Selenium(WebDriver)+ python 脚本编写教程
安装完 Selenium(WebDriver)+ python + Pycharm 后,可以学习编写脚本了。
前置任务:安装WebTours
下载地址:https://marketplace.microfocus.com/appdelivery/content/web-tours-sample-application#app_releases
若无法下载,可以选择网盘链接。
网盘地址:https://pan.baidu.com/s/17xmMtQ9OayFz4PepzkP3GQ
提取码:lbtn
安装 strawberry,解压 WebTours,打开 WebTours 解压目录,点击 StartServer.bat 启动

输入网址:http://localhost:1080/WebTours/
默认账号:jojo,密码:bean,可在 sign up now 新建账号
编写脚本
导入包
from selenium import webdriver
打开、关闭浏览器
driver = webdriver.Ie()
driver = webdriver.Chrome()
driver = webdriver.FireFox()
# 关闭浏览器
driver.close()
# 关闭浏览器及浏览器驱动程序
driver.quit()
打开url
driver.get(url)
等待时间
from time import sleep
# 等待2s
sleep(2)
# 隐性等待2s
driver.implicitly_wait(2)
定位页面元素
# 查找单个元素
driver.find_element_by_name()
.send_keys()、.click()
# id、class_name、tag_name、xpath('//-[@-=""]')
# link_text(链接文字)、partial_link_text(简略的链接文字)
# 查找多个元素(多个单选框)
driver.find_elements_by_name()[]
# 识别下拉列表元素
from selenium.webdriver.support.select import Select
Select(driver.find_elements_by_)
Select(driver.find_elements_by_name()).select_by_visible_text()
获取页面元素的属性和方法
# 获取网页标题
driver.title()
# 获取元素文本值
.text
# 获取指定属性值
.get_attribute()
# 下拉列表属性值
Select().select_by_value
# index、visible_text
# 返回第一个选项
first_selected_option()
# 返回所有选项
all_selected_option()
# 取消所有选项
deselect_all()
# 取消对应xx的选项
deselect_by_value()
# index、visible_text
# 输入数据
.send_keys()
# 单选按钮、复选框、命令按钮
.click()
切换窗口
driver.switch to.xx()
# 定位到当前聚焦元素
.active_element()
# 切换alert窗口
.alert()
# 切换某个frame
.frame()
# 切换主页面
.default_content()
# 切换 window_name 页签
.window(window_name)
# 切换上一层frame
.parent_frame()
编写脚本实战
PS:每当页面刷新的时候,可以添加 sleep() 等待时间,以防页面还没有加载完毕,而脚本运行过快,查找不到元素报错。
from selenium import webdriver
from time import sleep
from selenium.webdriver.support.select import Select
driver = webdriver.Chrome() # 选择喜欢的浏览器
# driver.implicitly_wait(2) 隐性等待2s
driver.get("http://localhost:1080/WebTours")
print(driver.title)
# 点击注册
driver.switch_to.default_content()
driver.switch_to.frame("body")
driver.switch_to.frame("info")
# driver.find_element_by_link_text("sign up now").click()
driver.find_element_by_partial_link_text("sign up").click()
sleep(3)
# 使用账号 jojo 和密码 bean 登录
driver.switch_to.default_content()
driver.switch_to.frame("body")
driver.switch_to.frame("navbar")
driver.find_element_by_name("username").send_keys("jojo")
driver.find_element_by_name("password").send_keys("bean")
driver.find_element_by_name("login").click()
sleep(3)
# 判断是否登录成功
driver.switch_to.default_content()
driver.switch_to.frame("body")
driver.switch_to.frame("info")
exp = "Welcome"
act = driver.find_element_by_tag_name("body").text
# 判断 body 是否包含“welcome”文字信息
if exp in act:
print("登录成功")
else:
print("登录失败")
# 结果为 登录成功
# driver.quit()
增强脚本
检查点
运算符 in :模糊匹配 ( == :精确匹配)
# 判断s1是否存在于s2中
s1 in s2
print("qw" in "qwe") # True
if 语句:if () : - else : -
# 括号可省略
a = 10
if a > 10:
print(1)
else:
print(0)
# 结果为0
参数化
1、for 循环语句
count = 0
for i in range(1,100):
count = count + i
print(count)
# 结果为 4950
a = 's1 s2 a1,b1'
# split() 可以按空格、tab拆分字符串
b = a.split()
print(type(b)) # 2、读取 txt 文件
- 打开 txt 文件
file = open(文件名,‘r’) :默认 r 只读,可省略 - 遍历文件
for 变量 in file:输出变量即读出整个文件,按行读出
list = file.readlines():把文件所有行读到一个列表,换行符也可读
len ( list ):返回列表元素个数 - 关闭文件
file.close():释放万文占用资源,即关闭文件
举栗子:在 C:\Users\ASUS\Desktop 新建一个 test.txt
文件内容为:

新建文件 test.py
# 打开文件,url 要注意转义,在每个 \ 前加 \
# 或者将 \ 改为 / ,open(r"C:/Users/ASUS/Desktop/test.txt","r")
# 或者在 url 前加 r ,open(r"C:\Users\ASUS\Desktop\test.txt","r")
file = open("C:\\Users\\ASUS\\Desktop\\test.txt","r")
# 读取文件每一行内容
for i in file:
print(i,end = "")
# end = "" 表示以空字符结束,否则数据将换行展示
# 关闭文件
file.close()
结果:

也可以这样写:
file = open("C:\\Users\\ASUS\\Desktop\\test.txt","r")
for i in file:
a = i.split()
# 或者 print(a[0] + " " + a[1])
for j in a:
print(j,end=" ")
print()
file.close()
file = open("C:\\Users\\ASUS\\Desktop\\test.txt","r")
a = file.readlines()
print(type(file)) # 3、读取 excel 文件
- 安装 pandas ,在线安装:pip install pandas (有点慢)
安装完成,pip list 查看 pandas 版本
离线安装:下载 pandas 压缩包,解压
打开 cmd 进入解压地址:pip install --no-index --find-links=. -r requirements.txt
网盘链接:https://pan.baidu.com/s/1lhQFlb8JfLwNxgTtgYsysg
提取码:ln91
在 pycharm 引入:
file - setting - project: xx - project Interpreter ,添加 pandas

编写用例时,若出现:
ImportError: Missing optional dependency ‘xlrd’. Install xlrd >= 1.0.0 for Excel support Use pip or conda to install xlrd.
打开cmd :pip install xlrd,别忘了在 pycharm 引入。
-
读取 excel 文件
import pandas
pandas.read_excel():文件名,sheet_name = sheet编号或名称,names = 列名列表(可新增),dtype = {列名:类型}(可新增),skiprows = 跳过数据某行数(第一行 = 列名),header = None 表示没有列名(如果没有列名,列表会把第一行数据当列名) -
返回列表
file.values.tolist()
举栗子:新建 exc.xls
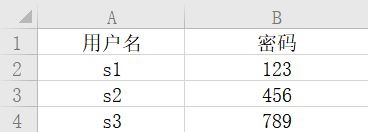
import pandas
file = pandas.read_excel(r"C:\Users\ASUS\Desktop\exc.xls")
print(file)
结果:

也可以:
import pandas
file = pandas.read_excel(r"C:\Users\ASUS\Desktop\exc.xls",
names = ['name','pass'],
dtype = {'name':str,'pass':str})
print(file)
结果:

返回数据列表 file.values.tolist()
import pandas
file = pandas.read_excel(r"C:\Users\ASUS\Desktop\exc.xls",
names = ['name','pass'],
dtype = {'name':str,'pass':str},
header = None,
skiprows = 1)
ls = file.values.tolist()
print(ls)
for i in ls:
print(i[0] + '\t' + i[1])
结果:

4、访问数据库
安装 pymysql:pip install pymaysql,pip list 查看安装版本
-
连接数据库
conn = pymysql.connect():host = 服务器ip(默认localhost),port = 3306,user = 用户名,passwd = 密码,db = 数据库名,charset = ‘utf8’ -
读取数据
data = conn.cursor():创建游标
sql = select - (sql 语句):查询数据
data.execute(sql):执行语句
list = data.fetchall():获得数据元组
data.close():关闭游标
conn.close():关闭数据库 -
插入数据
sql = ’ insert into - values(%d, “%s”) ’ % (值1, 值2):插入数据
data.execute(sql):执行语句
conn.commit():提交数据 -
批量提交数据
list.append((值1, 值2, …)):数据存入列表
sql = ’ insert into - values(%s,%s,…) ’ :插入数据
data.executemany(sql , list)
conn.commit():提交数据
举栗子:
打开 cmd,输入 net start mysql 启动 mysql 服务
在 test 数据库创建表 users,包含字段 uname、passd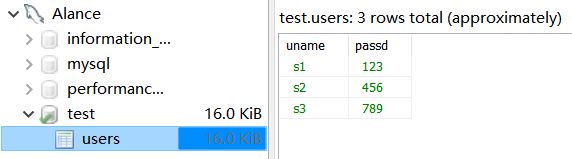
读取数据
import pymysql
# 连接数据库
conn = pymysql.connect(host = "localhost",port = 3306,
user = 'root',passwd = "123456",
db = 'test',charset = 'utf8')
# 定义游标
data = conn.cursor()
# 定义sql语句
sql = 'select * from users'
# 执行语句
data.execute(sql)
list = data.fetchall()
print(list)
for i in list:
print(i[0] + " " + i[1])
# 关闭游标与数据库
data.close()
conn.close()
结果:

插入数据
import pymysql
# 连接数据库
conn = pymysql.connect(host = "localhost",port = 3306,
user = 'root',passwd = "123456",
db = 'test',charset = 'utf8')
# 定义游标
data = conn.cursor()
# 定义sql语句
sql = 'insert into users values("%s","%s")' % ('s4','666')
# 执行语句
data.execute(sql)
# 提交数据
conn.commit()
# 关闭游标与数据库
data.close()
conn.close()
结果:

批量插入数据
import pymysql
# 连接数据库
conn = pymysql.connect(host = "localhost",port = 3306,
user = 'root',passwd = "123456",
db = 'test',charset = 'utf8')
# 定义游标
data = conn.cursor()
# 批量数据
list = []
for i in range(5,10):
list.append(('s' + str(i), str(i)))
# 定义sql语句
sql = 'insert into users values(%s, %s)'
# 执行语句
data.executemany(sql,list)
# 提交批量数据
conn.commit()
# 关闭游标与数据库
data.close()
conn.close()
结果:

编写自动化测试脚本实战
1、txt 文档自动化
C:\Users\ASUS\Desktop\test.txt 的内容
from selenium import webdriver
from time import sleep
from selenium.webdriver.support.select import Select
driver = webdriver.Chrome() # 选择喜欢的浏览器
file = open(r"C:\Users\ASUS\Desktop\test.txt","r")
for i in file:
f = i.split() # 一组账号密码
uname = f[0] # 用户名
passw = f[1] # 密码
# driver.implicitly_wait(2) 隐性等待2s
driver.get("http://localhost:1080/WebTours")
print(driver.title)
# 点击注册
driver.switch_to.default_content()
driver.switch_to.frame("body")
driver.switch_to.frame("info")
# driver.find_element_by_link_text("sign up now").click()
driver.find_element_by_partial_link_text("sign up").click()
sleep(3)
# 跳转注册页面,填写用户名与密码,点击注册
driver.switch_to.default_content()
driver.switch_to.frame("body")
driver.switch_to.frame("info")
driver.find_element_by_name("username").send_keys(uname)
driver.find_element_by_name("password").send_keys(passw)
driver.find_element_by_name("passwordConfirm").send_keys(passw)
driver.find_element_by_name("register").click()
sleep(3)
# 判断是否注册成功
driver.switch_to.default_content()
driver.switch_to.frame("body")
driver.switch_to.frame("info")
exp = "Thank you, " + uname
act = driver.find_element_by_tag_name("body").text
# 判断 body 是否包含 "Thank you, " + uname 文字信息
if exp in act:
print("注册成功")
else:
print("注册失败")
file.close()
driver.quit()
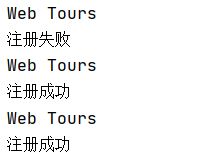
结果:

打开 WebTours 解压地址,WebTours - cgi-bin - users
可以看到新增三个用户:s1,s2,s3

2、excel 文件自动化
先将 WebTours - cgi-bin - users 路径的 s2,s3 删除
C:\Users\ASUS\Desktop\exc.xls 文件, sheet_name = 2
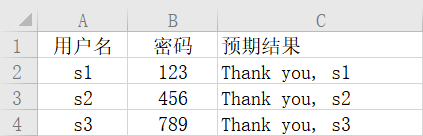
预期结果:s1、s2、s3 - 注册成功
实际结果:s1 - 注册失败,s1、s2 - 注册成功
from selenium import webdriver
from time import sleep
import pandas
driver = webdriver.Chrome() # 选择喜欢的浏览器
file = pandas.read_excel(r"C:\Users\ASUS\Desktop\exc.xls",
names = ['name','pass','exp'],
dtype = {'name':str,'pass':str,'exp':str},
sheet_name = 'Sheet2')
ls = file.values.tolist()
for i in ls:
uname = i[0] # 用户名
passw = i[1] # 密码
exp = i[2] # 预期结果
driver.get("http://localhost:1080/WebTours")
print(driver.title)
# 点击注册
driver.switch_to.default_content()
driver.switch_to.frame("body")
driver.switch_to.frame("info")
driver.find_element_by_partial_link_text("sign up").click()
sleep(3)
# 跳转注册页面,填写用户名与密码,点击注册
driver.switch_to.default_content()
driver.switch_to.frame("body")
driver.switch_to.frame("info")
driver.find_element_by_name("username").send_keys(uname)
driver.find_element_by_name("password").send_keys(passw)
driver.find_element_by_name("passwordConfirm").send_keys(passw)
driver.find_element_by_name("register").click()
sleep(3)
# 判断是否注册成功
driver.switch_to.default_content()
driver.switch_to.frame("body")
driver.switch_to.frame("info")
act = driver.find_element_by_tag_name("body").text
# 判断 body 是否 exp 文字信息
if exp in act:
print("注册成功")
else:
print("注册失败")
driver.quit()
结果: