边缘计算与云计算的未来

本文为翻译发表,转载需要注明来自公众号EAWorld。
作者:Gokhan Simsek
译者:白小白
原题:
Edge Computing and the Future of the Cloud
原文:
https://softwareengineeringdaily.com/2018/09/14/edge-computing-and-the-future-of-the-cloud/
全文4681字,阅读约需要10分钟
“Edge(边缘)”和“Fog(雾)”是我们不断听到的新流行词汇。什么是边缘计算,又有哪些应用场景?要谈论这些,我们需要了解边缘计算的产生过程。让我们从一节简短的历史课开始。
一、边缘计算的历史
在过去的几十年中,计算基础设施在集中式和分散式体系结构之间经历了多次变迁。简单讲,顾名思义,集中式计算体系中,会有一台中央计算机,其他多台计算机可以通过终端访问这台计算机。而在分散式计算体系中,会有多台独立的计算机或机器,通过各种协议相互通信。
20世纪50年代,在商业计算开始时,集中式计算在大型、昂贵的主机系统中大行其道。自主机时代以来一直到1997年,计算体系架构就经历了集中和分散的两个周期(来源 http://t.cn/Ez2FVOg)。这时,家用台式电脑已经随着硬件的降价而广泛普及。这是最后一次分散化的进程,此后便是著名的集中式云体系结构,巨型的数据中心基本上承揽了所有的重要任务。现在,边缘计算正在敲门,为下一次换班做准备。
云服务是当前的集中式体系范例。几乎所有的网络内容都是通过一个主要的数据中心提供的。研究人员从云端租借他们的私有服务器来测试他们的模型并进行实验,企业在远程服务器中执行业务逻辑。云服务为企业提供了一种便捷的资源获取方式,无论是小企业还是大企业,都可以通过服务提供商获得计算资源,而不是构建自己的数据中心供使用。云服务的应用随处可见,AWS、DigitalSea、Azure、GoogleCloud、VMWare在开发人员中耳熟能详。但是,情况在发生变化。是什么导致了对边缘设备和边缘计算更受重视的新趋势?边缘到底是什么?
二、定义边缘计算
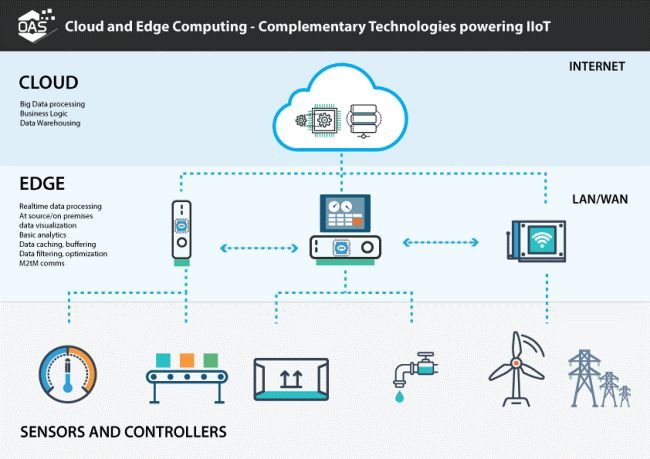
云服务与边缘计算-图表
(来源http://t.cn/Ez2kkBz)
在Aran Khanna的“边缘深度学习”(来源 http://t.cn/Ez2kpQ3)一文中,给边缘设备下了一个非常简洁的定义。“边缘设备本质上是位于数据中心之外的任何设备。”因此,“边缘计算”是一种新的模式,将大量的计算和存储资源放置在互联网的边缘,靠近移动设备或传感器(来源 http://t.cn/Ez2kveR )。
边缘设备可能是你现在使用的手机。可以是街道和银行周围的监控摄像头。他们也不一定是体积很小的的东西,自动驾驶汽车也被认为是边缘设备。就像Peter Levine所讲的 (来源http://t.cn/Ez2DmX1),使用这些设备,实时和现实世界的信息收集变得更加容易,并且随着物联网设备的普及,信息收集也越来越广泛。此外,这些设备会生成许多真实世界的数据,如图像和视频。
边缘设备不断丰富的最大问题之一是产生的数据量越来越庞大。一个帧速率为10赫兹的监视摄像机可以产生超过每秒250 MB数据(来源 http://t.cn/Ez2DTVL)。将飞行数据连网的飞机每天生成5TB的数据。自动驾驶汽车每天4TB数据(来源 http://t.cn/Ez2DNP1)。这些还仅是针对个人设备的统计。想象一下,如果这些设备中一部分将原始数据发送到集中式服务器,那通信量将有多大。在需要进行准实时处理的场景下,设备的带宽和延迟问题是云计算结构不再适用的原因之一。
另一个问题是能源消耗。Harvard SEAS的一位计算机架构师David Brooks指出,在互联网上传输一个比特位的能源消耗是500微焦耳(来源 http://t.cn/Ez2DizS)。根据他的计算,2015年,每个月的手机数据使用量为3.7EB,从而达到500太瓦时的能源消耗,世界上2%的能源消耗用于移动电话的数据传输。而边缘计算可以大大降低这种能源消耗。
白小白:
此处原文的数据是有问题的,或者说原文所引用的Brooks的原话是有问题的。这段数据来自视频中3分50秒处开始, 5分钟左右有个小笑点,也是关于500太瓦时这个数据的引用处。3.7EB是3.41*10^19Bit,从而是1.7*10^22Microjoule,即4.73*10^9KWh,即4.73Terawatt,而原文是500Terawatt。按2015年全球耗电21153TW(数据来源statista.com)来说,手机数据的耗电占0.27%,按照500TW计算则为2.36%。Anyway,文章主要想强调的是边缘计算可以带来的能源节约。
在使用云服务时,一个重要的考虑因素是隐私和安全性。数据泄露越来越普遍。(来源http://t.cn/R8vdP0f)以及必须确保用户隐私的组织(如医院)不能直接向其云服务发送原始数据。这就必须在边缘层面进行预处理。
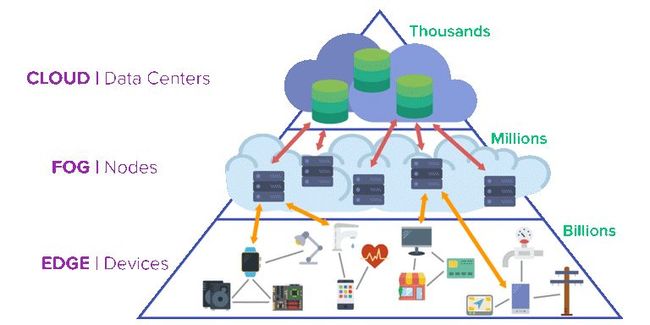
边缘计算金字塔
(来源 http://t.cn/Ez2eGob)
由于上述的场景和问题,边缘计算应运而生。在这种体系结构中,无论是以设备本地执行计算的形式,还是通过在设备附近部署一个微型云的方式,或者两种形态的组合方式,计算行为都在物理上更接近设备。由微型云组成的中间层有时也被称为“雾”,而这些云有时被称为“雾节点”。这种“云-雾-边缘”架构带来了许多好处。其中四个主要优点是延迟时间短、边缘分析成本低、隐私策略的加强以及可靠性的提高(来源 http://t.cn/Ez2FFYq)。
与云相比,边缘设备和雾节点在物理上更接近,通常只有一步之遥,而边缘设备到中心云节点通常路途遥远。雾节点甚至可以通过有线连接到边缘设备。这提供了更低的延迟和更高的带宽,因为与中心云相比,雾节点连接到的设备数量要少得多。在雾节点中管理数据可以带来更低的响应时间消耗。(来源 http://t.cn/Ez2FFYq)。
边缘设备收集的数据是巨大的,特别是由高速率数据设备收集的数据.将所有这些数据发送到云端进行分析和推断会占用宝贵的带宽,而且在许多情况下是不可能实现的。在边缘设备或雾节点执行诸如采样和消隐之类的预处理可以大大减少正在传输的数据量,并允许将结构化数据直接发送到中心云端存储或进一步处理。因此,以较低的成本,消耗较少的带宽和能源是可以实现的。在本地节点上进行的这种预处理还可以确保执行必要的隐私策略,例如从医院报告中编辑敏感和可识别的信息,以及模糊来自摄像机的面部信息。
哪里有海量数据,哪里就有机器学习。因此,边缘设备和边缘计算与机器学习有着密切的关系。例如,一个监视摄像头不断地生成它所覆盖的区域的图像。这种相机可能会利用深度学习来识别人类或汽车等特定的物体,并且可以移动视角以保持监视信息的完整。自动驾驶汽车需要根据从传感器和摄像机接收到的数据来计算其下一个动作,所有这些因素都必须通过机器学习模型进行适当的推理。一个有趣的用例是Chang等人关于使用机器学习进行网络边缘缓存的工作。他们声称,通过准确分析用户在某一区域的行为,从移动电话和个人电脑等边缘设备获取数据,并在数据上构建无监督学习的集群,可以主动地将适当的内容缓存在用户的边缘设备中或在邻近区域的云端,以获得较低的延迟并节约能源。随着物联网应用越来越富有创造力,并渗透到我们的日常生活中,机器学习在边缘的应用可能是无限的。
三、边缘计算与机器学习的复杂性
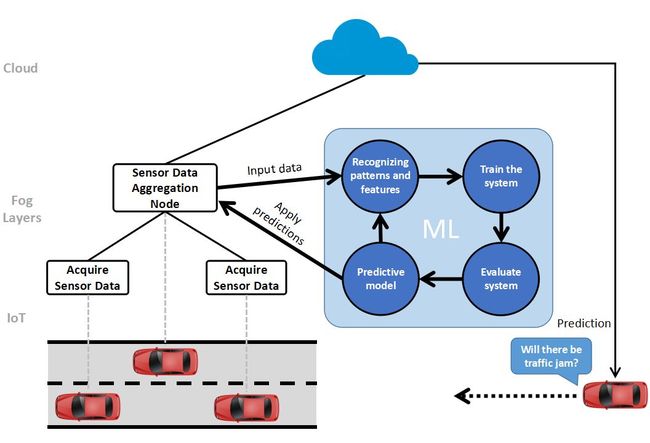
一种用于在边缘计算环境中进行机器学习的示例模型
(来源http://t.cn/Ez2sDRQ )
与中心云服务器或雾节点相比,边缘设备的内存要小得多,计算能力也要小得多。然而,大多数这些设备必须根据它们收集到的输入信息做出近乎实时的决定。这些设备中的大多数不可能保存它们生成的数据,并使用这些数据来构建机器学习模型。过去几年,大多数应用程序是处理推断(注)的方式,是将数据上传到云中,并通过云中的模型运行输入数据 ,并将响应结果返回到边缘设备。然而,对于需要近乎实时响应的应用程序来说,这不是一个理想的解决方案。
白小白:
所谓推断。举例来说,就是给神经网络一堆猫的图片进行训练学习,当给定一堆新的图片时,模型从中找出猫的过程。当然这只是人工智能的应用场景之一,即图像识别。关于人工智能和机器学习,更多的内容,可以参考宋潇男的文章《AI杂谈:从洗衣机到老鼠屁股》和《一起来DIY一个人工智能实验室吧》 以及李广珍博士的《拥抱人工智能,从机器学习开始》 。
在这种情况下,有几种边缘计算的方案可供选择:
方案一:将训练好的模型放在边缘设备
模型在远程机器中训练并部署到边缘设备上,这样,智能手机等移动设备具有足够的计算能力和内存来执行模型和推理。在这种情况下,边缘设备所收集的数据可以通过部署的模型运行,并且可以实现近乎实时的推断。然后,这些数据可以发送到云,并通过迁移学习,集成到现有的模型中,以提高其准确性。听起来不错吧?不完全是。
白小白:
迁移学习,是将学习到的知识进行存储和转移以解决新问题的方法。简单讲,学会了识别小汽车,就可以将相关知识转移到识别卡车的模型中,至少关于轮子、后视镜等存在一定的共通性。

亚马逊的人工智能和该公司如何使用边缘
(来源 http://t.cn/EzLLyqc)
方案二:对模型本身进行瘦身(压缩)
这些模型本身可能相当大,特别是典型的具有无数参数和权重值过滤器的深度学习模型。这种大小可能使边缘设备无力运行经过训练的模型,也可能阻碍设备生成和保存生成的数据的能力。然而,有一些技巧可以执行。在云上训练的占用更多空间的模型可以采用“量化”的方式来进行瘦身从而部署在边缘设备上(来源 http://t.cn/Ez2kpQ3 )。量化过程基本上是将机器学习模型中权值的大小从32位浮点权值减少到16位或8位的精度。这不仅有助于简化模型,而且还允许更快的执行推断,而不需要为边缘设备创建不同的流水线和单独建立不同的模型。这种方法的一个小缺点是精度略有降低,但在需要更快推理而非追求完美精确的应用中,这可能是非常有益的(来源 http://t.cn/EzLybGa)。
白小白:
所谓流水线。是指机器学习的模型通常需要整合多个组成部分和环节在一起来输出最终的结果,这个整合的过程即“流水线”,有点类似于软件开发过程中,开发->编译->部署->预生产->生产,数据科学也有源数据的提取转换->预处理->特征选取->模型训练等一系列的过程。段尾作者给出的Tensorflow的“量化”的介绍地址已经404了,在这个地址可以看到关于浮点精确性下降的量化解释 http://t.cn/EzLyNgZ。
方法三:将模型能力限定在特定子域
在边缘设备中进行更快推断的另一种方法是将模型的能力限制在特定的子域之上,这些子域仅服务于边缘设备所应执行的任务。这方面的一个完美例子是Nikouei等人提出的轻量级CNN(L-CNN 来源 http://t.cn/Ez2DTVL ),该项目的目的是让更多运行在边缘设备的人工智能作出更快和更好的推断。文中所举的示例中,边缘设备是一个监视摄像头,用以检测到人类。细节不作过多解释,简单讲,L-CNN在不牺牲太多精确性的前提下保持了高性能,方法就是专门为人类检测建立检测方法,以减少不必要的过滤器。L-CNN能更有效地利用设备的资源。因此,建立一定的约束条件,机器学习可以很好的集成到边缘计算中,以获得更快、更低成本的推理能力。
方案四:Bonsai模型
L-CNN是为诸如Raspberry PI(基于Linux的单片机)一样的内存接近1GB的更智能的边缘设备开发的。这个假设是可以接受的,毕竟处理图像数据需要大量的资源。然而,我们可以为资源更稀缺的边缘设备开发算法,这一点体现在Kumar等人开发的Bonsai树算法中(来源 http://t.cn/EzLt6HX)。Bonsai是一种致力于解决资源高效型设备机器学习的算法,Bonsai(来源 http://t.cn/EzLtND8)适用于通常在医疗、工业或农业应用中充当传感器的小得多的设备,模型大小小于2kb,可以匹配不同的应用程序和数据集,由“基于在低维空间中学习到的单一、浅层、稀疏树的新模型”实现。在边缘设备上部署模型,而不是从云获得推论,还具有离线功能的额外优势。
白小白:
Bonsai,盆景(盆栽)是在中国发明,之后传到日本、越南和朝鲜特有的一种传统艺术,约有一千二百多年历史。按中文维基百科的解释,是寓意于景,以观四季。按Bonsai英文维基百科的解释,是“在容器中制造一棵与完整的树相同形态的小树”。
四、边缘计算的未来挑战
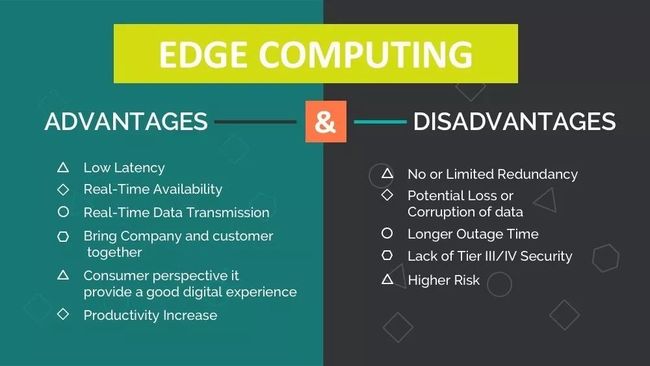
边缘计算的优点和优点
(来源http://t.cn/EzLVbZn)
云时代的一个典型好处是集中化及其带来的管理的便利性。随着计算分布在许多节点和设备上,管理问题也随之出现。此外,集中式系统更容易提供安全性。随着网络中设备数量的增加,网络的安全性越来越难保证。对设备的物理篡改成为可能。在边缘设备与雾节点之间或雾节点与中央云之间的数据传输中实施插入恶意代码成为可能。当然,随着大家的努力,这些挑战已经得到解决,因此,在边缘计算面前的道路似乎越来越清晰。
最后,云中心模式当然不会消失。对于需要大量计算和存储的许多其他用例,我们仍然需要数据中心。然而,除非出现另一次重大的变革,边缘计算仍旧是未来的方向。
关于作者:Gokhan Simsek 来自 Eindhoven, 尼德兰王国。Gokhan是毕业于计算机科学专业,目前在Eindhoven技术大学攻读数据科学硕士学位。他对大数据、NLP和机器学习怀有兴趣。
 关于EAWorld:微服务,DevOps,数据治理,移动架构原创技术分享,长按二维码关注
关于EAWorld:微服务,DevOps,数据治理,移动架构原创技术分享,长按二维码关注
课程预告! 10月19日(今天)下午14:30普元架构师陈清娟为大家分享《构建金融生态服务平台分享》,在此公众号回复“YG+微信号”马上入群并完成报名!
