Apache Flink流处理(五)
本章介绍Flink的DataStream API的基础知识。我们将展示一个标准的Flink流式应用程序的结构和组件,还会讨论Flink的类型系统及其支持的数据类型,并给出数据转换和分区转换。我们将在下一章将讨论窗口操作符【windows operator】、基于时间的转换【time-based transformations】、有状态操作符【stateful operators】和连接器【connectors】。在阅读本章之后,您将了解如何实现一个具有基本功能的流处理应用程序。我们的实例代码使用的是Scala,但是Java API基本上是类似的(例外或特殊情况,我们会特别指出的)。我们还在Github存储库中提供了用Java和Scala实现的完整示例应用程序。
5.1 Hello Flink
让我们从一个简单的例子开始,初步了解用DataStream API编写流应用程序是什么样的。 我们将使用此示例来展示一个Flink程序的基本结构,并介绍DataStream API的一些重要特性。 我们的这个示例应用程序从多个传感器摄取温度测量的数据流。
首先,让我们看一看用来表示传感器读数的数据类型:
case class SensorReading(
id: String,
timestamp: Long,
temperature: Double)
Example 5-1. Scala case class for sensor data(表示传感器数据的Scala样本类)
下面的程序将温度从华氏温度转换为摄氏温度,并为每个传感器每五秒钟计算一次平均温度。
//V1.7
// Scala object that defines the DataStream program in the main() method.
object AverageSensorReadings {
// main() defines and executes the DataStream program
def main(args: Array[String]) {
// set up the streaming execution environment
val env = StreamExecutionEnvironment.getExecutionEnvironment
// use event time for the application
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// create a DataStream[SensorReading] from a stream source
val sensorData: DataStream[SensorReading] = env
// ingest sensor readings with a SensorSource SourceFunction
.addSource(new SensorSource)
// assign timestamps and watermarks (required for event time)
.assignTimestampsAndWatermarks(new SensorTimeAssigner)
val avgTemp: DataStream[SensorReading] = sensorData
// convert Fahrenheit to Celsius with an inline lambda function
.map( r => {
val celsius = (r.temperature - 32) * (5.0 / 9.0)
SensorReading(r.id, r.timestamp, celsius)
} )
// organize readings by sensor id
.keyBy(_.id)
// group readings in 5 second tumbling windows
.timeWindow(Time.seconds(5))
// compute average temperature using a user-defined function
.apply(new TemperatureAverager)
// print result stream to standard out
avgTemp.print()
// execute application
env.execute("Compute average sensor temperature")
}
}
Example 5-2. Compute the average temperature every 5 seconds for a stream of sensors
您可能已经注意到Flink程序是用常规的Scala或Java方法定义并提交执行的。 最常见的做法是在静态main方法中完成。 在我们的示例中,我们定义了一个Object类:AverageSensorReadings ,并在main()中包含了大部分应用程序逻辑。
标准的流式Flink应用程序的结构由下面的这几点组成:
- 设置执行环境
- 从数据源读取一个或多个流
- 应用流式转换来实现应用程序逻辑
- 可选地将结果输出到一个或者多个数据接收器【data sinks】
- 执行程序(run)
现在我们使用上面的示例详细研究流式Flink应用程序的各个组成部分。
5.1.1 Set up the Execution Environment:设置执行环境
Flink应用程序需要做的第一件事是设置其执行环境。执行环境决定该程序是在本地机器上运行还是在集群上运行。在DataStream API中,应用程序的执行环境由StreamExecutionEnvironment来表现的。在我们的示例中,我们通过调用静态getExecutionEnvironment()来检出执行环境。该方法将返回的是一个本地环境或远程环境,具体取决于调用该方法的上下文。如果该方法的调用者是一个连接到远程集群的负责提交的客户端,那么该方法返回的是一个远程执行环境。否则,它返回一个本地环境。
当然Flink也可以显式地创建本地或远程执行环境,如下所示:
// create a local stream execution environment
val localEnv: StreamExecutionEnvironment.createLocalEnvironment()
// create a remote stream execution environment
val remoteEnv = StreamExecutionEnvironment.createRemoteEnvironment(
"host", // hostname of JobManager
1234, // port of JobManager process
"path/to/jarFile.jar) // JAR file to ship to the JobManager
Example 5-3. Create a local or remote execution environment
传输到JobManager的JAR文件必须包含执行流式应用程序所需的所有资源.
接下来,我们使用env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)来指示我们的程序使用事件时间【event time】来解释时间语义。执行环境还允许更多的配置选项,例如设置程序并行度和启用容错功能。
5.1.2 Read an input stream:读取输入流
一旦配置了执行环境,就应该执行一些实际工作并开始处理流了。StreamExecutionEnvironment提供了方法用于创建流源/发生器【stream source】,该流源/发生器可以将数据流【data streams】摄入到应用程序中。数据流【data streams】可以从消息队列、文件等源上获取,也可以动态生成。
在本例中,我们这样使用:
val sensorData: DataStream[SensorReading] = env.addSource(new SensorSource)
通过这样的方法调用,我们可以连接到传感器测量数据源/发生器并创建一个数据类型为SensorReading的初始DataStream。Flink支持多种数据类型,我们将在下一节中详细讲解。现在,我们使用在前面定义的Scala样本类:SensorReading,来作为数据的类型。该样本类SensorReading 包含:①传感器的ID ②表示温度测量时的时间戳 ③测量的温度值。
接下来我们通过调用setParallelism(4)将输入数据源的并行度配置为4,并使用 assignTimestampsAndWatermarks(new SensorTimeAssigner)分配事件时间【event time】所需的时间戳和水印。SensorTimeAssigner 的实现细节目前不需要关注,我们后面会讲解。
5.1.3 应用转换【Apply transformations】
一旦我们有了一个DataStream,我们就可以对它应用转换。这里有多种不同类型的转换。有的转换可以生成新的DataStream,甚至可能是生成不同类型的DataStream,而其他的转换则不会修改DataStream中的记录,而是通过分区或分组对其进行重新组织。应用程序的逻辑是通过串链转换来定义的。
在我们的这个样例中,我们首先应用了一个map()转换,将每个传感器读数中的温度读数由华氏度转换为摄氏度。然后,我们使用 keyBy()转换来根据传感器的ID对传感器读数进行分区。随后,我们定义了一个timeWindow()转换,它将每个传感器ID分区的传感器读数分组为每5秒一撮的滚动窗口。
val avgTemp: DataStream[SensorReading] = sensorData
.map( r => {
val celsius = (r.temperature - 32) * (5.0 / 9.0)
SensorReading(r.id, r.timestamp, celsius)
} )
.keyBy(_.id)
.timeWindow(Time.seconds(5))
.apply(new TemperatureAverager)
下一章我们将详细描述窗口转换。最后,我们应用了一个用户定义函数(UDF)来计算每个窗口的平均温度。我们将在本章后面讨论如何在DataStream API中定义用户定义函数(UDF)。
5.1.4 结果输出
流式应用程序通常将结果发布到一些外部系统,如Apache Kafka、文件系统或数据库。Flink提供了一个维护良好的流接收器【stream sinks】集合,可用于将数据写入不同的系统。当然Flink也允许我们实现自己的流式接收器。还有一些应用程序不发出结果,而是将结果保留在内部,以便通过Flink的可查询状态特性【queryable state feature】提供结果。
在我们的示例中,结果是DataStream[SensorReading],其中的值是每5秒内的平均测量温度。结果流会可以通过调用print()写入到标准输出。
avgTemp.print()
请注意,流式接收器的选择会影响应用程序的端到端一致性,即,应用程序的结果是具有至少一次语义【at-least once semantics】还是具有唯一语义【exactly-once semantics】。应用程序的端到端一致性取决于所选流接收器与Flink检查点算法的集成。我们将在第7章的“Application Consistency Guarantees”中更详细地讨论这个主题。
5.1.5 执行
当应用程序被完全定义之后,可以通过调用StreamExecutionEnvironment.execute()来执行它。
env.execute("Compute average sensor temperature")
Flink程序是惰性执行的。也就是说,到目前为止,所有创建流数据源和转换的方法都没有产生任何数据处理。相反,执行环境构建了一个执行计划,该计划从从环境创建的所有流数据源开始,并包括对这些数据源临时应用的所有转换。只有在调用execute()时,系统才触发对执行计划的执行。根据执行环境的类型,应用程序或者在本地执行,或者被发送到远程JobManager执行。
构造的计划被转换成JobGraph ,并提交给JobManager 执行。根据执行环境的类型,JobManager 将作为本地线程(本地执行环境)启动,或者将JobGraph 发送到远程JobManager。如果JobManager在远程运行,则必须将JobGraph与一个Jar文件一起提供,该Jar文件包含应用程序的所有类和所需的依赖项。
5.2 类型【Types】
Flink DataStream应用程序处理事件流,其中事件是以数据对象来表现的。在数据对象上应用函数,并发射出现数据对象。在内部,Flink需要能够处理这些对象。需要对事件进行序列化和反序列化,以便通过网络传输它们,或者将它们与状态后端、检查点和保存点之间执行写入和读取交互。为了有效地做到这一点,Flink需要关于应用程序处理的数据类型的详细知识。Flink具有类型信息的概念,用于表示数据类型并为每种数据类型生成特定的序列化器、反序列化器和比较器。
Flink提供了一个类型提取系统,它分析函数的输入和返回类型,从而自动获得类型信息,从而获得序列化器和反序列化器。然而,在某些情况下,例如lambda函数或泛型类型,有必要显式地提供类型信息,以使应用程序工作或提高其性能。
在本节中,我们将讨论Flink支持的类型,如何为数据类型创建类型信息,以及如何在Flink的类型系统无法自动推断函数的返回类型时使用提示【hints 】来帮助它进行类型推断。
5.2.1 支持的数据类型
Flink支持许多常见的数据类型。最广泛使用的类型大致可分为以下几类:
- Primitives
- Java and Scala tuples
- Scala case classes
- POJOs, including classes generated by Apache Avro
- Flink Value types
- Some special types
没有特别处理的类型被视为泛型类型,并使用Kryo序列化框架进行序列化。
让我们通过示例研究每个类型类别。
5.2.1.1 PRIMITIVES(基本数据类型)
所有Java和Scala所支持的基本类型,如Int(或Java的Integer)、String和Double,都支持作为DataStream的类型。下面例子中处理Long类型记录的数据流,并对流中的记录应用一个递增操作。
val numbers: DataStream[Long] = env.fromElements(1L, 2L, 3L, 4L)
numbers.map( n => n + 1)
Example 5-4. Increment a stream of Long values
5.2.1.2 JAVA AND SCALA TUPLES
元组是由固定数量的类型化字段组成的复合数据类型。
Scala DataStream API使用规范的Scala元组。下面是一个过滤二元元组类型的DataStream的示例。我们将在下一节中讨论filter转换的语义:
// DataStream of Tuple2[String, Integer] for Person(name, age)
val persons: DataStream[(String, Integer)] = env.fromElements(
("Adam", 17),
("Sarah", 23))
// filter for persons of age > 18
persons.filter(p => p._2 > 18)
Example 5-5. Filtering tuples in the Scala DataStream API
Flink提供了Java元组的有效实现。Flink的Java元组最多可以支持有25个属性字段,每种长度的元组都通过一个单独的类来实现,即, Tuple1,Tuple2,直到Tuple25。元组类是强类型的。
我们可以在Java DataStream API中重写上面的过滤示例:
// DataStream of Tuple2 for Person(name, age)
DataStream> persons = env.fromElements(
Tuple2.of("Adam", 17),
Tuple2.of("Sarah", 23));
// filter for persons of age > 18
persons.filter(new FilterFunction() {
@Override
public boolean filter(Tuple2 p) throws Exception {
return p.f1 > 18;
}
})
Example 5-6. Filtering tuples in the Java DataStream API
Tuple中的属性字段可以通过其公共属性字段的名称来进行类型安全的访问,如f0、f1、f2等,如上面例子中这样;除此之外,我们还也可以使用Object getField(int pos)方法,通过指定索引进行访问,其中索引从0开始:
Tuple2 personTuple = Tuple2.of("Alex", "42");
Integer age = personTuple.getField(1); // age = 42
Example 5-7. Accessing a tuple field in the Java DataStream API
与Scala的元组不同,Flink支持的Java元组是可变的,这样我们可以重新分配属性字段的值。因此,函数可以重用Java元组,以减少对垃圾回收的压力:
personTuple.f1 = 42; // set the 2nd field to 42
personTuple.setField(43, 1); // set the 2nd field to 43
Example 5-8. Setting tuple fields in the Java DataStream API
5.2.1.3 SCALA CASE CLASSES
Flink支持Scala的样本类;即可以通过模式匹配分解的类。样本类的属性字段是按名称访问的。在下面的例子中,我们定义了一个样本类:Person,它有两个字段,即name和age。与元组类似,我们按年龄筛选DataStream:
case class Person(name: String, age: Int)
val persons: DataStream[Person] = env.fromElements(
Person("Adam", 17),
Person("Sarah", 23))
// filter for persons with age > 18
persons.filter(p => p.age > 18)
Example 5-9. Filtering persons by age using a Scala case class
5.2.1.4 POJOS
Flink对不属于任何类别的每种类型进行分析,并检查是否可以将其标识为POJO类型并作为POJO类型处理。当一个类满足下面的条件时,Flink接受其作为POJO:
- 该类是一个public类
- 该类有public的无参构造器
- 所有属性需要是public声明,或者可以通过getter和setter访问到。而且getter和setter方法必须遵守默认的命名方案,比如属性字段x的类型是Y,那么他的getter和setter方案应该是Y getX() 和 setX(Y x)
- 所有属性字段都具有Flink支持的类型
例如,下面的Java类将被Flink标识为POJO:
public class Person {
// both fields are public
public String name;
public int age;
// default constructor is present
public Person() {}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}
DataStream persons = env.fromElements(
new Person("Alex", 42),
new Person("Wendy", 23));
Example 5-10. A Java class which is identified by Flink as a POJO
Avro生成的类由Flink自动识别,并作为POJO处理.
5.2.1.5 FLINK VALUE TYPES
实现了org.apache.flink.types.Value接口的类型被视为Flink值类型。该接口由read()和write()两个方法组成,用于实现序列化和反序列化逻辑。例如,可以利用这些方法实现比通用序列化器更有效地对公共值进行编码。
Flink提供了一些内置的值类型,例如IntValue、DoubleValue和StringValue,它们为Java和Scala的不可变基本类型提供了一种可变的替代选择。
5.2.1.6 ARRAYS, LISTS, MAPS, ENUMS, AND OTHER SPECIAL TYPES
Flink支持几种特殊用途的类型,例如Scala的Either、Option和Try类型,以及Flink的Java版本的Either类型。与Scala的Either类型类似,它表示两种可能类型之一的值,Left或者Right。此外,Flink还支持基本类型和对象Array类型、Java的Enum类型和Hadoop的Writable类型。
5.2.2 TypeInformation
Flink类型系统的核心类是TypeInformation。 它为系统提供了用于生成序列化器和比较器所需的必要信息。 例如,当您通过某个键加入(join)或分组(group)时,这个类允许Flink执行语义检查,检查被用作键的字段是否有效。
当应用程序提交执行时,Flink的类型系统尝试为框架处理的每个数据类型自动派生类型信息。所谓的类型提取器分析所有函数的泛型类型和返回类型,以获得相应的类型信息对象。因此,您可以暂时使用Flink,而不必担心数据类型的类型信息。然而,有时类型提取器会失败,或者您可能希望定义自己的类型并告诉Flink如何有效地处理它们。在这种情况下,需要为特定的数据类型生成类型信息。
Flink使用静态方法为Java和Scala提供了两个实用程序类来生成类型信息。对于Java, 这个助手类是org.apache.flink.api.common.typeinfo.Types,如下面的例子所示:
// TypeInformation for primitive types
TypeInformation intType = Types.INT;
// TypeInformation for Java Tuples
TypeInformation> tupleType =
Types.TUPLE(Types.LONG, Types.STRING);
// TypeInformation for POJOs
TypeInformation personType = Types.POJO(Person.class);
对于Scala API,类型信息助手类是org.apache.flink.api.scala.typeutils。类型和它的使用如下代码示例所示:
// TypeInformation for primitive types
val stringType: TypeInformation[String] = Types.STRING
// TypeInformation for Scala Tuples
val tupleType: TypeInformation[(Int, Long)] = Types.TUPLE[(Int, Long)]
// TypeInformation for case classes
val caseClassType: TypeInformation[Person] = Types.CASE_CLASS[Person]
NOTE:在Scala API中,Flink使用在编译时运行的宏。 要访问’createTypeInformation’宏函数,请确保始终添加以下import语句:
import org.apache.flink.streaming.api.scala._
显式地提供TypeInformation
在大多数情况下,Flink能够自动推断类型并生成正确的TypeInformation。 Flink的类型提取器利用反射和对函数的签名于子类信息进行分许,来获取用户定义函数的正确输出类型。但是,有时无法提取必要的信息,例如Java会擦除泛型类型信息。此外,在某些情况下,Flink可能不会选择生成最有效的序列化器和反序列化器的TypeInformation。
因此,对于应用程序中使用的某些数据类型,您可能需要向Flink显式提供TypeInformation对象。有两种方法可以提供TypeInformation。
首先,您可以通过实现ResultTypeQueryable接口来扩展函数类,以显式提供其返回类型的TypeInformation。以下示例显示了一个提供其返回类型的MapFunction。
class Tuple2ToPersonMapper extends MapFunction[(String, Int), Person]
with ResultTypeQueryable[Person] {
override def map(v: (String, Int)): Person = Person(v._1, v._2)
// provide the TypeInformation for the output data type
override def getProducedType: TypeInformation[Person] = Types.CASE_CLASS[Person]
}
在Java DataStream API中,还可以使用returns()方法在定义数据流时显式指定操作符的返回类型,如下例所示:
DataStream> tuples = ...
DataStream persons = tuples
.map(t -> new Person(t.f0, t.f1))
// provide TypeInformation for the map lambda function's return type
.returns(Types.POJO(Person.class));
可以用Class类来提供类型提示,如下例所示:
DataStream result = input
.map(new MyMapFunction())
.returns(MyType.class);
Example 5-11. Providing type hints with a class in the Java API
如果函数在返回类型中使用不能从输入类型推断的泛型类型变量,则需要提供一个TypeHint:
DataStream result = input
.flatMap(new MyFlatMapFunction())
.returns(new TypeHint(){});
class MyFlatMapFunction implements FlatMapFunction {
public void flatMap(T value, Collector out) { ... }
}
Example 5-12. Providing type hints with a TypeHint in the Java API
5.3 转换
在本节中,我们将概述DataStream API的基本的转换。我们将在下面的章节中介绍与时间相关的操作符(如窗口运算符),以及进一步的特定转换。 流转换可以被应用于一个或多个输入流上,并将它们转换为一个或多个输出流。 编写DataStream API程序本质上归结为组合这些转换以创建实现应用程序逻辑的数据流图。
大多数流转换都是基于用户定义的函数的(UDF)。 UDF封装用户应用程序逻辑,并定义了如何将输入流的元素转换为输出流的元素。 UDF通过类的形式定义,该类需要扩展自特定转换的函数接口,例如以下示例中的FilterFunction和MapFunction:
class MyFilterFunction extends FilterFunction[Int] {
override def filter(value: Int): Boolean = {
value > 0;
}
}
class MyMapFunction extends MapFunction[Int, Int] {
override def map(value: Int): Int = value + 1
}
Example 5-14. A DataStream UDF class
函数接口中定义了需要由用户实现的转换方法,比如上例中的filter()、map()方法。
大多数函数接口设计为SAM(单一抽象方法)接口。因此,它们可以在Java 8中实现为lambda函数。Scala DataStream API也提供了对lanmbda函数的内置支持。在介绍DataStream API的转换时,我们将展示所有实现了的函数类的接口,但为了简洁起见,我们在代码中还是使用更简洁的lambda,而不是函数类。
DataStream API为常见的数据转换操作提供了转换。如果您熟悉批处理数据API、函数式编程语言或SQL,就会发现API概念非常容易掌握。下面,我们将DataStream API的转换分为四组:
- 基本转换【Basic transformations】是对单个事件的转换
- KeyedStream转换【KeyedStream transformations】是应用于键上下文中的事件的转换
- 多流转换【Multi-stream transformations】将多个流合并到一个流中,或者将一个流拆分为多个流
- 分区转换则会重新组织流事件
5.3.1 Basic transformations
基本转换用于处理单个事件。我们下面来解释它们的语义并展示代码示例:
FILTER [DATASTREAM -> DATASTREAM]
过滤器转换通过计算每个输入事件的布尔条件,来决定丢弃或转发流中的事件。 返回值为true会保留输入事件并将其转发到输出,而如果返回值为false则会导致事件被丢弃。 通过调用DataStream.filter()方法来指定对一个过滤器转换的使用。 图5.1显示了一个仅保留白色方块的过滤操作。
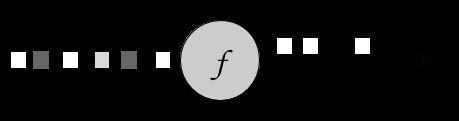
Figure 5-1. A filter operation that only retains white values.
布尔条件可以使用FilterFunction接口或lambda函数任一方式实现为一个UDF。 FilterFunction根据输入流的类型进行类型化,并定义filter()方法,该方法使用输入事件调用,并返回一个布尔值。
// T: the type of elements
FilterFunction[T]
> filter(T): Boolean
下面的例子展示了一个过滤器,它将温度低于25度的所有传感器测量数据丢弃掉:
val readings: DataStream[SensorReadings] = ...
val filteredSensors = readings
.filter( r => r.temperature >= 25 )
Example 5-15. A filter transformation that drops sensor measurements with temperature below 25 degrees
MAP [DATASTREAM -> DATASTREAM]
映射转换是通过调用DataStream.map()方法来指定的。它将每个传入事件传递给一个用户定义的映射器【mapper】,该映射器恰好返回一个输出事件,但是它可能是不同类型的输出事件。图5.1展示了一个将每个正方形转换为圆行的映射转换。
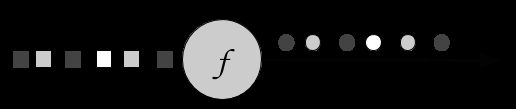
Figure 5.2 A map operation that transforms every square into a circle of the same color.
映射器【mapper】的类型是根据输入和输出事件的类型来类型化的,可以使用MapFunction接口指定。 该接口定义了一个map()方法,该方法将输入事件转换为一个输出事件。
// T: the type of input elements
// O: the type of output elements
MapFunction[T, O]
> map(T): O
下面是一个简单的映射器,它在输入流中投影每个SensorReading 中的id属性:
val readings: DataStream[SensorReading] = ...
val sensorIds: DataStream[String] = readings.map(new MyMapFunction)
class MyMapFunction extends ProjectionMap[SensorReading, String] {
override def map(r: SensorReading): String = r.id
}
Example 5-16. A mapper that projects the first field of each SensorReading in the input stream
当使用Scala API或者Java8,该映射器可以使用lambda函数来表达。
val readings: DataStream[SensorReading] = ...
val sensorIds: DataStream[String] = readings.map(r => r.id)
Example 5-17. A mapper using a lambda function
FLATMAP [DATASTREAM -> DATASTREAM]
FlatMap与map类似,但是它可以为每个传入事件生成0个、1个或多个输出事件。事实上,flatMap是filter和map的一种泛化,可以用来实现这两种操作。图5.3展示了一个flatMap操作,该操作根据传入事件的颜色区分其输出。如果输入是白色方块,则输出未经修改的事件。黑色方块将会被Copy,灰色方块则被过滤掉。

Figure 5-3. A flatMap operation that outputs white squares, duplicates black squares, and drops gray squares.
flatMap转换对每个传入事件应用UDF。对应的FlatMapFunction定义了一个flatMap()方法,该方法可以通过将它们传递给Collector对象来返回零个,一个或多个事件。
// T: the type of input elements
// O: the type of output elements
FlatMapFunction[T, O]
> flatMap(T, Collector[O]): Unit
下面的示例展示了flatMap转换,它被用于转换传感器的字符串类型的ID。用于生成传感器读数的简版事件源所生成的ID的形式为“sensor_N”,其中N是整数。 下面的flatMap函数则根据“_”将该ID分割为前缀“sensor”和传感器编号,并将二者都发射出来:
val sensorIds: DataStream[String] = ...
val splitIds: DataStream[String] = sensorIds
.flatMap(id => id.split("_"))
Example 5-18. A flatMap that splits the incoming sensor ids into their prefix and their number.
注意,每个字符串都将作为一个单独的记录发出,即flatMap扁平化了输出集合。
5.3.2 KeyedStream transformations
许多应用程序的一个常见需求是一起处理共享某个属性的事件组。DataStream API具有KeyedStream的抽象,KeyedStream是一个DataStream,它在逻辑上被分区为 共享相同键(key)的事件 的不相交子流。
应用到KeyedStream上的有状态的转换【Stateful transformations 】,会从当前处理的事件的键【key】的上下文中读取和写入状态。这意味着具有相同键【key】的所有事件可以访问到相同的状态,从而一起处理。需要注意的是,必须谨慎使用有状态的转换【Stateful transformations 】和键控聚合【keyed aggregates 】。如果键域【key domain 】持续增长,例如因为键【key】是一个惟一的事务ID,那么应用程序最终可能会遇到内存问题。请参阅第8章:Implementing Stateful Functions” ,其中详细讨论了有状态函数。
可以使用之前看到的map,flatMap和filter转换来处理KeyedStream。 在下文中,您将了解如何使用keyBy转换将DataStream转换为KeyedStream以及键控转换【keyed transformations】(如滚动聚合和reduce)。
KEYBY [DATASTREAM -> KEYEDSTREAM]
keyBy转换使用指定的键【key】将DataStream转换为KeyedStream。它根据键【key】,将流中的事件分配给不同的分区。虽然具有不同键【key】的事件可以分配给同一分区,但我们可以保证具有相同键【key】的元素始终位于同一分区。 因此,一个分区可能由多个逻辑子流组成,每个子流具有一个唯一的键【key】。
假设以输入事件中的颜色属性作为键【key】,下面的图5.4将白色和灰色事件分配给一个分区,将黑色事件分配给另一个分区:

Figure 5-4. A keyBy operation that partitions together events based on their color.
keyBy()方法接收一个参数,该参数指定用于分组的键【key】(或keys)并返回一个KeyedStream。 有不同的方法来指定这个键【key】。 我们将在本章后面的“Defining Keys”部分中看到它们。以下示例根据ID对传感器读数流进行分组:
val readings: DataStream[SensorReading] = ...
val keyed: KeyedStream[SensorReading, String] = readings
.keyBy(r => r.id)
Example 5-19. Group a DataStream of SensorReadings by id
ROLLING AGGREGATIONS [KEYEDSTREAM -> DATASTREAM]
滚动聚合转换应用于一个KeyedStream并生成聚合流,这种转换有sum、minimum和maximum。 滚动聚合操作符为每个观察到的键【key】存放一个聚合值。 对于每个传入事件,操作符更新相应的聚合值,并使用更新后的值发出事件。 滚动聚合不需要用户定义的函数,但它也接收一个参数,该参数用于指定使用哪个字段来计算聚合。 DataStream API提供以下滚动聚合方法:
- sum(): 输入流在指定字段上滚动求和
- min(): 输入流在指定字段上滚动求得最小值
- max(): 输入流在指定字段上滚动求得最大值
- minBy(): 输入流的滚动最小值,返回到目前为止观察到的具有最低值的事件
- maxBy(): 输入流的滚动最大值,返回到目前为止观察到的具有最高值的事件
不可以组合多个滚动聚合方法,即,一次只能计算一个滚动聚合。
考虑下面例子:
val inputStream: DataStream[(Int, Int, Int)] = env.fromElements(
(1, 2, 2), (2, 3, 1), (2, 2, 4), (1, 5, 3))
val resultStream: DataStream[(Int, Int, Int)] = inputStream
.keyBy(0) // key on first field of the tuple
.sum(1) // sum the second field of the tuple in place
resultStream.print()
Example 5-20. Computing a rolling sum on a tuple and printing the result
在本例中,元组输入流根据第一个字段键控分组,并基于第二个字段进行滚动求和计算。对于key=1的分组中,输出是(1,2,2),然后是(1,7,2);对于key=2的分组中,输出则是(2,3,1),然后是(2,5,1)。示例中inputStream流所输出元组中:第一个字段是公共的键【key】,第二个字段是待求和的值,第三个字段没有定义。
NOTE只在限界的键域上才使用滚动聚合:滚动聚合操作符为处理的每个键保存一个状态。由于这种状态从未被清除,因此您应该只在具有限界键域的流上应用滚动聚合操作符
REDUCE [KEYEDSTREAM -> DATASTREAM]
归约【reduce】转换是滚动聚合的一种推广。它在KeyedStream上应用了一个用户定义的函数,该函数将每个传入事件与当前归约得到的值结合起来。归约【reduce】转换不会改变流的类型,即,输出流的类型与输入流的类型相同。
可以使用实现了ReduceFunction接口的类来指定UDF。 ReduceFunction定义了educe()方法,该方法接受两个输入事件并返回相同类型的事件。
// T: the element type
ReduceFunction[T]
> reduce(T, T): T
val readings: DataStream[SensorReading] = ...
// a rolling reduce that computes the highest temperature of the each group's readings
val reducedSensors = readings
.keyBy(_.id)
.reduce((r1, r2) => {
val highestTimestamp = Math.max(r1.timestamp, r2.timestamp)
SensorReading(r1.id, highestTimestamp, r1.temperature)
})
在下面的例子中,流是根据语言【language】键控分组的,结果是关于每种语言不断的不断更新的单词列表:
val inputStream: DataStream[(String, List[String])] = env.fromElements(
("en", List("tea")), ("fr", List("vin")), ("en", List("cake")))
val resultStream: DataStream[(String, List[String])] = inputStream
.keyBy(0)
.reduce((x, y) => (x._1, x._2 ::: y._2))
Example 5-21. A rolling reduce that computes the highest timestamp of the each sensor group’s readings
5.3.3 Multi-stream transformations
许多应用程序会摄取需要联合处理的多个流,或者需要将流拆分以便将对不同的子流应用不同的逻辑。 在下文中,我们将讨论处理多个输入流或发出多个输出流的DataStream API转换。
UNION [DATASTREAM* -> DATASTREAM]
Union将一个或多个输入流合并到一个输出流中。图5.5展示了一个union操作,它将黑白事件合并到单个输出流中:

Figure 5-5. A union operation that merges two input streams into one.
DataStream.union()方法接收一个或者多个具有相同输入类型的DataStreams ,并生成一个相同类型的新DataStream, 随后的转换会处理输入流中所有的元素。
事件以先入先出的方式合并,即,则操作符不会生成特定的顺序或事件。此外,union操作符不执行重复消除。每个输入事件都被发送给下一个操作符。
下面的例子展示了如何将三种SensorReading类型的流读入到一个流中:
val parisStream: DataStream[SensorReading] = ...
val tokyoStream: DataStream[SensorReading] = ...
val rioStream: DataStream[SensorReading] = ...
val allCities: DataStream[SensorReading] = parisStream
.union(tokyoStream, rioStream)
Example 5-22. A union transformation on three sensor streams
CONNECT, COMAP, AND COFLATMAP [CONNECTEDSTREAMS -> DATASTREAM] 本章翻译比较水,可以暂时忽略,尤其最后两段
在流处理中,组合两个流的事件是一个非常常见的需求。考虑这样一个应用程序,该应用程序监视森林区域,并在发生火灾的高风险时输出警报。该应用程序接收您之前看到的温度传感器读数流和一个额外的烟雾水平测量流。当温度超过给定的阈值且烟雾水平很高时,应用程序发出火灾警报。
DataStream API提供了联结【connect】转换来支持这种用例。DataStream.connect()方法接收一个DataStream并返回一个ConnectedStreams对象,该返回值对象表示一个由两个流联结后的流。
// first stream
val first: DataStream[Int] = ...
// second stream
val second: DataStream[String] = ...
// connect streams
val connected: ConnectedStreams[Int, String] = first.connect(second)
ConnectedStreams提供map()和flatMap()方法,它们分别需要CoMapFunction和CoFlatMapFunction作为参数。
这两个函数都是根据第一个和第二个输入流的类型以及输出流的类型来类型化的(即接口的泛型类型),并定义了两个方法,每个方法对应一个输入流。调用map1()和flatMap1()来处理第一个输入中的事件,调用map2()和flatMap2()来处理第二个输入中的事件。
// IN1: the type of the first input stream
// IN2: the type of the second input stream
// OUT: the type of the output elements
CoMapFunction[IN1, IN2, OUT]
> map1(IN1): OUT
> map2(IN2): OUT
// IN1: the type of the first input stream
// IN2: the type of the second input stream
// OUT: the type of the output elements
CoFlatMapFunction[IN1, IN2, OUT]
> flatMap1(IN1, Collector[OUT]): Unit
> flatMap2(IN2, Collector[OUT]): Unit
NOTE 函数不能选择要从哪个已连接的流中读取:请注意,我们无法控制调用CoMapFunction和CoFlatMapFunction方法的顺序。相反,只要事件通过相应的输入到达,就会调用相应的方法。
两个流的联合处理通常要求在这两个流上的事件,基于某些条件被确切的路由,使得可以在操作符所并行运行的同一个实例(其实就是任务)上被执行。 默认情况下,connect()不会在两个流的事件之间建立关系,这样两个流中的事件会被随机分配给操作符实例(其实就是任务)。 但是这种行为会产生不确定性的结果,而这通常是我们所不希望看到的。为了在ConnectedStreams上实现确定性的转换,connect()可以与keyBy()或broadcast()结合使用,如下所示:
val one: DataStream[(Int, Long)] = ...
val two: DataStream[(Int, String)] = ...
// keyBy two connected streams
val keyedConnect1: ConnectedStreams[(Int, Long), (Int, String)] = one
.connect(two)
.keyBy(0, 0) // key both input streams on first attribute
// alternative: connect two keyed streams
val keyedConnect2: ConnectedStreams[(Int, Long), (Int, String)] = one.keyBy(0)
.connect(two.keyBy(0)
无论您是对ConnectedStreams应用了keyBy()还是对KeyedStreams应用了connect(),connect() 转换都会将来自两个流中的使用相同键的数据记录路由到相同的操作符实例上。注意,这两个流的键应该引用相同的实体类,就像SQL查询中的join谓词一样。应用于既联结又键控的流上的操作符可以访问键控状态【keyed state】(第八章详细讲解)
下一个例子展示了如何将一个(非键控的)DataStream 与一个广播流联结起来:
val first: DataStream[(Int, Long)] = ...
val second: DataStream[(Int, String)] = ...
// connect streams with broadcast
val keyedConnect: ConnectedStreams[(Int, Long), (Int, String)] = first
// broadcast second input stream
.connect(second.broadcast())
将广播流的所有事件复制并发送到后续处理函数的所有并行操作符实例上。而非广播流中的事件只是简单的被转发。 因此,可以联合处理两个输入流的所有元素。
NOTE:USE BROADCAST STATE IF YOU NEED CONNECT A KEYED AND A BROADCASTED STREAM
Broadcast state是Broadcast ()-connect()转换的改进版本。它还支持联结键控和广播流,并将广播事件存储在托管状态。有了它,您可以实现通过数据流动态配置的操作符,例如,添加或删除过滤规则或更新机器学习模型。在“第七章:Using Connected Broadcast State”.中详细讨论了广播状态。
下面的示例代码展示了火灾警报场景的简化版实现:
// ingest sensor stream
val tempReadings: DataStream[SensorReading] = env
.addSource(new SensorSource)
.assignTimestampsAndWatermarks(new SensorTimeAssigner)
// ingest smoke level stream
val smokeReadings: DataStream[SmokeLevel] = env
.addSource(new SmokeLevelSource)
.setParallelism(1)
// group sensor readings by their id
val keyed: KeyedStream[SensorReading, String] = tempReadings
.keyBy(_.id)
// connect the two streams and raise an alert
// if the temperature and smoke levels are high
val alerts = keyed
.connect(smokeReadings.broadcast)
.flatMap(new RaiseAlertFlatMap)
alerts.print()
Example 5-23. Fire alert application using connected streams
class RaiseAlertFlatMap extends CoFlatMapFunction[SensorReading, SmokeLevel, Alert] {
var smokeLevel = SmokeLevel.Low
override def flatMap1(in1: SensorReading, collector: Collector[Alert]): Unit = {
// high chance of fire => true
if (smokeLevel.equals(SmokeLevel.High) && in1.temperature > 100) {
collector.collect(Alert("Risk of fire!", in1.timestamp))
}
}
override def flatMap2(in2: SmokeLevel, collector: Collector[Alert]): Unit = {
smokeLevel = in2
}
}
Example 5-24. A CoFlatMapFunction that raises an alert if the temperature and the smoke level are both high
请注意,此示例中的状态(smokeLevel)没有被检查点,那么在发生故障时将会丢失。
SPLIT [DATASTREAM -> SPLITSTREAM] AND SELECT [SPLITSTREAM -> DATASTREAM]
Split是对union转换的逆转换。 它将输入流拆分为两个或多个输出流。 每个传入的事件都可以路由到0个,一个或多个输出流。 因此,split也可用于过滤或复制事件。 图5.6展示了一个操作符,它将所有白色事件放入一个单独的流中。

Figure 5-6. A split operation that splits the input stream into a stream of white events and a stream of others.
DataStream.split() 方法接收一个OutputSelector,它定义如何将流元素分配给指定名字的输出【named outputs】。 OutputSelector中定义了一个为每个输入事件调用的select()方法,该方法返回一个 java.lang.Iterable [String]。 其中的字符串表示的是元素路由到的输出【output】的名称。
// IN: the type of the split elements
OutputSelector[IN]
> select(IN): Iterable[String]
DataStream.split() 方法返回一个SplitStream,它提供一个select()方法,我们可以通过指定一个输出名称【output name】的列表作为该方法的入参,以从SplitStream中选择一个或多个流。
下面的示例将数字流分为大数流和小数流。
Example 5-25. Split a tuple stream into a stream with large numbers and a stream with small numbers.
val inputStream: DataStream[(Int, String)] = ...
val splitted: SplitStream[(Int, String)] = inputStream
.split(t => if (t._1 > 1000) Seq("large") else Seq("small"))
val large: DataStream[(Int, String)] = splitted.select("large")
val small: DataStream[(Int, String)] = splitted.select("small")
val all: DataStream[(Int, String)] = splitted.select("small", "large")
Split转换的一个限制是所有输出流都与输入类型相同。在“Emitting to Side Outputs”中,我们给出了ProcessFunction的side output特性,它能够从一个函数发射多个不同类型的流
5.2.4 Partitioning transformations
分区转换对应于我们在第2章中介绍的数据交换策略。这些操作【operations】定义了如何将事件分配给任务。在使用DataStream API构建应用程序时,系统根据操作语义和配置的并行度自动选择数据分区策略,并将数据路由到正确的目的地。有时,有必要或希望在应用程序级别中控制分区策略或定义自定义分区器。 例如,如果我们知道DataStream的并行分区的负载是倾斜的,我们可能希望重新对数据进行负载均衡,以便均匀地分配后续操作符的计算负载。 或者,应用程序逻辑可能要求操作的所有任务接收相同的数据,或者按照自定义策略分发事件。 在本节中,我们将介绍DataStream中相应的方法,使用户能够控制分区策略或定义自己的分区策略。
请注意,keyBy()与本节中讨论的分区转换不同。 此部分中的所有转换都会生成DataStream,而keyBy()生成的是KeyedStream,可以在其上应用可以访问键控状态的转换。
RANDOM
随机数据交换策略是通过DataStream API的shuffle()方法实现的。该方法将数据事件呈均匀分布的随机分布到下游操作符的并行任务中。
ROUND-ROBIN
rebalance()方法对输入流进行分区,以便事件以轮询【round-robin】的方式均匀地分布到后继任务【successor task】上。
RESCALE
rescale()方法亦以轮询【round-robin】的方式分发事件,但仅将任务分配给后继任务【successor task】的子集上。 从本质上讲,重新缩放分区策略【rescale partitioning strategy】提供了一种在数据流图包含扇出模式时执行轻量级负载再平衡的方法。 rebalance()和rescale()之间的根本区别在于形成的任务连接的方式。 虽然rebalance()将在所有发送端任务与所有接收端任务之间创建通信通道【communication channels 】,但rescale()将仅创建从每个任务到下游操作符的某些任务的通信通道【communication channels 】。rebalance和rescale之间的连接模式差异如下图所示:
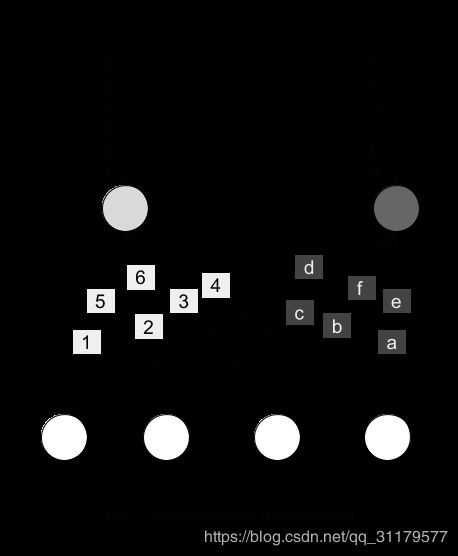
Figure 5-7. Rebalance transformation

Figure 5-8. Rescale transformation
BROADCAST
broadcast()方法复制输入数据流,以便将所有事件发送到下游操作符的所有并行任务上。
GLOBAL
global()方法将输入数据流的所有事件发送到下游操作符的第一个并行任务。必须小心使用这种分区策略,因为将所有事件路由到同一个任务可能会影响应用程序的性能。
CUSTOM
当预定义的分区策略都不合适时,可以使用partitionCustom()方法定义自己的自定义分区策略。该方法接收一个Partitioner对象,该对象实现分区逻辑以及对流进行分区所使用的字段(field)或键位置(例如列表的索引)。下面的示例对整数流进行分区,以便将所有负数发送到第一个任务,并将所有其他数字发送到一个随机任务:
val numbers: DataStream[(Int)] = ...
numbers.partitionCustom(myPartitioner, 0)
object myPartitioner extends Partitioner[Int] {
val r = scala.util.Random
override def partition(key: Int, numPartitions: Int): Int = {
if (key < 0) 0 else r.nextInt(numPartitions)
}
}
Example 5-26. A custom partitioning example
5.2.4.Setting the parallelism
Flink应用程序通常在并行环境下执行,例如机器集群。 当将使用DataStream编写的程序提交给JobManager执行时,系统会创建数据流图【dataflow graph】并准备操作符以供执行。 每个操作符被并行化为一个或多个并行任务,每个任务处理输入流的一个子集。 操作符的并行任务数称为 操作符的并行度。它决定了操作符的处理工作量可以分配多少,以及它可以处理多少数据。
您可以通过在执行环境中设置并行度或通过设置各个操作符的并行度来控制Flink应用程序的操作符并行度。执行环境为它所执行的所有操作符、数据发生器/数据源和数据接收器定义默认的并行性。环境的并行性(以及所有运算符的默认并行性)根据应用程序启动的上下文自动初始化。如果应用程序在本地执行环境中运行,则将并行性设置为与CPU核心数相匹配。当向正在运行的Flink集群提交应用程序时,除非通过提交客户机显式指定环境并行度,否则将环境并行度设置为集群的默认并行度
通常,将操作符的并行度配置为一个相对于环境的默认并行度的值,这是一个好主意。这使得您可以通过提交客户端【submission client】,来调整并行度轻松地扩展应用程序。您可以访问环境的默认并行性,如下例所示:
val env: StreamExecutionEnvironment.getExecutionEnvironment
// get default parallelism as configured in the cluster config or
// explicitly specified via the submission client.
val defaultP = env.env.getParallelism
Example 5-27. Setting the default parallelism for all operators to 4
您还可以覆盖环境的默认并行性,但是您将无法再通过提交客户端【submission client】来控制应用程序的并行度。它是使用StreamExecutionEnvironment.setParallelism()方法设置的。下面的例子展示了如何将所有操作符的默认并行度设置为32:
val env: StreamExecutionEnvironment.getExecutionEnvironment
// set parallelism of the environment
env.setParallelism(32)
您可以通过设置单个操作符的并行度来覆盖执行环境的默认并行度。在下面的例子中,数据发生器/数据源操作符将以默认并行度执行,而映射转换的并行度为默认并行度的2倍,接收器操作将由2个并行任务执行:
val env = StreamExecutionEnvironment.getExecutionEnvironment
// get default parallelism
val defaultP = env.getParallelism
// the source runs with the default parallelism
val result: = env.addSource(new CustomSource)
// the map parallelism is set to double the default parallelism
.map(new MyMapper).setParallelism(defaultP * 2)
// the print sink parallelism is fixed to 2
.print().setParallelism(2)
Example 5-28. Setting different parallelism for different operators
当您通过提交客户端提交应用程序并指定并行度为16时,数据源/发生器程序将以并行度为16运行,映射程序将以32个任务运行,接收器将以2个任务运行。如果您在本地环境中运行应用程序,例如在IDE中,在一台有8个内核的机器上,源任务将运行8个任务,映射器运行16个任务,接收器运行2个任务。
5.2.5 Defining keys and referencing fields
您在上一节中看到的某些转换需要建立在输入流类型基础上的键规范或字段引用。在Flink中,keys并不像使用键值对的系统那样在输入流中预定义, 而是将key定义为建立在输入数据之上的函数。 因此,没有必要定义数据类型来保存键和值,这避免了许多样板代码。
下面我们将讨论引用字段的不同方法和定义数据类型的键。
FIELD POSITIONS
如果数据类型是元组,则可以通过使用对应元组元素的属性字段位置来定义键。以下示例通过输入元组的第二个属性字段键入输入流:
val input: DataStream[(Int, String, Long)] = ...
val keyed = input.keyBy(1)
Example 5-29. Key by field position
还可以定义由多个元组字段组成的组合键。在这种情况下,我们要提供这些元组属性字段的位置列表,一个接一个。我们可以通过下面方式,使用元组的第二个和第三个属性字段来键控输入流:
val keyed2 = input.keyBy(1, 2)
FIELD EXPRESSIONS
另一种定义键【define keys】和选择属性字段【select fields】的方法是使用基于字符串的字段表达式。字段表达式适用于元组、POJOs和样本类。它们还支持嵌套字段的选择。
在本章的介绍性示例中,我们定义了以下样本类:
case class SensorReading(
id: String,
timestamp: Long,
temperature: Double)
我们就可以将字段名“id”传递给keyBy()函数,以指定我们希望通过传感器id对输入流进行键控。
val sensorStream: DataStream[SensorReading] = ...
val keyedSensors = sensorStream.keyBy("id")
POJO或样本类是根据它们的属性字段名来选择字段的,就如上面的示例所示。而元组则可以通过字段名(Scala中元组是以_1开始,而java版的元组则以_0开始)或字段偏移索引(均从0开始偏移)来选择字段。
val input: DataStream[(Int, String, Long)] = ...
val keyed1 = input.keyBy("2") // key by 3rd field
val keyed2 = input.keyBy("_1") // key by 1st field
DataStream> javaInput = ...
javaInput.keyBy(“f2”) // key Java tuple by 3rd field
通过用“.”表示嵌套级别,可以选择POJO和元组中的嵌套字段。例如,考虑下面这个样本类:
case class Address(
address: String,
zip: String
country: String)
case class Person(
name: String,
birthday: (Int, Int, Int), // year, month, day
address: Address)
如果我们想引用一个人的邮政编码(ZIP code),我们可以使用字段表达式address.zip。如下所示:
val persons: DataStream[Person] = ...
persons.keyBy("address.zip") // key by nested POJO field
也可以在混合类型上嵌套表达式:比如birthday._1表达式引用的则是birthday 这个元组的第一个字段,即,也就是出生的年份。
persons.keyBy("birthday._1") // key by field of nested tuple
可以使用通配符字段表达式:,来选择完整的数据类型。例如birthday.,引用的是整个birthday 元组。通配符字段表达式对于Flink所有支持的数据类型都是有效的。
persons.keyBy("birthday._") // key by all fields of nested tuple
KEY SELECTORS
指定键的第三种方式是KeySelector函数。KeySelector 函数用于从输入事件中提取键。
// T: the type of input elements
// KEY: the type of the key
KeySelector[IN, KEY]
> getKey(IN): KEY
这个介绍性示例实际上在keyBy()方法中使用了一个简单的KeySelector函数:
val sensorData: DataStream[SensorReading] = ...
val byId: KeyedStream[SensorReading, String] = sensorData.keyBy(_.id)
KeySelector函数接收一个输入条目并返回一个键。键并不需要是输入事件中的某一字段,它可以由任意计算派生出。在以下代码示例中,KeySelector函数返回元组字段中的最大值作为键:
val input : DataStream[(Int, Int)] = ...
val keyedStream = input.keyBy(value => math.max(value._1, value._2))
与字段位置【field positions】和字段表达式【field expressions】这两种方法相比,KeySelector函数的优点是:得益于KeySelector类的泛型类型,生成的键是强类型的。
5.2.6 Defining UDFs
到目前为止,您已经在本章的代码示例中看到了用户定义函数【UDF】的作用。在本节中,我们将更详细地解释在DataStream API中定义和参数化UDF的不同方法。
Function Classes
Flink将用户定义函数(如MapFunction、FilterFunction和ProcessFunction)的所有接口公开为接口或抽象类。
函数是通过实现接口或扩展抽象类来实现的。在下面的例子中,我们实现了一个过滤器函数,用于过滤包含单词“flink”的字符串:
class FlinkFilter extends FilterFunction[String] {
override def filter(value: String): Boolean = {
value.contains("flink")
}
}
然后,函数类的一个实例可以作为参数传递给filter转换:
val flinkTweets = tweets.filter(new FlinkFilter)
函数也可以实现为匿名类:
val flinkTweets = tweets.filter(
new RichFilterFunction[String] {
override def filter(value: String): Boolean = {
value.contains("flink")
}
})
函数可以通过它们的构造函数接收参数。我们可以对上面的例子进行参数化,并将字符串“flink”作为参数传递给KeywordFilter构造函数,如下所示:
val tweets: DataStream[String] = ???
val flinkTweets = tweets.filter(new KeywordFilter("flink"))
class KeywordFilter(keyWord: String) extends FilterFunction[String] {
override def filter(value: String): Boolean = {
value.contains(keyWord)
}
}
当一个程序被提交执行时,所有函数对象都使用Java序列化进行序列化,并被传送到其相应操作符的所有并行任务中。因此,在对象反序列化之后,所有配置值都将保留。
NOTE: FUNCTIONS MUST BE JAVA SERIALIZABLE
Flink使用Java序列化序列化所有函数对象,将它们发送到工作进程【worker processes】。用户函数中包含的所有内容都必须是可序列化的。
如果函数需要一个不可序列化的对象实例,则可以将其实现为一个富函数并在open()方法中初始化不可序列化字段,或者覆盖Java序列化和反序列化方法。
LAMBDA FUNCTIONS
大多数DataStream API方法都接受lambda函数形式的UDF。Lambda函数可用于Scala和Java 8,当不需要访问状态和配置等这样的高级操作时,它提供了一种简单而简洁的方式来实现应用程序逻辑:
val tweets: DataStream[String] = ...
// a filter lambda function that checks if tweets contains the
// word “flink”
val flinkTweets = tweets.filter(_.contains("flink"))
RICH FUNCTIONS CLASSES
定义UDF的一种更强大的方法是富函数。富函数定义了额外的方法,用于UDF的初始化和拆解,并提供钩子【hooks】来访问UDF执行的上下文。前面的lambda函数示例可以使用富函数来重写,如下所示:
class FlinkFilterFunction extends RichFilterFunction[String] {
override def filter(value: String): Boolean = {
value.contains("flink")
}
}
然后,可以将富函数实现的实例对象,作为参数传递给filter转换:
val flinkTweets = tweets.filter(new FlinkFilterFunction)
另一种定义富函数的方法是作为匿名类:
val flinkTweets = tweets.filter(
new RichFilterFunction[String] {
override def filter(value: String): Boolean = {
value.contains(“flink”)
}
})
所有DataStream API转换函数都有富函数的版本,因此您可以在可以使用lambda函数的地方使用它们。命名约定是,函数名以Rich开头,后面跟着转换名,例如Filter,并以Function结尾,比如RichMapFunction, RichFlatMapFunction,等等。
UDF可以通过其构造函数接收参数。 这些参数将作为函数对象的一部分使用常规Java序列化进行序列化,并传递到将执行该函数的所有并行任务实例上。
PS: UDF SERIALIZATION
Flink使用Java序列化序列化所有udf,将它们发送给工作者进程【worker processes】。用户函数中包含的所有内容都必须是可序列化的。
我们可以对上面的例子进行参数化,并将字符串“flink”作为参数传递给FlinkFilterFunction构造函数,如下所示:
val tweets: DataStream[String] = …
val flinkTweets = tweets.filter(new MyFilterFunction(“flink”))
class MyFilterFunction(keyWord: String) extends RichFilterFunction[String] {
override def filter(value: String): Boolean = {
value.contains(keyWord)
}
}
当使用富函数时,您可以实现两个额外的方法,它们提供对函数生命周期的访问:
- open()方法是富函数的初始化方法。在调用像filter、map和fold这样的转换方法之前,每个任务都会调用一次open方法。open()通常用于只需要完成一次的设置工作。请注意,Configuration参数只可被DataSet API使用,而不能被DataStream API使用。因此,在这里它应该被忽略。
- close()方法是函数的终结方法,在最后一次调用转换方法之后,每个任务都会调用一次close方法。 因此,它通常用于清理和释放资源
此外,getRuntimeContext()方法提供对函数的RuntimeContext的访问。RuntimeContext可用于检索诸如函数并行度、子任务索引以及当前执行UDF的任务的名称等信息。此外,它还包括访问分区状态的方法。Flink中的有状态的流处理将在第8章中详细讨论。下面的示例代码展示了如何使用RichFlatMapFunction的方法:
class MyFlatMap extends RichFlatMapFunction[Int, (Int, Int)] {
var subTaskIndex = 0
override def open(configuration: Configuration): Unit = {
subTaskIndex = getRuntimeContext.getIndexOfThisSubtask
// do some initialization
// e.g. establish a connection to an external system
}
override def flatMap(in: Int, out: Collector[(Int, Int)]): Unit = {
// subtasks are 0-indexed
if(in % 2 == subTaskIndex) {
out.collect((subTaskIndex, in))
}
// do some more processing
}
override def close(): Unit = {
// do some cleanup, e.g. close connections to external systems
}
}
Example 5-30. The open() and close() methods of a RichFlatMapFunction
open()和getRuntimeContext()方法还可以通过环境ExecutionConfig用于配置。我们可以使用RuntimeContext的getExecutionConfig()方法检出ExecutionConfig,它允许我们设置可以被所有富UDF访问的全局配置选项。
下面的示例程序使用全局配置将“keyWord”参数设置为“flink”,然后在RichFilterFunction中读取该参数:
def main(args: Array[String]) : Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
// create a configuration object
val conf = new Configuration()
// set the parameter “keyWord” to “flink”
conf.setString("keyWord", "flink")
// set the configuration as global
env.getConfig.setGlobalJobParameters(conf)
// create some data
val input: DataStream[String] = env.fromElements(
"I love flink", "bananas", "apples", "flinky")
// filter the input stream and print it to stdout
input.filter(new MyFilterFunction).print()
env.execute()
}
class MyFilterFunction extends RichFilterFunction[String] {
var keyWord = ""
override def open(configuration: Configuration): Unit = {
// retrieve the global configuration
val globalParams = getRuntimeContext.getExecutionConfig.getGlobalJobParameters
// cast to a Configuration object
val globConf = globalParams.asInstanceOf[Configuration]
// retrieve the keyWord parameter
keyWord = globConf.getString("keyWord", null)
}
override def filter(value: String): Boolean = {
// use the keyWord parameter to filter out elements
value.contains(keyWord)
}
}
Example 5-31. Using the global configuration to set parameters in a RichFilterFunction
Including External and Flink Dependencies
在实现Flink应用程序时,添加外部依赖项是常见的要求。 有许多流行的库,例如Apache Commons或Google Guava,它们可以解决和简化各种用例。 此外,大多数Flink应用程序依赖于Flink的一个或多个连接器以用来从外部系统(如Apache Kafka,文件系统或Apache Cassandra)中提取数据或向其发送数据。 某些应用程序还利用Flink的特定领域的库,例如Table API,SQL或CEP库。 因此,大多数Flink应用程序不仅依赖于Flink的DataStream API依赖项和Java SDK,还依赖于其他第三方和Flink内部包。
当一个应用程序被执行时,它的所有依赖关系必须对应用程序可用。默认情况下,Flink集群只加载核心API依赖项(DataStream和DataSet API)。应用程序需要的所有其他依赖项都必须显式地提供。
这种设计的原因是将默认依赖项的数量保持在较低的水平。大多数连接器和库依赖于一个或多个库,这些库通常具有多个额外的传递依赖项。这些通常包括经常使用的库,如Apache Commons或谷歌的Guava。许多问题源自同一库的不同版本之间的不兼容性,这些版本从不同的连接器或直接从用户应用程序引入。
有两种方法可以确保应用程序在执行时所有依赖项都可用:
- 将所有依赖的库绑定到应用程序的JAR文件中。这将生成一个自包含的、但通常相当大的应用程序JAR文件。
- 依赖的JAR文件可以添加到Flink设置的./lib文件夹中。在这种情况下,当Flink进程启动时,依赖项被加载到类路径中。像这样添加到类路径的依赖项对于在Flink设置上运行的所有应用程序都是可用的(并且可能会干扰)
构建所谓的胖JAR文件是处理应用程序依赖关系的首选方法。我们在第4章中介绍的使用Flink的Maven原型生成的Maven项目,这些项目被配置为生成包含所有必需依赖项的应用程序胖JAR。默认情况下包含在Flink进程类路径【classpath】中的依赖项将自动从JAR文件中排除。pom.xmll文件包含解释如何添加额外依赖项的注释。
Summary
在本章中,我们介绍了Flink的DataStream API的基础知识。 您已经检查了Flink程序的结构,并且已经学习如何组合数据和分区转换以构建流应用程序。 您还研究了受支持的数据类型以及指定键和用户定义函数的不同方法。 如果您现在退后一步并再次阅读介绍性示例,那么您就有了一个清楚的概念。 在下一章中,随着您学习如何使用窗口运算符和时间语义来丰富我们的程序,事情会变得更加有趣。
- 有关键控状态的详细信息,请参阅第8章。
- Flink还旨在将其自身的外部依赖降到最低限度,并对用户应用程序隐藏大部分依赖(包括传递依赖),以防止版本冲突。