团队git流程
前一段时间接触一个新团队时,发现他们因没有”流程”,常发生代码合并困难,或者合并后漏掉几个commit,上线后把别人代码搞坏的情况。由此想探讨一下“流程”问题。
两大流程
调查时发现阮一峰老师在Git 工作流程一文中已经探讨了3种经典流程,由此了解到几种经典流程的名字:git flow, github flow, 和 gitlab flow。不过我认为git flow不适合多人协作,所以只探讨github流程和gitlab流程。
先谈谈基本原则
两种流程区别只在于gitlab流程比github流程多一个线上分支。他们的原则是一样的:
- 不在主分支开发,保证主分支“干净”,只接受开发完成的代码合并,或补丁。
- 每个功能在单独分支上开发。
- 避免多人在同一个模块上做修改。按模块分工,错开排期。
哪怕自己一个人玩,也总有进行到一半意外终止,或不小心把分支玩坏了的时候。创建一个开发分支可避免别人受到自己还没“完成”的代码的影响,保证主分支“干净”。
当两人动了同一块代码,后合并的一方得解决很多冲突。合并大块代码冲突极费时间。需搞清楚来龙去脉,且产生新bug几率很高。因此尽量避免多人在同一块代码上修改。
团队小,大家都知道对方在干什么的时候,通过适当排期很容易避免冲突。而团队大了后,便需要分割成小团队,明确负责的功能模块来避免。
Github flow:主分支 + 多开发分支
Github flow只存在一个长期维护的主分支,通常叫master。接下来粗略分3种情况讨论:
- 新功能开发、非紧急bug修复、小范围不影响接口的重构
- 打补丁
- 大范围重构
新功能开发/非紧急bug修复/小范围重构
首先,基于最新的master创建独立的功能开发分支。
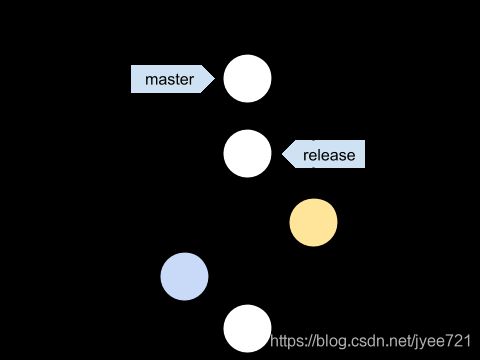
Git树如下:

待功能开发完成,测试通过后,向master发起PR (pull request 合并请求),请求维护人员审核代码。
代码被合并之前,需定期rebase或merge主分支的最新代码,减少大块冲突发生的几率,并保证代码在最新版上能正常工作。
审核通过后,由维护人员合并代码。被合并的分支可立即清理,或定期用git工具提供的一键清除已合并分支清理。
合并之后git树如下:

发版
一个阶段的开发完成,或到指定时间点,在master分支上发版:
- 更新版本号(如npm version)。新功能可更新次要版本。如
v16.11.9更新到v16.12.0。改动较大时,则应更新主版本。如v1.0.1更新到v2.0.0。 - 在最新的master commit上打版本tag。如React的v16.12.0。
- 适当地添加版本说明、更新记录。
- npm包发布,或部署。
打补丁
为已发布版本打补丁,不适合基于master分支直接打,而要用上节中打的tag。这是因为主分支时不时有新功能合并进来,代码上下文随时会发生变化,我们不能在为线上打补丁的时候带进不能在此时上线的代码。
假设在v1.5.0版本上打补丁。我们先基于该版本tag创建一个分支:
$>master: git fetch
$>master: git checkout v1.5.0
$>v1.5.0: git checkout -b jennie/fix/xxx
然后在新分支上开发、测试、再提交合并请求。合并请求的目标可以是:
- master - 如果master主版本仍旧在v1.5。
- 旧的主版本分支 - 如果master主版本已经是v2,有些项目会保留一个v1的分支,用于维护旧版本。
代码审核、合并后,仓库负责人应发一个新的补丁版本,如v1.5.1。过程同上节。
大范围重构
大范围重构一般能分成小重构一点点来就一点点来吧,除非像Angular 1到2那样整个接口都重新设计。
遇到这种“重新设计”的坑,基本都是旧代码扔掉,从新再写了。这时最容易的是从初始或一个比较空白的commit创建新的主分支。如master主版本为v1,现在要开始开发v2,就建一个v2主分支。合理规划,在v2分支基础上创建新功能分支,同上面章节所述的新功能开发流程相同。
v2开发告一断落,并发布预览版之后,因为master与v2的git树相差甚远,已不适合走合并的路子,而且也没必要。那此时最容易的就是让仓库管理员将现在的master更名为v1,v2更名为master,让v2分支变为主分支。
评价
Github flow比较适合库、组件、框架、工具、应用、开源项目,或是发布控制比较简单的小团队。它的优点是流程比较直观清晰,容易理解上手。但像网站一类的代码仓库,并不需要为旧版打补丁,需要补丁的永远是当前线上部署的版本。并且功能或修复进入主分支后需要等待一段时间才能上线,期间有可能因为误操作、更改排期导致改动被回退。因此单一主分支不够,需要再加一个发布的第二主分支(release),也就是下面我们要讨论的gitlab flow。
Gitlab flow: 预发布分支(主分支)+ 已发布分支 + 多个开发分支
Gitlab flow长期维护两个主分支master和release。这种模式通常更适合于网站代码一类不太需要维护旧版本,但经常为线上版本打补丁的项目。
Gitlab flow中做新功能,修非紧急bug,以及重构的部分与github flow相同,使用master主分支。但在设计上线发版和打补丁时会有些区别。
发版
与github flow不同的是,gitlab flow在代码合并到master分支后,并不直接从master发版。
master可用于做上线前的回归测试,为上线做准备。一旦上线准备完成,需要将master合并入release分支,再从release分支发版。
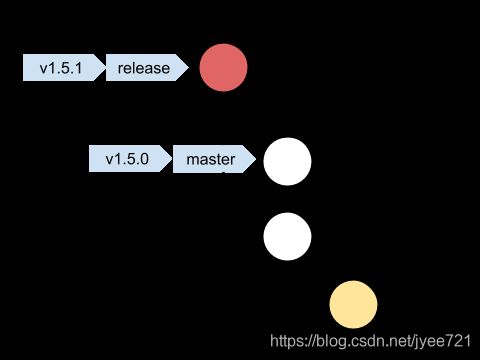
发版的tag在master或release打没有什么区别,因为对应的commit应最终同时存在于两个分支中。
master合并入release分支的操作,应是没有任何冲突的,除非release上有补丁没有被及时合并入master,这部分在下节作详细讨论。master合并入release可考虑由维护者手动进行。
打补丁
有了release分支后,所有需要紧急上线的补丁应直接打在release分支上。即基于release分支创建补丁分支。修复,测试,审核之后合并入release分支而非master分支。再直接从release发版。
打过补丁的release分支会与master分支产生分歧:
此时要记得及时将release分支的改动合并入master,以保证后续的开发能顺利进行。
team足够大的时候,这步发生冲突的几率很高。一旦发生冲突,因为网页版的合并工具一般都不太可靠,推荐维护人员手动线下合并。
解决冲突时,先从最新的master创建一个merge-release分支。在这个分支里,我们合并release分支,解决冲突并提交一个合并commit。然后将代码推送至远端,并向master提交PR,让相关人员审核。
这就是两个主流流程。下面我们补充一些实际操作过程中涉及处理和需要注意的细节。
并入主分支后回退
导致并入主分支后回退有以下可能:
- 维护者误操作。毕竟合并只是点一个按钮,是人都有误操作的时候。
- 合并后上线日程推迟。比如,某国皇族去世了,为了政治正确,一段时间内不许有搞活动。
- 合并后发现其他小伙伴的代码挂了。
主分支的内容分分钟可能被小伙伴用来创建自己的功能分支,想要回退的commit可能已经存在在小伙伴们的功能分支上。为了避免小伙伴们受到影响,我们用双git revert:
- 可在主分支上直接操作
git revert或创建PR。Git revert会新建一个回退commit。 - 再从主分支创建一个新分支,然后
git revert。 - 待需要上线时,再合并第二个revert。
多环境
企业级开发中,为保证发布应用的可靠性,会引入更多复杂的流程。比如QA测试,用户验收测试,回归测试等等。同时会引入多个独立环境以保证能各自运行不同版本的代码,用作不同目的。
当然这事又增加了流程的复杂性。
共用测试环境
先说个反例。有些团队为QA测试环境建了个分支叫test。每当开发完成需要QA测试的时候,他们就把代码并入test分支,开发分支保留。待QA测试完成之后再并入master主分支等待上线。
一段时间后大家发现测试环境非常不稳定,回归测试bug非常多。QA表示很委屈,测试明明是通过的,不能是我的锅。
这流程里代码被合并了至少两次,而且两次的合并目标里的内容不同,QA测试的上下文跟最终上线的上下文相差甚远,增加了不稳定性。一旦遇到冲突也极可能需要解决两次,增加了额外的时间成本。同时解决冲突量越多,越容易引入新bug。
独立测试环境
实践经验得出以下比较好的解决方案:
- QA和用户验收测试用以已包含release最新代码的功能分支,如果master极少发生回退操作最好用master。即每个需要测试的功能分支享有独立环境。
- 回归测试使用待“上线的”master分支,或master分支上待发的版本标签(tag) 。
以上方案缺陷是环境的控制。团队需要有足够的多环境部署控制能力或有牛X的DevOps做容器化支持来保证大家不抢环境,不浪费资源。
功能开关
还有种成本稍低一些的做法是功能开关(feature toggle)。它允许还未开发完成的代码存在于上线的分支中,可使用构建工具将不上线的代码块移除,在测试环境中根据需要打开。经过适当的设计,也可以做A/B testing等更多的控制。
当然事情不会如此完美。
功能开关可以选择将“关闭”的代码移除。前端的代码移除靠AST操作,玩过的都知道有多复杂。多数功能开关工具都没法做好内连代码的移除。因此会建议使用特定的编程方式,比如只能用if else来判断代码块的开与关。
如果关的代码不被移除,又难保不会影响其他开着的功能。且开发需要兼顾在同一文件上多个版本,增加开发成本。如果开发2个不同文件服务功能的开与关,那没有改动的部分就要一起维护,增加维护成本。
因此我认为它不适用于作为节省环境成本的解决方案,团队小时可以借此一用。
处理复杂依赖关系
有时有“大功能”需要多位开发一起分工合作,或是涉及同一模块的不同改动需要同期进行但有先后依赖关系。当然其实项目和产品够给力这都可以通过好好计划避免的。
然并卵。一旦遇到此类情况,可先从master创建一个功能主分支,比如:feature-a/master。
分工合作的小伙伴们再从feature-a/shared分出自己的模块分支。如:feature-a/module-1, feature-a/module-2。模块分支之间在分工时就需避免互相依赖。
如果有共用的方法、常量,线下商量清楚后放入功能主分支,模块分支rebase或merge功能主分支。
模块开发完成后,可互相审核一下代码,审核通过,就可以合并入功能主分支。待所有模块开发完成,便可在功能主分支上进行测试。
期间因为项目大开发周期长,注意功能主分支需定期合并master或release。注意功能主分支不要rebase,一旦rebase,所有依赖它的模块分支需特殊处理,不然git树很混乱,还会面临一些奇怪的冲突。
rebase功能主分支后
如果不小心rebase了,我发现有两种方式处理比较容易:
方法一:cherry-pick。从最新的功能主分支重新创建分支feature-a/module-1,将改动commit从原模块分支上cherry-pick到新的feature-a/module-1上。
$>feature-a/shared: git checkout -b feature-a/module-1
$>feature-a/module-1: git cherry-pick xxx
如果commit很多,事前flush一下commit就不必cherry-pick这么多commit了。
方法二: soft reset + stash。在git log中找到创建分支时的commit SHA。soft reset到该commit就能得到所有你在此分支做的所有改动。把它们git stash起来。重新从最新的功能主分支创建模块分支,再把stash的改动放回来。
$>old-branch: git reset --soft xxx
$>old-branch: git stash
$>old-branch: git checkout feature-a/shared
$>feature-a/shared: git checkout -b feature-a/module-1
$>feature-a/module-1: git stash pop
制定规则
实行流程中,制定一些规则可以帮助团队工作更高效。
分支名称
**规则一:使用有意义的分支名。**有意义的分支名能帮助自己和小伙伴用关键字寻找分支。
举例:
- 小伙伴建了个功能主分支,我不记得叫啥,但知道通常按功能命名,在git网页版工具中通过关键字搜索一下就找到了功能主分支和小伙伴的分支。
- 我有时一天在无数分支之间切换,切换时按照我自己的命名规则用关键字就可以迅速在命令行自动完成分支名并切换。
反例:小伙伴偷懒直接用了需求单的ID(只是几位数字)命名,隔两天后不找到那个需求单,看它的标题,压根不知道这分支是干啥的。
规则二:用名字缩写/修改类型/修改内容命名。 git的GUI工具如SourceTree,Github官方工具,都会把这种命名方式处理成树状显示,分支多的时候就凸显出这类归类显示的整洁清晰。
commit消息
规则一:包含在哪个功能上修复、增加、删除、修改了什么,还有为啥。 以个人经验来讲,commit消息的用处如下:
- 追责。git blame并不一定能帮你找到谁是搞坏代码的罪魁祸首,也不能帮你搞清楚来龙去脉,但清晰的commit消息可以。
- 代码回退时容易找到回退目标。
- 识别操作失误中额外增加的commit。
- 生成更新日志。
规则二:用链接解释为啥。 比如Github可以通过特定格式连接Issue或PR,当简短的消息无法让人了解事情的全貌,提供记录会有所帮助。
权限
一般git社区里的代码仓库至少有4种角色:管理员、维护人员、其他开发、访客。利用这4种角色做适当的权限控制,我们可以避免新手误操作,和非相关人员不正当使用代码。
假设团队队长是管理员,资深队员是维护人员,剩余不足年的新人和不靠谱的小伙伴都只是普通开发角色,非开发都是访客。
常见操作有:
- 保护主分支。不允许任何人直接往主分支推代码。只允许管理员和维护人员合并PR。
- 代码评审。只有通过管理员和维护人员审核过的代码才能进入合并流程。
贴标签label
标签可以用于对PR或Issue进行分类。比较有用的标签有以下几类:
- 表明类型:功能、bug、问问题、讨论等。
- 项目名称。常见于monorepo之类多项目共享一个代码仓库的情况。
- 状态:代码评审状态、过久没人处理但需要处理的triage状态等。
- 参加活动。比如Hacktoberfest。
- 适合人群。比如Good first issue,对于想为开源做贡献的新手是一个很好的起始点。
PR和Issue样板
创建合适的PR和Issue样板,列出希望对方说清楚的点,可以减少很多交流成本。
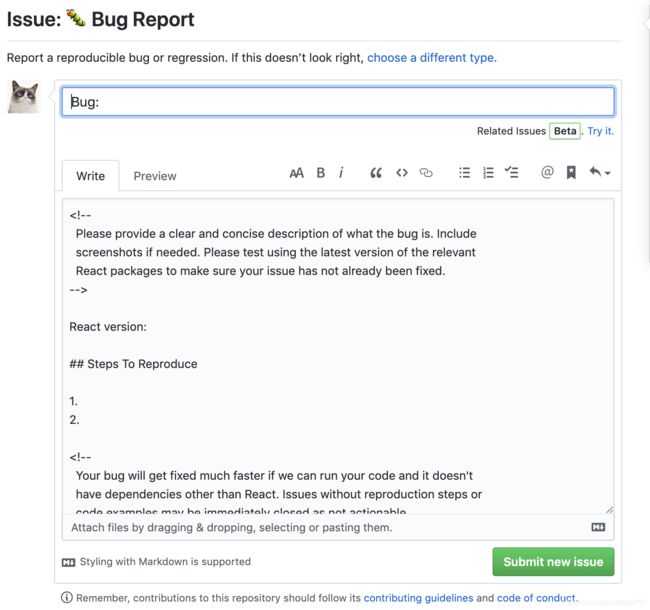
如上图为React的Issue样板,要求大家在提bug的时候描述bug表现,期望表现,发生的环境等。
Codeowners
Codeowner是一个文件,用于列出代码仓库路径对应的维护者。一旦有了这个文件,大家在创建PR的时候就不用愁发给谁了,像Github就会自动根据PR的更改推荐评审人。
Github详细的说明看这里。
自动化测试
自动化测试、lint、还有类型验证可以帮开发避免许多bug发生。因此,有必要在工作流程中强制一些测试,如:
- 用Husky在commit代码之前做一些检测,比如ESlint。
- 用CI设置测试步骤,并设置必须通过的步骤。