一文搞懂交叉熵损失
本文从信息熵和最大似然估计来推导交叉熵作为分类损失的依据。
从熵来看交叉熵损失
信息量
信息量来衡量一个事件的不确定性,一个事件发生的概率越大,不确定性越小,则其携带的信息量就越小。
设 X X X是一个离散型随机变量,其取值为集合 X = x 0 , x 1 , … , x n X = {x_0,x_1,\dots,x_n} X=x0,x1,…,xn ,则其概率分布函数为 p ( x ) = P r ( X = x ) , x ∈ X p(x) = Pr(X = x),x \in X p(x)=Pr(X=x),x∈X,则定义事件 X = x 0 X = x_0 X=x0 的信息量为:
I ( x 0 ) = − log ( p ( x 0 ) ) I(x_0) = -\log(p(x_0)) I(x0)=−log(p(x0))
当 p ( x 0 ) = 1 p(x_0) = 1 p(x0)=1时,该事件必定发生,其信息量为0.
熵
熵用来衡量一个系统的混乱程度,代表系统中信息量的总和;熵值越大,表明这个系统的不确定性就越大。
信息量是衡量某个事件的不确定性,而熵是衡量一个系统(所有事件)的不确定性。
熵的计算公式
H ( x ) = − ∑ i = 1 n p ( x i ) log ( p ( x i ) ) H(x) = -\sum_{i=1}^np(x_i)\log(p(x_i)) H(x)=−i=1∑np(xi)log(p(xi))
其中, p ( x i ) p(x_i) p(xi)为事件 X = x i X=x_i X=xi的概率, − l o g ( p ( x i ) ) -log(p(x_i)) −log(p(xi))为事件 X = x i X=x_i X=xi的信息量。
可以看出,熵是信息量的期望值,是一个随机变量(一个系统,事件所有可能性)不确定性的度量。熵值越大,随机变量的取值就越难确定,系统也就越不稳定;熵值越小,随机变量的取值也就越容易确定,系统越稳定。
相对熵 Relative entropy
相对熵也称为KL散度(Kullback-Leibler divergence),表示同一个随机变量的两个不同分布间的距离。
设 p ( x ) , q ( x ) p(x),q(x) p(x),q(x) 分别是 离散随机变量 X X X的两个概率分布,则 p p p对 q q q的相对熵是:
D K L ( p ∥ q ) = ∑ i p ( x i ) l o g ( p ( x i ) q ( x i ) ) D_{KL}(p \parallel q) = \sum_i p(x_i) log(\frac{p(x_i)}{q(x_i)}) DKL(p∥q)=i∑p(xi)log(q(xi)p(xi))
相对熵具有以下性质:
- 如果 p ( x ) p(x) p(x)和 q ( x ) q(x) q(x)的分布相同,则其相对熵等于0
- D K L ( p ∥ q ) ≠ D K L ( q ∥ p ) D_{KL}(p \parallel q) \neq D_{KL}(q \parallel p) DKL(p∥q)=DKL(q∥p),也就是相对熵不具有对称性。
- D K L ( p ∥ q ) ≥ 0 D_{KL}(p \parallel q) \geq 0 DKL(p∥q)≥0
总的来说,相对熵是用来衡量同一个随机变量的两个不同分布之间的距离。在实际应用中,假如 p ( x ) p(x) p(x)是目标真实的分布,而 q ( x ) q(x) q(x)是预测得来的分布,为了让这两个分布尽可能的相同的,就需要最小化KL散度。
交叉熵 Cross Entropy
设 p ( x ) , q ( x ) p(x),q(x) p(x),q(x) 分别是 离散随机变量 X X X的两个概率分布,其中 p ( x ) p(x) p(x)是目标分布, p p p和 q q q的交叉熵可以看做是,使用分布 q ( x ) q(x) q(x) 表示目标分布 p ( x ) p(x) p(x)的困难程度:
H ( p , q ) = ∑ i p ( x i ) l o g 1 log q ( x i ) = − ∑ i p ( x i ) log q ( x i ) H(p,q) = \sum_ip(x_i)log\frac{1}{\log q(x_i)} = -\sum_ip(x_i)\log q(x_i) H(p,q)=i∑p(xi)loglogq(xi)1=−i∑p(xi)logq(xi)
将熵、相对熵以及交叉熵的公式放到一起,
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ H(p) &= -\sum_…
通过上面三个公式就可以得到
D K L ( p , q ) = H ( p , q ) − H ( p ) D_{KL}(p,q) = H(p,q)- H(p) DKL(p,q)=H(p,q)−H(p)
在机器学习中,目标的分布 p ( x ) p(x) p(x) 通常是训练数据的分布是固定,即是 H ( p ) H(p) H(p) 是一个常量。这样两个分布的交叉熵 H ( p , q ) H(p,q) H(p,q) 也就等价于最小化这两个分布的相对熵 D K L ( p ∥ q ) D_{KL}(p \parallel q) DKL(p∥q)。
设 p ( x ) p(x) p(x) 是目标分布(训练数据的分布),我们的目标的就让训练得到的分布 q ( x ) q(x) q(x)尽可能的接近 p ( x ) p(x) p(x),这时候就可以最小化 D K L ( p ∥ q ) D_{KL}(p \parallel q) DKL(p∥q),等价于最小化交叉熵 H ( p , q ) H(p,q) H(p,q) 。
从最大似然看交叉熵
设有一组训练样本 X = { x 1 , x 2 , ⋯ , x m } X= \{x_1,x_2,\cdots,x_m\} X={x1,x2,⋯,xm} ,该样本的分布为 p ( x ) p(x) p(x) 。假设使用 θ \theta θ 参数化模型得到 q ( x ; θ ) q(x;\theta) q(x;θ) ,现用这个模型来估计 X X X 的概率分布,得到似然函数
L ( θ ) = q ( X ; θ ) = ∏ i m q ( x i ; θ ) L(\theta) = q(X; \theta) = \prod_i^mq(x_i;\theta) L(θ)=q(X;θ)=i∏mq(xi;θ)
最大似然估计就是求得 θ \theta θ 使得 L ( θ ) L(\theta) L(θ) 的值最大,也就是
θ M L = a r g max θ ∏ i m q ( x i ; θ ) \theta_{ML} = arg \max_{\theta} \prod_i^mq(x_i;\theta) θML=argθmaxi∏mq(xi;θ)
对上式的两边同时取 log \log log ,等价优化 log \log log 的最大似然估计即log-likelyhood ,最大对数似然估计
θ M L = a r g max θ ∑ i m log q ( x i ; θ ) \theta_{ML} = arg \max_\theta \sum_i^m \log q(x_i;\theta) θML=argθmaxi∑mlogq(xi;θ)
对上式的右边进行缩放并不会改变 a r g max arg \max argmax 的解,上式的右边除以样本的个数 m m m
θ M L = a r g max θ 1 m ∑ i m log q ( x i ; θ ) \theta_{ML} = arg \max_\theta \frac{1}{m}\sum_i^m\log q(x_i;\theta) θML=argθmaxm1i∑mlogq(xi;θ)
和相对熵等价
上式的最大化 θ M L \theta_{ML} θML 是和没有训练样本没有关联的,就需要某种变换使其可以用训练的样本分布来表示,因为训练样本的分布可以看作是已知的,也是对最大化似然的一个约束条件。
注意上式的
1 m ∑ i m log q ( x i ; θ ) \frac{1}{m}\sum_i^m\log q(x_i;\theta) m1i∑mlogq(xi;θ)
相当于求随机变量 X X X 的函数 log ( X ; θ ) \log (X;\theta) log(X;θ) 的均值 ,根据大数定理,随着样本容量的增加,样本的算术平均值将趋近于随机变量的期望。 也就是说
1 m ∑ i m log q ( x i ; θ ) → E x ∼ P ( log q ( x ; θ ) ) \frac{1}{m}\sum_i^m \log q(x_i;\theta) \rightarrow E_{x\sim P}(\log q(x;\theta)) m1i∑mlogq(xi;θ)→Ex∼P(logq(x;θ))
其中 E X ∼ P E_{X\sim P} EX∼P 表示符合样本分布 P P P 的期望,这样就将最大似然估计使用真实样本的期望来表示
θ M L = a r g max θ E x ∼ P ( log q ( x ; θ ) ) = a r g min θ E x ∼ P ( − log q ( x ; θ ) ) \begin{aligned} \theta_{ML} &= arg \max_{\theta} E_{x\sim P}({\log q(x;\theta)}) \\ &= arg \min_{\theta} E_{x \sim P}(- \log q(x;\theta)) \end{aligned} θML=argθmaxEx∼P(logq(x;θ))=argθminEx∼P(−logq(x;θ))
对右边取负号,将最大化变成最小化运算。
上述的推导过程,可以参考 《Deep Learning》 的第五章。 但是,在书中变为期望的只有一句话,将式子的右边除以样本数量 m m m 进行缩放,从而可以将其变为 E x ∼ p log q ( x ; θ ) E_{x \sim p}\log q(x;\theta) Ex∼plogq(x;θ),没有细节过程,也可能是作者默认上面的变换对读者是一直。 确实是理解不了,查了很多文章,都是对这个变换的细节含糊其辞。一个周,对这个点一直耿耿于怀,就看了些关于概率论的科普书籍,其中共有介绍大数定理的:当样本容量趋于无穷时,样本的均值趋于其期望。
针对上面公式,除以 m m m后, 1 m ∑ i m log q ( x i ; θ ) \frac{1}{m}\sum_i^m\log q(x_i;\theta) m1∑imlogq(xi;θ) ,确实是关于随机变量函数 log q ( x ) \log q(x) logq(x) 的算术平均值,而 x x x 是训练样本其分布是已知的 p ( x ) p(x) p(x) ,这样就得到了 E x ∼ p ( log q ( x ) ) E_{x \sim p}(\log q(x)) Ex∼p(logq(x)) 。
D K L ( p ∥ q ) = ∑ i p ( x i ) l o g ( p ( x i ) q ( x i ) ) = E x ∼ p ( log p ( x ) q ( x ) ) = E x ∼ p ( log p ( x ) − log q ( x ) ) = E x ∼ p ( log p ( x ) ) − E x ∼ p ( log q ( x ) ) \begin{aligned} D_{KL}(p \parallel q) &= \sum_i p(x_i) log(\frac{p(x_i)}{q(x_i)})\\ &= E_{x\sim p}(\log \frac{p(x)}{q(x)}) \\ &= E_{x \sim p}(\log p(x) - \log q(x)) \\ &= E_{x \sim p}(\log p(x)) - E_{x \sim p} (\log q(x)) \end{aligned} DKL(p∥q)=i∑p(xi)log(q(xi)p(xi))=Ex∼p(logq(x)p(x))=Ex∼p(logp(x)−logq(x))=Ex∼p(logp(x))−Ex∼p(logq(x))
由于 E x ∼ p ( log p ( x ) ) E_{x \sim p} (\log p(x)) Ex∼p(logp(x)) 是训练样本的期望,是个固定的常数,在求最小值时可以忽略,所以最小化 D K L ( p ∥ q ) D_{KL}(p \parallel q) DKL(p∥q) 就变成了最小化 − E x ∼ p ( log q ( x ) ) -E_{x\sim p}(\log q(x)) −Ex∼p(logq(x)) ,这和最大似然估计是等价的。
和交叉熵等价
最大似然估计、相对熵、交叉熵的公式如下
θ M L = − a r g min θ E x ∼ p log q ( x ; θ ) D K L = E x ∼ p log p ( x ) − E x ∼ p log q ( x ) H ( p , q ) = − ∑ i m p ( x i ) log q ( x i ) = − E x ∼ p log q ( x ) \begin{aligned} \theta_{ML} &= -arg \min_\theta E_{x\sim p}\log q(x;\theta) \\ D_{KL} &= E_{x \sim p}\log p(x) - E_{x \sim p} \log q(x) \\ H(p,q) &= -\sum_i^m p(x_i) \log q(x_i) = -E_{x \sim p} \log q(x) \end{aligned} θMLDKLH(p,q)=−argθminEx∼plogq(x;θ)=Ex∼plogp(x)−Ex∼plogq(x)=−i∑mp(xi)logq(xi)=−Ex∼plogq(x)
从上面可以看出,最小化交叉熵,也就是最小化 D K L D_{KL} DKL ,从而预测的分布 q ( x ) q(x) q(x) 和训练样本的真实分布 p ( x ) p(x) p(x) 最接近。而最小化 D K L D_{KL} DKL 和最大似然估计是等价的。
多分类交叉熵
多分类任务中输出的是目标属于每个类别的概率,所有类别概率的和为1,其中概率最大的类别就是目标所属的分类。 而softmax 函数能将一个向量的每个分量映射到 [ 0 , 1 ] [0,1] [0,1] 区间,并且对整个向量的输出做了归一化,保证所有分量输出的和为1,正好满足多分类任务的输出要求。所以,在多分类中,在最后就需要将提取的到特征经过softmax函数的,输出为每个类别的概率,然后再使用交叉熵 作为损失函数。
softmax函数定义如下:
S i = e z i ∑ i = 1 n e z i S_i = \frac{e^{z_i}}{\sum^n_{i=1}e^{z_i}} Si=∑i=1neziezi
其中,输入的向量为 z i ( i = 1 , 2 , … , n ) z_i(i = 1,2,\dots,n) zi(i=1,2,…,n) 。
更直观的参见下图
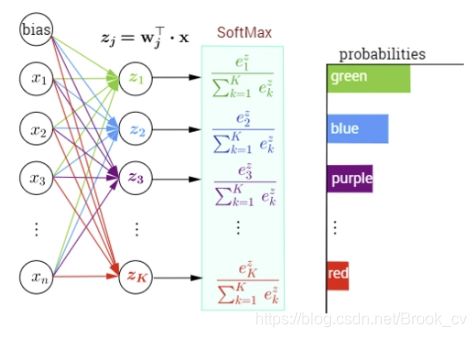
通过前面的特征提取到的特征向量为 ( z 1 , z 2 , … , z k ) (z_1,z_2,\dots,z_k) (z1,z2,…,zk) ,将向量输入到softmax函数中,即可得到目标属于每个类别的概率,概率最大的就是预测得到的目标的类别。
Cross Entropy Loss
使用softmax函数可以将特征向量映射为所属类别的概率,可以看作是预测类别的概率分布 q ( c i ) q(c_i) q(ci) ,有
q ( c i ) = e z i ∑ i = 1 n e z i q(c_i) = \frac{e^{z_i}}{\sum^n_{i=1}e^{z_i}} q(ci)=∑i=1neziezi
其中 c i c_i ci 为某个类别。
设训练数据中类别的概率分布为 p ( c i ) p(c_i) p(ci) ,那么目标分布 p ( c i ) p(c_i) p(ci) 和预测分布 q ( c i ) q(c_i) q(ci)的交叉熵为
H ( p , q ) = − ∑ i p ( c i ) log q ( c i ) H(p,q) =-\sum_ip(c_i)\log q(c_i) H(p,q)=−i∑p(ci)logq(ci)
每个训练样本所属的类别是已知的,并且每个样本只会属于一个类别(概率为1),属于其他类别概率为0。具体的,可以假设有个三分类任务,三个类分别是:猫,猪,狗。现有一个训练样本类别为猫,则有:
p ( c a t ) = 1 p ( p i g ) = 0 p ( d o g ) = 0 \begin{aligned} p(cat) & = 1 \\ p(pig) &= 0 \\ p(dog) & = 0 \end{aligned} p(cat)p(pig)p(dog)=1=0=0
通过预测得到的三个类别的概率分别为: q ( c a t ) = 0.6 , q ( p i g ) = 0.2 , q ( d o g ) = 0.2 q(cat) = 0.6,q(pig) = 0.2,q(dog) = 0.2 q(cat)=0.6,q(pig)=0.2,q(dog)=0.2 ,计算 p p p 和 q q q 的交叉熵为:
H ( p , q ) = − ( p ( c a t ) log q ( c a t ) + p ( p i g ) + log q ( p i g ) + log q ( d o g ) ) = − ( 1 ⋅ log 0.6 + 0 ⋅ log 0.2 + 0 ⋅ log 0.2 ) = − log 0.6 = − log q ( c a t ) \begin{aligned} H(p,q) &= -(p(cat) \log q(cat) + p(pig) + \log q(pig) + \log q(dog)) \\ &= - (1 \cdot \log 0.6 + 0 \cdot \log 0.2 +0 \cdot \log 0.2) \\ &= - \log 0.6 \\ &= - \log q(cat) \end{aligned} H(p,q)=−(p(cat)logq(cat)+p(pig)+logq(pig)+logq(dog))=−(1⋅log0.6+0⋅log0.2+0⋅log0.2)=−log0.6=−logq(cat)
利用这种特性,可以将样本的类别进行重新编码,就可以简化交叉熵的计算,这种编码方式就是one-hot 编码。以上面例子为例,
cat = ( 100 ) pig = ( 010 ) dog = ( 001 ) \begin{aligned} \text{cat} &= (1 0 0) \\ \text{pig} &= (010) \\ \text{dog} &= (001) \end{aligned} catpigdog=(100)=(010)=(001)
通过这种编码方式,在计算交叉熵时,只需要计算和训练样本对应类别预测概率的值,其他的项都是 0 ⋅ log q ( c i ) = 0 0 \cdot \log q(c_i) = 0 0⋅logq(ci)=0 。
具体的,交叉熵计算公式变成如下:
Cross_Entropy ( p , q ) = − log q ( c i ) \text{Cross\_Entropy}(p,q) = - \log q(c_i) Cross_Entropy(p,q)=−logq(ci)
其中 c i c_i ci 为训练样本对应的类别,上式也被称为负对数似然(negative log-likelihood,nll)。
PyTorch中的Cross Entropy
PyTorch中实现交叉熵损失的有三个函数torch.nn.CrossEntropyLoss,torch.nn.LogSoftmax以及torch.nn.NLLLoss。
-
torch.nn.functional.log_softmax比较简单,输入为 n n n维向量,指定要计算的维度dim,输出为 l o g ( S o f t m a x ( x ) ) log(Softmax(x)) log(Softmax(x))。其计算公式如下:
LogSoftmax ( x i ) = log ( exp ( x i ) ∑ j exp ( x j ) ) \text{LogSoftmax}(x_i) = \log (\frac{\exp(x_i)}{\sum_j \exp(x_j)}) LogSoftmax(xi)=log(∑jexp(xj)exp(xi))
没有额外的处理,就是对输入的 n n n维向量的每个元素进行上述运算。 -
torch.nn.functional.nll_loss负对数似然损失(Negative Log Likelihood Loss),用于多分类,其输入的通常是torch.nn.functional.log_softmax的输出值。其函数如下
torch.nn.functional.nll_loss(input, target, weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
input 也就是log_softmax的输出值,各个类别的对数概率。target 目标正确类别,weight 针对类别不平衡问题,可以为类别设置不同的权值;ignore_index 要忽略的类别,不参与loss的计算;比较重要的是reduction 的值,有三个取值:none 不做处理,输出的结果为向量;mean 将none结果求均值后输出;sum 将none 结果求和后输出。
torch.nn.CrossEntropyLoss就是上面两个函数的组合nll_loss(log_softmax(input))。
二分类交叉熵
多分类中使用softmax函数将最后的输出映射为每个类别的概率,而在二分类中则通常使用sigmoid 将输出映射为正样本的概率。这是因为二分类中,只有两个类别:{正样本,负样本},只需要求得正样本的概率 q q q,则 1 − q 1-q 1−q 就是负样本的概率。这也是多分类和二分类不同的地方。
sigmoid \text{sigmoid} sigmoid 函数的表达式如下:
σ ( z ) = 1 1 + e − z \sigma(z) = \frac{1}{1 + e^{-z}} σ(z)=1+e−z1
sigmoid的输入为 z z z ,其输出为 ( 0 , 1 ) (0,1) (0,1) ,可以表示分类为正样本的概率。
二分类的交叉熵可以看作是交叉熵损失的一个特列,交叉熵为
Cross_Entropy ( p , q ) = − ∑ i m p ( x i ) log q ( x i ) \text{Cross\_Entropy}(p,q) = -\sum_i^m p(x_i) \log q(x_i) Cross_Entropy(p,q)=−i∑mp(xi)logq(xi)
这里只有两个类别 x ∈ x 1 , x 2 x \in {x_1,x_2} x∈x1,x2 ,则有
Cross_Entropy ( p , q ) = − ( p ( x 1 ) log q ( x 1 ) + p ( x 2 ) log q ( x 2 ) ) \begin{aligned} \text{Cross\_Entropy}(p,q) &= -(p(x_1) \log q(x_1) + p(x_2) \log q(x_2)) \end{aligned} Cross_Entropy(p,q)=−(p(x1)logq(x1)+p(x2)logq(x2))
因为只有两个选择,则有 p ( x 1 ) + p ( x 2 ) = 1 , q ( x 1 ) + q ( x 2 ) = 1 p(x_1) + p(x_2) = 1,q(x_1) + q(x_2) = 1 p(x1)+p(x2)=1,q(x1)+q(x2)=1 。设,训练样本中 x 1 x_1 x1的概率为 p p p,则 x 2 x_2 x2为 1 − p 1-p 1−p; 预测的 x 1 x_1 x1的概率为 q q q,则 x 2 x_2 x2的预测概率为 1 − q 1 - q 1−q 。则上式可改写为
Cross_Entropy ( p , q ) = − ( p log q + ( 1 − p ) log ( 1 − q ) ) \text{Cross\_Entropy} (p,q) = -(p \log q + (1-p) \log (1-q)) Cross_Entropy(p,q)=−(plogq+(1−p)log(1−q))
也就是二分类交叉熵的损失函数。
总结
相对熵可以用来度量两个分布相似性,假设分布 p p p是训练样本的分布, q q q是预测得到的分布。分类训练的过程实际上就是最小化 D K L ( p ∥ q ) D_{KL}(p \parallel q) DKL(p∥q),由于由于交叉熵
H ( p , q ) = D K L ( p ∥ q ) + H ( p ) H(p,q)= D_{KL}(p \parallel q) + H(p) H(p,q)=DKL(p∥q)+H(p)
其中, H ( p ) H(p) H(p)是训练样本的熵,是一个已知的常量,这样最小化相对熵就等价于最小化交叉熵。
从最大似然估计转化为最小化负对数似然
θ M L = − a r g min θ E x ∼ p log q ( x ; θ ) \theta_{ML} = -arg \min_\theta E_{x\sim p}\log q(x;\theta) θML=−argθminEx∼plogq(x;θ)
也等价于最小化相对熵。