A*算法—第K短路
A*算法—第K短路
A* 算法(这里的* 英文就读作star),是一种启发式搜索的方法,它离我们并不遥远,常用的BFS就是A*算法的一种特例。
启发式搜索:
DFS与BFS都属于非启发式搜索,又称盲目型搜索,它们最大的不同就是启发式搜索的选择不是盲目的,可以通过一个启发函数进行选择。
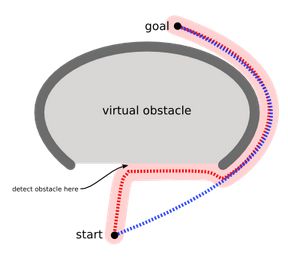
现在看一下下面的两张图,就可以很形象的理解了:

假如正常的搜索方式,我们会不断移动,直至遇到障碍物,显然这种方法是很愚蠢的,但是正常的方法的确是这样进行的,那么我们就希望扩展一个运动算法,用于对付上图所示的障碍物。或者避免制造凹形障碍,或者把凹形出口标识为危险的(只有当目的地在里面时才进去):
A*算法:
为启发式算法中很重要的一种,被广泛应用在最优路径求解和一些策略设计的问题中。而A*算法最为核心的部分,就在于它的一个估值函数的设计上:
f(n)=g(n)+h(n)
其中f(n)是每个可能试探点的估值,它有两部分组成:一部分为g(n),它表示从起始搜索点到当前点的代价(通常用某结点在搜索树中的深度来表示)。另一部分,即h(n),它表示启发式搜索中最为重要的一部分,即当前结点到目标结点的估值,h(n)设计的好坏,直接影响着具有此种启发式函数的启发式算法的是否能称为A*算法。
一种具有f(n)=g(n)+h(n)策略的启发式算法能成为A算法的充分条件是:
- 搜索树上存在着从起始点到终了点的最优路径。
- 问题域是有限的。
- 所有结点的子结点的搜索代价值>0。
- h(n) <= h * (n) (h*(n)为实际问题的代价值)。
一般的搜索前三条都可以满足,而第四点就要视情况而定了。
如果上面的概念不能很好理解也没关系,下面来看一道A*算法的经典题目,求第K短路【POJ2449】—— [ 题目链接 ]:
Description
“Good man never makes girls wait or breaks an appointment!” said the mandarin duck father. Softly touching his little ducks’ head, he told them a story.
“Prince Remmarguts lives in his kingdom UDF – United Delta of Freedom. One day their neighboring country sent them Princess Uyuw on a diplomatic mission.”
“Erenow, the princess sent Remmarguts a letter, informing him that she would come to the hall and hold commercial talks with UDF if and only if the prince go and meet her via the K-th shortest path. (in fact, Uyuw does not want to come at all)”
Being interested in the trade development and such a lovely girl, Prince Remmarguts really became enamored. He needs you - the prime minister’s help!
DETAILS: UDF’s capital consists of N stations. The hall is numbered S, while the station numbered T denotes prince’ current place. M muddy directed sideways connect some of the stations. Remmarguts’ path to welcome the princess might include the same station twice or more than twice, even it is the station with number S or T. Different paths with same length will be considered disparate.
Input
The first line contains two integer numbers N and M (1 <= N <= 1000, 0 <= M <= 100000). Stations are numbered from 1 to N. Each of the following M lines contains three integer numbers A, B and T (1 <= A, B <= N, 1 <= T <= 100). It shows that there is a directed sideway from A-th station to B-th station with time T.
The last line consists of three integer numbers S, T and K (1 <= S, T <= N, 1 <= K <= 1000).
Output
A single line consisting of a single integer number: the length (time required) to welcome Princess Uyuw using the K-th shortest path. If K-th shortest path does not exist, you should output “-1” (without quotes) instead.
Sample Input
2 2
1 2 5
2 1 4
1 2 2
Sample Output
14
在这道题目中,要求很明确,就是需要你求从s到t的第K短路
第k短路:
K短路的定义:假设从1出发,有M条长度不同的路径可以到达点N,则K短路就是这M条路径中第K小的路径长度。
以上所述,设f[n]为最终所求,则f(n)=g(n)+h(n);h(n)就是我们所说的‘启发式函数’,表示为重点t到其余一点p的路径长度,g(n)表示g当前从s到p所走的路径的长度。
即
估价函数=当前值+当前位置到终点的距离
Solution:
(1)将有向图的所有边反向,以原终点t为源点,求解t到所有点的最短距离;
(2)新建一个优先队列,将源点s加入到队列中;
(3)从优先级队列中弹出f(p)最小的点p,如果点p就是t,则计算t出队的次数;
如果当前为t的第k次出队,则当前路径的长度就是s到t的第k短路的长度,算法结束;
否则遍历与p相连的所有的边,将扩展出的到p的邻接点信息加入到优先级队列;
Code:
#include
using namespace std;
#define INF 0xffffff
#define MAXN 100010
struct node
{
int to;
int val;
int next;
};
struct node2
{
int to;
int g,f;
bool operator<(const node2 &r ) const
{
if(r.f==f)
return r.greturn r.fint n,m,s,t,k,cnt,cnt2,ans;
int dis[1010],visit[1010],head[1010],head2[1010];
void init()
{
memset(head,-1,sizeof(head));
memset(head2,-1,sizeof(head2));
cnt=cnt2=1;
}
void addedge(int from,int to,int val)
{
edge[cnt].to=to;
edge[cnt].val=val;
edge[cnt].next=head[from];
head[from]=cnt++;
}
void addedge2(int from,int to,int val)
{
edge2[cnt2].to=to;
edge2[cnt2].val=val;
edge2[cnt2].next=head2[from];
head2[from]=cnt2++;
}
bool spfa(int s,int n,int head[],node edge[],int dist[])
{
queue<int>Q1;
int inq[1010];
for(int i=0;i<=n;i++)
{
dis[i]=INF;
inq[i]=0;
}
dis[s]=0;
Q1.push(s);
inq[s]++;
while(!Q1.empty())
{
int q=Q1.front();
Q1.pop();
inq[q]--;
if(inq[q]>n)
return false;
int k=head[q];
while(k>=0)
{
if(dist[edge[k].to]>dist[q]+edge[k].val)
{
dist[edge[k].to]=edge[k].val+dist[q];
if(!inq[edge[k].to])
{
inq[edge[k].to]++;
Q1.push(edge[k].to);
}
}
k=edge[k].next;
}
}
return true;
}
int A_star(int s,int t,int n,int k,int head[],node edge[],int dist[])
{
node2 e,ne;
int cnt=0;
priority_queueQ;
if(s==t)
k++;
if(dis[s]==INF)
return -1;
e.to=s;
e.g=0;
e.f=e.g+dis[e.to];
Q.push(e);
while(!Q.empty())
{
e=Q.top();
Q.pop();
if(e.to==t)//找到一条最短路径
{
cnt++;
}
if(cnt==k)//找到k短路
{
return e.g;
}
for(int i=head[e.to]; i!=-1; i=edge[i].next)
{
ne.to=edge[i].to;
ne.g=e.g+edge[i].val;
ne.f=ne.g+dis[ne.to];
Q.push(ne);
}
}
return -1;
}
int main()
{
while(~scanf("%d%d",&n,&m))
{
init();
for(int i=1;i<=m;i++)
{
int a,b,c;
scanf("%d%d%d",&a,&b,&c);
addedge(a,b,c);
addedge2(b,a,c);
}
scanf("%d%d%d",&s,&t,&k);
spfa(t,n,head2,edge2,dis);
ans=A_star(s,t,n,k,head,edge,dis);
printf("%d\n",ans);
}
return 0;
} A*对启发式函数的使用
·h(n)越小,运行的越慢
·如果h(n)=0,则只有g(n),此时的A*就变成了Dijkstra算法。
·如果h(n)比g(n)大很多,则A*就变成了BFS
所以我们得到一个很有趣的情况,那就是我们可以决定我们想要从A*中获得什么。理想情况下(注:原文为At exactly the right point),我们想最快地得到最短路径。如果我们的目标太低,我们仍会得到最短路径,不过速度变慢了;如果我们的目标太高,那我们就放弃了最短路径,但A*运行得更快。 —— [ 参考 ]
注:在学术上,如果启发式函数值是对实际代价的低估,A*算法被称为简单的A算法(原文为simply A)。然而,我继续称之为A*,因为在实现上是一样的,并且在游戏编程领域并不区别A和A*。
ADD:
- A*算法在理论上是时间最优的,但是也有缺点:它的空间增长是指数级别的。
- IDA*算法:这种算法被称为迭代加深A*算法,可以有效的解决A*空间增长带来的问题,甚至可以不用到优先级队列。如果要知道详细:google一下。
- 可以认为BFS是“最烂的”A*算法
- 启发式搜索中,对位置的估价是十分重要的。采用了不同的估价可以有不同的效果
比较BFS与A*算法:

Sumarry
我们可以看出:A*算法最为核心的过程,就在每次选择下一个当前搜索点时,是从所有已探知的但未搜索过点中(可能是不同层,亦可不在同一条支路上),选取f值最小的结点进行展开。而所有“已探知的但未搜索过点”可以通过一个按f值升序的队列(即优先队列)进行排列。这样,在整体的搜索过程中,只要按照类似广度优先的算法框架,从优先队列中弹出队首元素(f值),对其可能子结点计算g、h和f值,直到优先队列为空(无解)或找到终止点为止。
或者流程图: