SQL学习笔记
https://blog.csdn.net/moguxiansheng1106/article/details/44258499
- Having与where的区别:https://baijiahao.baidu.com/s?id=1600513158500665764&wfr=spider&for=pc
- LEFT JOIN 关键字从左表(Websites)返回所有的行,即使右表(access_log)中没有匹配。
- 好评率是会员对平台评价的重要指标。现在需要统计2018年1月1日到2018年1月31日,用户’小明’提交的母婴类目"花王"品牌的好评率(好评率=“好评”评价量/总评价量):
用户评价详情表:a
字段:id(评价id,主键),create_time(评价创建时间,格式’2017-01-01’), user_name(用户名称),goods_id(商品id,外键) ,
sub_time(评价提交时间,格式’2017-01-01 23:10:32’),sat_name(好评率类型,包含:“好评”、“中评”、“差评”)
商品详情表:
b 字段:good_id(商品id,主键),bu_name(商品类目), brand_name(品牌名称)
SELECT SUM(CASE
WHEN sat_time = '好评' THEN 1
ELSE 0
END)/COUNT(sat_time) AS "好评率"
FROM a JOIN b ON a.good_id = b.good_id
WHERE user_name = '小明' AND sub_time BETWEEN ('2017-1-1') AND ('2017-1-31') AND b.bu_name = '母婴' AND b.brand_name ='花王'- 考拉运营"小明"负责多个品牌的销售业绩,请完成:
(1)请统计小明负责的各个品牌,在2017年销售最高的3天,及对应的销售额。
销售表 a:
字段:logday(日期,主键组),SKU_ID(商品SKU,主键组),sale_amt(销售额)
商品基础信息表 b:
字段:SKU_ID(商品SKU,主键),bu_name(商品类目),brand_name(品牌名称),user_name(运营负责人名称)
(2)请统计小明负责的各个品牌,在2017年连续3天增长超过50%的日期,及对应的销售额。
(1)
select * from
(select b.brand_name, a.logday,row_number() OVER (PARTITION BY b.brand_name ORDER BY a.sale_amt desc) as num
from a join b on a.sku_id = b.sku_id
where year(a.logday)='2017' and b.user_name = '小明')c
where c.num <= 5
group by b.brand_name(2)两表合并c->按品牌和时间分组,计算对应的销售额->前一天表和当天表按品牌合并->计算每个品牌在每一天的增长率->(未实现)
https://bbs.csdn.net/topics/392421965?page=1
create table a(
SKU_ID INT NOT NULL,
logday datetime NOT NULL,
sale_amt INT NOT NULL);
insert into a values (1,'2019-06-01',100);
insert into a values (2,'2019-06-01',200);
insert into a values (1,'2019-06-01',100);
insert into a values (4,'2019-06-01',300);
insert into a values (1,'2019-06-02',200);
insert into a values (2,'2019-06-02',150);
insert into a values (3,'2019-06-02',200);
insert into a values (4,'2019-06-02',100);
insert into a values (1,'2019-06-03',400);
insert into a values (3,'2019-06-03',80);
insert into a values (4,'2019-06-03',190);
insert into a values (4,'2019-06-04',390);
insert into a values (3,'2019-06-04',150);
insert into a values (1,'2019-06-05',150);
insert into a values (2,'2019-06-05',300);
insert into a values (3,'2019-06-05',200);
insert into a values (4,'2019-06-05',180);
insert into a values (2,'2019-06-05',300);
insert into a values (2,'2019-06-06',250);
insert into a values (2,'2019-06-06',350);
create table b(
SKU_ID INT NOT NULL,
brand_name varchar(12) NOT NULL,
user_name varchar(12) NOT NULL
);
insert into b values (1,'A','xm');
insert into b values (2,'A','xm');
insert into b values (3,'B','xm');
insert into b values (4,'B','xm');with cte_1
as
(
select A.logday,B.brand_name, sum(A.sale_amt)as sum_amt
from A
join B on A.SKU_ID=B.SKU_ID
where user_name='xm'
group by A.logday,B.brand_name),
cte_2
as
(select logday, brand_name
from cte_1
)
select * from cte_2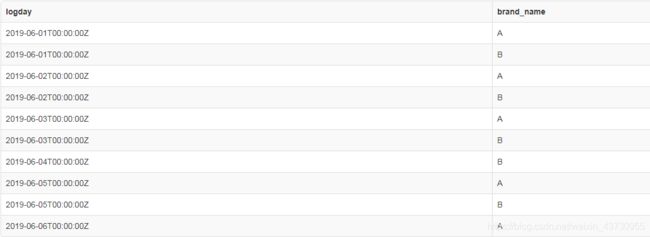
- with as用法
WITH AS短语,也叫做子查询部分(subquery factoring),如果WITH AS短语所定义的表名被调用两次以上,则优化器会自动将WITH AS短语所获取的数据放入一个TEMP表里,如果只是被调用一次,则不会。将WITH AS短语里的数据放入一个全局临时表里。很多查询通过这种方法都可以提高速度。
with cr as( select CountryRegionCode from person);
select * from cr;
https://www.cnblogs.com/firstdream/p/7356481.html
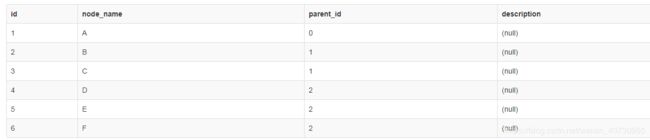
表有三个字段:id、node_name、parent_id。这个表中保存了一个树型结构,分三层:省、市、区。其中id表示当前省、市或区的id号、node_name表示名称、parent_id表示节点的父节点的id。现在有一个需求,要查询出某个省下面的所有市和区(查询结果包含省)
SQL SERVER
create table t_tree
(
id int not null
,node_name varchar(50) not null
,parent_id int not null
,[description] varchar(255) null
)
insert into t_tree
(
id, node_name, parent_id
)
values
(1,'A',0),
(2 ,'B' ,1),
(3 ,'C' ,1),
(4 ,'D' ,2),
(5 ,'E' ,2),
(6 ,'F' ,2),
(7 ,'G' ,8)with
district as
(
select * from t_tree where node_name= 'A'
union all
select a.* from t_tree a, district b
where a.parent_id = b.id
)
select * from districthttps://www.w3school.com.cn/sql/sql_union.asp
6. INNER JOIN
INNER JOIN 与 JOIN 是相同的。INNER JOIN 关键字在表中存在至少一个匹配时返回行。
7. LEFT OUTER JOIN
left join 是 left outer join 的简写,两者含义一样的。一个LEFT OUTER JOIN包含“左”表中的所有记录,即使它与在此连接中指定的“右”表并不存在任何匹配。
8. PRIMARY KEY 约束
PRIMARY KEY 约束唯一标识数据库表中的每条记录。
主键必须包含唯一的值。
主键列不能包含 NULL 值。
每个表都应该有一个主键,并且每个表只能有一个主键。在表中,此主键可以包含单个或多个列(字段)。
9. 创建sql表
MYSQL5.6
-- borrowed from https://stackoverflow.com/q/7745609/808921
CREATE TABLE IF NOT EXISTS `docs` (
`id` int(6) unsigned NOT NULL,
`rev` int(3) unsigned NOT NULL,
`content` varchar(200) NOT NULL,
PRIMARY KEY (`id`,`rev`)
) DEFAULT CHARSET=utf8;
INSERT INTO `docs` (`id`, `rev`, `content`) VALUES
('1', '1', 'The earth is flat'),
('2', '1', 'One hundred angels can dance on the head of a pin'),
('1', '2', 'The earth is flat and rests on a bull\'s horn'),
('1', '3', 'The earth is like a ball.');-
sql server中的real数据类型
float 和 real 数据类型被称为近似数据类型。近似数值数据类型并不存储为许多数字指定的精确值,它们只储存这些值的最近似值。float 和 real 的使用遵循有关近似数值数据类型的 IEEE 754 规范。IEEE 754 规范提供四种舍入模式:舍入到最近、向上舍入、向下舍入以及舍入到零。Microsoft SQL Server 2005 使用向上舍入。
decimal(numeric ) 用于精确存储数值(整型)
money 用于精确存储数值(浮点型)
float 和 real 不能精确存储数值 -
利用SQL创建表时的 NOT NULL 约束:
CREATE TABLE test
(
age int(10),
sex varchar(20),
name varchar(20) NOT NULL
)NOT NULL 约束强制列不接受 NULL 值。
约束,就是限制某些东西不能干什么,或者说不能是什么样子。
- ord1表 user_id,ord_id,ord_amt,create_time,act_user
act1表 act_id,user_id,create_time
第一问:每个活动类型所有用户的总订单额,订单数
第二问:每个活动类型活动开始时间(第一个用户报名的时间)到今天,平均每天产生的订单数
创建ord1表, act1表 (MY SQL/ MS SQL SERVER)
create table ord1(
user_id INT NOT NULL,
ord_id INT NOT NULL,
ord_amt REAL NOT NULL,
create_time datetime NOT NULL
);
INSERT INTO ord1 VALUES(1,10,100,'2019-07-02 10:00:01');
INSERT INTO ord1 VALUES(1,11,120,'2019-07-01 11:00:01');
INSERT INTO ord1 VALUES(1,11,120,'2019-07-02 11:00:01');
INSERT INTO ord1 VALUES(1,12,150,'2019-07-03 10:00:01');
INSERT INTO ord1 VALUES(2,13,200,'2019-07-02 10:00:01');
INSERT INTO ord1 VALUES(2,14,300,'2019-07-05 11:00:01');
INSERT INTO ord1 VALUES(3,15,100,'2019-07-02 10:00:01');
INSERT INTO ord1 VALUES(3,16,300,'2019-07-03 10:00:01');
INSERT INTO ord1 VALUES(4,17,200,'2019-07-02 10:00:01');
INSERT INTO ord1 VALUES(5,18,100,'2019-07-02 10:00:01');
create table act1(
act_id VARCHAR(15) NOT NULL,
user_id INT NOT NULL,
create_time datetime NOT NULL
);
INSERT INTO act1 VALUES('A',1,'2019-07-02 10:00:01');
INSERT INTO act1 VALUES('A',2,'2019-07-02 11:00:01');
INSERT INTO act1 VALUES('A',3,'2019-07-02 10:00:01');
INSERT INTO act1 VALUES('B',4,'2019-07-02 10:00:01');
INSERT INTO act1 VALUES('B',5,'2019-07-02 10:00:01');
INSERT INTO act1 VALUES('C',6,'2019-07-02 10:00:01');统计每个活动类型所有用户的总订单额,订单数
select
b.act_id
,count(ord_id)
,sum(ord_amt)
from ord1 a
join act1 b
on a.user_id = b.user_id
where a.create_time >= b.create_time
group by b.act_id;每个活动类型活动开始时间(第一个用户报名的时间)到今天,平均每天产生的订单数
select
b.act_id
,sum(ord_amt)/DATEDIFF(day, min(a.create_time),'2019-7-28') as avg
from ord1 a
left join act1 b
on a.user_id = b.user_id
where a.create_time >= b.create_time
group by b.act_id;- log表(userid,opr_type,log_time)
第一问:每天的访客数量
第二问:每天执行opr_type=A到B,先A后B,而且必须紧紧挨着的用户数
创建数据表
create table logtable(
user_id INT NOT NULL,
opr_type VARCHAR(15) NOT NULL,
log_time datetime NOT NULL);
insert into logtable values (1,'A','2019-06-01 10:10:01');
insert into logtable values (1,'B','2019-06-01 10:11:01');
insert into logtable values (1,'C','2019-06-01 10:12:01');
insert into logtable values (9,'A','2019-06-01 10:13:01');
insert into logtable values (9,'B','2019-06-01 10:14:01');
insert into logtable values (2,'A','2019-06-01 10:10:02');
insert into logtable values (2,'C','2019-06-01 10:11:01');
insert into logtable values (2,'B','2019-06-01 10:12:01');
insert into logtable values (3,'A','2019-06-02 10:10:01');
insert into logtable values (3,'B','2019-06-02 10:11:01');
insert into logtable values (4,'A','2019-06-03 10:10:01');
insert into logtable values (4,'C','2019-06-03 10:11:01');
insert into logtable values (4,'B','2019-06-03 10:12:01');每天的访客数量
select date_format(log_time,'%y-%m-%d')
,count(distinct user_id)
from logtable
group by date_format(log_time,'%y-%m-%d');每天执行opr_type=A到B,先A后B,而且必须紧紧挨着的用户数
思路:增加新标签usertime(同user_id下大于当前log_id的注册时间的最小值), 并将其加入原数据表中;再通过特定标签进行右连接以保证A到B,先A后B,而且必须紧紧挨着的。最后通过注册时间进行分组,利用count()计算符合条件的用户数。
select date_format(t1.log_time,'%y-%m-%d')
,count(distinct t1.user_id)
from (
select *,(select min(log_time) from logtable l2 where l2.user_id = l1.user_id and l2.log_time > l1.log_time) as usetime
from logtable as l1
) as t1
right join logtable as t2
on t2.user_id=t1.user_id
where t2.opr_type = 'B'
and t1.opr_type = 'A'
and t2.log_time = t1.usetime
group by date_format(t1.log_time,'%y-%m-%d');
注:usertime是同user_id下大于当前log_id的注册时间的最小值
- log表(userid,opr_type, log_time)
问:每天新增的用户数量,这些用户第2天的回访数。
create table logtable(
user_id INT NOT NULL,
opr_type VARCHAR(15) NOT NULL,
log_time datetime NOT NULL);
insert into logtable values (1,'A','2019-06-01 10:10:01');
insert into logtable values (1,'B','2019-06-01 10:11:01');
insert into logtable values (1,'C','2019-06-01 10:12:01');
insert into logtable values (9,'A','2019-06-01 10:13:01');
insert into logtable values (9,'B','2019-06-01 10:14:01');
insert into logtable values (2,'A','2019-06-01 10:10:02');
insert into logtable values (2,'C','2019-06-01 10:11:01');
insert into logtable values (2,'B','2019-06-01 10:12:01');
insert into logtable values (3,'A','2019-06-02 10:10:01');
insert into logtable values (3,'B','2019-06-02 10:11:01');
insert into logtable values (4,'A','2019-06-03 10:10:01');
insert into logtable values (4,'C','2019-06-03 10:11:01');
insert into logtable values (4,'B','2019-06-03 10:12:01');
insert into logtable values (1,'A','2019-06-02 10:10:01');
insert into logtable values (1,'B','2019-06-02 10:11:01');
insert into logtable values (1,'C','2019-06-03 10:12:01');
insert into logtable values (9,'A','2019-06-02 10:13:01');
insert into logtable values (9,'B','2019-06-03 10:14:01');
insert into logtable values (2,'A','2019-06-03 10:10:02');
insert into logtable values (2,'C','2019-06-03 10:11:01');
insert into logtable values (2,'B','2019-06-03 10:12:01');
insert into logtable values (3,'A','2019-06-03 10:10:01');
insert into logtable values (3,'B','2019-06-05 10:11:01');
insert into logtable values (4,'A','2019-06-07 10:10:01');
insert into logtable values (4,'C','2019-06-05 10:11:01');
insert into logtable values (4,'B','2019-06-06 10:12:01');select date_format(t1.first_time,'%y-%m-%d')
,count(distinct case when t1.log_time = t1.first_time then user_id else null end) as aa
,count(distinct case when date_format(t1.first_time,'%y-%m-%d') = date_format(date_sub(t1.log_time,interval 1 day),'%y-%m-%d') then user_id else null end ) as bb
from(
select *,(select min(log_time) from logtable l2 where l1.user_id = l2.user_id) as first_time
from logtable l1) as t1
group by date_format(t1.first_time,'%y-%m-%d');https://blog.csdn.net/kylin_learn/article/details/97616259
- 用一条SQL 语句 查询出每门课都大于80 分的学生姓名
name kecheng fenshu
张三 语文 81
张三 数学 75
李四 语文 76
李四 数学 90
王五 语文 81
王五 数学 100
王五 英语 90
select distinct name from table where name not in (select distinct name from table where fenshu<=80)
select name from table group by name having min(fenshu)>80- 学生表 如下:
自动编号 学号 姓名 课程编号 课程名称 分数
1 2005001 张三 0001 数学 69
2 2005002 李四 0001 数学 89
3 2005001 张三 0001 数学 69
删除除了自动编号不同, 其他都相同的学生冗余信息
delete from tablename where 自动编号 not in(select min( 自动编号) from tablename group by学号, 姓名, 课程编号, 课程名称, 分数)- 一个叫 team 的表,里面只有一个字段name, 一共有4 条纪录,分别是a,b,c,d, 对应四个球队,现在四个球队进行比赛,用一条sql 语句显示所有可能的比赛组合.
select a.name, b.name
from team a, team b
where a.name < b.name- 怎么把这样一个表儿
year month amount
1991 1 1.1
1991 2 1.2
1991 3 1.3
1991 4 1.4
1992 1 2.1
1992 2 2.2
1992 3 2.3
1992 4 2.4
查成这样一个结果
year m1 m2 m3 m4
1991 1.1 1.2 1.3 1.4
1992 2.1 2.2 2.3 2.4
create table logtable(
year INT NOT NULL,
mouth INT NOT NULL,
amount FLOAT(2,1) NOT NULL);
insert into logtable values (1991,1,1.1);
insert into logtable values (1991,2,1.2);
insert into logtable values (1991,3,1.3);
insert into logtable values (1991,4,1.4);
insert into logtable values (1992,1,2.1);
insert into logtable values (1992,2,2.2);
insert into logtable values (1992,3,2.3);
insert into logtable values (1992,4,2.4);select year,
(select amount from logtable m where mouth=1 and m.year=logtable.year) as m1,
(select amount from logtable m where mouth=2 and m.year=logtable.year) as m2,
(select amount from logtable m where mouth=3 and m.year=logtable.year) as m3,
(select amount from logtable m where mouth=4 and m.year=logtable.year) as m4
from logtable group by yearselect logtable.year,sum(case when logtable.mouth = 1 then 1.1 else 0 end)as m1,
sum(case when logtable.mouth = 2 then 1.2 else 0 end)as m2,
sum(case when logtable.mouth = 3 then 1.3 else 0 end)as m3,
sum(case when logtable.mouth = 4 then 1.4 else 0 end)as m4
from logtable
group by logtable.year- 如何用sql语句复制一张表
1)复制表结构及数据到新表
CREATE TABLE 新表 SELECT * FROM 旧表
2)只复制表结构到新表
CREATE TABLE 新表 SELECT * FROM 旧表 WHERE 1=2
3)复制旧表的数据到新表(假设两个表结构一样)
INSERT INTO 新表 SELECT * FROM 旧表
4)复制旧表的数据到新表(假设两个表结构不一样)
INSERT INTO 新表(字段1,字段2,…) SELECT 字段1,字段2,… FROM 旧表 - 显示文章、提交人和最后回复时间
select a.title,a.username,max(a.adddate)from table a
group by a.title,a.username- 说明:外连接查询( 表名1 :a表名2 :b)
select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUTER JOIN b ON a.a = b.c- 日程安排提前五分钟提醒
select * from 日程安排 where datediff(minute,getdate(),开始时间)>5- 删除B表中不存在于A表中的id的相关记录
DELETE FROM
B
WHERE NOT EXISTS(
SELECT 1
FROM
A
WHERE
B.id=A.id
)sql语句查询中exists中为什么要用select 1?
如果有查询结果,查询结果就会全部被1替代(当不需要知道结果是什么,只需要知道有没有结果的时候会这样用),可以提高语句的运行效率,在大数据量的情况下,提升效果非常明显。
以select * from A where exists(select * from B where A.a=B.a)为例,
exists表示, 对于A中的每一个记录, 如果在表B中有记录,其属性a的值与表A这个记录的属性a的值相同,则表A的这个记录是符合条件的记录,
如果是NOT exists, 则表示如果表B中没有记录能与表A这个记录连接, 则表A的这个记录是符合条件的记录。
- 已知存在以下表
S 表保存着学生关系,有两列,其中SNO 为学号,SNAME 为姓名
C 表保存着课程关系,有三列,其中CNO 为课程号,CNAME 为课程名,CTEACHER 为老师
SC表保存着选课关系,有三列,其中SNO为学号,CNO为课程号,SCORE 为成绩
1) 找出没有选“小易”老师课程的所有学生姓名
2)列出有三门(包括三门)以上课程分数>90的学生姓名及其平均成绩
select sname from s where sno not in
(select distinct sno from sc join c on sc.cno = c.cno where c.cteacher='小易');select s.sname, avg(sc.score) as avg
from s join sc
on s.sno = sc.sno
where sc.score > 90
group by s.sname having count(*) > 2;- sql中sign(x)
符号函数。若x>0,则返回1;若x=0,则返回0;若x<0,则返回-1。 - decode(oracle可以编译)
decode(条件,值1,翻译值1,值2,翻译值2,…值n,翻译值n,缺省值)的理解如下:
if (条件== 值1)
then
return ( 翻译值1)
elsif (条件 == 值2)
then
return(翻译值2)
…
elsif (条件==值n)
then
return(翻译值n)
else
return(缺省值)
end if
注:其中缺省值可以是你要选择的column name 本身,也可以是你想定义的其他值,比如Other等; - 原表:
courseid coursename score
1 Java 70
2 oracle 90
3 xml 40
4 jsp 30
5 servlet 80
为了便于阅读, 查询此表后的结果显式如下( 及格分数为60):
courseid coursename score mark
1 Java 70 pass
2 oracle 90 pass
3 xml 40 fail
4 jsp 30 fail
5 servlet 80 pass
create table logtable(
courseid INT NOT NULL,
coursename VARCHAR(10) NOT NULL,
score INT NULL);
insert into logtable values (1,'JAVA',70);
insert into logtable values (2,'ORACLE',90);
insert into logtable values (3,'XML',40);
insert into logtable values (4,'JSP',30);
insert into logtable values (5,'SERVELET',80);(mysql, ms sql server)
select courseid, coursename ,score ,(case when score < 60 then 'fail' else 'pass' end)as mark from logtable;(oracle)
select courseid, coursename, score, decode(sign(score-60),-1,'fail','pass') as mark from course- isnull()函数的使用
create table testtable1(
ID INT NOT NULL,
department VARCHAR(12) NOT NULL);
insert into testtable1 values(1,'A');
insert into testtable1 values(2,'B');
insert into testtable1 values(3,'C');
create table testtable2
(
dptID INT NOT NULL,
name VARCHAR(12) NOT NULL
);
insert into testtable2 values(1,'D');
insert into testtable2 values(1,'E');
insert into testtable2 values(2,'F');
insert into testtable2 values(3,'G');
insert into testtable2 values(4,'H');
SELECT testtable2.* , ISNULL(department,'I')
FROM testtable1 right join testtable2 on testtable2.dptID = testtable1.ID- 如程序中不使用sum,不符合sql语法规则(group by语法规则),报错
create table testtable1(
p_ID INT NOT NULL,
p_Num INT NOT NULL,
s_id VARCHAR(12) NOT NULL);
insert into testtable1 values(1,10,'01');
insert into testtable1 values(1,12,'02');
insert into testtable1 values(2,8,',01');
insert into testtable1 values(3,11,'01');
insert into testtable1 values(3,8,'03');select p_id ,
sum(case when s_id='01' then p_num else 0 end) as s1_id
,sum(case when s_id='02' then p_num else 0 end) as s2_id
,sum(case when s_id='03' then p_num else 0 end) as s3_id
from testtable1 group by p_id
- 为管理业务培训信息,建立3个表:
S(S#,SN,SD,SA)S#,SN,SD,SA分别代表学号,学员姓名,所属单位,学员年龄
C(C#,CN)C#,CN分别代表课程编号,课程名称
SC(S#,C#,G) S#,C#,G分别代表学号,所选的课程编号,学习成绩
(1) 使用标准SQL嵌套语句查询选修课程名称为’税收基础’的学员学号和姓名?
答案:select s# ,sn from s where s# in(select S# from c,sc where c.c#=sc.c# and cn=’税收基础’)
MS SQL SERVER
create table logtable1(
title VARCHAR NOT NULL,
user_id INT NOT NULL,
log_time datetime NOT NULL);
insert into logtable1 values ('A',1,'2019-06-01 ');
insert into logtable1 values ('A',2,'2019-06-02 ');
insert into logtable1 values ('A',3,'2019-06-03 ');
insert into logtable1 values ('B',4,'2019-06-02 ');
insert into logtable1 values ('B',5,'2019-06-07 ');
insert into logtable1 values ('B',6,'2019-06-05 ');
insert into logtable1 values ('B',7,'2019-06-03 ');
create table logtable2(
title VARCHAR NOT NULL,
user_id INT NOT NULL,
name varchar(12) NOT NULL);
insert into logtable2 values ('A',7,'a ');
insert into logtable2 values ('A',6,'b ');
insert into logtable2 values ('A',5,'c ');
insert into logtable2 values ('B',4,'c ');
insert into logtable2 values ('B',3,'e');
insert into logtable2 values ('B',2,'d ');
insert into logtable2 values ('B',1,'e');select log_time from logtable1,logtable2 where logtable1.user_id =logtable2.user_id and name='c'(2) 使用标准SQL嵌套语句查询选修课程编号为’C2’的学员姓名和所属单位?
答:select sn,sd from s,sc where s.s#=sc.s# and sc.c#=’c2’
(3) 使用标准SQL嵌套语句查询不选修课程编号为’C5’的学员姓名和所属单位?
答:select sn,sd from s where s# not in(select s# from sc where c#=’c5’)
(4)查询选修了课程的学员人数
答:select count(distinct s#) as number from sc
select number = count(distinct s#) from sc
(5) 查询选修课程超过5门的学员学号和所属单位?
答:select sn,sd from s where s# in(select s# from sc group by s# having count(distinct c#)>5)
31. 查询表A中存在ID重复三次以上的记录,完整的查询语句如下:
select *
from A
where id in(select ID from A group by id having count(id)>3)- 当不使用聚合函数时,GROUP BY的结果是分组内容中的第一组查询结果。(mysql可以通过,server不能通过)HAVING 子句可以让我们筛选通过 GROUP BY 分组后的各组数据。where子句不能包含聚合函数。
https://blog.csdn.net/liitdar/article/details/85272035
根据要求写出SQL
表A结构如下:
Member_ID(用户的ID,字符型)
Log_time(用户访问页面时间,日期型(只有一天的数据))
URL(访问的页面地址,字符型)
要求:提取出每个用户访问的第一个URL(按时间最早),形成一个新表(新表名为B,表结构和表A一致)
create table B as select Member_ID, min(Log_time), URL from A group by Member_ID- 通过关联表的方式实现A表中去除B表异常交易(保留A中的字段即可)
select * from A where trade_no not in (select trade_no from B)- SQL执行顺序(1)from (2) join(3) on (4) where (5)group by(6) avg,sum… (组合函数)(7)having (8) select (9) distinct (10) order by
- 以逆字母顺序显示公司名称,并以数字顺序显示顺序号:
SELECT Company, OrderNumber FROM Orders ORDER BY Company DESC, OrderNumber ASCgroupby分组了以后,order需要是分组的列
https://developer.aliyun.com/ask/82363?spm=a2c6h.13159736
一张成绩表有如下字段,班级ID,英语成绩,数据成绩,语文成绩,查询出 每个班级英语成绩最高的前两名的记录。
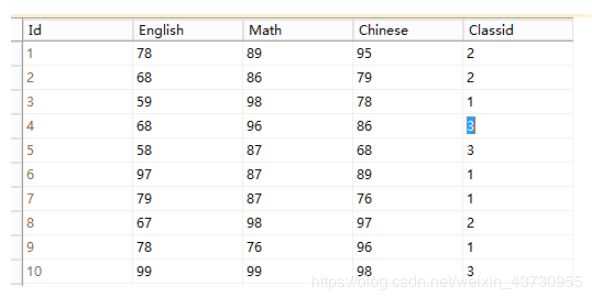
方法一
SELECT * FROM CJ m
where(
select COUNT(*) from CJ n
where m.Classid = n.Classid and n.English > m.English)<2
order by Classid, English desc方法二(官方说最好的方法)
select a.Classid,a.English from
(select Classid,English,row_number() over(partition by Classid order by English desc) as n
from CJ) a
where n<=2row_number() OVER (PARTITION BY COL1 ORDER BY COL2) 表示根据COL1分组,在分组内部根据 COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的)
https://www.cnblogs.com/hxfcodelife/p/10226934.html
- SQL 可与数据库程序协同工作,比如 MS Access、DB2、Informix、MS SQL Server、Oracle、Sybase 以及其他数据库系统。
不幸地是,存在着很多不同版本的 SQL 语言,但是为了与 ANSI 标准相兼容,它们必须以相似的方式共同地来支持一些主要的关键词(比如 SELECT、UPDATE、DELETE、INSERT、WHERE 等等)。 - 如何用SQL做留存率分析
分析步骤:
1)从数据库中提取出user_id和login_time并排序
2)增加一列first_day,存储每个用户ID最早登录时间
3)用登录时间-最早登录时间得到一列by_day
4)然后从表中提取数据,找到first_day对应的by_day列中0有多少个,1有多少个,一直到7以上。
5)根据此表,就很容易计算出每天引流的留存率。
SELECT
first_day,
sum(case when by_day = 0 then 1 else 0 end) day_0,
sum(case when by_day = 1 then 1 else 0 end) day_1,
sum(case when by_day = 2 then 1 else 0 end) day_2,
sum(case when by_day = 3 then 1 else 0 end) day_3,
sum(case when by_day = 4 then 1 else 0 end) day_4,
sum(case when by_day = 5 then 1 else 0 end) day_5,
sum(case when by_day = 6 then 1 else 0 end) day_6,
sum(case when by_day >= 7 then 1 else 0 end) day_7plus
FROM
(SELECT
user_id,
login_time,
first_day,
DATEDIFF(day,first_day,login_time) as by_day
FROM
(
SELECT
b.user_id,
b.login_time,
c.first_day
FROM
(
SELECT
user_id,
str_to_date(login_time,'%Y/%m/%d') login_time
FROM user_info
GROUP BY 1,2) b
LEFT JOIN
(
SELECT
user_id,
min(login_time) first_day
FROM
(
select
user_id,
str_to_date(login_time,'%Y/%m/%d') login_time
FROM
user_info
group by 1,2
) a
group by 1
) c
on b.user_id = c.user_id
order by 1,2
) e
order by 1,2
) f
group by first_day
order by 1https://www.jianshu.com/p/be2cb8880df6
注:order by1,2在mysql数据库系统中表示先对第一列排序,如果第一列值相同则按第二列排序。
MYSQL
create table testtable1(
p_ID INT NOT NULL,
p_Num INT NOT NULL,
s_id VARCHAR(12) NOT NULL);
insert into testtable1 values(1,10,'01');
insert into testtable1 values(1,12,'02');
insert into testtable1 values(2,8,',01');
insert into testtable1 values(3,11,'01');
insert into testtable1 values(3,8,'03');select p_ID,p_Num from testtable1 group by 1,2;
- 求众数,中位数(sql server)
1)众数应用场合:有极端值,有某些数据多次重复出现时
求众数
CREATE TABLE graduates (
name varchar(255) ,
income int
)
go
INSERT INTO graduates VALUES ('桑普森', '400000');
INSERT INTO graduates VALUES ('迈克', '30000');
INSERT INTO graduates VALUES ('怀特', '20000');
INSERT INTO graduates VALUES ('阿诺德', '20000');
INSERT INTO graduates VALUES ('史密斯', '20000');
INSERT INTO graduates VALUES ('劳伦斯', '15000');
INSERT INTO graduates VALUES ('哈德逊', '15000');
INSERT INTO graduates VALUES ('肯特', '10000');
INSERT INTO graduates VALUES ('贝克', '10000');
INSERT INTO graduates VALUES ('斯科特', '10000');通过count(*)求每个数出现的次数->通过max()求出现的最多次数->通过having过滤出出现次数最多的income
select income,count(*) cnt
from graduates
group by income
having count(*) >= (
select max(cnt) from (select count(*) cnt from graduates group by income) tmp注:GO语句把程序分成一个个代码块,即使一个代码块执行错误,它后面的代码块仍然会执行。
2)有极端值,且无某数据重复出现多次的情况下集中趋势的刻画。
求中位数
select AVG(DISTINCT income)
from (
select T1.income from graduates T1,graduates T2
group by T1.income
having sum(case when T2.income >= T1.income then 1 else 0 end) >= count(*)/2
and sum(case when T2.income <= T1.income then 1 else 0 end) >= count(*)/2
) tmp
go注:
平均数应用场合:没有极端值的情况下数据集中趋势的刻画。
- 利用SQL进行用户消费行为分析
在MySQL环境下,对userinfo和orderinfo两个表格进行用户消费行为分析。userinfo和orderinfo数据信息如下:
userinfo 客户信息表
userId 客户id
sex 性别
birth 出生年月日
orderinfo 订单信息表:
orderId 订单序号
userId 客户id
isPaid 是否支付
price 商品价格
paidTime 支付时间
1)统计不同月份的下单人数
select month(paidTime) ,count(distinct userId) from data.orderinfo
where isPaid = '已支付'
group by month(paidTime)2)统计用户三月份的回购率和复购率
复购率指当月消费者中消费次数多于一次的人数占比
回购率指本月消费者中在下月再次消费的占比
复购率:
先统计三月份每个购买者的购买次数,作为一个子查询返回,
外层使用count+if函数统计大于一次消费的购买者人数,将其与总人数相除,即可得到复购率。
select count(ct) ,count(if(ct>1,1,null)),count(if(ct>1,1,null))/count(ct) as ratio
from ( select userId,count(userId) as ct from data.orderinfo
where isPaid = '已支付'
and month(paidTime) = 3
group by userId) t回购率:
根据用户id和月份相差访问月份相差一个月使用左连接,统计在本月购买的用户数量,本月购买并在下月继续购买的客户数量,进而计算回购率。
select t1.m,count(t1.m),count(t2.m),count(t2.m)/count(t1.m) from (
select userId,date_format(paidTime,'%Y-%m-01') as m from data.orderinfo
where isPaid = '已支付'
group by userId,date_format(paidTime,'%Y-%m-01')) t1
left join (
select userId,date_format(paidTime,'%Y-%m-01') as m from data.orderinfo
where isPaid = '已支付'
group by userId,date_format(paidTime,'%Y-%m-01')) t2
on t1.userId = t2.userId and t1.m = date_sub(t2.m,interval 1 month)
group by t1.m 3)统计男女用户平均消费频次
通过内连接过滤空值,连接两个表,通过count统计单个购买者的购买次数,
根据性别分组,统计均值,得到男女平均消费频次。
select sex,avg(ct) from (
select o.userId,sex,count(1) as ct from data.orderinfo o
inner join (
select * from data.userinfo
where sex!= '') t
on o.userId = t.userId
group by userId) t2
group by sexcount(1) 与 count( * ) 都表示对全部数据行的查询, 在统计结果的时候,不会忽略列值为NULL 。在字段较多、数据量较大的情况下,使用count(1) 要明显比 count( * ) 更加高效。
4)统计多次消费的用户,第一次和最后一次消费间隔是多少
提取多次消费用户,用datediff计算max和min的差值
select userId,max(paidTime),min(paidTime),
datediff(day,min(paidTime),max(paidTime)) from data.orderinfo
where isPaid = '已支付'
group by userId having count(1) > 1 5)统计不同年龄段用户消费频次是否有差异
先计算用户所属的不同年龄段,并利用内连接使之加入表中,然后不同用户id下的消费频次,最后根据年龄段分组,统计不同年龄段下用户的平均消费频次。
CEIL(N):上取整,取大于等于N的最小整数。
select age,avg(ct) from (
select o.userId,age,count(o.userId) as ct
from data.orderinfo o
inner join (
select userId,ceil((year(now()) - year(birth)) / 10) as age
from data.userinfo
where birth > '1901-00-00') t
on o.userId = t.userId
group by o.userId,age) t2
group by age count(o.userId)统计消费频次
6)统计消费的二八法则,消费top 20%用户,贡献了多少额度?
select count(userId),sum(total) from (
select userId,sum(price) as total from data.orderinfo o
where isPaid = '已支付'
group by userId
order by total desc
limit 17000)t top = order.groupby('userID').sum().sort_values('price',ascending = False)
top.shape[0]*0.2#计算top前20%有多少人, 计算结果为17129.8
top = top.head(17130)
top.price.sum()#计算top前20%的人的总贡献度- ROW_NUMBER()
1)MySQL 从8.0版开始引入了该功能。这ROW_NUMBER()是一个窗口函数或分析函数,它为从1开始应用的每一行分配一个序号。
2)PARTITION BY子句将行分成更小的集合。PARTITION BY子句将行分成更小的集合。
3)ORDER BY子句的目的是设置行的顺序。此ORDER BY子句独立ORDER BY于查询的子句。
为行分配序号
SELECT
ROW_NUMBER() OVER (
ORDER BY productName
) row_num,
productName,
msrp
FROM
products
ORDER BY
productName;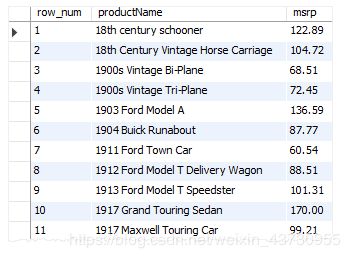
找到每组的前N行
WITH inventory
AS (SELECT
productLine,
productName,
quantityInStock,
ROW_NUMBER() OVER (
PARTITION BY productLine
ORDER BY quantityInStock DESC) row_num
FROM
products
)
SELECT
productLine,
productName,
quantityInStock
FROM
inventory
WHERE
row_num <= 3;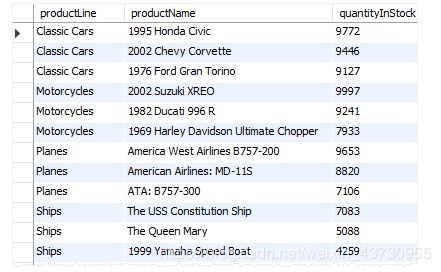
删除重复的行
首先,创建一个包含一些重复值的表:
CREATE TABLE t (
id INT,
name VARCHAR(10) NOT NULL
);
INSERT INTO t(id,name)
VALUES(1,'A'),
(2,'B'),
(2,'B'),
(3,'C'),
(3,'C'),
(3,'C'),
(4,'D');使用该ROW_NUMBER()函数进行分区编号
SELECT
id,
name,
ROW_NUMBER() OVER (PARTITION BY id, name ORDER BY id) AS row_num
FROM t;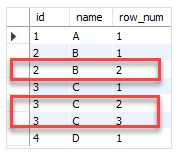
从输出中可以看出,唯一的行是行号等于1的行。
版本低于8.0的MySQL不支持row_number(),但幸运的是,MySQL提供了可用于模拟row_number()函数的会话变量 。
SET @row_number = 0;
SELECT
(@row_number:=@row_number + 1) AS num, firstName, lastName
FROM
employees
LIMIT 5;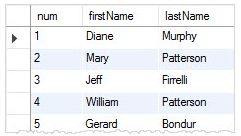
在第一个语句中,我们定义了一个名为的变量 row_number(),并将其值设置为0。 这row_number()是由@前缀指示的会话变量。
在第二个语句中,我们从表中选择数据,并将每行employees row_number()变量值增加到1。该LIMIT子句用于约束返回的行数,在这种情况下,它被设置为5。
MySQL row_number - 为每个组添加行号
SELECT
@row_number:=CASE
WHEN @customer_no = customerNumber THEN @row_number + 1
ELSE 1
END AS num,
@customer_no:=customerNumber as CustomerNumber,
paymentDate,
amount
FROM
payments
ORDER BY customerNumber;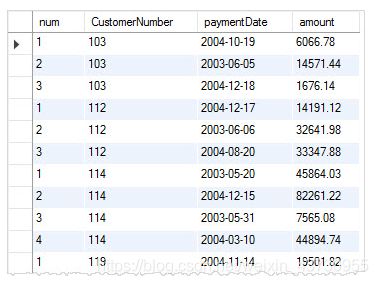
- 现有一个数据库表Tourists,记录了某个景点7月份每天来访游客的数量如下: id date visits 1 2017-07-01 100 …… 非常巧,id字段刚好等于日期里面的几号。现在请筛选出连续三天都有大于100人的日期。 上面例子的输出为: date 2017-07-01 ……
select t1.date
from Tourists as t1, Tourists as t2, Tourists as t3
on t1.id = (t2.id+1) and t2.id = (t3.id+1)
where t1.visits > 100 and t2.visits > 100 and t3.visits > 100
- 在一张工资表salary里面,发现2017-07这个月的性别字段男m和女f写反了,请用一个Updae语句修复数据 例如表格数据是: id name gender salary month 1 A m 1000 2017-06 2 B f 1010 2017-06
MS SQL SERVER
CREATE TABLE salary (
gender varchar(255) not null ,
income int not null
)
INSERT INTO salary VALUES ('m', '400000');
INSERT INTO salary VALUES ('m', '30000');
INSERT INTO salary VALUES ('f', '20000');
INSERT INTO salary VALUES ('f', '20000');
update salary
set gender = replace('mf', gender, '');
select * from salary- 现有A表,有21个列,第一列id,剩余列为特征字段,列名从d1-d20,共10W条数据! 另外一个表B称为模式表,和A表结构一样,共5W条数据 请找到A表中的特征符合B表中模式的数据,并记录下相对应的id 有两种情况满足要求: 1 每个特征列都完全匹配的情况下。 2 最多有一个特征列不匹配,其他19个特征列都完全匹配,但哪个列不匹配未知
select A.id,
((case when A.d1 = B.d1 then 1 else 0 end) +
(case when A.d2 = B.d2 then 1 else 0 end) +
...) as count_match
from A join B
on A.d1 = B.d1
having count_match >= 19Case具有两种格式。简单Case函数和Case搜索函数。
简单case函数
CASE sex
WHEN '1' THEN '男'
WHEN '2' THEN '女'
ELSE '其他' ENDcase搜索函数
CASE WHEN sex = '1' THEN '男'
WHEN sex = '2' THEN '女'
ELSE '其他' END - 我们把用户对商品的评分用稀疏向量表示,保存在数据库表t里面: t的字段有:uid,goods_id,star uid是用户id;goodsid是商品id;star是用户对该商品的评分,值为1-5。 现在我们想要计算向量两两之间的内积,内积在这里的语义为:对于两个不同的用户,如果他们都对同样的一批商品打了分,那么对于这里面的每个人的分数乘起来,并对这些乘积求和。 例子,数据库表里有以下的数据: U0 g0 2 U0 g1 4 U1 g0 3 U1 g1 1 计算后的结果为: U0 U1 23+41=10 ……
思路:根据用户id,goods_id,通过内连接将两表相连,计算不同用户,相同商品的分数乘积,通过用户id进行分组求和,计算内积。
CREATE TABLE goods_table (U VARCHAR(20),G VARCHAR(20),S INT);
INSERT INTO goods_table VALUES ('u0','g0',3);
INSERT INTO goods_table VALUES ('u0','g1',2);
INSERT INTO goods_table VALUES ('u0','g2',1);
INSERT INTO goods_table VALUES ('u1','g0',4);
INSERT INTO goods_table VALUES ('u1','g1',5);
INSERT INTO goods_table VALUES ('u1','g2',6);
INSERT INTO goods_table VALUES ('u2','g0',7);
INSERT INTO goods_table VALUES ('u2','g1',8);
INSERT INTO goods_table VALUES ('u2','g2',9);select T.Ua, T.Ub,SUM(T.res) sum_prod
FROM(select a.U as Ua,a.G as Ga,a.S as Sa,b.U as Ub,b.G as Gb,b.S as Sb,(a.S*b.S)as res
from goods_table a,goods_table b
where a.U<b.U and a.G = b.G) T
GROUP BY T.Ua, T.Ub
- 统计教授多门课老师数量并输出每位老师教授课程数统计表
解:设表class中字段为id,teacher,course
1)统计教授多门课老师数量
select count(*) from (select count(*) from class
group by teacher having count(distinct course) > 1 )A2)输出每位老师教授课程数统计
select teacher, count(distinct course) as count_course
from class
group by teacher- 五个人选举出一个骑士,统计投票数,并输出真正的骑士名字
设表tabe中字段为id,knight,vote_knight
Mysql
CREATE TABLE goods_table (ID INT, knight VARCHAR(20),vote_knight INT);
INSERT INTO goods_table VALUES (1,'A',3);
INSERT INTO goods_table VALUES (2,'B',5);
INSERT INTO goods_table VALUES (3,'C',1);
INSERT INTO goods_table VALUES (4,'B',2);
INSERT INTO goods_table VALUES (5,'C',1);select knight,sum(vote_knight)as num from goods_table
group by knight
order by num desc limit 1;报错:Unable to get host connection: Connections could not be acquired from the underlying database!
可能原因: 1.数据库用户名密码是否正确;2.连接数是否超过最大连接数。
set @sum1 = (select sum(frequency)+1 as sum1 from goods_table)
- 给出一堆数和频数的表格,统计这一堆数中位数
思路:统计这一堆数有多少个,以变量的形式存储。排序后为每个数添加索引(开头,结尾),如果索引满足要求则对应的数为中位数。
CREATE TABLE goods_table (ID INT, number INT,frequency INT);
INSERT INTO goods_table VALUES (1,5,2);
INSERT INTO goods_table VALUES (2,2,1);
INSERT INTO goods_table VALUES (3,3,1);
INSERT INTO goods_table VALUES (4,4,1);
INSERT INTO goods_table VALUES (5,1,1);set @sum = (select sum(frequency)+1 as sum from goods_table);
set @index1 = 0;
set @last_index = 0;
select avg(t.number)
from
(select @last_index:=@index1 as last_index, @index1:=@index1 + frequency as index1,
frequency, number from
(select * from goods_table
group by goods_table.number
)a
)as t
where t.index1 in (floor(@sum/2),ceiling(@sum/2))
or (floor(@sum/2)>=t.last_index and ceiling(@sum/2)<t.index1);
- 三个班级合在一起的一张成绩单,统计每个班级成绩中位数
思路:按班级分组后组内排序形成表1,表1计算组内序号后形成表2,计算每个班级的人数形成表3,表2和表3根据userid进行内连接形成表4。如果表四中序号满足一定的条件(如果对应的班级总人数为奇数,则对应的序号为班级总人数除以2后上取整的值。如果对应的班级总人数为偶数,则对应的序号为班级总人数除以2的值,及加1的值)则对应的数为符合条件的中位数。
CREATE TABLE info_table (ID INT, class INT,score INT);
INSERT INTO info_table VALUES (1,1,60);
INSERT INTO info_table VALUES (2,2,70);
INSERT INTO info_table VALUES (3,3,50);
INSERT INTO info_table VALUES (4,1,90);
INSERT INTO info_table VALUES (5,2,80);
INSERT INTO info_table VALUES (5,2,75);
INSERT INTO info_table VALUES (6,1,85);
INSERT INTO info_table VALUES (7,3,100);
INSERT INTO info_table VALUES (8,3,55);
INSERT INTO info_table VALUES (9,1,70);
INSERT INTO info_table VALUES (10,3,90);select class,avg(score)as median
from
(select a.num,a.class,a.score,b.count
from(
SELECT
@row_number:= CASE
WHEN @customer_no = class THEN @row_number + 1
ELSE 1
END AS num,
@customer_no:=class as class,
ID,
score
FROM
(select * from info_table order by class,score)
ORDER BY class,score)a
left join (select class,count(*)as count from info_table group by class )b
on a.class = b.class
having a.num = (case when b.count%2 = 0 then b.count/2 else ceiling(b.count/2) end)
or a.num = (case when b.count%2 = 0 then b.count/2+1 else ceiling(b.count/2) end)
)c
group by c.class
- 交易表结构为user_id,order_id,pay_time,order_amount,假设给出过去一个月的日表。
写sql查询过去一个月付款用户量(提示 用户量需去重)最高的3天分别是哪几天。
select day(pay_time) as pay_time, count(distinct user_id) as c from table group by day(pay_time) order by c desc limit 3写sql查询昨天每个用户最后付款的订单ID及金额
整合包含用户在昨天最后付款信息的一张表并与原表相连(相连时根据用户id,最后付款时间与支付时间判别),在表中选取需要的订单ID及金额信息
select order_id, order_amount from
(select user_id, max(pay_time) as mt
from table group by user_id where DATEDIFF(day, pay_time, NOW()) = 1)t1
left join table as t2
on t1.user_id = t2.user_id and t1.mt = t2.pay_time)- 数据倾斜
概念: 数据倾斜就是我们在计算数据的时候,数据的分散度不够,导致大量的数据集中到了一台或者几台机器上计算,这些数据的计算速度远远低于平均计算速度,导致整个计算过程过慢。
表现: 任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。因为其处理的数据量和其他reduce差异过大。
单一reduce的记录数与平均记录数差异过大,通常可能达到3倍甚至更多。 最长时长远大于平均时长。
数据倾斜的解决方案: 参数调节,SQL语句调节
SQL语句调节
1) 大小表Join:
使用map join让小的维度表(1000条以下的记录条数) 先进内存。在map端完成reduce。
2)大表Join大表且存在大量空值:
把空值的key变成一个字符串加上随机数,把倾斜的数据分到不同的reduce上,由于null值关联不上,处理后并不影响最终结果。
3)存在大量相同特殊值
如果是计算count distinct,可以不用处理,直接过滤,在最后结果中加1。如果还有其他计算。需要进行group by,可以先将值为空或其他特殊值的记录单独处理,再和其他计算结果进行union。
https://www.cnblogs.com/ggjucheng/archive/2013/01/03/2842860.html - PV表a(表结构为user_id,goods_id),点击表b(user_id,goods_id),数据量各为50万条,在防止数据倾斜的情况下,写一句sql找出两个表共同的user_id和相应的goods_id
题意理解:在大表join大表的情况下,如果表中存在大量空值,则大量空值的计算会集中到一个reduce里,发生数据倾斜。
解决方法:把空值的 key 变成一个字符串加上随机数,就能把倾斜的数据分到不同的reduce上 ,解决数据倾斜问题。
select a.user_id, a.goods_id
from a
left outer join b
on (case when a.user_id is null then concat(‘hive’,rand() ) else a.user_id end )= b.user_id;- 表结构为user_id,reg_time,age
随机抽样2000个用户
select * from table order by rand() limit 2000- 用户登录日志表为user_id,log_id,session_id,plat,visit_date
用sql查询近30天每天登录用户数量
select visit_date, count(distince user_id)
where DateDiff(day,t1.log_time,now())<= 30)
group by visit_date近30天连续访问7天以上的用户数量
select count(*)
from table t1, table t2, ..., table t7
where t1.visit_date = (t2.visit_date+1) and t2.visit_date = (t3.visit_date+1)
and ... and t6.visit_date = (t7.visit_date+1) and t1.user_id = t2.user_id and t2.user_id = t3.user_id and...and t6.user_id = t7.user_id
and DateDiff(dd,t1.log_time,getdate())<= 30)- 表user_id,visit_date,page_name,plat 统计近7天每天到访的新用户数
转换时间格式->根据用户id分类计算每个用户first_time,并将此特征加入表中,根据用户first_time分类,利用where选出first_time等于log_time的记录数,然后根据first_time分类去重计数。
MYSQL
create table logtable(
user_id INT NOT NULL,
log_time datetime NOT NULL);
insert into logtable values (1,'2019-06-01 10:10:01');
insert into logtable values (1,'2019-06-01 10:11:01');
insert into logtable values (1,'2019-06-01 10:12:01');
insert into logtable values (9,'2019-06-01 10:13:01');
insert into logtable values (9,'2019-06-01 10:14:01');
insert into logtable values (2,'2019-06-01 10:10:02');
insert into logtable values (2,'2019-06-01 10:11:01');
insert into logtable values (2,'2019-06-01 10:12:01');
insert into logtable values (3,'2019-06-02 10:10:01');
insert into logtable values (3,'2019-06-02 10:11:01');
insert into logtable values (4,'2019-06-03 10:10:01');
insert into logtable values (4,'2019-06-03 10:11:01');
insert into logtable values (4,'2019-06-03 10:12:01');
insert into logtable values (1,'2019-06-02 10:10:01');
insert into logtable values (1,'2019-06-02 10:11:01');
insert into logtable values (1,'2019-06-03 10:12:01');
insert into logtable values (9,'2019-06-02 10:13:01');
insert into logtable values (9,'2019-06-03 10:14:01');
insert into logtable values (2,'2019-06-03 10:10:02');
insert into logtable values (2,'2019-06-03 10:11:01');
insert into logtable values (2,'2019-06-03 10:12:01');
insert into logtable values (3,'2019-06-03 10:10:01');
insert into logtable values (3,'2019-06-05 10:11:01');
insert into logtable values (4,'2019-06-07 10:10:01');
insert into logtable values (4,'2019-06-05 10:11:01');
insert into logtable values (4,'2019-06-06 10:12:01');select logtime,count(*) from
(select b.user_id, logtime, first_time
from
(select distinct * from
(select user_id, date_format(log_time,'%Y-%m-%d')as logtime from logtable
group by user_id,log_time)a
)b
join
(select user_id,min(logtime)as first_time
from
(select distinct * from
(select user_id, date_format(log_time,'%Y-%m-%d')as logtime from logtable
group by user_id,log_time)a
)b
group by user_id
)c
on b.user_id = c.user_id
where b.logtime = c.first_time
)d
group by first_time- coalesce函数详解
select coalesce(success_cnt, 1) from tableA当success_cnt 为null值的时候,将返回1,否则将返回success_cnt的真实值。
select coalesce(success_cnt,period,1) from tableA当success_cnt不为null,那么无论period是否为null,都将返回success_cnt的真实值(因为success_cnt是第一个参数),当success_cnt为null,而period不为null的时候,返回period的真实值。只有当success_cnt和period均为null的时候,将返回1。
- concat()函数
功能:将多个字符串连接成一个字符串。
语法:concat(str1, str2,…)
返回结果为连接参数产生的字符串,如果有任何一个参数为null,则返回值为null。
语法:concat(str1, seperator,str2,seperator,…)
返回结果为连接参数产生的字符串并且有分隔符,如果有任何一个参数为null,则返回值为null。 - SQL ROUND() 语法
SELECT ROUND(column_name,decimals) FROM table_name
column_name 必需。要舍入的字段。
decimals 必需。规定要返回的小数位数。 - MySQL的时间差函数TIMESTAMPDIFF、DATEDIFF的用法
datediff函数,返回值是相差的天数,不能定位到小时、分钟和秒。
TIMESTAMPDIFF函数,有参数设置,可以精确到天(DAY)、小时(HOUR),分钟(MINUTE)和秒(SECOND),使用起来比datediff函数更加灵活。对于比较的两个时间,时间小的放在前面,时间大的放在后面。
–相差1天
select TIMESTAMPDIFF(DAY, '2018-03-20 23:59:00', '2015-03-22 00:00:00');–相差49小时
select TIMESTAMPDIFF(HOUR, '2018-03-20 09:00:00', '2018-03-22 10:00:00');–相差2940分钟
select TIMESTAMPDIFF(MINUTE, '2018-03-20 09:00:00', '2018-03-22 10:00:00');
–相差176400秒
select TIMESTAMPDIFF(SECOND, '2018-03-20 09:00:00', '2018-03-22 10:00:00');- SQL中char、varchar、nvarchar的区别
a. char是定长的,也就是当你输入的字符小于你指定的数目时,char(8),你输入的字符小于8时,它会在后面补空值。当你输入的字符大于指定的数时,它会截取超出的字符。CHAR字段上的索引效率级高。
b. nvarchar(n)包含 n 个字符的可变长度 Unicode 字符数据。方便判断是否超存储,所以一般来说,如果含有中文字符,用nchar/nvarchar。
(英文字符只需要一个字节存储就足够了,但汉字众多,需要两个字节存储,英文与汉字同时存在时容易造成混乱(判断是否超存储时比较麻烦),Unicode字符集就是为了解决字符集这种不兼容的问题而产生的,它所有的字符都用两个字节表示,即英文字符也是用两个字节表示,在存储英文时数量上有些损失。)
c. varchar[(n)] 长度为 n 个字节的可变长度且非 Unicode 的字符数据。一般来说,如果纯英文和数字,用char/varchar。如果一个字段可能的值是不固定长度的,我们只知道它不可能超过10个字符,把它定义为 VARCHAR(10)是最合算的。 - 查找入职员工时间排名倒数第三的员工所有信息
#查找入职员工时间排名倒数第三的员工所有信息
CREATE TABLE employees (
emp_no int(11) NOT NULL,
birth_date date NOT NULL,
first_name varchar(14) NOT NULL,
last_name varchar(16) NOT NULL,
gender char(1) NOT NULL,
hire_date date NOT NULL,
PRIMARY KEY (emp_no));SELECT * FROM employees
WHERE hire_date =
(SELECT DISTINCT hire_date FROM employees ORDER BY hire_date DESC LIMIT 1 OFFSET 2)Limit 与offset 一起使用的用法
举个例子,LIMIT 3 OFFSET 1, 这意味着,跳过第1条记录(即从第2条记录开始),返回接下来3条记录。即最终得到,原本的第2,3,4条记录。
- 查找所有员工入职时候的薪水情况
#查找所有员工入职时候的薪水情况,给出emp_no以及salary, 并按照emp_no进行逆序
CREATE TABLE employees (
emp_no int(11) NOT NULL,
birth_date date NOT NULL,
first_name varchar(14) NOT NULL,
last_name varchar(16) NOT NULL,
gender char(1) NOT NULL,
hire_date date NOT NULL,
PRIMARY KEY (emp_no));
CREATE TABLE salaries (
emp_no int(11) NOT NULL,
salary int(11) NOT NULL,
from_date date NOT NULL,
to_date date NOT NULL,
PRIMARY KEY (emp_no,from_date));思路
a. 通过 employees表的hire_date = salaries表的from_date,e.emp_no = s.emp_no 连接两张表;
b. 用ORDER BY 对emp_no进行排序。
方法一:INNER JOIN连接两张表
SELECT s.emp_no, s.salary
FROM employees AS e INNER JOIN salaries AS s
ON e.emp_no = s.emp_no AND e.hire_date = s.from_date
ORDER BY s.emp_no DESC方法二:并列查询
SELECT s.emp_no, s.salary
FROM employees AS e, salaries AS s
WHERE e.emp_no = s.emp_no AND e.hire_date = s.from_date
ORDER BY s.emp_no DESCINNER JOIN VS 并列查询
Q: 这两种方法有什么不同呢?
A: 内连接是取左右两张表的交集形成一个新表,用FROM并列两张表后仍然还是两张表。如果还要对新表进行操作则要用内连接。从效率上看应该FROM并列查询比较快,因为不用形成新表。本题从效果上看两个方法没区别。
- ’ Superyouyo ’ 指出,大数据量时,distinct的效率不高,可以用group by解决重复问题。
- 获取所有部门当前manager的当前薪水情况。
#获取所有部门当前manager的当前薪水情况,给出dept_no, emp_no以及salary,当前表示to_date=‘9999-01-01’
CREATE TABLE dept_manager (
dept_no char(4) NOT NULL,
emp_no int(11) NOT NULL,
from_date date NOT NULL,
to_date date NOT NULL,
PRIMARY KEY (emp_no,dept_no));
CREATE TABLE salaries (
emp_no int(11) NOT NULL,
salary int(11) NOT NULL,
from_date date NOT NULL,
to_date date NOT NULL,
PRIMARY KEY (emp_no,from_date));方法一:INNER JOIN
SELECT dm.dept_no, dm.emp_no, s.salary
FROM dept_manager AS dm INNER JOIN salaries AS s
ON dm.emp_no = s.emp_no AND dm.to_date = '9999-01-01' AND s.to_date = '9999-01-01'方法二:并列查询
SELECT dm.dept_no, dm.emp_no, s.salary
FROM dept_manager AS dm, salaries AS s
WHERE dm.emp_no = s.emp_no AND dm.to_date = '9999-01-01' AND s.to_date = '9999-01-01'- 获取所有非manager的员工emp_no
获取所有非manager的员工emp_no
CREATE TABLE dept_manager (
dept_no char(4) NOT NULL,
emp_no int(11) NOT NULL,
from_date date NOT NULL,
to_date date NOT NULL,
PRIMARY KEY (emp_no,dept_no));
CREATE TABLE employees (
emp_no int(11) NOT NULL,
birth_date date NOT NULL,
first_name varchar(14) NOT NULL,
last_name varchar(16) NOT NULL,
gender char(1) NOT NULL,
hire_date date NOT NULL,
PRIMARY KEY (emp_no));思路
思路一:employees 表 LEFT JOIN dept_emp 表,通过判断 dept_emp对应为空的记录,可以筛选出 「非manager的员工」;
思路二:在表employees中排除dept_emp表中的记录,用NOT IN字段。
方法一:IS NULL
SELECT e.emp_no
FROM employees AS e LEFT JOIN dept_manager AS dm ON e.emp_no = dm.emp_no
WHERE dm.dept_no IS NULL方法二: NOT IN
SELECT emp_no FROM employees
WHERE emp_no NOT IN (SELECT emp_no FROM dept_manager)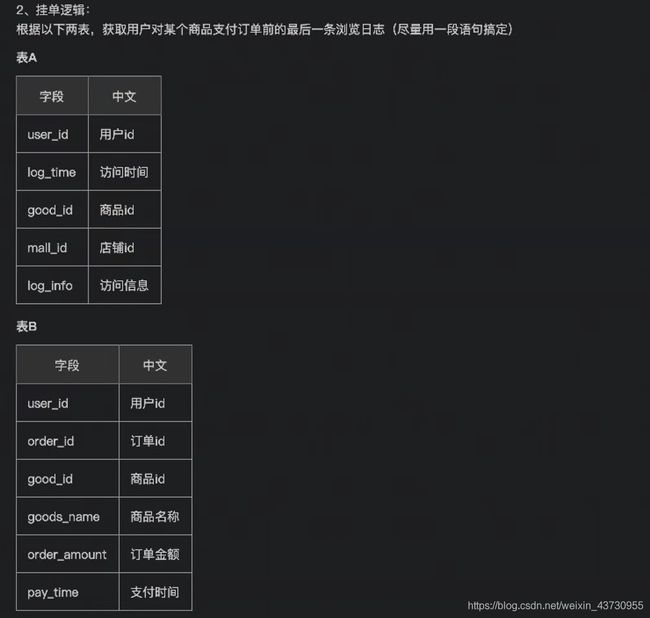
select A.*
from
(select B.user_id,B.good_id,max(log_time) as recent_time
from A join B on A.user_id = B.user_id and A.log_time < B.pay_time
group by B.user_id,B.good_id)C
join A on A.user_id = C.user_id and A.good_id = C.good_id and A.log_time = C.recent_time
计算每个用户支付每个商品订单前浏览的前五条信息
select * from
(
select B.user_id,B.good_id,row_number()over(partition by A.user_id, A.goods_id order by A.log_time desc) as num
from A join B on A.user_id = B.user_id and A.log_time < B.pay_time
)
where num < 6- sql求用户近一个月平均登录时间间隔
通过group by1,2(用户id,登陆时间)进行排序,并利用with as形成新表a,创建表b(与a表相同),并通过用户id相等join连接表a和表b形成表c,通过datediff计算访问时间间隔by_day,通过group by为用户id分组,通过avg每个用户的平均访问时间间隔。 - 显示50%的数据
create table logtable2(
title VARCHAR NOT NULL,
user_id INT NOT NULL,
name varchar(12) NOT NULL);
insert into logtable2 values ('A',7,'a ');
insert into logtable2 values ('A',6,'b ');
insert into logtable2 values ('A',5,'c ');
insert into logtable2 values ('B',4,'c ');
insert into logtable2 values ('B',3,'e');
insert into logtable2 values ('B',2,'d ');
insert into logtable2 values ('B',1,'e');SELECT TOP 50 PERCENT * FROM logtable2- 查询近5小时,近7天,近30天的用户数据。
https://blog.csdn.net/knight_key/article/details/81874028
https://www.w3school.com.cn/sql/func_date_sub.asp - 订单表OrderInfo 记录了每个用户Id和其所对应的订单Id, 以及每笔订单的原始价格。优惠券表Coupon记录了每个订单Id,每笔订单所使用的优惠券种类以及优惠券金额,且每笔订单可使用多种优惠券,每种优惠券仅可使用一张。请编写SQL程序,基于订单表OrderInfo和优惠券表Coupon查询每个用户Id,以及每笔订单所对应的实际支付金额(原始价格减去优惠部分),先按uid再按orderid升序排列。
样例输出:
uid orderid realamount
A1001 301 285.0
A1001 303 440.0
A1002 523 705.0
输入
create table OrderInfo(uid string,orderid bigint,oderamount double);
insert into OrderInfo(uid,orderid,oderamount)values('A1001',301,300.0);
insert into OrderInfo(uid,orderid,oderamount)values('A1002',523,720.0);
insert into OrderInfo(uid,orderid,oderamount)values('A1001',303,450.0);
create table Coupon(orderid bigint,coupon string, discount double);
insert into Coupon(orderid,coupon,discount)values(301,'A',5.0);
insert into Coupon(orderid,coupon,discount)values(301,'B',10.0);
insert into Coupon(orderid,coupon,discount)values(303,'A',10.0);
insert into Coupon(orderid,coupon,discount)values(523,'B',15.0);select E.uid, E.orderid,E.oderamount - E.discount_a - E.discount_b as realamount
from
(
select C.uid, C.orderid,C.oderamount,C.coupon_a,C.discount_a,D.coupon as coupon_b,(case when D.discount is null then 0 else D.discount end) as discount_b from
(
select OrderInfo.uid, OrderInfo.orderid,OrderInfo.oderamount,Coupon.coupon as coupon_a,(case when Coupon.discount is null then 0 else Coupon.discount end) as discount_a from OrderInfo left join Coupon
on OrderInfo.orderid = Coupon.orderid and Coupon.coupon = 'A'
)C
left join Coupon D on C.orderid = D.orderid and D.coupon = 'B'
)E
order by 1,2- SQL语言的书写顺序和解析顺序
书写顺序:select — from —where — group by — having —order by
解析顺序:from —where —group by — having — select — order by - 数据库中的表可通过键将彼此联系起来。主键(Primary Key)是一个列,在这个列中的每一行的值都是唯一的。在表中,每个主键的值都是唯一的。这样做的目的是在不重复每个表中的所有数据的情况下,把表间的数据交叉捆绑在一起。