C语言:详解指针
本人录制技术视频地址:https://edu.csdn.net/lecturer/1899 欢迎观看。
指针应该算得上是c语言的精华,但也是难点。很多教程或者博客都有对其详细的讲解与分析。我这一节的内容,也是讲解指针,但我会尽量使用图解的方式,使大家很容易理解及掌握。
一、基本使用
先来看看下面的代码:
int i = 3;
int *p;
p = &i;
printf("i 存放的内容的值: %d, i 自己所在的地址: %p\n", i, &i);
printf("p 存放的地址的值: %p; p 自己所在的地址: %p; p 存放的地址所指所存放内容的值: %d", p, &p, *p);
return 0;变量p是int *类型,所以存放的是指向int类型的地址。
这样说,似乎还是没有表达清楚,我使用下面的一张图进行说明:

1. int i = 3; 这句话执行完毕之后,变量i中的内容是3,假设 变量i本身的内存地址为 "0x8000"。
2. int *p; 只是为指针变量p申请了一块内存地址,假设它的内存地址为 "0x7000",此时变量p中存放的内容为nil。
3. p = &i; 表示将变量i的地址赋值给指针p所存放的内容,至此,就呈现出了上图的情形。
所以程序中的那两句打印结果就很明显了。
i 存放的内容的值: 3, i 自己所在的地址: 0x8000
p 存放的地址的值: 0x8000; p 自己所在的地址: 0x7000; p 存放的地址所指所存放内容的值: 3
二、 交换两个整数的值
示例代码如下:
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
int main(int argc, const char * argv[]) {
int a = 3, b = 5;
swap(&a ,&b);
printf("a: %d; b: %d", a ,b);
return 0;
}

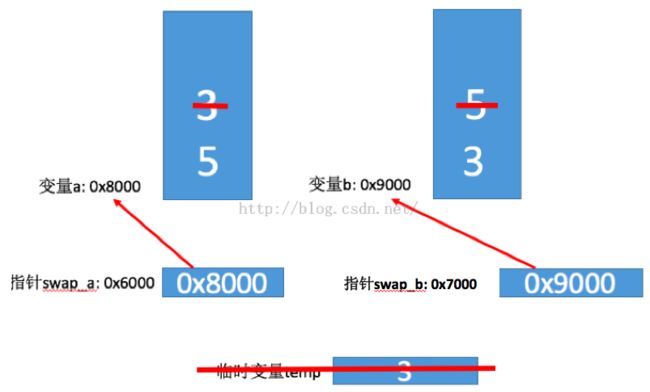
然后调用swap(&a, &b); 注意,这里传递的是变量a, b 本身的地址。而函数swap的接受形参int *a, int *b均是指针变量,用来接受传递过来的变量a, b的地址,即传递过来的变量a, b 和 函数 swap中的形式参数a, b 完全是两回事;为了以示区别,我将形参中的a, b 表达为 swap_a, swap_b。所以将变量a, b 的地址赋值给swap_a 和 swap_b 之后,内存中的地址分布大致如下(假设swap_a本身的地址为0x6000, swap_b本身的地址为0x7000)。
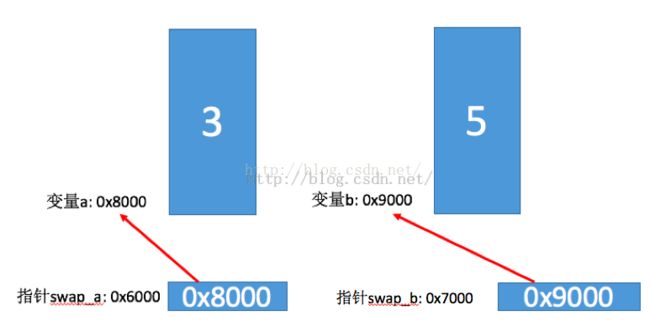
int temp = *a, 定义一个临时变量temp,用来存储指针swap_a 所指向变量a所存储的值,所以临时变量temp此时存储的值为3,如下图:
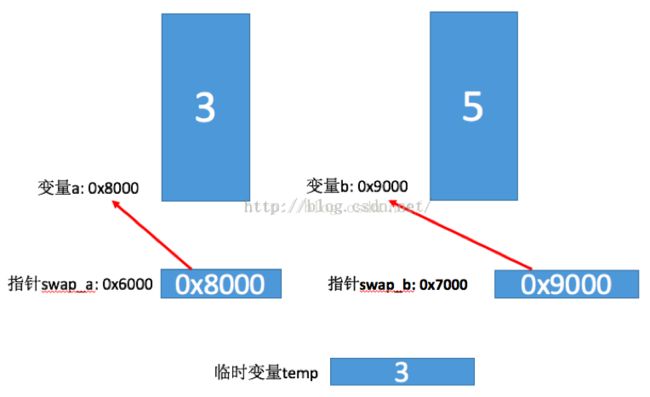
*a = *b, 表示将将指针swap_b所指向变量b的内容赋值给指针swap_a所指向变量a的内容,所以执行完毕之后,内存图大致如下:
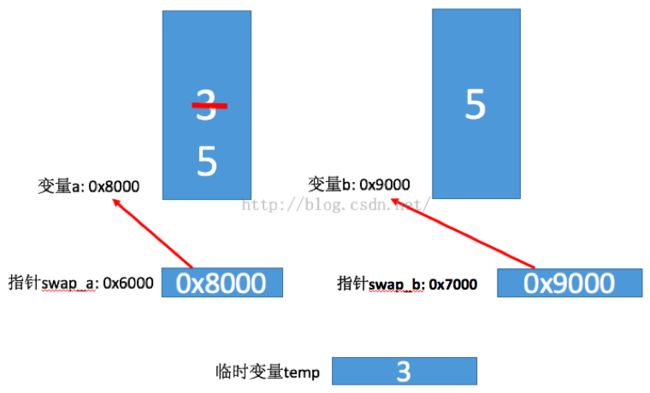
最后一句代码 *b = temp, 就是将temp所存储的内容赋值给指针swap_b所指向的变量b存储的内容,所以执行完这句话之后,内存图大致如下:
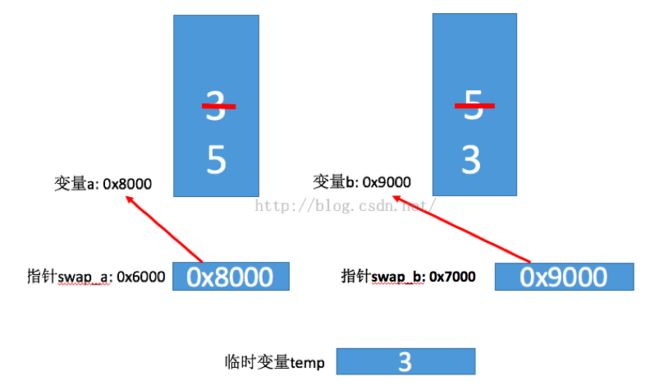
当程序执行到swap函数 右边 “}” 结束后,此时,表示函数swap已经结束,而变量temp是局部变量,所以此时它也会被立刻销毁,所以最终的内存结构图大致而下:
通过上面两个例子的图解,相信大家对指针的概念有了初步的了解,下面的内容,我就直接讲解其内容不做画图处理了,如果自己感兴趣的话,也可以画图尝试尝试。
三、 字符数组与字符串常量
1. 字符数组
char str[] = "good";
while (*str != '\0') {
putchar(*str++);
}2. 字符串常量
char *str2 = "good";
while (*str2 != '\0') {
putchar(*str2++);
}比如下面的Demo
const char *str = "hello";
printf("address: %p\t%s\t%c\n", &str,str, *str);
str++;
printf("address: %p\t%s\n", &str,str);address: 0x7fff5fbff6b8helloh
address: 0x7fff5fbff6b8ello
所以str的值就是指针所在位置及后面字符的值,而*str取得的就是指针所在位置字符的值。四、函数指针
示例代码:
int add(int num1, int num2) {
return num1 + num2;
}
int main(int argc, const char * argv[]) {
printf("result:%d", add(1, 2));
printf("\n%p", add);
int (*p)(int,int) = add;
printf("\n%d", p(3, 4));
return 0;
}int (*p)(int,int) = add;五、 泛型指针
泛型指针就是在定义的时候还不知道指针的具体类型,直到调用的时候才确定类型,并且进行相应的强制类型转换工作,完成任务。泛型指针的形式就是void *。下面用泛型指针实现一个冒泡排序,代码如下:
void init_array(int *a, int n) {
srand(time(NULL));
for (int i = 0; i < n; i++) {
a[i] = rand() % 100;
}
}
int cmp_array(void *a, void *b) {
int num1 = *((int *)a);
int num2 = *((int *)b);
return num1 > num2;
}
void swap_array(void *a, void *b) {
int temp = *((int *)a);
*((int *)a) = *((int *)b);
*((int *)b) = temp;
}
// 这里的void * 就是 泛型指针,需要进行指针转换,达到自己想要的结果
void sort_array(int *a, int n, int (*cmp)(void *, void *), void (*swap)(void *, void *)){
int i,j;
// 冒泡排序
for (i = 0; i < n; i++) {
for (j = 0; j < n - i - 1; j++) {
if (cmp(&a[j], &a[j+1])) {
swap(&a[j], &a[j+1]);
}
}
}
}
int main(int argc, const char * argv[]) {
int a[10];
init_array(a, 10);
sort_array(a, 10, cmp_array, swap_array);
return 0;
}
在c语言中,书写起来看起来是有点复杂了,其实现在的高级语言没有必要这么麻烦了,用泛型就可以解决问题了,但是这些高级语言的泛型底层还是依赖于c语言的泛型指针。
六、更为复杂的指针
注:以下的测试代码均为在64位系统处理所得。
1) 指针数组
char *p[10];
printf("sizeof(p):%lu \t sizeof(*p):%lu\n",sizeof(p), sizeof(*p));1. p存放的是一个指针数组的首地址,而指针数组中每一个元素又是指向char *类型元素的地址。
2. sizeof(p)计算的是数组字节大小,输出80,而sizeof(*p)是计算首元素中存放内容的大小,而存放的内容是地址,所以结果为8。
3. p+1 就是 p[1], 每一个地址中存放的就是char *类型元素的地址,即8个字节,所以p+1的地址是在首元素地址的基础上面加8。
最终打印结果:
sizeof(p):80 sizeof(*p):8
2) 指针的指针
char **pl;
printf("sizeof(pl):%lu \t sizeof(*pl):%lu, \t **pl:%lu \t pl:%p \t pl+1:%p\n",sizeof(pl), sizeof(*pl), sizeof(**p), p, p+1);1. pl是指针的指针,所以pl指向的是一个指针的地址,所以sizeof(pl)结果为8, 打印出来的pl是一个地址,由于pl指向的是一个“指针的地址”,而“指针的地址”存放的是char类型变量的地址,所以占8个字节,所以pl+1 比pl大8。
2. *pl指向char类型变量的,所以它存放的是char类型变量的地址,所以sizeof(*pl)结果为8。
3. **pl,获取char类型变量的值,由于是char类型,所以sizeof(**p)结果为1。
最终打印结果:
sizeof(pl):8 sizeof(*pl):8, **pl:1 pl:0x7fff5fbff6b0 pl+1:0x7fff5fbff6b8
char (*pt)(void);1. pt存放的是函数的首地址,所以sizeof(pt)结果为8
2. *pt 获取的是函数内部的代码块,所以sizeof(*pt) 和 pt + 1 均没有实际意义
char (*pk)[10]; // 数组指针
printf("sizeof(pk):%lu \t sizeof(*pk):%lu, pk:%p \t *pk:%p \t pk + 1:%p \t *pk + 1: %p\n",sizeof(pk), sizeof(*pk),pk,*pk, pk + 1, *pk + 1);1. char (*pk)[10];相当于二维数组 char a[][10]
2. pk相当于指向二维数组的指针,存放的是地址,所以sizeof(pk)结果为8;pk存放的是整个二维数组的首地址; pk + 1 就是相当于指针移动了一个一维数组的距离,所以地址在pk的基础上面加了10.
3. *pk就是取得二维数组第一行的值,它是一个含有10个char元素的一维数组,所以sizeof(*pk)结果为10;*pk存放的是二维数组中第一维数组的首地址; *pk + 1就是在一维数组的基础上,移动了一个char的距离,所以地址在*pk基础上面加1。
4. 所以 pk和*pk打印的地址结果是一样的。
最终打印结果:sizeof(pk):8 sizeof(*pk):10, pk:0x7fff5fc27190 *pk:0x7fff5fc27190 pk + 1:0x7fff5fc2719a *pk + 1: 0x7fff5fc27191