页面元素定位的方式 主要有8种 分类如下
元素属性定位 有 id , name , class_name
元素标签定位 tag_name
链接定位 link_text , partial_link_text
选择器定位 xpath , css_selector
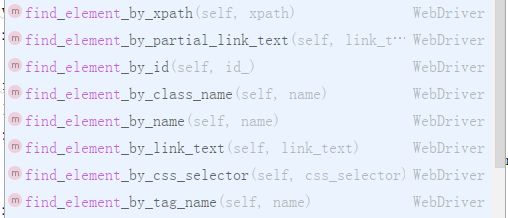
因为很多时候只通过 id , name , class_name ,tag_name , link_text , partial_link_text 是无法定位到某些元素的 此时就需要借助 xpath 和css_selector
定位方式 难点和重点也就是xpath和css_selector 这两种其实只要会一种即可 。css_selector 这种方式这里就不深入讲解,有兴趣的可以专门去学习下。
xpath 的定位需要对 xml/html 有一定的了解
1.斜杠 / 的用法和平时选择路径(绝对路径)用法相同 例如: /xxx 就是选取根节点 /xxx/yyy 就是通过绝对路径选择到元素
2.双斜杆 // 的用法和平时路径(相对路径)用法相同 例如 //xxx 就是选取整个页面的xxx元素
1和2是可以混合使用的 例如 //xxx/yyy 选取的就是xxx元素下的yyy元素
3. 点 . 选取当前节点的父元素节点
4.点点 .. 选取的是父元素的地址
5. @ 的运用 例如//xxx[@id] 选取的就是xxx元素下有id属性得元素 ,//xxx[@id=yyy] 选取的就是xxx下 id为yyy的元素
6.以上这些如果有多个值的时候 默认返回的都是第一个值 例如 通过 /html/.../input 获取到有多个值 那么返回的是第一个值 要获取第二个值可用 /html/.../input[2]
下面举例几个
‘//frame//input‘ 默认获取的是第一个值
‘//frame//input[2]’ 获取的是第二个
‘//input[@id] ‘含有id的
‘//input[not(@id)] ’ 不含id的
‘//input[not(@id=“name”)]’ id为name的
‘//*’ 查找整个文档的所有元素
‘//*[(count(input))=2]’ input的个数为2的标签
...
这种例子很多 还要自己慢慢深入了解
8中定位模式 还有elements的这种
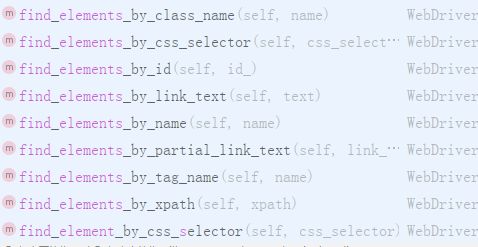
elements 这种返回的是一个列表 所有要利用索引获取到元素 例如 find_elements_by_id(‘xxx’) 那么他返回的就是id为xxx的所有元素 要获取值必须加上索引