数据结构与算法之美--1.时间复杂度分析
时间复杂度分析
- 为什么要进行时间复杂度的分析
- 大O复杂度表示法
- 如何分析一段代码的时间复杂度?
- 几种常见时间复杂度实例分析。
- 空间复杂度
- 最好、最坏时间复杂度
- 平均时间复杂度
- 均摊时间复杂度
为什么要进行时间复杂度的分析
如果我们直接将代码跑一遍,通过统计,监控,就能够得到算法执行的时间和占有的内存,为什么还需要进行时间、空间复杂度的分析?
因为上述评估算法的方式称为事后统计法,具有很大局限性。
- 测试结果非常依赖测试环境。
- 测试结果受数据规模影响很大。举个例子,就像我们的排序算法。对于小规模的数据排序,插入排序可能反倒会比快速排序还快。
所以,我们需要一个不用具体的测试数据来测试,就可以粗略的估计算法的执行效率的方法。
大O复杂度表示法
算法执行效率,其实我们可以即将它等价为,算法代码的执行时间。
我们从一个例子入手:估算下列代码的执行时间。
public int cal(int n){
int sum=0;
for(int i=1;i<=n;i++){
sum+=i;
}
return sum;
}
从cpu的角度来看,这段代码的每一行都执行着类似的操作:读数据-运算-写数据。尽管每一行对应的cpu执行的个数,执行的时间都不一样,但是,我们这里只是粗略估计,假设每行代码执行的时间都一样,为unit_time.那么这行代码的总执行时间是多少呢?
分析思路:第2行代码分别需要1个unit_time的执行时间,第3、4行代码都运行了n次,所以需要2nunit_time。所以这段代码总的执行时间就是(2n+2)*unit_time。可以看出来,所有代码的执行时间T(n)与每行代码的执行次数成正比。
按照上述分析思路,我们分析下列代码。
public int cal(int n) {
int sum=0; //1
int i=1; //1
int j=1; //1
for(;i<=n;i++) { //n
j=1;//n
for(;j<=n;j++) {//n*n
sum=sum+i*j; //n*n
}
}
return sum;
}
T ( n ) T(n) T(n)=( 2 n 2 2n^2 2n2+ 2 n 2n 2n+3)个unit_time。
通过两段代码的推导过程,我们可以得出结论:
所有代码的执行时间T(n)与每行代码的执行次数成正比。
T(n)=O(f(n))
f(n)代表代码执行的次数总和。
第一个例子:T(n)=O(2n+2)
第二个例子:T(n)=O( 2 n 2 2n^2 2n2+ 2 n 2n 2n+ 3 3 3)
当n很大时,公式里的低阶、常量、系数三部分并不左右增长趋势。所以可以忽略。也就是
第一个例子:T(n)=O(n)
第二个例子:T(n)=O( n 2 n^2 n2)
如何分析一段代码的时间复杂度?
- 只关注循环执行次数最多的一段代码。
- 加法法则:总复杂度等于量级最大的那段代码的复杂度。
public int cal(int n) {
int sum_1=0;
int p=1;
for(;p<100;p++) {
sum_1=sum_1+p; //100
}
int sum_2=0;
int q=1;
for(;q<n;++q) {
sum_2=sum_2+q; //n
}
int sum_3=0;
int i=1;
int j=1;
for(;i<=n;i++) {
j=1;
for(;j<=n;j++) {
sum_3=sum_3+i*j; //n*n
}
}
return sum_1+sum_2+sum_3;
}
代码分为3部分,第一部分的时间复杂度是常量的,因为100是已知的,就算代码执行1000000次,只要它是已知的,他就是常量级的执行时间;第二、三段代码很容易分析出的O(n)和O( n 2 n^2 n2)。
综合三段代码。我们取最大的量级,所以整段代码的时间复杂度是O( n 2 n^2 n2)
T(n)=max(O(f(n)),O(g(n)));
- 乘法法则:嵌套代码的复杂度等于嵌套内外代码复杂度的乘积
几种常见时间复杂度实例分析。
非多项式量级和多项式量级。

非多项式量级只有两种。O( 2 n 2^n 2n) 和O( n ! n! n!),我们把时间复杂度为非多项式量级的算法问题叫做NP问题,NP时间复杂度的算法其实是非常低效的算法,因为随着数据规模增大,执行时间会急剧增加。
- O(1)
一般情况下,只要算法不存在循环语句,递归语句,即使有成千上万行代码,其时间复杂度也是O(1)。 - O(logn)、O(nlogn)
i=1;
while(i<=n){
i=i*2; //
}
我们分析上述代码的时间复杂度,因为第三行代码是执行循环次数最多的,所以我们只要分析第三行代码的执行时间,亦即第三行代码执行的次数。
2 0 2^0 20, 2 1 2^1 21, 2 2 2^2 22, 2 3 2^3 23, 2 4 2^4 24, 2 5 2^5 25, 2 x 2^x 2x=n,
第三行代码执行的次数是x,x=log2n。
所以代码的时间复杂度为O(log2n),在计算机科学中,我们认为logn是log2n的缩写。
实际上无论以2为底还是以3为底甚至以10为底,都记为O(logn),因为代数之间是可以互相转换的。log3n=log32*log2n,前面的常数可以将其忽略。
- O(m+n)、O(m*n)
代码的复杂度由两个数据的规模来决定。
int sum_1=0;
int p=1;
for(;p<m;p++) {
sum_1=sum_1+p; //m
}
int sum_2=0;
int q=1;
for(;q<n;++q) {
sum_2=sum_2+q; //n
}
从代码中可以看出,我们无法事先评估m和n谁的量级大,所以我们在表示复杂度的时候,就不能简单地利用加法法则,省略掉其中一个。所以上面代码地时间复杂度是O(m+n)。这种情况下加法法则就不有效了。但是乘法法则同样有效。
空间复杂度
我们常见的空间复杂度就是O(1)、O(n)和O(n2)。空间复杂度的分析比时间复杂度的分析要简单的多。
最好、最坏时间复杂度
public int find(int[] array,int n,int x) {
int i=0;
int pos=-1;
for(;i<n;i++) {
if(array[i]==x)
pos=i;
}
return pos;
}
根据上述分析方法,我们可以看出这段代码的复杂度为O(n)
我们在数组中查找一个数据,并不需要每次把整个数据都遍历一遍,因为有可能中途找到就可以提前结束循环了,但是这段代码写得不够漂亮。我们可以这样优化这段查找代码。
public int find(int[] array,int n,int x) {
int i=0;
int pos=-1;
for(;i<n;i++) {
if(array[i]==x){
pos=i;
break;
}
}
return pos;
}
这时间复杂度不再是O(n),因为,如果我们找到了,就会退出循环,但是我们并不知道什么时候会找到。最好的情况是第一个元素就是我们要找的元素,那么时间复杂度就是O(1)。最坏的情况是找不到。那么时间复杂度是O(n)。
平均时间复杂度
我们都知道,最好时间复杂度和最坏时间复杂度是极端的情况。所以我们引入平均时间复杂度。
我们知道,要查找的变量x,要么在数组中,要么不在数组中。我们假设在数组中在与不在数组中的概率都为1/2。另外,要查找的数据出现在0~n-1这n个位置的概率也是一样的,为1/n。所以要查找的数据出现在 0~n-1中任意位置的概率为1/2n。
因此平均复杂度的计算过程是
1 ∗ 1 / 2 n + 2 ∗ 1 / 2 n + 3 ∗ 1 / 2 n + . . . + n ∗ 1 / 2 n = ( 3 n + 1 ) / 4 1*1/2n+2*1/2n+3*1/2n+...+n*1/2n=(3n+1)/4 1∗1/2n+2∗1/2n+3∗1/2n+...+n∗1/2n=(3n+1)/4
均摊时间复杂度
均摊时间复杂度和摊还分析应用场景比较特殊,所以我们并不会经常用到。简单总结一下它们的应用场景。对一个数据结构进行一组连续操作中,
- 大部分情况下时间复杂度都很低,只有个别情况下时间复杂度比较高
- 这些操作之间存在前后连贯的时序关系。
这个时候,我们就可以将这一组操作放在一块分析,看是否能将较高时间复杂度那次操作的耗时,平摊到其他那些时间复杂度比较低的操作上。而且,在能够应用均摊时间复杂度分析的场合,一般均摊时间复杂度就等于最好情况时间复杂度。
举个例子:
// array表示一个长度为n的数组
// 代码中的array.length就等于n
int[] array = new int[n];
int count = 0;
void insert(int val) {
//如果元素插入完毕,我们将数组的元素累加,然后将和存储到数组的第一位上
if (count == array.length) {
int sum = 0;
for (int i = 0; i < array.length; ++i) {
sum = sum + array[i];
}
array[0] = sum;
count = 1;
}
//将元素插入数组。
array[count] = val;
++count;
}
分析这段代码的时间复杂度。
最好的情况:数组有空闲的位置,元素直接插入,所以是O(1)
最坏的情况:数组没有空闲的位置,元素需要累加求和,然后将和赋给数组第一个元素。
平均情况:利用概率论。
假设数组的长度是 n,根据数据插入的位置的不同,我们可以分为 n 种情况,每种情况的时间复杂度是 O(1)。除此之外,还有一种“额外”的情况,就是在数组没有空闲空间时插入一个数据,这个时候的时间复杂度是 O(n)。而且,这 n+1 种情况发生的概率一样,都是 1/(n+1)。所以,根据加权平均的计算方法,我们求得的平均时间复杂度就是:
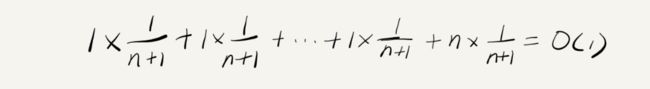
我们引入第四种复杂度的分析,就是均摊时间复杂度。其实均摊时间复杂度就是特殊的平均时间复杂度。它特殊在哪呢?
我们和上述的find()作比较。
- find() 是在一个数组里找元素,如果在第一位,我们只需要消耗1个unit_time。这是很极端的情况,只有在第一位才有这么好的情况。如果在第二位,就需要消耗2个unit_time。
但是insert()它大部分情况(只要数组有空闲)只需要消耗1个unit_time。这就满足我们应用场景第一个特点。大部分情况下时间复杂度都很低,只有个别情况下时间复杂度比较高。 - find()中最差的情况O(n)和最好的情况O(1)之间并没有什么关系。但是在insert()里,我们可以很清楚的发现,每次在经历n个O(1)后,就会出现一次O(n),所以这里满足我们应用场景的第二个特点。这些操作之间存在前后连贯的时序关系。
既然它这么特殊,那我们是不是就不用用那么复杂的方法分析。,我们引入了一种更加简单的分析方法:摊还分析法。
通过摊还分析得到的时间复杂度,叫均摊时间复杂度。
那究竟如何使用摊还分析法来分析算法的均摊时间复杂度呢?
我们还是继续看在数组中插入数据的这个例子。每一次 O(n) 的插入操作,都会跟着 n-1 次 O(1) 的插入操作,所以把耗时多的那次操作均摊到接下来的 n-1 次耗时少的操作上,均摊下来,这一组连续的操作的均摊时间复杂度就是 O(1)。这就是均摊分析的大致思路。