知识图谱_概述:课程PPT+个人理解
//2019.05.08
一、概念(是什么)
1、知识 :有不同的解释,可以是“不变的真理”、“经验、背景、解释”、“交工的信息”
(1)分类
- 陈述性知识 -> 描述客观事物的性状和关系等静态信息
-> 事物
->概念:一类事物本质反映
->命题:对事物间关系的陈述
-->非概括性命题:表示特定事物之间的关系
-->概括性命题:描述概念之间的普遍关系
- 过程性知识 ->描述问题如何求解等动态信息
->规则描述事物的因果
->控制结构描述问题的求解步骤
(2)知识库
在对各种知识进行收集和整理的基础上,进行形式化表示, 按照一定方法存储,并提供相应的知识查询手段,从而使知 识有序化,是知识共享和应用的基础,知识的编码化和数字化就形成知识。(理解:就是将所谓的知识做一定的处理,处理成一个统一的格式保存起来,并提供查询)
2、知识图谱(Knowledge Graph)
目前,大量非结构化数据在互联网中传播存储,计算机不擅长处理;图是一种有效表示数据之间结构的表达形式,考虑将数据中蕴含的知识用图结构进行形式化的表示,并与结构化数据进行关联,构成知识图谱。
(知识图谱是google用来支持从语义角度组织网络数据,从而提供智能搜索服务的知识库)
=>知识图谱是一种比较通用的语义知识的形式化描述框架,用节点表示语义符号,用边表示符号之间的语义关系。
3、相关术语
(1)Ontology(本体/存在) vs. Knowledge Base vs. Database
Ontology:一套对客观世界进行描述的共享概念化体系, 对特定领域中概念(对象类型)及其相互关系进行形式化 表达。用来进行领域建模或者推理。因此,重点是对数据 的定义进行描述,而没有描述具体的实例数据
Knowledge Base:服从于ontology 控制的知识实例及其 载体
Database:计算机科学家为了用电脑表示和存储计算机应 用中所需要的数据所设计开发的产品
例如:Ontology是蛋糕的模具,Knowledge Base是蛋糕, Database是存放蛋糕的盒子(理解:Ontology是一个模板,KV是用这个模板做出的一个具体的东西,然后用DB来存储)
(2)Ontology vs. Taxonomy(分类)
两者都是树状结构(应该都是两个知识的模板),但Ontology是严格的IsA关系,可适用于知识推理,但无法表示概念的二义性
4、知识图谱中数据的表示形式
-->三元组形式(二元关系):这就相当于一个框架(Schema/元知识),对知识进行描述和定义
知识框架和实例数据构成了一个完整的知识系统,那么在约定的框架下,对数据进行结构化,并与已有的结构化数据进行关联,就形成知识图谱。
总结:知识是认知,图谱是载体,数据库是实现,知识图谱就是在数据库系统上利用图谱这种抽象载体表示知识这种认知内容。
狭义知识图谱:是一种知识描述语言,是语义网络的思想在语义网上的具体实施,使得互联 网知识元素以及知识元素之间的关系具有明确的语义和规范的描述,从而易于互联网知识资源的规模 化建设,并互相链接,促进知识资源的共享,从而 通过知识推理与知识计算赋能各种互联网服务
广义知识图谱:是一个包括知识表示、知识构建、知识维护以及知识应用的完整生态系统,它不仅包含了特定领域中的知识定义和实例数据,还 包含了支撑描述、构建、存储、管理和应用知识所 需的配套标准、技术和工具。
二、发展历程
1、从AI:知识的数据化(让计算机表示、组织和存储人类的知识) -------> 语义网:数据的知识化(让数据支持推理等职能任务)
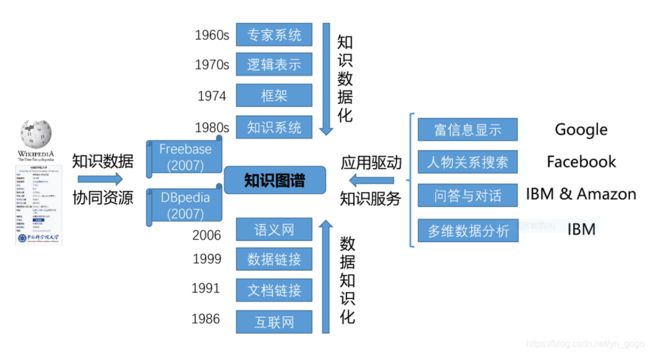
知识图谱 vs. 人工智能 vs. 万维网
人工智能研究热点:“如何自动学习和利用知识进行”---->知识工程是其重要组成部分。
万维网发展有两个局限:(1)使用超文本标记语言HTML,是面向人的存储和共享信息的媒介,但不方便机器去理解和浏览。
(2)是按照网址去定位信息资源,而非“内容的语义”,这缺少语义的联结
==>语义网(Semantic Web):智能网络,以Web数据的内容(数据的语义)为核心,用机器能够理解和处理的方式链接起来海量分布式数据库。
*挑战:要有支撑网络应用的大规模知识本体和知识库(Ontology);要有数据的语义标注和链接;要具有语义分析能力的搜索引擎。
2、常用知识图谱
- 谷歌知识图谱:试图通过知识图谱对于网页中的文本内容 ,特别是客观类事实性文本内容中的语义信息进行刻画, 从非结构化的文本内容中提取出实体及其关系,将文本内 容转化为相互连接的图谱结构,从而让计算机真正做到内 容理解。
- 百度之心:通过对搜索结果的筛选,将相近的信息组织在 一起,以知识图谱的形式呈现出来,提高搜索的准确性
- 搜狗知立方:通过搜集、挖掘互联网上的海量碎片信息并 汇总成图谱形式,以更好地支撑语义搜索、智能问答的服 务。
3、知识图谱的特点
- 人工智能应用不可或缺的基础资源
- 语义表达能力丰富(知识图谱源于语义网络,是一阶谓词的简化形式),能够胜任当前知识服务
- 描述形式统一(Ontology & Taxonomy),便于不同类型知识的集成与融合
- 表示方法对人类友好,给众包等方式编辑和构建知 识提供了便利
- 二元关系为基础的描述形式,便于知识的自动获取
- 表示方法对计算机友好,支持高效推理
- 基于图结构的数据格式,便于计算机系统的存储与检索
三、类型和代表性的知识图谱
1、类型
- 语言知识图谱(WordNet)
WordNet是一个英文电子词典和本体,采用人工标注的方法,将英文单词按照语义组成一个大的概念网络。词语被聚类成统一词集(Synset),每个同义词集表示一个基本的词汇语义概念,词集之间有多种语义关系:同义、反义、上下位(概括性较强的单词叫做特定性较强的单词的上位词(hypernym),特定性较强的单词叫做概括性较强的单词的下位词(hyponym),像红色是上位词,鲜红色是下位词)、整体、部分、蕴含、相似、因果
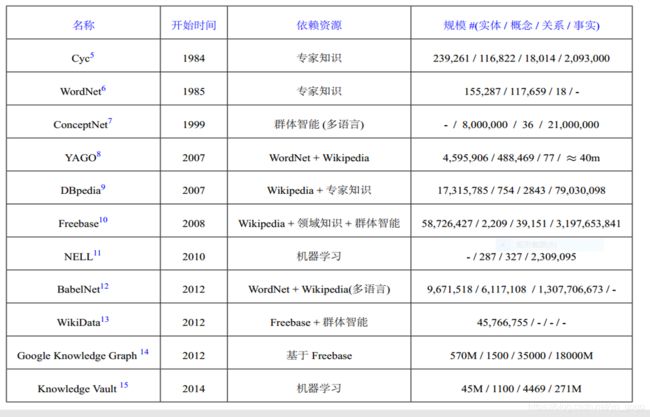
- 常识知识图谱(主要有 Cyc和 ConceptNet等。)
Cyc:通用常识知识库,目的是将上万条知识编码为机器可处理的形式,并在此基础上实现知识推理等智能信息处理任务
ConceptNet:开放的、多语言的知识图谱,起源于一个众包项目,致力于帮助计算机理解人们日常使用的单词的意义。
- 语言认知知识图谱(中文知网词库HowNet)
HowNet:一个语言认知知识库/常识知识库,以概念为中心,基于义原描述了概念与概念之间,以及概念所具有的属性之间的关系,每个概念可以由多种语言的词汇进行描述。
- 领域知识图谱(医学知识图谱 SIDER(Side Effect Resource) ,电影知识图谱 IMDB (Internet Movie Database) ,音乐知识图谱 MusicBrainz等,)
- 百科知识图谱( Freebase、DBpedia、YAGO和 Wikidata )
Wikipedia:免费的在线百科全书,目标是构建全世界最大的百科全书
DBPedia:其主要目标是构建一个社区,通过社区成员 来定义和撰写准确的抽取模板,从维基百科中抽取结构信息 ,并将其发布到Web上(*抽取方法:社区人工构建Ontology,采用DIEF框架去抽取Wiki的结构化信息)
YAGO:基于WordNet的知识体系,将Wiki的类别与WordNet中的类别进行关联,同时将Wiki中的条目挂载到WordNet的体系,使用RDFs语言与OWL语言进行描述,构成一个具有清晰完整逻辑定义的知识系统
BabelNet:是多语言词汇级的语义网络和本体,与YAGO类似,其主要特点是将维基百科连接到WordNet,但是多语言的,是维基百科与WordNet结合。
FreeBase:从wiki和其它数据源中导入知识,是基于维基百科、使用群体智能方法建立的结构化知识资源。其核心思想是,用FreeBase编辑结构化知识(Wiki中编辑文章),2010年被Google收购,并在2015年关闭,将全部数据迁移到了Wikidata
- 其它知识图谱
KnowltALL:文本抽取系统,目标是让机器自动阅读互联网上的文本内容,从大量非结构化的文本中抽取结构化的实体关系三元组信息。其抽取关系不再是预定义的(即知识抽取的范围是开放域文本);其代表系统是TextRuner和Reverb
NELL:基于Read the Web项目开发的一套“永不停歇的语言学习”系统,本身是一套语言学习系统,每天不间断的执行两项任务(阅读(从web文本中获取知识,并添加到内部知识库)和学习(提升机器学习算法的性能));其可以抽取大量的事实,并标注所抽取的迭代轮数、时间及系统置信度,供人工进行校验。
Knowledge Vault:大规模知识图谱,相比于FreeBase,其不再采用众包的方式进行构建,而是,通过算法自动搜索网上信息,通过机器学习方法对已有的结构化数据进行集成和融合,将其变为可用知识。
2、通用知识图谱 vs. 领域知识图谱
| 通用知识图谱 | 领域知识图谱 |
| 面向通用领域 | 面向某一特定领域 |
| 以常识性知识为主 | 基于行业数据构建 |
| 结构化的百科知识 | 基于语义技术的行业知识库 |
| 强调知识的广度 | 强调知识的深度 |
| 使用者是普通用户 | 潜在使用者是行业人员 |
通用知识图谱的广度+领域知识的深度,两者相互补充,形成更加完善的知识图谱。
*相关领域知识图谱
- 影视领域IMDB(Internet Movie Database)
- 音乐领域MusicBrainZ
- 医疗卫生领域SIDER
*企业相关知识图谱
- 阿里电商知识图谱
*Linked Open data:目的将有互联文档组成的网络(Web of Documents)扩展成为由互联数据组成的全球数据及知识共享平台(Web of Data),目标是以RDF语义在Web上发布各种开放数据集,并在不同来源的数据项之间建立语义链接,从而增强Web上的数据共享,最终实现语义Web知识资源的开放共享。
四、生命周期
1、知识体系构建(知识建模)
指采用什么样的方式表达知识,其核心是构建一个本体(知识的类别体系,每个类别下的概念和实体,概念实体等间的语义关系、推理规则)对目标知识进行描述。
相关技术:OntologyEngineering;
知识建模采用语义网的知识建模方式,分为概念、关系、概念关系三元组三个层次,并利用“资源描述框架(RDF)”;)
RDF的基本数据模型包括了三个对象类型:资源(Resouce:互联网上的实体、事件、概念等)、谓词(Predicate:关系)、陈述(Statements:一条陈述包含三个部分,其实称之为RDF三元组<主体,谓词,宾语>(当谓词表示关系是,并与可以是一个资源;当表示属性时,可以表示一个属性值)
2、知识获取和验证
从海量的文本数据中通过信息抽取的方式获取知识,其方法根据所处理数据源(结构化、半结构化、非结构化文本数据)的不同而不同
相关技术:信息抽取、文本挖掘
相关数据源特点:
| 结构化 | 半结构化 | 纯文本 | |
| 置信度 | 高 | 较高 | 低 |
| 规模 | 小 | 较大 | 大 |
| 个性化信息 | 缺乏 | 具备 | |
| 其它 | 形式多样 含有噪声 |
复杂多样 | |
| 抽取方式 | 抽取相对简单,经过人工过滤后就能得到高质量的结构化三元组 | 难度较大,但目前更多的信息是以非结构化文本的形式存在,因此,是构建核心 | |
*非结构化文本的实体关系抽取非常最重要!
知识获取类别:
- 实体识别:目标是从文本中识别实体信息,相关任务是实体抽取(命名实体、领域实体等))、
- 实体消歧:是建立语言表达和知识图谱联系的关键环节,从技术上可以划分为实体链接(将给定文本中的某一个实体指项链接到已有知识图谱中的某一个实体上(每个实体有唯一编号),结果就是消除了文本指称项歧义)和实体聚类(假设已有的知识图谱没有已经确定的实体,在给定一个语料库的前提下,通过聚类的方法消语料中所有同一实体指称项的歧义,具有相同所指的实体指称项应该被聚为同一类别)
- 关系抽取:目标是获取两个实体之间的语义关系(通常为一元/二元关系,还有上下位关系、部分整体关系、属性关系等)
- 事件抽取:目标是从描述事件信息的文本中抽取出用户感兴趣的事件信息并以结构化的形式呈现出来。根据抽取方法的不同,已有的事件抽取方法可以分为基于模式匹配的事件抽取和基于机器学习的事件抽取。
3、知识融合
对不同来源、不同语言或不同结构的知识进行融合,从而对于已有的知识图谱进行补充、更新和去重。
*相关技术:Ontology Matching、Entity Linking
*分类:
(1)融合对象角度:核心问题是计算两个知识图谱中两个节点或边之间的语义映射关系。
- 知识体系的融合:两个或多个异构知识体系进行融合,即对相同的类别、属性、关系进行映射。
- 实例的融合:对两个不同知识图谱中的实例(实体实例、关系实例)进行融合,包括不同知识体系下的实例、不同语言的实例。
(2)融合的知识图谱类型角度:
- 竖直方向的融合:融合(较)高层通用本体与(较)底层领域本体或实例数据。(融合Wordnet 和Wikipedia)
- 水平方向的融合:融合同层次的知识图谱,实现实例数据的互补。(融合Freebase 和DBpedia)
4、知识存储和查询(!!!!)
任务是研究采用何种方式将已有知识图谱进行存储。
*存储形式:目前大多是基于图的数据结构,存储方式主要有两种形式
- RDF格式存储:以三元组的形式存储数据(该方式搜索效率低)
- 图数据库:目前典型的开源数据库是Neo4j(比RDF更通用,具有完善的图查询语言,支持图挖掘算法,但是数据更新慢,大节点处理开销大,目前研究“子图筛选”、“子图同构判定”)
5、知识推理
目前知识推理的研究主要集中在针对知识图谱中确实关系的补足,即挖掘两个实体之间隐含的语义关系;其也应用在相关应用任务中(例如知识问答系统),其关键在于,如何将问题映射到知识图谱所支撑的结构表示中,在此基础上才能利用知识图谱中的上下文语义约束以及已有的知识推理,并结合常识等相关知识,得到正确答案。
*相关技术方法
- 基于传统逻辑规则的方法:研究如何自动学习推理规则,以及如何解决推理过程中的规则冲突问题。
- 基于表示学习的推理:即采用学习的方式,将传统推理过程转化成基于分布式表示的语义向量相似度计算任务。
6、知识应用
(1)
- 精准语义搜索(天眼查)
- 关系搜索(人立方)
- 智能问答
- 推荐
(2)领域知识图谱应用
- 金融证券:企业风险评估、反欺诈(目前应用很广!)
- 生物医疗:中医药知识服务平台、Watson辅助诊断与治疗、Open PHACTS 新药物发现
- 图书情报
- 电商
- 农业
- 政府
- 电信
- 出版
五、与其他课程的联系
AI分为计算智能(运算和存储能力)、感知智能(听觉、触觉、嗅觉->交互)、认知智能(推理、概括、演绎、监控等)
AI三大学派:符号主义、连接主义、行为主义
| 知识图谱 | 深度学习 | |
| 基于符号计算的AI | 基于数值计算的AI | |
| 知识表示 | 语言符号和知识符号 | 基于分布的表示 |
| 系统 | 符号逻辑系统 | 数值计算系统 |
| 语言和知识单元存储形式 | 蕴含在形式化符号机器结构中 | 蕴含在数值空间的点、线、面、子空间等单元之中 |
| 语义计算 | 精确匹配和梳理推算 | 数值演算 |
两者都有一定的优点和缺点,在实际应用中,将两者进行融合
六、相关会议
- ACL、IJCAI、AAAI、KDD、SIGIR、COLING、EMNLP、ISWC
- CCKS(主题:知识计算与语言理解,相关报告人员:张钹院士、玄难副总裁、Prof. James A. Hendler、Prof. Roberto Navigli)
理解:通过概述可以了解,接下来学习,即是展开知识图谱的各个生命周期:知识图谱的构建、知识的获取(知识抽取)、知识的融合、知识的存储与查询、知识推理、知识的应用。
具体理解和概括:
- 机器学习基础和图算法基础【课程第二周、第三周】(理解:机器学习在整个知识图谱中是一个具体处理数据的工具,每个步骤中或多或少的应用它处理数据,从而进行数据的转化,分析等;而图算法,更多的是提供了检索的方法,以及数据的分析等原理;着重去了解两ML的操作以及图算法的思想)
- 知识的表示【课程第四周】:是整个问题的前提和关键,只有定好了知识的表示方式,才可以将其形式化,进行下一步的处理和操作
- 知识体系的构建和知识融合【课程第五周】:确定了知识的表示方法,即可进行知识体系的构建,因为后面的知识融合方式差不多,一块进行了解,中间还要获取知识,这一步是重点,细处理
- 知识获取【课程第六、七、八、九周】:包含了实体识别和扩展、实体消歧、关系抽取、事件抽取
- 存储和检索【课程第十周】
- 知识推理和语义计算【课程第十一周】
- 知识应用【课程第十二周、十三周】:问答系统和对话系统
安排:把各个模块的思想、流程、基础弄清楚,目前感兴趣点在于存储和检索,跟自己相关专业沾边,同时,对于知识图谱这门课而言,知识获取和处理是重点,弄清楚相关的内容。先将内容了解,然后将相关论文弄清。