0. paper & code
DenseBox
paper: DenseBox: Unifying Landmark Localization with End to End Object Detection
code: Caffe 、PyTorch
FCOS
paper: FCOS: Fully Convolutional One-Stage Object Detection
code: FCOS
PolarMask
paper: PolarMask: Single Shot Instance Segmentation with Polar Representation
code: PolarMask
1. DenseBox
15 年的一篇论文,放当时并不惊艳,但如今由于 Anchor Free 倒是火了... 只能说作者的 Idea 太超前了
该论文解决的人脸、车辆这类单一类别目标检测问题。可提取的关键信息包括 Anchor Free、one stage、FCN、特征融合、OHEM。

我们先来看看 GT 是怎么做的,作者采用 crop&resize 的方式,以目标为中心获得 240x240 尺度的图片,crop&resize 的原则是要保证目标在获得的图片中大致 50x50 大小。接下来需要制作一个 60x60x5 尺度的 GT map,将之前获得的240x240 尺度的图片中目标中心点映射到 GT map 中并以 $r_c$ 为半径填充 GT map:GT map 第一个 channel 填充 1(正样本),其他地方填充 0(负样本),构成一个语义分割 map,为了提升模型性能采用类似 OHEM 的方法将正样本周围 2 个像素的样本标记为忽略区域;GT map 随后四个 channel 则代表距离 bbox 的左上、右下坐标的距离。

网络上没有多尺度预测但采用了特征融合。
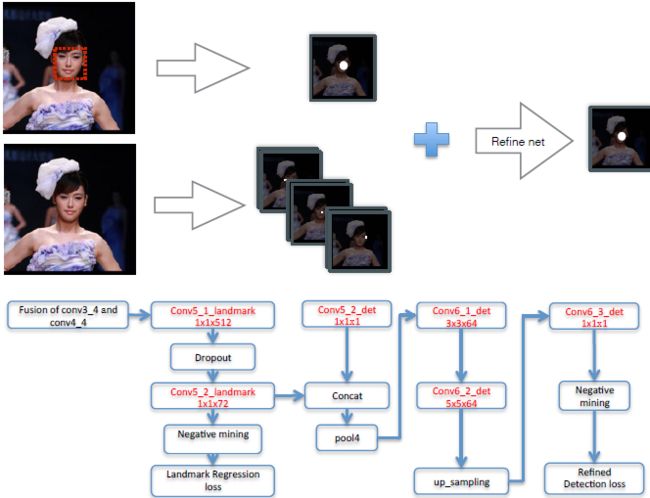
为了提升检测器的性能,加入了 landmark 这个任务(毕竟理论上来说相近的任务间可以互相提升的)。将 landmark 输出 feature map 和 上一步检测输出 feature map 连接后在经过 pool->conv3->conv5->up_sample->conv1 再次判断目标中心点位置。
2. FCOS
FCOS 可以理解为是 DenseBox 的改进版,提取到的关键信息包括 Anchor Free、one stage、FCN、center-ness、NMS。
FCOS 首先说明了下 DenseBox 的缺点,包括:1. 由于 DenseBox 训练时是固定 crop&resize 到 224x224(保证图片中心的目标大小约 50x50),因此需要图像金字塔来完成多尺度,这和一拳超人任何敌人一拳搞定相违背。2. 它很难解决重叠目标的问题。
作者尝试使用特征金字塔 FPN 结构可以避免上面的问题,达到和传统基于 Anchor 的检测器相当的性能。但是试验中发现,会产生很多远离目标中心的低质量的框。在此背景下,FCOS 提出一种 "center-ness" 分支任务(只有一层网络)来预测检测框和 GT 中心点之间的偏移程度。这样的话在测试的时候就可以用它来降低偏远检测框的置信度了,以期在 NMS 中干掉这些低质量的检测框。"center-ness" 使得 FCOS 超越了基于 Anchor 的检测器。作者在优点中还强调了,RPNs 替换成 FCOS 可以使得两阶段检测器性能更强。同时还可以经过小小的改动扩展到解决其他视觉任务,包括实例分割(后面要讲的 PolarMask 就是)和关键点检测。
1. feature map 上,所有落在 bbox 内的 (x,y) 都将被视为正样本,回归目标是该位置到 bbox 的四个边框(映射到 feature map 上)的距离, 这就相当于是一个框级别的实例分割了:
\begin{equation}
\label{regression target}
\begin{split}
& l^* = x - x_0^{(i)}, \ t^* = y - y_0^{(i)} , \\
& r^* = x_1^{(i)} - x, \ b^* = y_1^{(i)} - y . \\
\end{split}
\end{equation}
2. 对于落在重叠框里的点 (x,y) 则简单选择面积最小的那个作为回归目标/分类目标。
3. 网络输出预测一个 $ND$ 的类别预测 $\textbf{p}$ 和一个 $4D$ 的回归预测 $\textbf{t}$。
4. 用训练 $C$ 个 binary classifiers 代替训练一个 multi-class classifier。
5. 每个预测 feature map 后用四个卷积层来分别预测分类和回归。
6. 由于回归目标都是正值,用 $exp(x)$(实际上是 $exp(s_ix)$,参考 11) 来对回归分支上$(0,+\infty)$的所有实数做映射。
7. Loss 上没有什么特别的,$L_{cls}$ 是 focal loss,$L_{reg}$ 是 IoU loss。$N_{pos}$ 代表正样本的数量,$\lambda$ 是一个权重因子(论文中设为1)。$\textbf{1}_{c_i^*>0}$ 是一个指标函数,当 $c_i^*>0$ 值为1,否则为0:
\begin{equation}
\label{loss function}
L(\{p_{x,y}\},\{t_{x,y}\}) = \frac{1}{N_{pos}}\sum_{x,y}{L_{cls}(p_{x,y}, x_{x,y}^*)} + \frac{\lambda}{N_{pos}}\sum_{x,y}{\textbf{1}_{\{c_i^*>0\}} L_{reg}(t_{x,y}, t_{x,y}^*)}
\end{equation}
8. 对于 Anchor based 的方法来说,如果该 feature map 的 stride 较大,可能会导致 low best possible recall(BPR)。而对于 FCOS 来说,乍一看可能会觉得 BPR 会更低,因为缺少先验的位置信息。但我们的实验表明, FCN based 的 FCOS 能有能力获得较好的 BPR,甚至超越基于 Anchor 的检测器。进一步来说,拥有多级 FCN based FCOS 有望超越 Anchor based 的检测器。
9. 对于 GT 重叠框的问题,由于我们不知道要回归到哪个 GT 最合适,这这模糊性是导致 FCN based 模型性能较差的一个原因。在本文中,我们展示了多层级预测可以很好的解决这个问题,使 FCN based 模型达到甚至超过 Anchor based 模型。

10. 网络结构上,如上图所示:FCOS 共 5 个尺度输出 {$P_3, P_4, P_5, P_6, P_7$},其中 $P_3, P_4, P_5$ 由 backbone 中的 feature map $C_3, C_4, C_5$ 经过一个1x1卷积横向连接得到。区别于 Anchor based 检测器中,通过在不同尺度 feature map 中设置不同大小的 Anchor boxes 来完成多尺度,这里直接限制 bounding box regression。具体的,每个尺度分别限定它们的预测范围为 $P_3$ [0, 64], $P_4$ [64, 128], $P_5$ [128, 256], $P_6$ [256, 512], $P_7$ [512,$+\infty$]。因为不同尺寸的目标被分配到不同特征层上,而大部分重叠都发生在尺寸差异比较大的目标之间,所以 multi-level prediction 可以缓解上文提到的二义性问题,提高 FCN based 检测器的性能,使之接近 Anchor based 检测器。特别的,如果还存在对应多个 GT 的实例,就简单取面积最小的那个 GT 为目标就好了。
11. 同 FPN、RetinaNet 一样,模型中共享 heads 部分的参数,这样不仅可以使检测器更参数高效,而且也可以提升检测性能。考虑到不同尺度的回归范围不同,模型中考虑利用 $exp(s_ix)$ 操作来标准化,其中 $s_i$ 是学习出来的,这对提升模型性能很重要。
12. 由于这种类分割的检测方式产生了很多原理 GT 中心点的低质量的检测框,作者提出 "center-ness" 来抑制这些低质量的框。具体的,在分类分支上加上一个 $1D$ 的分类分支,分类目标是个 smooth 形式:
\begin{equation}
\label{centerness}
centerness^* = \sqrt{\frac{min(l^*, r^*)}{max(l^*, r^*)} \times \frac{min(t^*, b^*)}{max(t^*, b^*)}}
\end{equation}
采用 BCE Loss, 该 loss 加到上面的Eq.2上。测试的时候,最终的分类 score 由分类分支的分数和 "center-ness" 分支的分数相乘获得。目的是为了降低那些远离目标中心的检测框的分数,随后这些低质量检测框可以通过 NMS 去除。当然中心化操作也可以通过限定 GT 中心的附近的点/Anchor 作为正样本来达到。
3. PolarMask