siamfc-pytorch代码讲解(二):train&siamfc
siamfc-pytorch代码讲解(二):train&siamfc
- 一、train.py
- 二、siamfc.py
- 2.1 SiamFCTransforms
- 2.2 Pair
- 2.3 train_step
- 上下篇
这是第二篇的siamfc-pytorch代码讲解,主要顺着程序流讲解代码,上一篇讲解在这里:
siamfc-pytorch代码讲解(一):backbone&head
show me code !!
一、train.py
因为作者使用了GOT-10k这个工具箱,train.py代码非常少,就下面几行:
from __future__ import absolute_import
import os
from got10k.datasets import *
from siamfc import TrackerSiamFC
if __name__ == '__main__':
root_dir = os.path.expanduser('~/data/GOT-10k')
seqs = GOT10k(root_dir, subset='train', return_meta=True)
tracker = TrackerSiamFC()
tracker.train_over(seqs)
首先我们就需要按照GOT-10k download界面去下载好数据集,并且按照这样的文件结构放好(因为现在用不到验证集和测试集,可以先不用下,训练集也只要先下载1个split,所以就需要把list.txt中只保留前500项,因为GOT-10k_Train_000001里面有500个squences):
|-- GOT-10k/
|-- train/
| |-- GOT-10k_Train_000001/
| | ......
| |-- GOT-10k_Train_000500/
| |-- list.txt
这里可以打印一下seps到底是什么,因为他是train_over的入参:
print(seqs)
# 二、siamfc.py
顺着代码流看到调用了siamfc.py中类TrackerSiamFC的train_over方法,在这个类里面就是进行数据增强,构造和加载,然后进行训练,这里主要有三个地方需要深入思考一下:
2.1 SiamFCTransforms
SiamFCTransforms是transforms.py里面的一个类,主要是对输入的groung truth的z, x, bbox_z, bbox_x进行一系列变换,构成孪生网络的输入,这其中就包括了:
- RandomStretch:主要是随机的resize图片的大小,其中要注意cv2.resize()的一点用法,可以参考我的这篇博客:cv2.resize()的一点小坑
- CenterCrop:从img中间抠一块(size, size)大小的patch,如果不够大,以图片均值进行pad之后再crop
- RandomCrop:用法类似CenterCrop,只不过从随机的位置抠,没有pad的考虑
- Compose:就是把一系列的transforms串起来
- ToTensor: 就是字面意思,把np.ndarray转化成torch tensor类型
类初始化里面针对self.transforms_z和self.transforms_x数据增强方法中具体参数的设置可以参考 issue#21,作者提到在train phase和test phase embedding size不一样没太大的影响,而且255-16可以模拟测试阶段目标的移动(个人感觉这里没有完全就按照论文上来,但也不用太在意,自己可以试着改回来看哪一个效果好)。
下面具体讲里面的_crop函数:
def _crop(self, img, box, out_size):
# convert box to 0-indexed and center based [y, x, h, w]
box = np.array([
box[1] - 1 + (box[3] - 1) / 2,
box[0] - 1 + (box[2] - 1) / 2,
box[3], box[2]], dtype=np.float32)
center, target_sz = box[:2], box[2:]
context = self.context * np.sum(target_sz)
size = np.sqrt(np.prod(target_sz + context))
size *= out_size / self.exemplar_sz
avg_color = np.mean(img, axis=(0, 1), dtype=float)
interp = np.random.choice([
cv2.INTER_LINEAR,
cv2.INTER_CUBIC,
cv2.INTER_AREA,
cv2.INTER_NEAREST,
cv2.INTER_LANCZOS4])
patch = ops.crop_and_resize(
img, center, size, out_size,
border_value=avg_color, interp=interp)
return patch
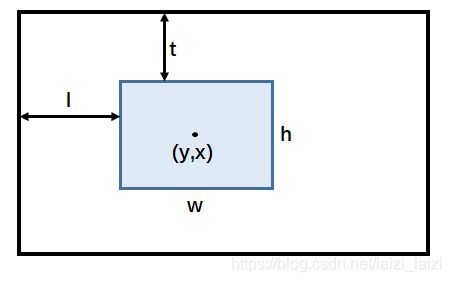
因为GOT-10k里面对于目标的bbox是以ltwh(即left, top, weight, height)形式给出的,上述代码一开始就先把输入的box变成center based,坐标形式变为[y, x, h, w],结合下面这幅图就非常好理解: y = t + h 2 y=t+\frac{h}{2} y=t+2h, x = l + w 2 x=l+\frac{w}{2} x=l+2w
crop_and_resize:
def crop_and_resize(img, center, size, out_size,
border_type=cv2.BORDER_CONSTANT,
border_value=(0, 0, 0),
interp=cv2.INTER_LINEAR):
# convert box to corners (0-indexed)
size = round(size) # the size of square crop
corners = np.concatenate((
np.round(center - (size - 1) / 2),
np.round(center - (size - 1) / 2) + size))
corners = np.round(corners).astype(int)
# pad image if necessary
pads = np.concatenate((
-corners[:2], corners[2:] - img.shape[:2]))
npad = max(0, int(pads.max()))
if npad > 0:
img = cv2.copyMakeBorder(
img, npad, npad, npad, npad,
border_type, value=border_value)
# crop image patch
corners = (corners + npad).astype(int)
patch = img[corners[0]:corners[2], corners[1]:corners[3]]
# resize to out_size
patch = cv2.resize(patch, (out_size, out_size),
interpolation=interp)
return patch
现在进入ops.py下的crop_and_resize,这个函数的作用就是crop一块以object为中心的,边长为size大小的patch(如下面的绿色虚线的正方形框),然后将其resize成out_size的大小:传入size和center计算出角落坐标形式的正方形patch,即 ( y m i n , x m i n , y m a x , x m a x ) (y_{min},x_{min},y_{max},x_{max}) (ymin,xmin,ymax,xmax),如下面两个点粗的绿点,因为这样扩大的坐标有可能会超出原来的图片(如粉红色线所表示),所以就要计算左上角和右下角相对原图片超出多少,好进行pad,上面13-14行代码就是干这事。然后根据他们超出当中的最大值npad来在原图像周围pad(也就是最外面的蓝框),因为原图像增大了,所以corner相对坐标也变了,对应上面22行代码。然后就是crop下来绿色方形的那块,经过resize后返回。

下面就是我的实验结果:

2.2 Pair
现在继续回到train_over方法,里面构造dataset的时候用了Pair类,所以从代码角度具体来看一下,因为继承了Dataset类,所以要overwrite __getitem__和__len__方法:
__getitem__:分析代码,这个方法就是通过index索引返回item = (z, x, box_z, box_x),然后经过transforms返回一对pair(z, x),就需要像论文里面说的:The images are extracted from two frames of a video that both contain the object and are at most T frames apart 。_filter:通过该函数筛选符合条件的有效索引val_indices,这里不详细分析,因为我也不知道为什么会有这样的filter condition。_sample_pair:如果有效索引大于2个的话,就从中随机挑选两个索引,这里取的间隔不超过T=100
__len__:这里定义的长度就是被索引到的视频序列帧数×每个序列提供的对数
2.3 train_step
现在来到siamfc.py里面最后一个关键的地方,数据准备好了,经过变换和加载进来就可以训练了,下面代码是常规操作,具体在train_step里面实现了训练和反向传播:
for epoch in range(self.cfg.epoch_num):
# update lr at each epoch
self.lr_scheduler.step(epoch=epoch)
# loop over dataloader
for it, batch in enumerate(dataloader):
loss = self.train_step(batch, backward=True)
print('Epoch: {} [{}/{}] Loss: {:.5f}'.format(
epoch + 1, it + 1, len(dataloader), loss))
sys.stdout.flush()
而train_step里面难度又是在于理解_create_labels,具体的一些tensor的shape可以看我的注释,我好奇就把他打印出来了,看来本来__getitem__返回一对pair(z, x),经过dataloader的加载,还是z堆叠一起,x堆叠一起,并不是(z, x)绑定堆叠一起【主要自己对dataloader源码不是很熟,手动捂脸】
而且criterion使用的BalancedLoss,是调用F.binary_cross_entropy_with_logits,进行一个element-wise的交叉熵计算,所以创建出来的labels的shape其实就是和responses的shape是一样的:
def train_step(self, batch, backward=True):
# set network mode
self.net.train(backward)
# parse batch data
z = batch[0].to(self.device, non_blocking=self.cuda)
x = batch[1].to(self.device, non_blocking=self.cuda)
# print("batch_z shape:", z.shape) # torch.Size([8, 3, 127, 127])
# print("batch_x shape:", x.shape) # torch.Size([8, 3, 239, 239])
with torch.set_grad_enabled(backward):
# inference
responses = self.net(z, x)
# print("responses shape:", responses.shape) # torch.Size([8, 1, 15, 15])
# calculate loss
labels = self._create_labels(responses.size())
loss = self.criterion(responses, labels)
if backward:
# back propagation
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
创建标签,论文里是这么说的:
y [ u ] = { + 1 if k ∥ u − c ∥ ≤ R − 1 otherwise y[u]=\left\{\begin{array}{ll} {+1} & {\text { if } k\|u-c\| \leq R} \\ {-1} & {\text { otherwise }} \end{array}\right. y[u]={+1−1 if k∥u−c∥≤R otherwise
因为我们的exemplar image z z z 和search image x x x都是以目标为中心的,所以labels的中心为1,中心以外为0。
def _create_labels(self, size):
# skip if same sized labels already created
if hasattr(self, 'labels') and self.labels.size() == size:
return self.labels
def logistic_labels(x, y, r_pos, r_neg):
dist = np.abs(x) + np.abs(y) # block distance
labels = np.where(dist <= r_pos,
np.ones_like(x),
np.where(dist < r_neg,
np.ones_like(x) * 0.5,
np.zeros_like(x)))
return labels
# distances along x- and y-axis
n, c, h, w = size
x = np.arange(w) - (w - 1) / 2
y = np.arange(h) - (h - 1) / 2
x, y = np.meshgrid(x, y)
# create logistic labels 这里除以stride,是相对score map上来说
r_pos = self.cfg.r_pos / self.cfg.total_stride
r_neg = self.cfg.r_neg / self.cfg.total_stride
labels = logistic_labels(x, y, r_pos, r_neg)
# repeat to size
labels = labels.reshape((1, 1, h, w))
labels = np.tile(labels, (n, c, 1, 1))
# convert to tensors
self.labels = torch.from_numpy(labels).to(self.device).float()
return self.labels
其中关于np.tile、np.meshgrid、np.where函数的使用可以去看我这篇博客,最后出来的一个batch下某一个通道下的label就是下面这样的,有没有一种扫雷的既视感,:

至此此份repo的训练应该差不多结束了,测试部分(inference phase)我还没怎么看,且涉及到GOT-10k的使用,下一次有空再看再写~
上下篇
上一篇:siamfc-pytorch代码讲解(一):backbone&head
下一篇:siamfc-pytorch代码讲解(三):demo&track