【理解Flink必备(二)】Flink核心概念理解-- Distributed Runtime Environment
笔者根据官方文档原文进行翻译,水平有限,如有理解偏差,请及时联系笔者更正。
Flink Version:1.8.0
文章目录
- Tasks and Operator Chains 任务和操作链
- Job Managers, Task Managers, Clients
- Task Slots and Resources
- State Backends
- Savepoints
Tasks and Operator Chains 任务和操作链
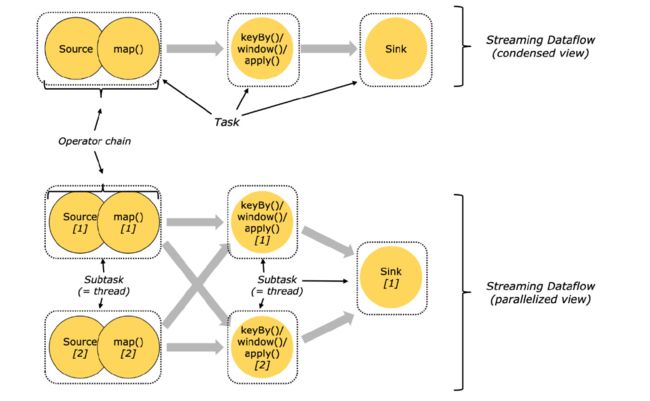
For distributed execution, Flink chains operator subtasks together into tasks. Each task is executed by one thread. Chaining operators together into tasks is a useful optimization: it reduces the overhead of thread-to-thread handover and buffering, and increases overall throughput while decreasing latency. The chaining behavior can be configured; see the chaining docs for details.
在分布式执行环境下,子任务被Flink链在一起被当作任务,每个任务由一个线程执行,将操作链在一起是一种非常有用的优化行为,它可以减少线程间切换的缓冲和开销,增加吞吐量,降低延迟。并且这个操作链是可配置的,详见: chaining docs 。
The sample dataflow in the figure below is executed with five subtasks, and hence with five parallel threads.
下图中的数据流由5个子任务执行,因此有5个并行的线程。上半部分是压缩(串行)版,下半部分是并行运行版
Job Managers, Task Managers, Clients
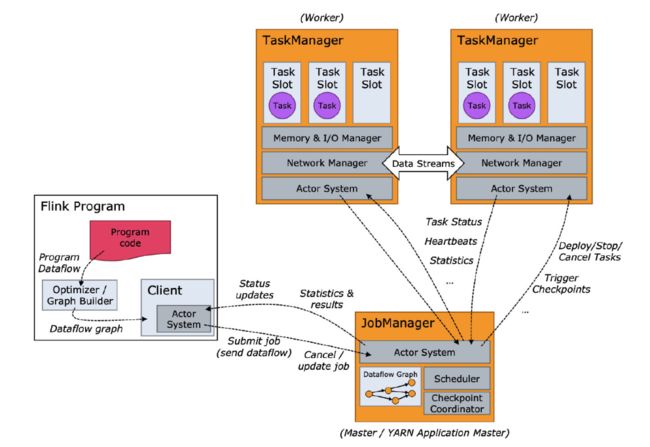
The Flink runtime consists of two types of processes:
Flink的运行由2部分组成:
-
The JobManagers (also called masters) coordinate the distributed execution. They schedule tasks, coordinate checkpoints, coordinate recovery on failures, etc.
There is always at least one Job Manager. A high-availability setup will have multiple JobManagers, one of which one is always the leader, and the others are standby.
JobManagers(也被称之为master),它用来协调分布式的执行,它可以调度任务,协调checkpoints,协调故障恢复等。
JobManager至少存在1个,如果你想高可用,那么你需要一个JobManager为leader,其它多个为standby状态。
-
The TaskManagers (also called workers) execute the tasks (or more specifically, the subtasks) of a dataflow, and buffer and exchange the data streams.
There must always be at least one TaskManager.
TaskManagers(理所当然,称它为workers),它用于执行数据流的任务(更具体的说,是执行子任务),并且缓冲和交换数据流
因此,一个Flink的runtime 环境,至少存在一个TaskManager
The JobManagers and TaskManagers can be started in various ways: directly on the machines as a standalone cluster, in containers, or managed by resource frameworks like YARN or Mesos. TaskManagers connect to JobManagers, announcing themselves as available, and are assigned work.
JobManagers 和 TaskManagers 可有通过很多种方式启动,譬如:
standalone cluster
容器
YARN 或者 Mesos
TaskManagers 连接到 JobManagers,告诉JobManagers 它们是可用的,然后被分配任务。
The client is not part of the runtime and program execution, but is used to prepare and send a dataflow to the JobManager. After that, the client can disconnect, or stay connected to receive progress reports. The client runs either as part of the Java/Scala program that triggers the execution, or in the command line process ./bin/flink run ....
client 并不是运行时和程序执行时的一部分,但是被用于准备和发送数据流到JobManager,完成自己的使命后,client 将断开连接 ,或者保持链接用来接收进度信息。client 是 java/scala 程序中触发执行的部分,或者是命令行程序:./bin/flink run …`.
Task Slots and Resources
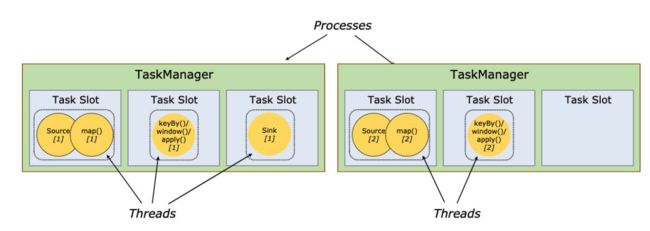
Each worker (TaskManager) is a JVM process, and may execute one or more subtasks in separate threads. To control how many tasks a worker accepts, a worker has so called task slots (at least one).
每个worker是一个JVM进程,它将执行一个或多个子任务在单独的线程中,为了知道,woker接收任务的个数,Flink用task slots来标识(每个worker至少有一个task slot)
Each task slot represents a fixed subset of resources of the TaskManager. A TaskManager with three slots, for example, will dedicate 1/3 of its managed memory to each slot. Slotting the resources means that a subtask will not compete with subtasks from other jobs for managed memory, but instead has a certain amount of reserved managed memory. Note that no CPU isolation happens here; currently slots only separate the managed memory of tasks.
每个task slot 代表了TaskManager 的一个固定子资源,例如:一个TaskManager 有3个 slots, 这3个slots将平分 TaskManager 控制的内存。切分资源,意味着不会与其它子任务去竞争内存,这样可以确保每个slot的内存足够。需要注意的是,这里没有CPU资源,目前的slots 只能去隔离task的内存。
By adjusting the number of task slots, users can define how subtasks are isolated from each other. Having one slot per TaskManager means each task group runs in a separate JVM (which can be started in a separate container, for example). Having multiple slots means more subtasks share the same JVM. Tasks in the same JVM share TCP connections (via multiplexing) and heartbeat messages. They may also share data sets and data structures, thus reducing the per-task overhead.
通过调整 slots 的数量,用户可以定义:有多少个子任务可以相互隔离;如果TaskManager 只有一个slot,意味着每个任务组将在一个JVM(也可以在一个容器中)中运行;如果TaskManager有多个slots,那么子任务将共享一个JVM,在当前JVM中,共享TCP链接(多路复用),和心跳信息。当然,也共享数据集和数据结构,以达到减少开销的目的。
如下图:启动了2个JVM进程(抛开容器的启动方式),左边3个线程,右边2个线程。
By default, Flink allows subtasks to share slots even if they are subtasks of different tasks, so long as they are from the same job. The result is that one slot may hold an entire pipeline of the job. Allowing this slot sharing has two main benefits:
默认情况下,只要子任务是来自于同一个job,Flink是允许子任务(也可以是不同任务的子任务)来共享slots,这样一个slot就可以hold住整个job的流程。
共享slot有以下2个优点:
-
A Flink cluster needs exactly as many task slots as the highest parallelism used in the job. No need to calculate how many tasks (with varying parallelism) a program contains in total.
-
It is easier to get better resource utilization. Without slot sharing, the non-intensive source/map() subtasks would block as many resources as the resource intensive window subtasks. With slot sharing, increasing the base parallelism in our example from two to six yields full utilization of the slotted resources, while making sure that the heavy subtasks are fairly distributed among the TaskManagers.
-
在一个Flink Cluster上,任务的并行度和 task slots 的数量是精确对应的,所以,没有必要去计算一共有多少个task.
-
更容易的去获取资源的利用率,如果没有slot 共享机制:
- 非密集型的 source/map() 子任务操作将会block (占用) 和密集窗口子任务 相同的资源
如例:
slot 共享机制存在的情况下,将平行度从2 -> 6时,那些负担较重的子任务,可以充分利用已经分配好的 slot 资源,也可以将TaskManager资源更公正的分配。

State Backends
The exact data structures in which the key/values indexes are stored depends on the chosen state backend. One state backend stores data in an in-memory hash map, another state backend uses RocksDB as the key/value store. In addition to defining the data structure that holds the state, the state backends also implement the logic to take a point-in-time snapshot of the key/value state and store that snapshot as part of a checkpoint.
key/values 的索引存储取决于所选的 state backend,state backend 的存储方式有2种,1种是在内存中以 hash map 存储,另一种是RocksDB(物理存储,但效果媲美内存),除了定义状态保存的数据结构,the state backends 也支持 implement key/value 键值状态的时间点快照,并将该快照,作为checkpoint的一部分。

Savepoints
Programs written in the Data Stream API can resume execution from a savepoint. Savepoints allow both updating your programs and your Flink cluster without losing any state.
用 Data Stream API 编写的程序可以从保存点恢复执行,在不丢失任何状态的情况下,保存点允许更新程序和Flink集群。
Savepoints are manually triggered checkpoints, which take a snapshot of the program and write it out to a state backend. They rely on the regular checkpointing mechanism for this. During execution programs are periodically snapshotted on the worker nodes and produce checkpoints. For recovery only the last completed checkpoint is needed and older checkpoints can be safely discarded as soon as a new one is completed.
savepoint 是 手动触发的 checkpoints,它创建一个 snapshot 并且写入 state backend,它依赖常规的检查点机制,程序运行期间,程序会定义的创建快照在worker上,并且生成checkpoint,如果想恢复的话,只需要找到最近的checkpoint,如果新checkPoint创建完成,那么旧的可安全删除。
Savepoints are similar to these periodic checkpoints except that they are triggered by the user and don’t automatically expire when newer checkpoints are completed. Savepoints can be created from the command line or when cancelling a job via the REST API.
savepoint和定期的checkpoint 是类似的,区别在于,它们是由用户生成,且当新的checkpoint生成时,不会自动过期。savepoints 可以通过命令行创建,也可以用REST API取消job时创建。