【理解Flink必备(一)】Flink核心概念理解-- Dataflow Programming Model
文章目录
- Levels of Abstraction
- Programs and Dataflows
- Parallel Dataflows
- Windows
- Time
- Stateful Operations
- Checkpoints for Fault Tolerance
- Batch on Streaming
笔者根据官方文档原文进行翻译,水平有限,如有理解偏差,请及时联系笔者更正。
Flink Version:1.8.0
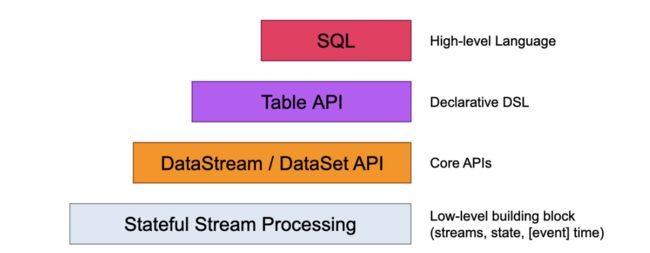
Levels of Abstraction
Flink offers different levels of abstraction to develop streaming/batch applications.
Flink 提供不通层次的抽象语言用来开发 流/批 程序。
-
The lowest level abstraction simply offers stateful streaming. It is embedded into the DataStream API via the Process Function. It allows users freely process events from one or more streams, and use consistent fault tolerant state. In addition, users can register event time and processing time callbacks, allowing programs to realize sophisticated computations.
最底层的抽象仅仅提供 stateful streaming,它通过 DateStream API嵌入到 ProcessFunction,它允许用户自由处理来自一个或多个流事件,并使用一致的容错状态。此外,使用者可以通过注册
events time 和 processing time来回调,允许程序实现复杂的计算。
-
In practice, most applications would not need the above described low level abstraction, but would instead program against the Core APIs like the DataStream API (bounded/unbounded streams) and the DataSet API (bounded data sets). These fluent APIs offer the common building blocks for data processing, like various forms of user-specified transformations, joins, aggregations, windows, state, etc. Data types processed in these APIs are represented as classes in the respective programming languages.
The low level Process Function integrates with the DataStream API, making it possible to go the lower level abstraction for certain operations only. The DataSet API offers additional primitives on bounded data sets, like loops/iterations.
在实践种,多数程序不需要上述的低级抽象,而是针对 Core API进行编程,例如 DataStream API (有界/无界流)和 DataSet API (有界数据集),这些操作顺滑的API提供了数据处理的基础通用模块,譬如用户指定的各种形式的转化,join,aggregations,windows,状态等等。被处理的数据类型称之为类。
DataStream API 是集成 更低阶的 process Function,使得对某些操作进行更低阶的抽象
DataSet API 为游街数据集提供了原始函数,譬如 loops/iterations
-
The Table API is a declarative DSL centered around tables, which may be dynamically changing tables (when representing streams). The Table API follows the (extended) relational model: Tables have a schema attached (similar to tables in relational databases) and the API offers comparable operations, such as select, project, join, group-by, aggregate, etc. Table API programs declaratively define what logical operation should be done rather than specifying exactly how the code for the operation looks. Though the Table API is extensible by various types of user-defined functions, it is less expressive than the Core APIs, but more concise to use (less code to write). In addition, Table API programs also go through an optimizer that applies optimization rules before execution.
One can seamlessly convert between tables and DataStream/DataSet, allowing programs to mix Table API and with the DataStream and DataSet APIs.
Table API 是以表为中心的声明式DSL,这张表,可能是张动态表(当表示流时),像关系型数据库一样,这张表也有一个schema,Table API 提供了一些操作:select,project,join,group-by,aggregate等。Table API 声明了执行的逻辑操作,而不是精确到代码。尽管Table API可以通过各种类型的函数进行扩展,与core API 相比,表现力不足,但是代码简洁,并且执行前可以优化规则。
Table API 可以在表和 DataStream/DataSet 之间转换,允许程序混合Table API and with the DataStream and DataSet APIs.编程。
-
The highest level abstraction offered by Flink is SQL. This abstraction is similar to the Table APIboth in semantics and expressiveness, but represents programs as SQL query expressions. The SQL abstraction closely interacts with the Table API, and SQL queries can be executed over tables defined in the Table API.
Flink 支持的最高阶的抽象是SQL,它在语意和表达上和Table API 类似,但是表现形式为SQL,SQL 和 Table API 紧密交互,可以在Table API 定义的表上 执行SQL。
Programs and Dataflows
The basic building blocks of Flink programs are streams and transformations. (Note that the DataSets used in Flink’s DataSet API are also streams internally – more about that later.) Conceptually a stream is a (potentially never-ending) flow of data records, and a transformation is an operation that takes one or more streams as input, and produces one or more output streams as a result.
Flink程序构建的基础是streams和 transformations(DataSet API内部也是以流的形式使用),概念上来说,流是数据对的一种记录方式,一个或多个流作为输入,经过转换,输出一个或多个流。
When executed, Flink programs are mapped to streaming dataflows, consisting of streams and transformation operators. Each dataflow starts with one or more sources and ends in one or more sinks. The dataflows resemble arbitrary directed acyclic graphs*(DAGs)*. Although special forms of cycles are permitted via iteration constructs, for the most part we will gloss over this for simplicity.
执行时,Flink程序 由流和转换操作 映射到 streaming dataflows,每个数据流有1个或多个 source,有一个或多个sink,这个数据流是一个 DAG,尽管允许特殊形式的循环(如迭代结构),但简单起见,我们忽略了这一点。
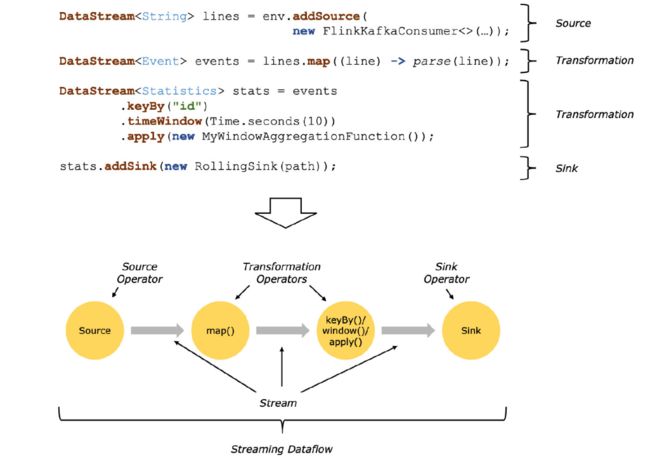
Often there is a one-to-one correspondence between the transformations in the programs and the operators in the dataflow. Sometimes, however, one transformation may consist of multiple transformation operators.
Sources and sinks are documented in the streaming connectors and batch connectors docs. Transformations are documented in DataStream operators and DataSet transformations.
通常,程序中转换和数据流的操作存在一一对应的关系,但是有时一个转换包含多个转换操作
source和sink 的文档详见: streaming connectors and batch connectors .
Transformation的文档详见: DataStream operators and DataSet transformations.
Parallel Dataflows
Programs in Flink are inherently parallel and distributed. During execution, a stream has one or more stream partitions, and each operator has one or more operator subtasks. The operator subtasks are independent of one another, and execute in different threads and possibly on different machines or containers.
The number of operator subtasks is the parallelism of that particular operator. The parallelism of a stream is always that of its producing operator. Different operators of the same program may have different levels of parallelism.
Flink程序的本质时并行和分布式,执行期间,一个stream有1个或多个 stream partitions,并且每个operator 有1个或多个 operator subtasks, operator subtasks彼此独立,可能在不同的线程,也可能在不同的机器或容器上执行。
operator subtasks 的数量,时该 operator的并行度,流的并行度始终是其生成 operator的并行度,同一程序中,不同operator可能有不同的并行级别。
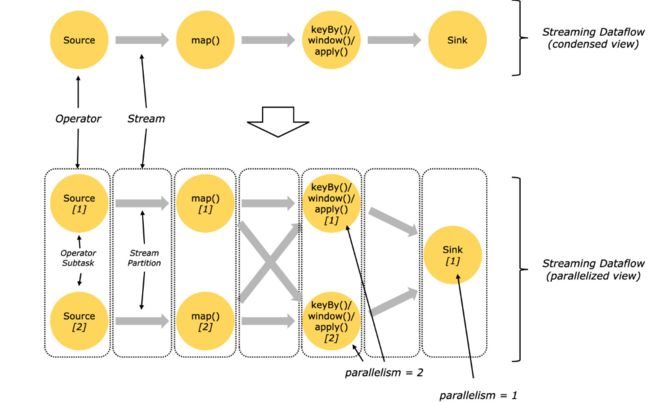
Streams can transport data between two operators in a one-to-one (or forwarding) pattern, or in a redistributing pattern:
流在 2个 operators 中 可以以1对1(转发)模式,或重新分配模式 传输数据。
-
One-to-one streams (for example between the Source and the map() operators in the figure above) preserve the partitioning and ordering of the elements. That means that subtask[1] of the map() operator will see the same elements in the same order as they were produced by subtask[1] of the Source operator.
一对一 流(如上图 source->map() )保留了分区和顺序,这意味着,source() 和 map() 操作中的数据是对齐的。
-
Redistributing streams (as between map() and keyBy/window above, as well as between keyBy/window and Sink) change the partitioning of streams. Each operator subtask sends data to different target subtasks, depending on the selected transformation. Examples are keyBy() (which re-partitions by hashing the key), broadcast(), or rebalance() (which re-partitions randomly). In a redistributing exchange the ordering among the elements is only preserved within each pair of sending and receiving subtasks (for example, subtask[1] of map() and subtask[2] of keyBy/window). So in this example, the ordering within each key is preserved, but the parallelism does introduce non-determinism regarding the order in which the aggregated results for different keys arrive at the sink.
重新分配流(如上图,map()和 keyBy/window 及 keyBy/window 和sink ) 改变了流的并行度,每个subtask,给不同的subtask 传递数据,具体取决于所选的转换操作。譬如:keyBy()(通过散列 key 重新分区),broadcast(),rebalance()(随机分区)。在重新分配流模式上, 数据之间的排序仅保留在每对发送和接受的子任务中(例如, subtask[1] of map() and subtask[2] of keyBy/window),因此,在这个例子中,保证了每个key的有序性,但并行化,又引入了key的聚合结果 到达 sink 顺序的不确定性。
Details about configuring and controlling parallelism can be found in the docs on parallel execution.
并行化的配置和控制,详见文档: parallel execution.
Windows
Aggregating events (e.g., counts, sums) works differently on streams than in batch processing. For example, it is impossible to count all elements in a stream, because streams are in general infinite (unbounded). Instead, aggregates on streams (counts, sums, etc), are scoped by windows, such as “count over the last 5 minutes”, or “sum of the last 100 elements”.
Windows can be time driven (example: every 30 seconds) or data driven (example: every 100 elements). One typically distinguishes different types of windows, such as tumbling windows (no overlap), sliding windows (with overlap), and session windows (punctuated by a gap of inactivity).
聚合事件(如 counts,sums)在流上的处理方式和批是不同的,例如:不可能计算流中所有的元素,因为流通常是无界的,相反,流上的聚合(count,sum)由 windows 限定,譬如统计最后5min的数据,或者,累加100个元素。
windows 可以被时间驱动(譬如:每30秒) ,也可被数据驱动(譬如:每100条元素),通常区分 windows 的方式是:翻滚窗口(没有重叠),滑动窗口(重叠)和会话窗口(被不活跃的间隙打断,形成windows)
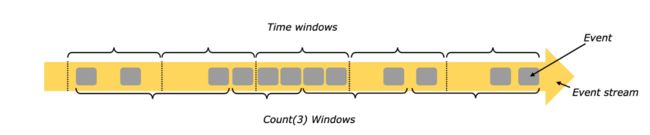
More window examples can be found in this blog post. More details are in the window docs.
更多 window的举例,可参照: blog post. 更多细节,详见文档: window docs.
Time
When referring to time in a streaming program (for example to define windows), one can refer to different notions of time:
流程序中,引入时间概念时(如定义窗口),可参考不同的时间概念。
-
Event Time is the time when an event was created. It is usually described by a timestamp in the events, for example attached by the producing sensor, or the producing service. Flink accesses event timestamps via timestamp assigners.
Event Time: 该事件被创建的时间,通常用时间戳表示,由生产服务来附加,Flink通过 timestamp assigners 来获得时间戳
-
Ingestion time is the time when an event enters the Flink dataflow at the source operator.
摄入时间:流入 Flink source operator 的时间。
-
Processing Time is the local time at each operator that performs a time-based operation.
处理时间:是基于时间操作的operator 的本地时间。
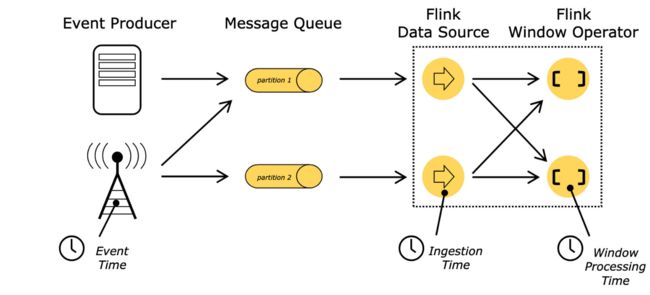
更多细节,详见文档: event time docs.
Stateful Operations
While many operations in a dataflow simply look at one individual event at a time (for example an event parser), some operations remember information across multiple events (for example window operators). These operations are called stateful.
尽管 数据流中许多的 operations 只是一次查看一个单独的事件(例如事件解析),但是一些operations 还是能记住多个事件的信息(如窗口操作),这些operations称为有状态的operations。
The state of stateful operations is maintained in what can be thought of as an embedded key/value store. The state is partitioned and distributed strictly together with the streams that are read by the stateful operators. Hence, access to the key/value state is only possible on keyed streams, after a keyBy() function, and is restricted to the values associated with the current event’s key. Aligning the keys of streams and state makes sure that all state updates are local operations, guaranteeing consistency without transaction overhead. This alignment also allows Flink to redistribute the state and adjust the stream partitioning transparently.
状态操作的状态,保存在可嵌入的 key/value 存储中,state随着流 严格的分区 ,并被一些 stateful operatiors 所读取,因此,想要访问 keyed stream这种 key/value 的status, 只能在 keyBy()之后,并且value 被当前的key 所限制。对齐流的 key 和 状态,保证了所有的状态更新是本地操作,保证了一致性的同时,而避免了事务开销。这种对齐允许Flink 清晰的调整流的分区和重分配状态。
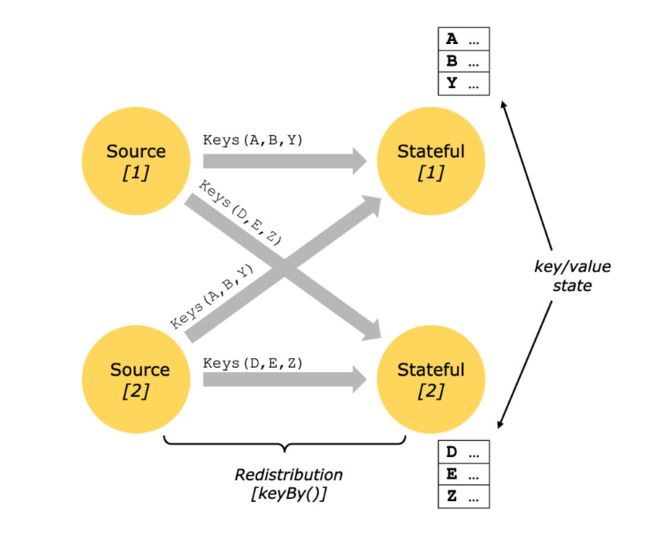
如上图,source[1] source[2] 都含有 keyed stream,经过keyBy()后,stateful[1]和stateful[2] 中都含有以DEZ,ABY为key 的状态。
Checkpoints for Fault Tolerance
Flink implements fault tolerance using a combination of stream replay and checkpointing. A checkpoint is related to a specific point in each of the input streams along with the corresponding state for each of the operators. A streaming dataflow can be resumed from a checkpoint while maintaining consistency (exactly-once processing semantics) by restoring the state of the operators and replaying the events from the point of the checkpoint.
Flink 通过 stream replay 和checkpointing 的组合 实现了容错机制,1个checkpoint 是与 input stream 的特定点及 每个opertaor 响应的状态 相关。流数据可以通过恢复 operators 的状态和checkpoint的重放来保证一致性(exactly-once 处理语义)
The checkpoint interval is a means of trading off the overhead of fault tolerance during execution with the recovery time (the number of events that need to be replayed).
checkpoint的间隔是表示程序执行恢复所需时间(取决于重放events的数据)的一种容错开销的方法。
即可用checkpoint 的 间隔,来表示容错开销大小(个人理解)。
The description of the fault tolerance internals provides more information about how Flink manages checkpoints and related topics. Details about enabling and configuring checkpointing are in the checkpointing API docs.
Flink如何管理checkpoint 及相关topics 详见: fault tolerance internals
Flink如何启用和配置检查点的细节详见: checkpointing API docs.
Batch on Streaming
Flink executes batch programs as a special case of streaming programs, where the streams are bounded (finite number of elements). A DataSet is treated internally as a stream of data. The concepts above thus apply to batch programs in the same way as well as they apply to streaming programs, with minor exceptions:
Flink将批处理,看做一种特殊的流(有界),DataSet在内部被视为数据流,因此,上述概念同样也适用于批处理,但有少数例外,如下:
-
Fault tolerance for batch programs does not use checkpointing. Recovery happens by fully replaying the streams. That is possible, because inputs are bounded. This pushes the cost more towards the recovery, but makes the regular processing cheaper, because it avoids checkpoints.
批处理的容错并不使用 checkpointing,可用过完整的回放来恢复,因为输入时有界的,这样可以将开销导向恢复,使处理更轻量,因为避免了检查点。
-
Stateful operations in the DataSet API use simplified in-memory/out-of-core data structures, rather than key/value indexes.
DataSet API的状态操作使用了 内存IO的核心数据结构,并非key/value索引。
-
The DataSet API introduces special synchronized (superstep-based) iterations, which are only possible on bounded streams. For details, check out the iteration docs.
DataSet API引入了只能在有界流上使用的特殊同步(superstep-based)迭代方式。详见文档: iteration docs.