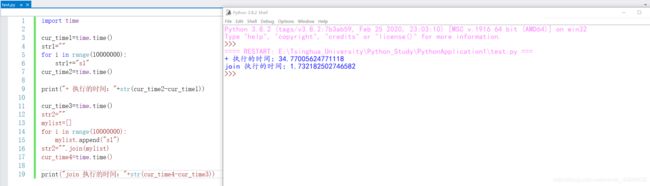
上面这两种字符串拼接,平时使用哪种都行。但是要是涉及到性能的时候,建议使用join。因为:使用字符串拼接符 + ,会生成新的字符串对象(+一次 生成一个新对象);而join函数会在拼接字符串之前 计算所有字符串的长度,然后逐一进行拷贝(仅新建一次对象)。如下:两种方式的对比
import time
cur_time1=time.time()
str1=""
for i in range(1000000):
str1+="song"
cur_time2=time.time()
print("+ 执行的时间:"+str(cur_time2-cur_time1))
cur_time3=time.time()
str2=""
mylist=[]
for i in range(1000000):
mylist.append("song")
str2="".join(mylist)
cur_time4=time.time()
print("join 执行的时间:"+str(cur_time4-cur_time3))

注:+ 方式的 上面这个时间的大小 和 所要连接的字符串长度有关:拼接的字符串越长 时间越长。
而且这两种方式下,在拼接次数更大的情况下 差异明显更大:
字符串复制
使用 * 来实现字符串的多次复制,如下:
>>> a='6'
>>> a
'6'
>>> a='6'*6
>>> a
'666666'
>>>
不换行打印
前面当调用print的时候,完成之后它会自动换行操作(默认以\n结尾)。可是有时候 我们不想换行。这个时候 可以通过使用end参数(end = “任意字符串”) 来实现末尾的内容添加(更改结尾内容)。

里面的内容也可以是 换行符 制表符等,如下:

从控制台读取字符串
在IDLE上操作如下:
>>> name = input("你个瓜娃儿叫个啥:")
你个瓜娃儿叫个啥:宋宝宝
>>> name
'宋宝宝'
>>>
在我的VS2019的控制台如下:

str()实现数字转字符串
函数str()可以实现 将其他数据类型转换成为字符串,如下:
>>> int('666')
666
>>> float("3.14")
3.14
-------------------------
>>> str(666)
'666'
>>> str(314e-2)
'3.14'
>>> str(6.28)
'6.28'
>>> str(3.14e2)
'314.0'
>>> str(False)
'False'
>>>
这就解释了 在调用print()函数的时候,解释器是自动地调用str()来把非字符串的对象转化成字符串。
使用[ ]来提取字符
这点 我们可以类比着C语言来理解:通过在字符序列的后面加上[偏移量:正负] 就可以得到这个指定位置的字符。
>>> string='abcdefg'
>>> len(string)
7
>>> string[6] #正向搜索 是最后一个
'g'
>>> string[-1] #反向搜索 是最后一个
'g'
>>> string[-7] #反向搜索 是第一个
'a'
>>> string[0] #正向搜索 是第一个
'a'
>>>
正向搜索: 范围是【0,len-1】
反向搜索: 范围是【-len, -1】
字符串替换
在Python里面 我们是不能改变字符串的内容的。可以调用replace函数来替换“原字符串的内容”
>>> string='abccba'
>>> string.replace('c','6')
'ab66ba'
>>> string
'abccba'
>>>
实质上:调用replace函数返回的是 新创建的字符串对象(旧的字符串并没有改变)。若是执行下面的操作,则新的对象的地址赋值给变量string。
>>> string='abccba'
>>> string=string.replace('c','6')
>>> string
'ab66ba'
>>>
字符串切片
主要是slice 操作:可以让我们快速的提取(截取)字符串,其格式如下:
[起始偏移量 start:终止偏移量 end:步长 step]
注:要头不要尾;步长默认 1
常见操作如下所示:
string="abcdef"
| 操作和说明 | 例子 | 最终结果 |
|---|---|---|
| [:] 提取整个字符串 | string[:] | ‘abcdef’ |
| [start:]从start索引处开始到结尾 | string[2:] | ‘cdef’ |
| [:end]从头到end-1处 | string[:2] | ‘ab’ |
| [start:end]从start索引处开始到end-1 | string[2:4] | ‘cd’ |
| [start:end:step]从start索引处开始到end-1,步长为step | string[1:5:2] | ‘bd’ |
>>> string
'abcdef'
>>> string[:]
'abcdef'
>>> string[2:]
'cdef'
>>> string[:2]
'ab'
>>> string[2:4]
'cd'
>>> string[1:5:2]
'bd'
>>>
上面的操作都是基于 start end step为正的情况下。下面看下这三个值为负的情形:
| 操作实例 | 例子说明 | 最终结果 |
|---|---|---|
| string[-3:] | 倒数三个 从-3开始向右走 | ‘def’ |
| string[-5:-3] | 倒数第五个到倒数第三个(包头不包尾) | ‘bc’ |
| string[::-1] | 步长为负,从右到左 反向提取 | ‘fedcba’ |
>>> string[-3:]
'def'
>>> string[-5:-3]
'bc'
>>> string[::-1]
'fedcba'
>>>
注:当切片操作时,起始偏移量和终止偏移量 不在[0,len-1]时,也不会报错。因为起始偏移量 小于0会被处理为0;终止偏移量大于len-1会被当成取到最结尾。如下:
>>> string[0:7]
'abcdef'
字符串切割
字符串切割 split()可以基于指定分隔符 将字符串分割处理为 多个子字符串(存储到列表中)。若是不进行指定分隔符,将采用默认的空白字符。如:换行符、空格、制表符。
>>> string="I want to go to the computer department of Tsinghua University"
>>> string.split() #默认切割
['I', 'want', 'to', 'go', 'to', 'the', 'computer', 'department', 'of', 'Tsinghua', 'University']
>>> string.split('to') #以to 为分割
['I want ', ' go ', ' the computer department of Tsinghua University']
>>>
字符串比较
首先介绍一下 字符串驻留机制:仅保留一份相同且不可变字符串的方法,不同的值被存放在字符串驻留池里面。在Python里面,对于符合标识符规则的字符串(仅包含下划线_ 、字母和数字)会启用字符串驻留机制(意思是说:符合规则的字符串对象,Python仅创建一次 然后由不同的变量引用这一个对象)。
>>> a='song_123_ok'
>>> b="song_123_ok"
>>> a is b
True
>>> c="#song_123_ok"
>>> d="#song_123_ok"
>>> c is not d
True
>>> id (c)
2390236304752
>>> id(d)
2390236304944
>>> e="aa"
>>> f='bb'
>>> e+f
'aabb'
>>> e+f is "aabb"
False
>>> e+f == "aabb"
True
>>>
如上,我们这里再说一下 字符串比较和同一性的问题
当使用“==”和“!=”的时候:对字符串的比较指的是 是否含有相同的字符(value)。
而当使用“is”和“is not”的时候:比较的是对象的地址(ID),即:id(obj1)是否等于id(obj2)。
说到比较,我们再介绍一下 成员操作符
in/not in 这两个关键字 ,用来判断 某个字符(子字符串)是否存在于某个字符串中。
>>> "a" in e
True
>>> 'cc' not in e+f
True
>>>
可变字符串
我们上面也说了,在Python里面 字符串属于不可变对象(一旦被定义出来,是不支持原地修改的)。若是真的需要修改其中的值,是通过创建新的字符串对象(每次都会创建)。可是若是我们的应用场景:需要原地来修改字符串(或许是频繁的修改),就需要借助于 io.StringIO对象或者array模块。详情如下:
>>> import io
>>> s="hello,world"
>>> s
'hello,world'
>>> sio=io.StringIO(s) #这里产生的新对象(可变对象),对象里面包含了一个字符串
>>> sio
<_io.StringIO object at 0x0000022C176795E0>
>>> sio.getvalue() #这个字符串就是可以随意的修改了,不在产生新的对象
'hello,world'
>>> sio.seek(6) # 移动偏移指针 即:指向w
6
>>> sio.write("W") #修改过程中 没有产生新对象
1
>>> sio.getvalue()
'hello,World'
>>> s #s还在 没有变化
'hello,world'
>>>
解释一下:如此 若是应用场景修改字符串比较频繁的话,就可以使用上面这种可变字符串对象。
字符串常用方法小结
查找方法
string='abcdefghijklmnopqrstuvwxyz'
| 方法实例 | 使用说明 | 结果 |
|---|---|---|
| len(string) | 该字符串长度 | 26 |
| string.startswith(‘abc’) | 以指定字符串开头 | True |
| string.endswith(‘xyz’) | 以指定字符串结尾 | True |
| string.find(“c”) | 第一次出现该指定字符串的位置 | 2 |
| string.rfind(“c”) | 最后一次出现该指定字符串的位置(反向搜索) | 2 |
| string.count(“c”) | 指定字符串出现的次数 | 1 |
| string.isalnum() | 所有字符全是字母或者数字 | True |
还有以下几个方法:
- isalnum() 判断是否为字母或数字
- isalpha() 判断字符串是否只为字母组成(含汉字)
- isdigit() 判断字符串是否只为数字组成
- isspace() 判断是否为空白符(空格 制表符 换行)
- isupper() 判断是否为大写字母
- islower() 判断是否为小写字母
| 方法实例 | 使用说明 | 结果 |
|---|---|---|
| “song666”.isalnum() | 所有字符全是字母或者数字 | True |
| “宋zzz”.isalpha() | 判断字符串是否只为字母组成(含汉字) | True |
| “1122345”.isdigit() | 判断字符串是否只为数字组成 | True |
| " ".isspace() | 判断是否为空白符 | True |
| “PPP”.isupper() | 判断是否为大写字母 | True |
| “bbb”.islower() | 判断是否为小写字母 | True |
去除首尾
主要是有三个函数具体在做这件事情:
- strip()去除字符串首尾指定信息
- lstrip()去除字符串左边指定信息
- rstrip()去除字符串右边指定信息
什么参数也不传,则表示去除空白;然后函数返回一个新的字符串。
>>> '666song666jin666zhou666'.strip("66")
'song666jin666zhou'
>>> '666song666jin666zhou666'.strip("6")
'song666jin666zhou'
>>> '666song666jin666zhou666'.strip("6666")
'song666jin666zhou'
>>> '666song666jin666zhou666'.lstrip("6")
'song666jin666zhou666'
>>> '666song666jin666zhou666'.rstrip("6")
'666song666jin666zhou'
>>>
大小写转换
>>> string="the computer department of Tsinghua University is very powerful"
>>> string.capitalize()
'The computer department of tsinghua university is very powerful'
>>> string.title()
'The Computer Department Of Tsinghua University Is Very Powerful'
>>> string.upper()
'THE COMPUTER DEPARTMENT OF TSINGHUA UNIVERSITY IS VERY POWERFUL'
>>> string.lower()
'the computer department of tsinghua university is very powerful'
>>> string.swapcase()
'THE COMPUTER DEPARTMENT OF tSINGHUA uNIVERSITY IS VERY POWERFUL'
>>>
如上,下面来介绍一下上面的函数
| 方法实例 | 使用说明 |
|---|---|
| string.capitalize() | 产生新的字符串,首字母大写 |
| string.title() | 产生新的字符串,每个单词都首字母大写 |
| string.upper() | 产生新的字符串,所有字符都转化成大写 |
| string.lower() | 产生新的字符串,所有字符都转化为小写 |
| string.swapcase() | 产生新的字符串,之前字符串大小写翻转 |
格式排版
主要是有三个函数具体在做这件事情:
- center()使用内容进行填充 居中
- ljust()使用内容进行填充 靠左
- rjust()使用内容进行填充 靠右
>>> string="tsinghua"
>>> len(string)
8
>>> string.center(12)
' tsinghua '
>>> string.center(12,"*")
'**tsinghua**'
>>> string.center(12,"-")
'--tsinghua--'
>>> string.ljust(12)
'tsinghua '
>>> string.ljust(12,'*')
'tsinghua****'
>>> string.ljust(12,"**")
Traceback (most recent call last):
File "" , line 1, in <module>
string.ljust(12,"**")
TypeError: The fill character must be exactly one character long
>>> string.ljust(12,"-")
'tsinghua----'
>>> string.rjust(12,"+")
'++++tsinghua'
>>>
注:这里面只能够使用 一个字符来作为参数。
字符串格式化{}
format() 实现字符串格式化的内容:
对于我最熟悉的C而言,%系列 对于传递参数是非常的了解的。在Python里面,使用{}来代替之前的 %。此外, format函数可以接受 不限个参数,位置可以不按照顺序。 在Python3之后 还是建议大家使用format函数去进行格式化。
>>> string='名字是:{0},年龄是:{1},学校是:{2}'
>>> string.format("宋大宝","22","清华大学")
'名字是:宋大宝,年龄是:22,学校是:清华大学'
>>> string.format("宋大宝",22,"清华大学")
'名字是:宋大宝,年龄是:22,学校是:清华大学'
>>> string.format("宋二宝","15","武汉大学")
'名字是:宋二宝,年龄是:15,学校是:武汉大学'
>>> string.format("宋三宝",12,"清华大学")
'名字是:宋三宝,年龄是:12,学校是:清华大学'
>>> string='名字是:{0},年龄是:{1},学校是:{2}.{0}是个好孩子'
>>> string.format("宋三宝",12,"清华大学")
'名字是:宋三宝,年龄是:12,学校是:清华大学.宋三宝是个好孩子'
>>>
{1} 等相当于 这是一个占位符的作用;我们通过使用format函数来进行实质的参数传递(根据索引号进行实际的字符串的填充 )。当然也可以如下:
>>> string='名字是:{name},学校是:{University}'
>>> string.format(name="宋大宝",University="清华大学")
'名字是:宋大宝,学校是:清华大学'
>>>
如上的方式 就是通过 {索引号}或者{参数名} ,直接映射参数值(这里是通过参数名进行的格式化匹配),实现对字符串的格式化 非常方便。
填充与对齐
填充是和对齐一起使用的,其使用方法如下:(上面format做的就是 填充)
- ^ < > 这三个符号分别表示的:居中 左对齐 右对齐,后面带上宽度(准备要打印的总的长度)。
- :冒号后面准备要填充的字符,只可以是一个字符,不指定的话 默认是使用空格进行填充
上面这两部分都是集合到将要调用format的字符串的{}里面,进行使用的。如下:
>>> "{:*>8}".format("666")
'*****666'
>>> "{:*^7}".format("666")
'**666**'
>>> "{:*<8}".format("666")
'666*****'
>>> "名字是:{0},学校是:{1:*^8}".format("宋宝宝","清华大学")
'名字是:宋宝宝,学校是:**清华大学**'
>>> "名字是:{name:-^7},学校是:{University:*^8}".format(name="宋宝宝",University="清华大学")
'名字是:--宋宝宝--,学校是:**清华大学**'
>>>
# 解释最后一个:name这个参数 有3个字符,但是宽度是7 而且又指定填充符为- 填充格式为居中。因此 --宋宝宝--
数字格式化
上面说了字符串的格式化,下面来看一下 数字的格式化:
通常浮点数(float)是通过f;整数是通过d来进行的格式化。实例如下:
>>> string="名字是:{0},专业代码是{1:d},成绩是:{2:.1f}"
>>> string.format("宋宝宝",912,425.50)
'名字是:宋宝宝,专业代码是912,成绩是:425.5'
>>>
下面进行一下 常见格式的大汇总:
- 保留小数点后的几位有效数字 {:.2f} 保留小数点后两位
>>> "{0:.2f}".format(3.1415926)
'3.14'
>>> "{0:.4f}".format(3.1415926)
'3.1416' #看来做的是 一个四舍五入
>>>
- 带符号的保留小数点后的几位有效数字 {:+.2f} 带符号保留小数点后2位
>>> "{0:+.2f}".format(3.1415926)
'+3.14'
>>> "{0:-.2f}".format(3.1415926)#后面是整数 依旧输出正数
'3.14'
>>> "{0:-.2f}".format(-3.1415926)
'-3.14'
>>> "{0:+.2f}".format(-3.1415926)
'-3.14'
>>> "{0:.2f}".format(-3.1415926)
'-3.14'
>>>
- 不带小数 {:.0f} 不带小数
>>> "{0:.0f}".format(3.1415926)
'3'
>>>
- 数字补零 {:0>2d} 填充到左边,宽度为2
>>> "{:0>2d}".format(3)
'03'
>>>
- 数字补x *等 {:x<4d} 数字补x 填充到右边 宽度为4
>>> "{0:x<4d}".format(12)
'12xx'
>>> "{0:*<4d}".format(12)
'12**'
>>> "{0:x^4d}".format(12)
'x12x'
>>> "{0:->4d}".format(12)
'--12'
>>>
- 以逗号分隔的数字格式 {:,}
>>> "{0:,}".format(10000000)
'10,000,000'
>>>
- 百分比格式 {:.2%} 保留2位小数的百分比
>>> "{0:.3%}".format(0.375777)
'37.578%'
>>>
- 指数 记法格式 {:.2e} 小数点后2位的指数
>>> "{0:.2e}".format(1200000000)
'1.20e+09'
>>> "{0:.2e}".format(1239000000)
'1.24e+09'
>>>
- 三种对齐 默认是右对齐
>>> "{0:6d}".format(12) #默认是右对齐 以空格填充 宽度是6
' 12'
>>> "{0:*>6d}".format(12) #右对齐 是左填充的
'****12'
>>> "{0:*^6d}".format(12)
'**12**'
>>> "{0:*<6d}".format(12) #左对齐 是右填充的
'12****'
>>>
2020年4月4日15:03:21