【one way的pytorch学习笔记】(五)构建基础神经网络LeNet
基础LeNet
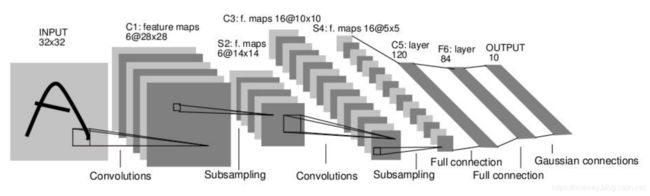
定义网络
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 3x3 square convolution
# kernel
self.conv1 = nn.Conv2d(1, 6, 3)
self.conv2 = nn.Conv2d(6, 16, 3)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 6 * 6, 120) # 6*6 from image dimension
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)
在pytorch中,通常来说,可以通过建立网络的class来实现(方法之一,个人比较推荐). 新建的网络继承nn.Module 基类.构建新的神经网络class的顺序:
-
定义__init__(),并 super 父类(因为需要实例化父类中的参数)初始化相关的网络层,需要在__init__()中初始化的类型:
1.一般来说将torch.nn中的相关层在init中初始化(),以torch.nn.Conv2d为例, 也就是说 torch.nn.Conv2d这种"函数"其实是个 Module类,在实例化类后会初始化2d卷积所需要的参数. 这些参数会在你做forward和 backward之后根据loss进行更新,所以通常存放在定义模型的 init() 中.
2.torch.nn.functional 中所需要的初始化参数,需要在__init__()中定义
具体细节请查看Pytoch 中 torch.nn 与 torch.nn.functional 的区别 -
定义forward():
输入项为x, 定义forward的整个流程
-
额外辅助函数
可以加可以不加, 为了更好的进行forward,可以创建相关函数
-
我们只需要定义forward函数,backward函数会自动根据autograd定义
可学习的参数记录可以通过 net.parameters()函数返回
params = list(net.parameters())
print(len(params))
print(params[0].size()) # conv1's .weight
10
torch.Size([6, 1, 3, 3])
用随机32x32tensor做输入,跑前向:
input = torch.randn(1, 1, 32, 32)
out = net(input)
print(out)
tensor([[-0.1564, 0.1191, 0.0464, -0.0260, -0.1250, 0.0476, 0.0177, -0.1471,
0.0538, 0.0109]], grad_fn=)
将所有参数的.grad缓存全部置0用随机梯度做backpropagation
net.zero_grad()
out.backward(torch.randn(1, 10))
torch.nn 仅支持mini batch处理,不支持单个样本的处理,例如 nn.Conv2d需要的输入图像为4维 nSamples x nChannels x Height x Width,如果需要输入单张图片,需要 input.unsqueeze(0)升维
loss 函数
mean squared error
output = net(input)
target = torch.randn(10) # a dummy target, for example
target = target.view(1, -1) # make it the same shape as output
criterion = nn.MSELoss()
loss = criterion(output, target)
print(loss)
tensor(0.8938, grad_fn=)
其实本质上,nn. 引导的loss functions也是一个类,和nn.Conv2D之类的layer层具有一样的父类Module,Module是一个可调类,本质上是通过 __ call__()来调用定义的forward().
另: 其实torch.nn.functional中的函数与torch.nn中最直接的区别是一个是函数,一个是类. 但是他们是有联系的, torch.nn往往是在forward()函数中调用torch.nn.functional来实现的.也就是说torch.nn相当于包装了的torch.nn.functional
loss 和其他layer 的操作是平级的,因为他们本质上是一致的,操作流程也是一致的. 因此完全可以把loss当成额外的一层"layer"(虽然它在结构上不属于layer,但在实现上是按照layer层的运行规则去实现的)
查看backward的graph就会看到
input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d
-> view -> linear -> relu -> linear -> relu -> linear
-> MSELoss
-> loss
print(loss.grad_fn) # MSELoss
print(loss.grad_fn.next_functions[0][0]) # Linear
print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # ReLU
Backprop
要想完成backpropagation,我们只需要用 loss.backward()这一句就行了.但是我们在每次操作前需要把现有的参数的grad清零,否则这些缓存的参数则会被累计到当前backward()后得到的梯度上.
net.zero_grad() # zeroes the gradient buffers of all parameters
print('conv1.bias.grad before backward')
print(net.conv1.bias.grad)
loss.backward()
print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)
conv1.bias.grad before backward
tensor([0., 0., 0., 0., 0., 0.])
conv1.bias.grad after backward
tensor([ 0.0012, 0.0053, -0.0044, 0.0030, -0.0081, 0.0011])
反向传播在代码上很简单,如果想要了解详细的 autograd过程和反向传播的流程机制,请参阅
- one way的pytorch学习笔记(二)autograd自动求导
- one way的pytorch学习笔记(三)leaf 叶子(张量)
- one way的pytorch学习笔记(四)autograd的流程机制原理
更新参数
最简单的更新参数的方法为随机梯度下降(SGD):
w e i g h t = w e i g h t − l e a r n i n g r a t e ∗ g r a d i e n t weight = weight - learning_rate * gradient weight=weight−learningrate∗gradient
我们可以通过一下代码实现
learning_rate = 0.01
for f in net.parameters():
f.data.sub_(f.grad.data * learning_rate)
如果想要用其他优化算法的话需要用到torch.optim包:
import torch.optim as optim
# create your optimizer
optimizer = optim.SGD(net.parameters(), lr=0.01)
# in your training loop:
optimizer.zero_grad() # zero the gradient buffers
output = net(input)
loss = criterion(output, target)
loss.backward()
optimizer.step() # Does the update