Flink DataStream API之State
DataStream API 之State
无论StructuredStreaming还是Flink在流处理的过程中都有一个“有状态计算“的概念,那么到底什么是有状态计算,有状态计算应用到什么场景,在Flink的DataStream API中如何使用状态,以及在Flink中状态是如何管理的,在这篇文章中,我们一点一点来学习。
1 什么是有状态计算
在讲什么是有状态计算之前,先简单说一下什么是无状态计算,在我理解,无状态计算是指本次计算结果与之前输出无关的计算。比如说,设备开关量的问题,假设我消息队列中存放的消息是每个设备的开关量信息,包含:设备ID,以及设备的开关状态(开启状态为1,关闭状态为0),我们需求是只要设备状态为0我们就标记为设备异常了需要告警。
输入:
{
"id": "divice-1",
"status": "1"
}
{
"id": "divice-2",
"status": "0"
}
输出:
{
"id": "divice-1",
"alarm": "false"
}
{
"id": "divice-2",
"alarm": "true"
}
可以发现,无论输入有多少条,它的输出只与当前输出数据有关,这样的计算就是无状态计算。
那么什么是有状态计算呢,再举个例子,同样是设备开关量的问题,现在需求是,假设数据是时间有序的,如果设备之前的开启状态,现在的处于关闭状态,即由1变为0,我们认为该设备异常了,需要告警了。那么我们在计算当前输出的时候,怎么拿到之前的输出呢?这时候就需要状态了,我们可以把之前的输入作为状态保存下来,在每次计算的时候拿出之前的状态做比较,然后进行输出。
输入:
{
"id": "divice-1",
"status": "1"
}
{
"id": "divice-1",
"status": "0"
}
{
"id": "divice-2",
"status": "0"
}
{
"id": "divice-2",
"status": "0"
}
输出:
{
"id": "divice-1",
"alarm": "true"
}
{
"id": "divice-2",
"alarm": "false"
}
2 有状态计算的应用场景
下面举几个常见的状态计算的应用场景
- 流式去重:上游系统中存在重复数据,需要先进行重复过滤,最简单的,在状态中记录所有主键,然后根据状态中是否包含主键信息,来判断是否重复。
- 窗口计算:以10分钟为一个窗口,进行词频统计,我们需要把这10分钟的数据统计结果先保存下来,等到窗口计算结束被触发之后,再将结果输出。
- 机器学习/深度学习:如训练的模型以及当前模型的参数也是一种状态,机器学习可能每次都用有一个数据集,需要在数据集上进行学习,对模型进行一个反馈。
- 访问历史数据:需要与之前的数据进行对比,上面举得设备开关量的问题,将历史数据放到状态里,与之对比。
3 Flink的DataStream中使用状态
3.1 Flink中的状态类型
Flink中的状态有两种:Managed State、Raw State。Managed State 是有Flink Runtime自动管理的State,而Raw State是原生态State,两者区别如下表所示:
| Managed State | Raw State | |
|---|---|---|
| 状态管理方式 | Flin Runtime管理,自动存储,自动恢复,在内存管理上有优化 | 需要用户自己管理,自己序列化 |
| 状态数据结构 | Value、List、Map等 | byte[] |
| 推荐使用场景 | 大多数情况都可以使用 | 当 Managed State 不够用时,比如需要自定义 Operator 时,推荐使用 Raw State |
3.2 Keyed State & Operator State
Flink提供两种基本状态:Keyed State、Operator State
| Keyed State | Operator State | |
|---|---|---|
| 使用 | 只能在KeyedStream上的算子中 | 可在所有算子中使用,常用于source,例如FlinkKafkaConsumer |
| state对应关系 | 每个Key对应一个state,一个Operatory实例处理多个Key,访问相应的多个State | 一个Operator实例对应一个State |
| 并发改变,分配方式 | State随着Key在实例间迁移 | 均匀分配、合并得全量 |
| 访问方式 | 通过 RuntimeContext 访问,这需要 Operator 是一个Rich Function | 自己实现 CheckpointedFunction 或 ListCheckpointed 接口 |
| 支持的数据结构 | ValueState、ListState、ReducingState、AggregatingState 和 MapState | ListState |
3.3 使用Managed Keyed State
keyed state需要在KeyedStream算子中使用,支持ValueState、ListState、ReducingState、AggregatingState 和 MapState这几种数据类型,这几种状态数据类型的差异如下表所示:
| 状态数据类型 | 访问接口 | 差异体现 | |
|---|---|---|---|
| ValueState | 单个值 | update(T) T value() |
储存单个值,值类型不限定 |
| MapState | Map | put(UK key,UV value) putAll(Map remove(UK key) boolean contains(UK key) UV get(UK key) Iterable Iterator Iterable Iterable |
储存类型为Map,需要注意的是在 MapState 中的 key 和 Keyed state 中的 key 不是同一个 |
| ListState | List | add(T) addAll(List update Iterable |
储存类型为List |
| ReducingState | 单个值 | add(T) addAll(List update T get() |
继承ListState但状态数据类型上是单个值,原因在于其中的 add 方法不是把当前的元素追加到列表中,而是把当前元素直接更新进了 Reducing 的结果中。输入输出类型相同。 |
| AggregatingStatte | 单个值 | add(IN) OUT get() |
类似ReducingState,但是输入输出类型可以不同 |
为方便演示这几种状态类型的实际运用,下面将分别举几个例子,有些应用场景有些牵强,只要领会其用意即可。
3.3.1 ValueState
ValueState为单值类型,我们可以通过update(T)方法更新值,通过value()方法获取该值。
3.3.1.1 获取 ValueState
要使用ValueState,需要从RuntimeContext中获取,所以需要实现RichFunction,在open()方法中通过getRuntimeContext获取RuntimeContext,最后通过getState()获取ValueState。
override def open(parameters: Configuration): Unit = {
// get state from RuntimeContext
state = getRuntimeContext
.getState(new ValueStateDescriptor[AvgState]("avgState", createTypeInformation[AvgState]))
}
getState里需要传入ValueStateDescriptor实例,无论是ValueState、MapState、ListState、ReducingState、还是AggregatingState,它们的Descriptor都继承自StateDescriptor,构造器方法相同的。如上代码,我们是通过name和typeInfo构建的实例,ValueStateDescriptor有共有三种构造器方法:
构造器一:传入name,以及typeClass
public ValueStateDescriptor(String name, Class typeClass) {
super(name, typeClass, null);
}
假如我们的状态数据类型为case class,如下所示定义
case class AvgState(count: Int, sum: Double)
我们可以通过classOf[AvgState]获取typeClass,使用此构造器创建实例如下:
new ValueStateDescriptor("avgState",classOf[AvgState])
构造器二:传入name,以及typeInfo
public ValueStateDescriptor(String name, TypeInformation typeInfo) {
super(name, typeInfo, null);
}
typeInfo我们可以通过import org.apache.flink.streaming.api.scala.createTypeInformation方法创建
new ValueStateDescriptor[AvgState]("avgState", createTypeInformation[AvgState])
构造器三:传入name,以及typeSerializer
public ValueStateDescriptor(String name, TypeSerializer typeSerializer) {
super(name, typeSerializer, null);
}
serializer可以通过继承TypeSerializer自定义实现,可以通过内置的KryoSerializer以及其它TypeSerializer创建
new ValueStateDescriptor[AvgState]("avgState", new KryoSerializer(classOf[AvgState], getRuntimeContext.getExecutionConfig))
3.3.1.2 使用ValueState实现移动平均
需求:
不考虑数据时序乱序问题,实现简单移动平均,每来到一个数就计算其整体平均值。
思路:
使用ValueState保存中间状态AvgState,该状态包含两个值,sum:目前所有数据的总和,count:目前所有数据的个数,然后sum/count求出平均值,数据进入后状态count+1,状态sum+当前数据,然后求其均值。
实现:
定义输入输出格式都为case class
输入数据格式
/**
* 设备事件
*
* @param id 设备ID
* @param value 设备数据
*/
case class DeviceEvent(id: String, value: Double)
输出数据格式
/**
* 设备移动均值
*
* @param id 设备ID
* @param avg 设备均值
*/
case class DeviceAverage(id: String, avg: Double)
状态存储格式
/**
* 均值状态
*
* @param count 数据个数
* @param sum 数据总和
*/
case class AvgState(count: Int, sum: Double)
继承RichMapFunction获取状态,并实现map方法
/**
* 继承 RichMapFunction 实现map方法
*/
class MoveAverage extends RichMapFunction[DeviceEvent, DeviceAverage] {
private var state: ValueState[AvgState] = _
override def open(parameters: Configuration): Unit = {
// get state from RuntimeContext
state = getRuntimeContext
.getState(new ValueStateDescriptor[AvgState]("avgState", new KryoSerializer(classOf[AvgState], getRuntimeContext.getExecutionConfig)))
}
override def map(value: DeviceEvent): DeviceAverage = {
// get or init state value.
val stateValue = Option(state.value()).getOrElse(AvgState(0, 0.0))
// update newStateValue to runtime
val newStateValue = AvgState(stateValue.count + 1, stateValue.sum + value.value)
state.update(newStateValue)
DeviceAverage(value.id, newStateValue.sum / newStateValue.count)
}
}
从socket获取实时数据,将数据转换为DeviceEvent格式,然后根据id分组,最后执行自定义map方法
def main(args: Array[String]): Unit = {
val params: ParameterTool = ParameterTool.fromArgs(args)
// set up execution environment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// make parameters available in the web interface
env.getConfig.setGlobalJobParameters(params)
// get input data
val streamText: DataStream[String] = env.socketTextStream(
Option(params.get("hostname")).getOrElse("localhost"),
Option(params.get("port")).getOrElse("9090").toInt)
val streamData: DataStream[DeviceEvent] = streamText.map(text => {
val token = text.split(" ")
DeviceEvent(token(0), token(1).toDouble)
})
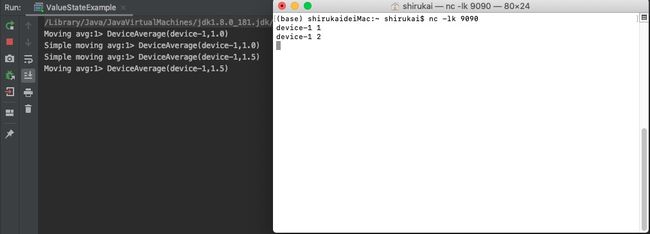
streamData.keyBy(_.id).map(new MoveAverage()).print("Moving avg")
env.execute("ManagedKeyedValueStateExample")
}
上述使用的自定义RichMap方法也可以简单的使用mapWithState实现
// simple
streamData.keyBy(_.id).mapWithState[DeviceAverage, AvgState] {
{
case (in: DeviceEvent, None) => (DeviceAverage(in.id, in.value), Some(AvgState(1, in.value)))
case (in: DeviceEvent, state: Some[AvgState]) =>
val newStateValue = AvgState(state.get.count + 1, state.get.sum + in.value)
(DeviceAverage(in.id, newStateValue.sum / newStateValue.count), Some(newStateValue))
}
}.print("Simple moving avg")
3.3.2 MapState
MapState存储类型为Map,我们可以使用Map特有的方法,比如put、get、keys() 、putAll等。
3.3.2.1 获取MapState
MapState的获取方式与ValueState一样,在RuntimeContext里通过getMapState获取,其中需要创建MapStateDescriptor实例,该实例同样有三种方式构建:typeClass、typeInfo、typeSerializer。
override def open(parameters: Configuration): Unit = {
state = getRuntimeContext.getMapState(
new MapStateDescriptor[Long, DeviceEvent](
"alarmMapState",
createTypeInformation[Long],
createTypeInformation[DeviceEvent]))
}
3.3.2.2 使用MapState实现开关量异常判别
需求:
假设设备信息包含id、timestamp、status,设备数据存在时序乱序的问题,需要实时判别设备状态是否异常,判别依据是,如果当前时间状态为0,上一条时间状态为1,即状态从1变为0了,我们则判断此设备变为异常。
思路:
由于考虑乱序问题,这里需要缓存过去一定量的数据,简单起见,我们保存10个数据,这10条数据以timstamp为key,status为value保存到MapState中。当时间戳为t的新数据到达之后,获取缓存数据的keys()转为TreeSet,如果当前数据的状态为0,则查找出keys中t的前一个值,如果存在前一个值,且前一个值状态为1,则转为异常事件发送给下游。如果当前数据的状态为1,则查找出keys中t的后一个值,如果存在后一个值,且后一个值状态为0,则转换下一个值为异常事件发送给下游。
实现:
定义输入事件格式:
/**
* 设备事件数据结构
*
* @param id 设备ID
* @param timestamp 事件时间
* @param status 设备状态
*/
case class DeviceEvent(id: String, timestamp: Long, status: Int)
定义输出事件格式
/**
* 设备告警数据结构
*
* @param id 设备ID
* @param timestamp 事件时间
* @param lastTimestamp 上一条记录时间
*/
case class DeviceAlarm(id: String, timestamp: Long, lastTimestamp: Long)
继承RichFlatMapFunction实现flatmap方法,实现开关量判别逻辑
class AlarmAnalyzer extends RichFlatMapFunction[DeviceEvent, DeviceAlarm] {
private var state: MapState[Long, DeviceEvent] = _
override def open(parameters: Configuration): Unit = {
state = getRuntimeContext.getMapState(
new MapStateDescriptor[Long, DeviceEvent](
"alarmMapState",
createTypeInformation[Long],
createTypeInformation[DeviceEvent]))
}
override def flatMap(value: DeviceEvent, out: Collector[DeviceAlarm]): Unit = {
// get all keys and transform to tree set.
val keys: util.TreeSet[Long] = new util.TreeSet[Long](state.keys().asInstanceOf[util.Collection[Long]])
// clear
clear(keys)
val currentKey = value.timestamp
keys.add(currentKey)
state.put(currentKey, value)
// 如果当前事件状态为0,查找是否包含上一个事件,如果上一个事件状态为1,则转换为异常事件将其发送给下游
if (value.status == 0) {
val lastKey = Some(keys.lower(currentKey))
if (lastKey.get!=null && state.get(lastKey.get).status == 1) {
out.collect(DeviceAlarm(value.id, currentKey, lastKey.get))
}
} else {
// 查找下一个事件,如果下一个事件为0,则转换为异常事件发送给下游
val nextKey = Some(keys.higher(currentKey))
if (nextKey.get!=null && state.get(nextKey.get).status == 0) {
out.collect(DeviceAlarm(value.id, nextKey.get, currentKey))
}
}
}
def clear(keys: util.TreeSet[Long], size: Int = 10): Unit = {
if (keys.size() == size) {
val firstKey = keys.first()
state.remove(firstKey)
keys.remove(keys.first())
}
}
}
从Socket中实时获取数据,转换为DeviceEvent类型,然后根据id进行分组,执行flatmap函数
def main(args: Array[String]): Unit = {
val params: ParameterTool = ParameterTool.fromArgs(args)
// set up execution environment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// make parameters available in the web interface
env.getConfig.setGlobalJobParameters(params)
// get input data
val streamText: DataStream[String] = env.socketTextStream(Option(params.get("hostname")).getOrElse("localhost"),
Option(params.get("port")).getOrElse("9090").toInt)
val streamData: DataStream[DeviceEvent] = streamText.map(text => {
val token = text.split(" ")
DeviceEvent(token(0), token(1).toLong, token(2).toInt)
})
streamData.keyBy(_.id).flatMap(new AlarmAnalyzer()).print()
env.execute("ManagedKeyedMapStateExample")
}
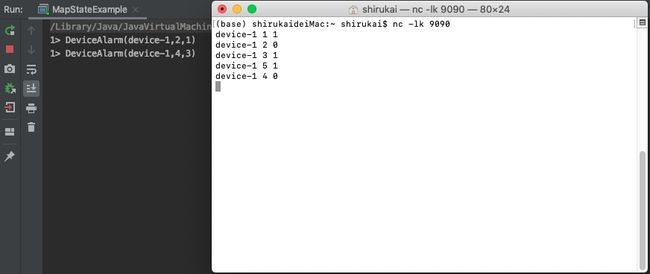
输入数据:
device-1 1 1
device-1 2 0
device-1 3 1
device-1 5 1
device-1 4 0
结果如下所示:
3.3.3 ListState
ListState顾名思义,存储结构为List,可以存储多个值。我们可以使用List的特有方法,如add,values()等
3.3.3.1 获取ListState
ListState方法异曲同工,在RuntimeContext里通过getListState方法获取,需要传入ListStateDescriptor实例,
ListStateDescriptor也有三种。
override def open(parameters: Configuration): Unit = {
state = getRuntimeContext
.getListState(new ListStateDescriptor[Double](
"varianceState",
createTypeInformation[Double]))
}
3.3.3.2 使用ListState实现累计方差计算
需求:
实时累计5条数据后做一次方差,然后输出
思路:
使用ListState存储历史数据,当数据达到5条之后,将其全部取出,计算方法,然后输出到下游。
实现:
输入数据格式
/**
* 设备事件
*
* @param id 设备ID
* @param value 设备值
*/
case class DeviceEvent(id: String, value: Double)
输出数据格式
/**
* 设备方差事件
*
* @param id 设备ID
* @param values 累计所有值
* @param variance 方差
*/
case class DeviceVariance(id: String, values: List[Double], variance: Double)
继承RichFlatMapFunction实现flatmap方法,完成计算方差逻辑。
class VarianceCalculator extends RichFlatMapFunction[DeviceEvent, DeviceVariance] {
private var state: ListState[Double] = _
private val countSize: Int = 5
override def open(parameters: Configuration): Unit = {
state = getRuntimeContext
.getListState(new ListStateDescriptor[Double](
"varianceState",
createTypeInformation[Double]))
}
override def flatMap(value: DeviceEvent, out: Collector[DeviceVariance]): Unit = {
import scala.collection.JavaConverters._
state.add(value.value)
val currentStateList: Iterable[Double] = state.get().asScala
if (currentStateList.size == countSize) {
out.collect(DeviceVariance(value.id, currentStateList.toList, variance(currentStateList)))
state.clear()
}
}
/**
* 计算方差
* @param values 数据列表
* @return 方差
*/
def variance(values: Iterable[Double]): Double = {
val avg = values.sum / values.size.toDouble
math.sqrt(values.map(x => math.pow(x - avg, 2)).sum / values.size)
}
}
从socket里获取数据,并转换为DeviceEvent,根据id分组之后,调用flatmap方法。
def main(args: Array[String]): Unit = {
val params: ParameterTool = ParameterTool.fromArgs(args)
// set up execution environment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// make parameters available in the web interface
env.getConfig.setGlobalJobParameters(params)
// get input data
val streamText: DataStream[String] = env.socketTextStream(Option(params.get("hostname")).getOrElse("localhost"),
Option(params.get("port")).getOrElse("9090").toInt)
val streamData: DataStream[DeviceEvent] = streamText.map(text => {
val token = text.split(" ")
DeviceEvent(token(0), token(1).toDouble)
})
streamData.keyBy(_.id).flatMap(new VarianceCalculator()).print()
env.execute("ManagedKeyedListStateExample")
}
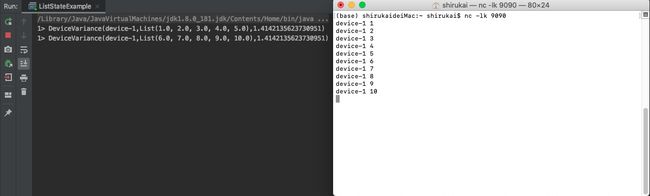
nc -lk 9090 输入数据:
device-1 1
device-1 2
device-1 3
device-1 4
device-1 5
device-1 6
device-1 7
device-1 8
device-1 9
device-1 10
结果:
3.3.3 ReducingState
ReductingState的存储类型也为单个值,需要用户实现reduce方法,当调用add()添加数据时,会指定自定义的reduce方法。
3.3.3.1 获取ReducingState
在RuntimeContext中通过getReducingState()方法获取,需要构建ReducingStateDescriptor实例,构造器不同于之前,除了name、typeinfo之前还需要传入自定义的reduce实例。
override def open(parameters: Configuration): Unit = {
// get state from runtime context
state = getRuntimeContext
.getReducingState(new ReducingStateDescriptor[Double](
"sumAccumulatorState",
new SumReducing(),
createTypeInformation[Double]))
}
3.3.3.2 使用ReducingState计算累加和
需求:
使用ReducingState实时计算数据总和
思路:
实现ReducFunction,将最近两个状态相加。
实现:
输入数据格式
/**
* 设备事件
*
* @param id 设备ID
* @param value 设备值
*/
case class DeviceEvent(id: String, value: Double)
输出数据格式
/**
* 设备累加和
*
* @param id 设备ID
* @param sum 设备值
*/
case class DeviceSum(id: String, sum: Double)
继承ReduceFunction实现reduce方法
class SumReducing extends ReduceFunction[Double] {
override def reduce(value1: Double, value2: Double): Double = value1 + value2
}
继承RichMapFunction实现map方法,完成累加和的逻辑
class SumAccumulator extends RichMapFunction[DeviceEvent, DeviceSum] {
private var state: ReducingState[Double] = _
override def open(parameters: Configuration): Unit = {
// get state from runtime context
state = getRuntimeContext
.getReducingState(new ReducingStateDescriptor[Double](
"sumAccumulatorState",
new SumReducing(),
createTypeInformation[Double]))
}
override def map(value: DeviceEvent): DeviceSum = {
state.add(value.value)
DeviceSum(value.id, state.get())
}
}
从socket中获取数据,并转换为DeviceEvent,然后根据id分组,调用自定义map方法。
def main(args: Array[String]): Unit = {
val params: ParameterTool = ParameterTool.fromArgs(args)
// set up execution environment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// make parameters available in the web interface
env.getConfig.setGlobalJobParameters(params)
// get input data
val streamText: DataStream[String] = env.socketTextStream(Option(params.get("hostname")).getOrElse("localhost"),
Option(params.get("port")).getOrElse("9090").toInt)
val streamData: DataStream[DeviceEvent] = streamText.map(text => {
val token = text.split(" ")
DeviceEvent(token(0), token(1).toDouble)
})
streamData.keyBy(_.id).map(new SumAccumulator()).print()
env.execute("ManagedKeyedReducingStateExample")
}
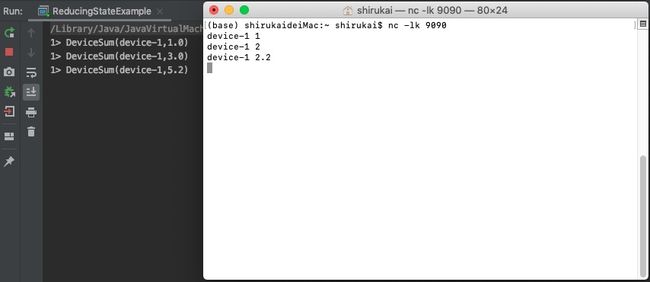
输入:
device-1 1
device-1 2
device-1 2.2
结果:
3.3.4 AggregatingState
AggregatingState与ReducingState类似,也是一种单个值的聚合状态。具有以下特点:
- 可以对输入值,中间聚合和结果类型使用不同类型,以支持各种聚合类型
- 支持分布式聚合:可以将不同的中间聚合合并在一起,以允许预聚合/最终聚合优化。
3.3.4.1 获取AggregatingState
AggregatingState也是通过RuntimeContext的getAggregatingStata方法获取,同样需要传入AggregatingStateDescriptor实例,构建AggregatingStateDescriptor实例时需要传入自定义的AggregatingFunction。
override def open(parameters: Configuration): Unit = {
state = getRuntimeContext.getAggregatingState(new AggregatingStateDescriptor[Long, AverageAccumulator, Double](
"rateAccumulatorState",
new AvgAggregating(),
createTypeInformation[AverageAccumulator]
))
}
3.3.4.2 使用AggregatingState实现移动平均
需求:
利用AggregatingState实时计算设备均值
思路:
思路与ValueState的均值计算相同
实现:
输入数据类型
/**
* 设备事件
*
* @param id 设备ID
* @param value 设备值
*/
case class DeviceEvent(id: String, value: Long)
输出数据类型
/**
* 设备均值
*
* @param id 设备ID
* @param avg 平均值
*/
case class DeviceAvg(id: String, avg: Double)
聚合累加器定义
case class AverageAccumulator(sum: Long, count: Int)
实现自定义的聚合方法
class AvgAggregating extends AggregateFunction[Long, AverageAccumulator, Double] {
override def createAccumulator(): AverageAccumulator = AverageAccumulator(0L, 0)
override def add(value: Long, accumulator: AverageAccumulator): AverageAccumulator =
AverageAccumulator(accumulator.sum + value, accumulator.count + 1)
override def getResult(accumulator: AverageAccumulator): Double = accumulator.sum.toDouble / accumulator.count.toDouble
override def merge(a: AverageAccumulator, b: AverageAccumulator): AverageAccumulator =
AverageAccumulator(a.sum + b.sum, a.count + b.count)
}
实现自定义的RichMapFunction
class MovingAvg extends RichMapFunction[DeviceEvent, DeviceAvg] {
private var state: AggregatingState[Long, Double] = _
override def open(parameters: Configuration): Unit = {
state = getRuntimeContext.getAggregatingState(new AggregatingStateDescriptor[Long, AverageAccumulator, Double](
"rateAccumulatorState",
new AvgAggregating(),
createTypeInformation[AverageAccumulator]
))
}
override def map(value: DeviceEvent): DeviceAvg = {
state.add(value.value)
DeviceAvg(value.id, state.get())
}
}
从Socket中获取数据,转换为DeviceEvent类型,然后根据id分组,调用自定义map方法。
def main(args: Array[String]): Unit = {
val params: ParameterTool = ParameterTool.fromArgs(args)
// set up execution environment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// make parameters available in the web interface
env.getConfig.setGlobalJobParameters(params)
// get input data
val streamText: DataStream[String] = env.socketTextStream(Option(params.get("hostname")).getOrElse("localhost"),
Option(params.get("port")).getOrElse("9090").toInt)
val streamData: DataStream[DeviceEvent] = streamText.map(text => {
val token = text.split(" ")
DeviceEvent(token(0), token(1).toLong)
})
streamData.keyBy(_.id).map(new MovingAvg()).print()
env.execute("ManagedKeyedAggregatingStateExample")
}
输入:
device-1 1
device-1 2
device-1 3
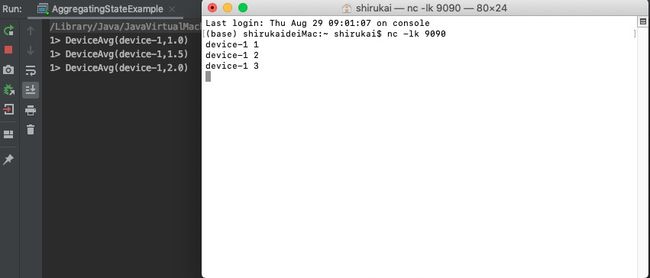
3.3.5 状态生命周期
在流处理的过程中,如果状态不断累积,很容易造成OOM,所以我们需要一种机制,来及时清理掉不需要的状态。对于Keyed State来说,自Flink 1.6之后引入了Time-To-Live (TTL)机制,能够友好的帮助我们自动清理掉过期状态。关于状态生命周期更多的内容可以参考:《如何应对飞速增长的状态?Flink State TTL 概述》。
3.3.5.1 StateTtlConfig
为了使用状态TTL,必须先构建StateTtlConfig配置对象。然后可以通过传递配置在任何状态描述符中启用TTL功能。
val ttlConfig: StateTtlConfig = StateTtlConfig
// 设置过期时间,10s后过期
.newBuilder(Time.seconds(10))
// ttl 刷新机制,默认在创建和写状态时刷新ssl
.setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite)
// 表示对已过期但还未被清理掉的状态如何处理
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
//过期对象的清理策略
.cleanupIncrementally(1, true)
.build
StateTtlConfig参数说明:
下面根据StateTtlConfig构造器参数,分别描述一下参数作用。
private StateTtlConfig(
UpdateType updateType,
StateVisibility stateVisibility,
TimeCharacteristic timeCharacteristic,
Time ttl,
CleanupStrategies cleanupStrategies) {
this.updateType = Preconditions.checkNotNull(updateType);
this.stateVisibility = Preconditions.checkNotNull(stateVisibility);
this.timeCharacteristic = Preconditions.checkNotNull(timeCharacteristic);
this.ttl = Preconditions.checkNotNull(ttl);
this.cleanupStrategies = cleanupStrategies;
Preconditions.checkArgument(ttl.toMilliseconds() > 0,
"TTL is expected to be positive");
}
- updateType: 表示状态时间戳的更新的时机,是一个 Enum 对象。如果设置为 Disabled,则表明不更新时间戳;如果设置为 OnCreateAndWrite,则表明当状态创建或每次写入时都会更新时间戳;如果设置为 OnReadAndWrite,则除了在状态创建和写入时更新时间戳外,读取也会更新状态的时间戳。
- stateVisibility: 表示对已过期但还未被清理掉的状态如何处理,也是 Enum 对象。如果设置为 ReturnExpiredIfNotCleanedUp,那么即使这个状态的时间戳表明它已经过期了,但是只要还未被真正清理掉,就会被返回给调用方;如果设置为 NeverReturnExpired,那么一旦这个状态过期了,那么永远不会被返回给调用方,只会返回空状态,避免了过期状态带来的干扰。
TimeCharacteristic以及 TtlTimeCharacteristic:表示 State TTL 功能所适用的时间模式,仍然是 Enum 对象。前者已经被标记为 Deprecated(废弃),推荐新代码采用新的 TtlTimeCharacteristic 参数。截止到 Flink 1.8,只支持 ProcessingTime 一种时间模式,对 EventTime 模式的 State TTL 支持还在开发中。- CleanupStrategies:表示过期对象的清理策略,目前来说有三种 Enum 值。当设置为 FULL_STATE_SCAN_SNAPSHOT 时,对应的是 EmptyCleanupStrategy 类,表示对过期状态不做主动清理,当执行完整快照(Snapshot / Checkpoint)时,会生成一个较小的状态文件,但本地状态并不会减小。唯有当作业重启并从上一个快照点恢复后,本地状态才会实际减小,因此可能仍然不能解决内存压力的问题。为了应对这个问题,Flink 还提供了增量清理的枚举值,分别是针对 Heap StateBackend 的 INCREMENTAL_CLEANUP(对应 IncrementalCleanupStrategy 类),以及对 RocksDB StateBackend 有效的 ROCKSDB_COMPACTION_FILTER(对应 RocksdbCompactFilterCleanupStrategy 类). 对于增量清理功能,Flink 可以被配置为每读取若干条记录就执行一次清理操作,而且可以指定每次要清理多少条失效记录;对于 RocksDB 的状态清理,则是通过 JNI 来调用 C++ 语言编写的 FlinkCompactionFilter 来实现,底层是通过 RocksDB 提供的后台 Compaction 操作来实现对失效状态过滤的。
3.3.5.2 开启TTL
想要在状态中启用TTL,需要在构建的StateDescriptor实例中,调用enableTimeToLive方法
val listStateDescriptor = new ListStateDescriptor("listState", createTypeInformation[Long])
listStateDescriptor.enableTimeToLive(ttlConfig)
state = getRuntimeContext.getListState(listStateDescriptor)
3.3.5.3 使用TTL例子
package com.hollysys.flink.streaming.state.managed.keyed
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor, StateTtlConfig}
import org.apache.flink.api.common.time.Time
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment, createTypeInformation}
/**
* Created by shirukai on 2019/8/27 4:23 下午
* 带有生命周期的状态,我们可以给状态设置过期时间
* https://cloud.tencent.com/developer/article/1452844
*/
object TimeToLiveStateExample {
val ttlConfig: StateTtlConfig = StateTtlConfig
// 设置过期时间,10s后过期
.newBuilder(Time.seconds(10))
// ttl 刷新机制,默认在创建和写状态时刷新ttl
// 枚举类型。有三种机制:Disabled、OnReadAndWrite、OnReadAndWrite
.setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite)
// 表示对已过期但还未被清理掉的状态如何处理
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
//过期对象的清理策略
.cleanupIncrementally(1, true)
.build
case class DeviceEvent(id: String, value: Long)
case class DeviceList(id: String, list: List[Long])
class ListCollector extends RichMapFunction[DeviceEvent, DeviceList] {
private var state: ListState[Long] = _
override def open(parameters: Configuration): Unit = {
val listStateDescriptor = new ListStateDescriptor("listState", createTypeInformation[Long])
listStateDescriptor.enableTimeToLive(ttlConfig)
state = getRuntimeContext.getListState(listStateDescriptor)
}
override def map(value: DeviceEvent): DeviceList = {
import scala.collection.JavaConverters._
state.add(value.value)
DeviceList(value.id, state.get().asScala.toList)
}
}
def main(args: Array[String]): Unit = {
val params: ParameterTool = ParameterTool.fromArgs(args)
// set up execution environment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// make parameters available in the web interface
env.getConfig.setGlobalJobParameters(params)
// get input data
val streamText: DataStream[String] = env.socketTextStream(Option(params.get("hostname")).getOrElse("localhost"),
Option(params.get("port")).getOrElse("9090").toInt)
val streamData: DataStream[DeviceEvent] = streamText.map(text => {
val token = text.split(" ")
DeviceEvent(token(0), token(1).toLong)
})
streamData.keyBy(_.id).map(new ListCollector()).print()
env.execute("TimeToLiveStateExample")
}
}
3.4 使用Managed Operator State
上面我们介绍了如何使用Managed Keyed State,通过RuntimeContext的getXXXState方法可以获取到不同的KeyedState,这必须要在KeyedDataStream中使用,如果在DataStream中使用的话会报如下异常:
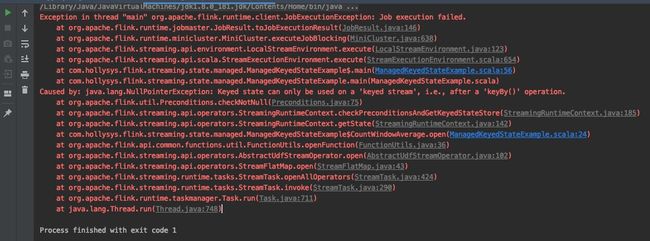
那么在普通的Operator中我们如何使用状态呢?官方提供了两种Operator State使用方法,继承CheckpointedFunction和ListCheckpointed
3.4.1 继承CheckpointedFunction实现有状态Operator
package com.hollysys.flink.streaming.state.managed.operator
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor}
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.runtime.state.{FunctionInitializationContext, FunctionSnapshotContext}
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction
import org.apache.flink.streaming.api.functions.sink.SinkFunction
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.scala._
import scala.collection.mutable.ListBuffer
/**
* Created by shirukai on 2019/8/29 10:06 上午
* 继承CheckpointedFunction获取状态
* 实现有状态的Sink
*/
object StateByCheckpointedExample {
case class DeviceEvent(id: String, value: Double)
class BufferSink(threshold: Int = 2) extends SinkFunction[DeviceEvent] with CheckpointedFunction {
@transient
private var checkpointedState: ListState[DeviceEvent] = _
private val bufferedElements = ListBuffer[DeviceEvent]()
override def invoke(value: DeviceEvent, context: SinkFunction.Context[_]): Unit = {
bufferedElements += value
println(bufferedElements)
if (bufferedElements.size == threshold) {
for (element <- bufferedElements) {
// send it to the sink
println(s"BufferSink: $element")
}
bufferedElements.clear()
}
}
// 当检查点被请求快照时调用,用以保存当前状态
override def snapshotState(context: FunctionSnapshotContext): Unit = {
checkpointedState.clear()
for (element <- bufferedElements) {
checkpointedState.add(element)
}
}
// 当并行实例被创建时调用,用以初始化状态
override def initializeState(context: FunctionInitializationContext): Unit = {
val descriptor = new ListStateDescriptor[DeviceEvent](
"buffered-elements",
createTypeInformation[DeviceEvent])
// 通过getOperatorStateStore方法获取operator状态
// getListState
// getUnionListState 获取全量状态,会合并所有并行实例状态
checkpointedState = context.getOperatorStateStore.getListState(descriptor)
import scala.collection.JavaConverters._
// 如果从先前的快照恢复状态,则返回true
if (context.isRestored) {
// 将恢复后的状态刷到ListBuffer里
for (element <- checkpointedState.get().asScala) {
bufferedElements += element
}
}
}
}
def main(args: Array[String]): Unit = {
val params: ParameterTool = ParameterTool.fromArgs(args)
// set up execution environment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.enableCheckpointing(1000)
// make parameters available in the web interface
env.getConfig.setGlobalJobParameters(params)
// get input data
val streamText: DataStream[String] = env.socketTextStream(Option(params.get("hostname")).getOrElse("localhost"),
Option(params.get("port")).getOrElse("9090").toInt)
val streamData: DataStream[DeviceEvent] = streamText.map(text => {
val token = text.split(" ")
DeviceEvent(token(0), token(1).toDouble)
})
streamData.addSink(new BufferSink(2))
env.execute("StateByCheckpointedExample")
}
}
3.4.2 继承ListCheckpointed实现有状态Operator
package com.hollysys.flink.streaming.state.managed.operator
import java.util
import java.util.Collections
import java.util.concurrent.TimeUnit
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.runtime.state.StateBackend
import org.apache.flink.runtime.state.filesystem.FsStateBackend
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.checkpoint.ListCheckpointed
import org.apache.flink.streaming.api.environment.CheckpointConfig
import org.apache.flink.streaming.api.functions.source.{RichParallelSourceFunction, SourceFunction}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
/**
* Created by shirukai on 2019/8/29 1:48 下午
* 继承ListCheckpointedExample获取状态
* 实现有状态的Source
*/
object StateByListCheckpointedExample {
case class DeviceEvent(id: String, value: Long)
case class Offset(value: Long) extends Serializable
class CounterSource extends RichParallelSourceFunction[DeviceEvent] with ListCheckpointed[Offset] {
@volatile
private var isRunning = true
private var offset = 0L
override def run(ctx: SourceFunction.SourceContext[DeviceEvent]): Unit = {
val lock = ctx.getCheckpointLock
while (isRunning) {
// output and state update are atomic
lock.synchronized({
ctx.collect(DeviceEvent(s"Device-$offset", offset))
offset += 1
TimeUnit.SECONDS.sleep(1)
})
}
}
override def cancel(): Unit = isRunning = false
// 恢复到之前检查点的状态
override def restoreState(state: util.List[Offset]): Unit = {
if (!state.isEmpty) offset = state.get(0).value
}
// 返回当前状态用以保存到快照中
override def snapshotState(checkpointId: Long, timestamp: Long): util.List[Offset] =
Collections.singletonList(Offset(offset))
}
def main(args: Array[String]): Unit = {
val params: ParameterTool = ParameterTool.fromArgs(args)
// set up execution environment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.enableCheckpointing(1000)
.setStateBackend(new FsStateBackend("file:///Users/shirukai/hollysys/repository/learn-demo-flink/data/checkpoint").asInstanceOf[StateBackend])
env.getCheckpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
// make parameters available in the web interface
env.getConfig.setGlobalJobParameters(params)
env.addSource(new CounterSource()).setParallelism(1).print()
env.execute("StateByListCheckpointedExample")
}
}
3.5 广播状态模式
以下关于“什么是广播状态”内容引用于文章《Apache Flink 中广播状态的实用指南》
广播状态可以用于通过一个特定的方式来组合并共同处理两个事件流。第一个流的事件被广播到另一个 operator 的所有并发实例,这些事件将被保存为状态。另一个流的事件不会被广播,而是发送给同一个 operator 的各个实例,并与广播流的事件一起处理。广播状态非常适合两个流中一个吞吐大,一个吞吐小,或者需要动态修改处理逻辑的情况。
package com.hollysys.flink.streaming.state.broadcast
import org.apache.flink.api.common.state.MapStateDescriptor
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.functions.co.KeyedBroadcastProcessFunction
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
import scala.collection.mutable
/**
* Created by shirukai on 2019/8/29 4:18 下午
* 广播状态示例
*/
object BroadcastStateExample {
val ruleStateDescriptor = new MapStateDescriptor("rule-state",
createTypeInformation[String],
createTypeInformation[mutable.Map[String, RuleEvent]])
case class DeviceEvent(id: String, value: Double)
case class RuleEvent(id: String, ruleType: String, bind: String)
case class DeviceWithRule(device: DeviceEvent, rule: RuleEvent)
class DeviceWithRuleProcess extends KeyedBroadcastProcessFunction[String, DeviceEvent, RuleEvent, DeviceWithRule] {
override def processElement(value: DeviceEvent, ctx: KeyedBroadcastProcessFunction[String, DeviceEvent, RuleEvent,
DeviceWithRule]#ReadOnlyContext, out: Collector[DeviceWithRule]): Unit = {
val ruleState = ctx.getBroadcastState(ruleStateDescriptor)
// 如果数据包含规则
if (ruleState.contains(value.id)) {
val rules = ruleState.get(value.id)
rules.foreach(rule => {
out.collect(DeviceWithRule(value,rule._2))
})
}
}
override def processBroadcastElement(value: RuleEvent, ctx: KeyedBroadcastProcessFunction[String, DeviceEvent,
RuleEvent, DeviceWithRule]#Context, out: Collector[DeviceWithRule]): Unit = {
val ruleState = ctx.getBroadcastState(ruleStateDescriptor)
val bindKey = value.bind
if (ruleState.contains(bindKey)) {
val bindRules = ruleState.get(bindKey)
bindRules.put(value.id, value)
} else {
ruleState.put(bindKey, mutable.Map(value.id -> value))
}
}
}
def main(args: Array[String]): Unit = {
val params: ParameterTool = ParameterTool.fromArgs(args)
// set up execution environment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// make parameters available in the web interface
env.getConfig.setGlobalJobParameters(params)
val deviceText: DataStream[String] = env.socketTextStream(
Option(params.get("device-hostname")).getOrElse("localhost"),
Option(params.get("device-port")).getOrElse("9090").toInt)
val ruleText: DataStream[String] = env.socketTextStream(
Option(params.get("rule-hostname")).getOrElse("localhost"),
Option(params.get("rule-port")).getOrElse("9091").toInt)
val deviceEvents = deviceText.map(x => {
val token = x.split(" ")
DeviceEvent(token(0), token(1).toDouble)
})
val ruleEvents = ruleText.map(x => {
val token = x.split(" ")
RuleEvent(token(0), token(1), token(2))
})
val ruleBroadcastStream = ruleEvents.broadcast(ruleStateDescriptor)
deviceEvents.keyBy(_.id).connect(ruleBroadcastStream).process(new DeviceWithRuleProcess()).print()
env.execute("BroadcastStateExample")
}
}