机器学习六之决策树
-
目录
十六、决策树
1、信息论里基本概念
1)熵
2)联合熵
3)条件熵
4)互信息(信息增益)
2、ID3
缺点和不足
3、C4.5
缺点和不足
4、CART树
决策树剪枝
决策树优缺点
决策树算法的优点:
决策树算法的缺点:
-
十六、决策树
-
1、信息论里基本概念
为了更好的理解,需要了解的概率必备知识有:
大写字母X表示随机变量,小写字母x表示随机变量X的某个具体的取值;
P(X): 随机变量X的概率分布,
P(X,Y): 随机变量X、Y的联合概率分布,
P(Y|X): 已知随机变量X的情况下随机变量Y的条件概率分布;
p(X = x): 随机变量X取某个具体值的概率,简记为p(x);
p(X = x, Y = y) : 联合概率,简记为p(x,y),
p(Y = y|X = x): 条件概率,简记为p(y|x),且有:p(x,y) = p(x) * p(y|x)。
1)熵
如果一个随机变量X的可能取值为X = {x1, x2,…, xk},其概率分布为P(X = xi) = pi(i = 1,2, ..., n),则随机变量X的熵定义为:

2)联合熵
两个随机变量X,Y的联合分布,可以形成联合熵Joint Entropy,用H(X,Y)表示。
3)条件熵
在随机变量X发生的前提下,随机变量Y发生所新带来的熵定义为Y的条件熵,用H(Y|X)表示,用来衡量在已知随机变量X的条件下随机变量Y的不确定性。
且有此式子成立:H(Y|X) = H(X,Y) – H(X),整个式子表示(X,Y)发生所包含的熵减去X单独发生包含的熵。至于怎么得来的请看推导:

简单解释下上面的推导过程。整个式子共6行,其中
第二行推到第三行的依据是边缘分布p(x)等于联合分布p(x,y)的和;
第三行推到第四行的依据是把公因子logp(x)乘进去,然后把x,y写在一起;
第四行推到第五行的依据是:因为两个sigma都有p(x,y),故提取公因子p(x,y)放到外边,然后把里边的-(log p(x,y) - log p(x))写成- log (p(x,y)/p(x) ) ;
第五行推到第六行的依据是:p(x,y) = p(x) * p(y|x),故p(x,y) / p(x) = p(y|x)。
相对熵(交叉熵或KL散度):又称互熵,交叉熵,鉴别信息,Kullback熵,Kullback-Leible散度等。设p(x)、q(x)是X中取值的两个概率分布,则p对q的相对熵是:

在一定程度上,相对熵可以度量两个随机变量的“距离”,且有D(p||q) ≠D(q||p)。另外,值得一提的是,D(p||q)是必然大于等于0的。
4)互信息(信息增益)
两个随机变量X,Y的互信息定义为X,Y的联合分布和各自独立分布乘积的相对熵,用I(X,Y)表示:

且有I(X,Y)=D(P(X,Y) || P(X)P(Y))。下面,咱们来计算下H(Y)-I(X,Y)的结果,如下:

通过上面的计算过程,我们发现竟然有H(Y)-I(X,Y) = H(Y|X)。故通过条件熵的定义,有:H(Y|X) = H(X,Y) - H(X),而根据互信息定义展开得到H(Y|X) = H(Y) - I(X,Y),把前者跟后者结合起来,便有I(X,Y)= H(X) + H(Y) - H(X,Y),此结论被多数文献作为互信息的定义。
2、ID3
我们有15个样本D,输出为0或者1。其中有9个输出为1, 6个输出为0。 样本中有个特征A,取值为A1,A2和A3。在取值为A1的样本的输出中,有3个输出为1, 2个输出为0,取值为A2的样本输出中,2个输出为1,3个输出为0, 在取值为A3的样本中,4个输出为1,1个输出为0.
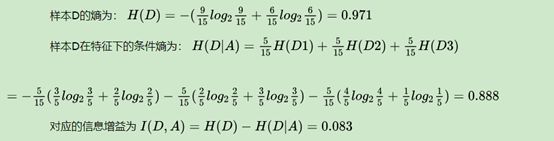
缺点和不足
a) ID3没有考虑连续特征,比如长度,密度都是连续值,无法在ID3运用。这大大限制了ID3的用途。
b) ID3采用信息增益大的特征优先建立决策树的节点。很快就被人发现,在相同条件下,取值比较多的特征比取值少的特征信息增益大。比如一个变量有2个值,各为1/2,另一个变量为3个值,各为1/3,其实他们都是完全不确定的变量,但是取3个值的比取2个值的信息增益大。
c) 没有考虑过拟合的问题
3、C4.5
1)对于第一个问题,不能处理连续特征, C4.5的思路是将连续的特征离散化。比如m个样本的连续特征A有m个,从小到大排列为a1,a2,...,am,则C4.5取相邻两样本值的平均数,一共取得m-1个划分点,其中第i个划分点表示Ti表示为:
![]()
2)对于第二个问题,信息增益作为标准容易偏向于取值较多的特征的问题。我们引入一个信息增益比的变量IR(X,Y),它是信息增益和特征熵的比值。表达式如下:
![]()
其中D为样本特征输出的集合,A为样本特征,对于特征熵HA(D), 表达式如下:
![]()
其中n为特征A的类别数, Di为特征A的第i个取值对应的样本个数。D为样本个数。
3)对于第三个问题C4.5引入了正则化系数进行初步的剪枝.
缺点和不足
1) 由于决策树算法非常容易过拟合,因此对于生成的决策树必须要进行剪枝。剪枝的算法有非常多,C4.5的剪枝方法有优化的空间。思路主要是两种,一种是预剪枝,即在生成决策树的时候就决定是否剪枝。另一个是后剪枝,即先生成决策树,再通过交叉验证来剪枝。后面在下篇讲CART树的时候我们会专门讲决策树的减枝思路,主要采用的是后剪枝加上交叉验证选择最合适的决策树。
2) C4.5生成的是多叉树,即一个父节点可以有多个节点。在计算机中二叉树模型会比多叉树运算效率高。如果采用二叉树,可以提高效率。
3) C4.5只能用于分类,如果能将决策树用于回归的话可以扩大它的使用范围。
4) C4.5由于使用了熵模型,里面有大量的耗时的对数运算。
4、CART树
CART分类树算法使用基尼系数来代替信息增益比,基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好。这和信息增益(比)是相反的。
具体的,在分类问题中,假设有K个类别,第k个类别的概率为pk, 则基尼系数的表达式为:
![]()
对于个给定的样本D,假设有K个类别, 第k个类别的数量为Ck,则样本D的基尼系数表达式为:

决策树剪枝
CART采用的办法是后剪枝法,即先生成决策树,然后产生所有可能的剪枝后的CART树,然后使用交叉验证来检验各种剪枝的效果,选择泛化能力最好的剪枝策略。其损失函数:
![]()

决策树优缺点
决策树算法的优点:
1)简单直观,生成的决策树很直观。
2)基本不需要预处理,不需要提前归一化,处理缺失值。
3)使用决策树预测的代价是。 m为样本数。
4)既可以处理离散值也可以处理连续值。很多算法只是专注于离散值或者连续值。
5)可以处理多维度输出的分类问题。
6)相比于神经网络之类的黑盒分类模型,决策树在逻辑上可以得到很好的解释
7)可以交叉验证的剪枝来选择模型,从而提高泛化能力。
8) 对于异常点的容错能力好,健壮性高。
决策树算法的缺点:
1)决策树算法非常容易过拟合,导致泛化能力不强。可以通过设置节点最少样本数量和限制决策树深度来改进。
2)决策树会因为样本发生一点点的改动,就会导致树结构的剧烈改变。这个可以通过集成学习之类的方法解决。
3)寻找最优的决策树是一个NP难的问题,我们一般是通过启发式方法,容易陷入局部最优。可以通过集成学习之类的方法来改善。
4)有些比较复杂的关系,决策树很难学习,比如异或。这个就没有办法了,一般这种关系可以换神经网络分类方法来解决。
5)如果某些特征的样本比例过大,生成决策树容易偏向于这些特征。这个可以通过调节样本权重来改善。
参考资料:
李航《统计学习方法》
http://www.cnblogs.com/jiangxinyang/p/9337094.html
https://blog.csdn.net/wjwfighting/article/details/82532847
https://www.cnblogs.com/pinard/category/894692.html
https://www.baidu.com/link?url=HfzWgzeRIWPH08txoXXCO7lJBotxDpxOfRDJE44TUY_-sKMQnXXrXZ7e3-Vs9BBsjKsd7ZXZ9v8_QjWj4fcIzNHVxZ8PnbhWOmUUvjeff0m&wd=&eqid=ffca968a000e7f22000000035bab7277
声明:本人从互联网搜集了一些资料整理,由于查找资料太多,好多内容出处不能记得,如有侵权内容,请各位博主及时联系我,我将尽快修改,并注明出处,再次感谢各位广大博主的资料。