【可视化】数据仓库与数据挖掘大作业
代码下载链接:http://download.csdn.net/detail/jsgaobiao/9534463
Ø 【概述】
本次大作业我们选取了第一个题目:基于统计方法的数据分布的图形显示。我们从各省市统计局公布的数据中搜集了包括人均GDP(元)、人口密度(人/平方公里)、PM2.5年平均浓度(微克/立方米)、年旅游收入(亿元)的数据并且做了统计和可视化。
我们认为这些数据可以一定程度上反映出一个省或直辖市的经济(人均GDP)、社会(人口密度)、环境(PM2.5年平均浓度)和文化产业(旅游收入)的发展水平。我们所呈现出来的两张图表也可以让用户直观的从地理位置和对比中,了解省市间发展的差异性以及每个省市自身的发展结构,并且能够轻松地寻找到用户感兴趣的区域。
下面我们将分步骤详细地讲述我们完成作业的流程以及其中涉及到的算法与技术,也希望借这个报告记录下我们学习和使用这些知识技能的过程。
Ø 【数据的选取】
本次作业采用的数据来源于各省市统计局的公报,包含了各省市、自治区、特别行政区的人均GDP(元)、人口密度(人/平方公里)、PM2.5年平均浓度(微克/立方米)和年旅游收入(亿元)。其中,澳门特别行政区和台湾的PM2.5年平均浓度、年旅游收入,以及香港特别行政区的年旅游收入缺少官方数据,因此我们采用了新闻报道中的统计数据用于研究。
为了尝试不同组织方式的数据处理,我们使用了tsv和json两种组织形式的数据文件用于两种不同的可视化方案。其中tsv类型的数据文件中,所有的数据条目按照group(数据类型)、id(省份名称)和value(数值)进行组织,而json文件中,每个数据对象表示了一个省份实体,当中包括id(省份名称)以及GDP、人口密度等不同属性的数据。
Ø 【数据可视化】
一、 环境与技术
本次作业的可视化采用了网页端的实现方式,它具有跨平台和轻便的特点。下面介绍了我们整个项目中涉及到的开发技术:
l 搭建HTTP本地服务器:我们希望用户通过浏览器打开HTML文件直接查看可视化的结果,不过这样有一些局限性。一旦我们需要从其他文件中加载数据,由于浏览器内建的安全机制,这样的行为会受到限制。为了绕开这个安全机制,我们使用Python搭建一个本地的HTTP服务器,用该服务器来维护HTML页面和数据文件,而不是直接从文件系统中加载。
本机采用了Python3.4.2的环境,只需要运行“python –m http.server”命令即可启动一个HTTP服务器,默认端口是8000.如果你采用了较老版本的Python,可以尝试命令“python–m SimpleHTTPServer 8000”即可。
l 网页前端:HTML +CSS,这两样“利器”的搭配,可以让我们方便的构建出网站和各种可视化元素的样式。
l 数据可视化:D3.js,它是一个JavaScript库,可以通过数据来操作文档。D3可以通过使用HTML、SVG和CSS把数据鲜活形象地展现出来。D3严格遵循Web标准,因而可以让你的程序轻松兼容现代主流浏览器并避免对特定框架的依赖。同时,它提供了强大的可视化组件,可以让使用者以数据驱动的方式去操作DOM。
二、 地图的可视化

我们的第一部分可视化使用了地图的形式,通过将各行政区域绘制深浅不同的颜色,表示各项数据的多少。通过选择地图下面的选项可以切换显示不同的数据分布。
从这样的图中我们可以直观的看出人均GDP和地理位置分布的关系,东部沿海省份的经济发展水平明显好于中西部地区。重庆作为一个直辖市,在中部地区的确也属于发展比较好的。另外,内蒙古在这张地图上显得比较“独树一帜”,不过结合人口密度分布图来看就可以发现,内蒙古因为人口密度特别低,所以人均GDP才会比较高。
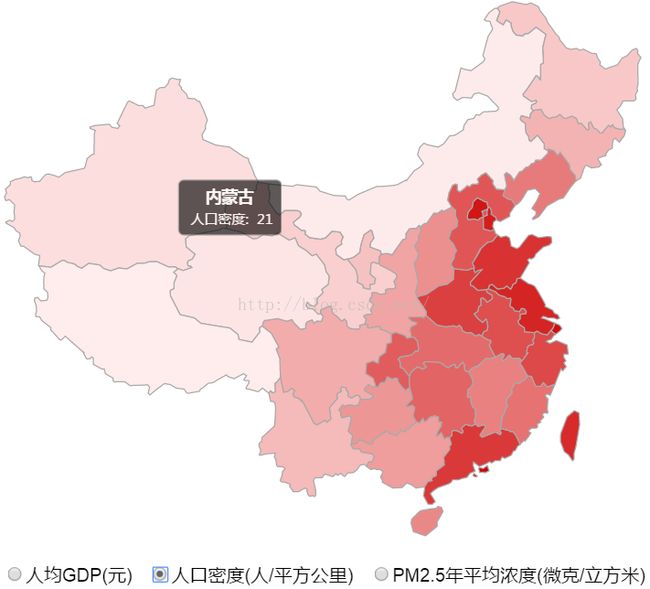
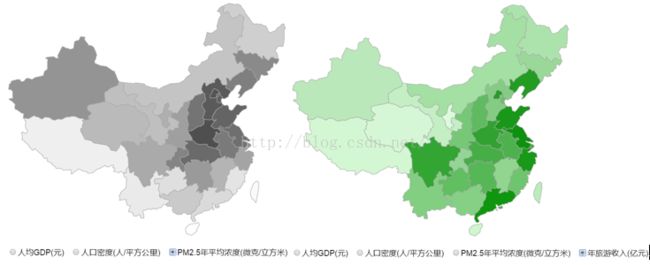
再通过PM2.5的浓度图和旅游收入的分布图,我们还可以发现,空气污染较为严重的地区主要分布在以京津冀为核心的华北平原,比较符合我们日常生活中的直观感受,而新疆地区的PM2.5浓度也处于一个较高的水平,可能是因为土壤沙漠化的影响。
下面介绍具体的算法:
首先介绍一下地图绘制的方式:我们采用了SVG(可缩放矢量图形),它是W3C颁布的一种成熟标准,用于规范网络和移动平台上的交互图形。它能够很好的与CSS、JavaScript等浏览器技术结合起来。SVG的图像基于矢量而非像素,因此具有良好的伸缩性,使得它在任意尺寸下都不会丢失精度。
为了绘制中国地图,我们采用了D3的线条生成器,事实上,它是使用svg:path元素实现的。我们在china.js中记录下了所有省份区域边界的顶点坐标,并通过创建的path元素对线条围出的区域进行相应颜色的填充,同时设置了与鼠标事件的交互。当用户将鼠标移动到某个省份区域之上时,会渐变地弹出提示框,标明了省份名称和具体的数据信息。

为了使得数值的区域显示不同深浅的颜色,我们先将数据进行了排序,然后根据排序的名字对colormap中的颜色进行插值。由于篇幅限制,此处就不附上代码了。具体可以参考index.html中的注释。
三、 条形图可视化
为了让数据的呈现更加多样化,并让用户可以方便地比较地区间的差异性,我们除了第一部分的地图可视化之外,还做了条形图的可视化。这一部分呈现了按照各个领域数据排名为标准进行度量的条形图。
为了方便比较,我们设置了Multiples和Stacked两种显示方式,分别可以方便用户比较单项指标之间的差异和整体指标的差异程度。
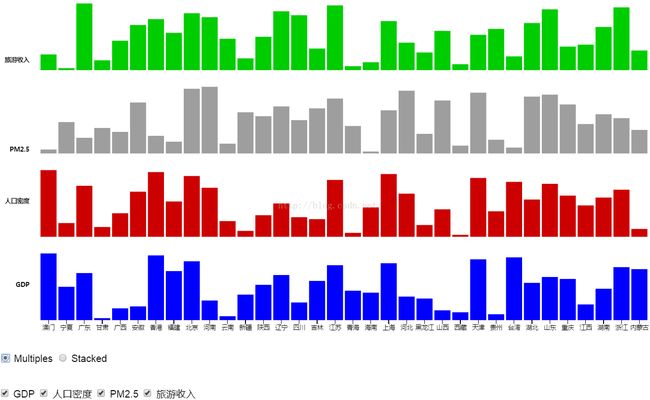
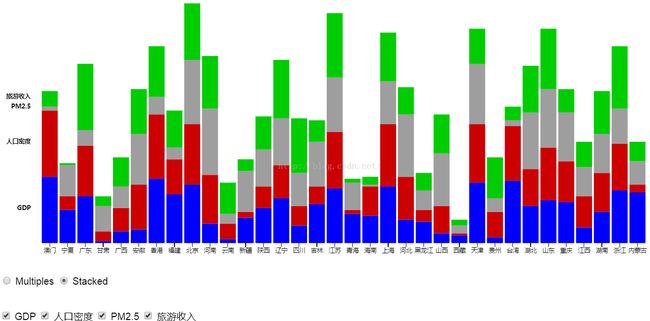
可视化界面的下方有两排选择按钮,其中第一排选择按钮可以选择可视化的方式是Multiples(上图)或者Stacked(下图)。第二排选择按钮则可以选择显示哪些数值的项目。
条形图的可视化中,每个条形的高度与这个省份某个数值的排名成正比。我们选择通过排名而不是具体的数值(如GDP)进行可视化是因为不同属性间的数值差异可能很大。例如GDP的数值几乎都在万或者十万的量级,而PM2.5的年平均浓度都在100以内。为了在可视化中较好的体现出每个省份各种属性所占的“比重”,以及避免某些省份在某个属性的数值过高而导致其他省份的差异难以呈现,所以我们选择了按照各个属性的排名进行可视化。
从这样的图中可以看出一个地区包括了经济(人均GDP)、社会(人口密度)、环境(PM2.5年平均浓度)和文化产业(旅游收入)的整体社会发展水平。其中,北京、江苏、上海三地位列前三,而西藏、甘肃两地的发展则比较滞后。
除此以外,通过比较各个颜色在一个省份条形图中所占的比例,也可以看出一些特征。例如,条形图高度接近的广东和辽宁,他们各项指数比例差异主要体现在广东的旅游收入(绿色)较高,人口较多(红色),而辽宁的PM2.5年平均浓度(灰色)占了更大的比例。这一现象体现出了辽宁是以高污染的重工业为主的发展模式,而广东的发展模式则更加的“环境友好”。
Ø 【结语】
通过上述的说明以及截图,我们可以发现这些数据都被直观地呈现出来。到目前为止,我们已经生活在大数据的包围之中,然而大量的数据难以被人们所理解,想要迅速地提取数据中的重要信息、洞悉数据中所蕴含的趋势,数据可视化必不可少。
这次的作业是我们第一次对数据可视化进行较为系统的学习和使用,让我们习得了很多新的技能,也让我们更清楚的认识到数据可视化的强大之处。当我们所写的代码将大量的数据绘制成漂亮的图像时,我们觉得数据可视化不仅仅是一门科学,也是一门艺术。