庖丁解牛yolo_v4之mosaic
mosaic 数据增强
Yolov4的mosaic 数据增强是参考CutMix数据增强,理论上类似,CutMix的理论可以参考这篇CutMix,但是mosaic利用了四张图片,据论文其优点是丰富检测物体的背景,且在BN计算的时候一下子会计算四张图片的数据,使得mini-batch大小不需要很大,那么一个GPU就可以达到比较好的效果。
实现方法
伪代码:
for data, target in batches:
w, h = (data[0]).shape
cut_x = random(0.2w, 0.8w)
cut_y = random(0.2h, 0.8h)
s1, s2, s3, s4 = area(block1) / wh, .....(分块所占比例)
d1 = data[random_index][0, :(h-cut_y), 0:cut_x, :]
d2 = data[random_index][1, (h-cut_y):, 0:cut_x, :]
d3 = data[random_index][2, (h-cut_y):, cut_x:, :]
d4 = data[random_index][3, :(h-cut_y), cut_x:, :]
x = concat(d1, d2, d3, d4)
y = target[random_index]*s1 + target[random_index]*s2 + target[random_index]*s3 + target[random_index]*s4
以上伪代码适用于分类的数据,检测的数据需要合并annotations,后面更新。
python代码在github
效果图:
对于用于检测的数据,首先对图片的处理和上面对分类数据处理一致,对于annotations需要对框的坐标在合成图中进行调整,超出边界的需要裁剪,效果图如下:
代码请见github,后期更新代码实现细节
————————————————
版权声明:本文为CSDN博主「popoffpopoff」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/popoffpopoff/article/details/105795999
CutMix:数据增强
目录
1.几种数据增强的区别:Mixup,Cutout,CutMix
2.CutMix的原理【与代码一同食用更好消化】
3.论文中的一些讨论内容
4.看看代码
看论文的原因:学习mixup的时候发现的这篇论文,读读看!
论文地址:https://arxiv.org/abs/1905.04899v2
1.几种数据增强的区别:Mixup,Cutout,CutMix
Mixup:将随机的两张样本按比例混合,分类的结果按比例分配;
Cutout:随机的将样本中的部分区域cut掉,并且填充0像素值,分类的结果不变;
CutMix:就是将一部分区域cut掉但不填充0像素而是随机填充训练集中的其他数据的区域像素值,分类结果按一定的比例分配
上述三种数据增强的区别:cutout和cutmix就是填充区域像素值的区别;mixup和cutmix是混合两种样本方式上的区别:mixup是将两张图按比例进行插值来混合样本,cutmix是采用cut部分区域再补丁的形式去混合图像,不会有图像混合后不自然的情形
优点:
在训练过程中不会出现非信息像素,从而能够提高训练效率;
保留了regional dropout的优势,能够关注目标的non-discriminative parts;
通过要求模型从局部视图识别对象,对cut区域中添加其他样本的信息,能够进一步增强模型的定位能力;
不会有图像混合后不自然的情形,能够提升模型分类的表现;
训练和推理代价保持不变。
2.CutMix的原理【与代码一同食用更好消化】
和是两个不同的训练样本,和是对应的标签值,CutMix需要生成的是新的训练样本和对应标签:和,公式如下:
是为了dropd掉部分区域和进行填充的二进制掩码,是逐像素相乘,是所有元素都为1 的二进制掩码,与Mixup一样属于Beta分布:,令则服从(0,1)的均匀分布。
为了对二进制掩进行采样,首先要对剪裁区域的边界框进行采样,用来对样本和做裁剪区域的指示标定。在论文中对矩形掩码进行采样(长宽与样本大小成比例)。
剪裁区域的边界框采样公式如下:
保证剪裁区域的比例为,确定好裁剪区域之后,将制掩中的裁剪区域置0,其他区域置1。就完成了掩码的采样,然后将样本A中的剪裁区域移除,将样本B中的剪裁区域进行裁剪然后填充到样本A。
3.论文中的一些讨论内容
1).What does model learn with CutMix?
作者通过热力图,给出了结果。CutMix的操作使得模型能够从一幅图像上的局部视图上识别出两个目标,提高训练的效率。由图可以看出,Cutout能够使得模型专注于目标较难区分的区域(腹部),但是有一部分区域是没有任何信息的,会影响训练效率;Mixup的话会充分利用所有的像素信息,但是会引入一些非常不自然的伪像素信息。
同时作者也给出了一个信息利用的对比表格,CutMix能有效地改善数据增强的效果,准确的定位和分类
4.看看代码
代码地址:https://github.com/clovaai/CutMix-PyTorch
1).生成剪裁区域:
"""train.py 279-295行"""
"""输入为:样本的size和生成的随机lamda值"""
def rand_bbox(size, lam):
W = size[2]
H = size[3]
"""1.论文里的公式2,求出B的rw,rh"""
cut_rat = np.sqrt(1. - lam)
cut_w = np.int(W * cut_rat)
cut_h = np.int(H * cut_rat)
# uniform
"""2.论文里的公式2,求出B的rx,ry(bbox的中心点)"""
cx = np.random.randint(W)
cy = np.random.randint(H)
#限制坐标区域不超过样本大小
bbx1 = np.clip(cx - cut_w // 2, 0, W)
bby1 = np.clip(cy - cut_h // 2, 0, H)
bbx2 = np.clip(cx + cut_w // 2, 0, W)
bby2 = np.clip(cy + cut_h // 2, 0, H)
"""3.返回剪裁B区域的坐标值"""
return bbx1, bby1, bbx2, bby2
2).整体流程:
"""train.py 220-244行"""
for i, (input, target) in enumerate(train_loader):
# measure data loading time
data_time.update(time.time() - end)
input = input.cuda()
target = target.cuda()
r = np.random.rand(1)
if args.beta > 0 and r < args.cutmix_prob:
# generate mixed sample
"""1.设定lamda的值,服从beta分布"""
lam = np.random.beta(args.beta, args.beta)
"""2.找到两个随机样本"""
rand_index = torch.randperm(input.size()[0]).cuda()
target_a = target#一个batch
target_b = target[rand_index] #batch中的某一张
"""3.生成剪裁区域B"""
bbx1, bby1, bbx2, bby2 = rand_bbox(input.size(), lam)
"""4.将原有的样本A中的B区域,替换成样本B中的B区域"""
input[:, :, bbx1:bbx2, bby1:bby2] = input[rand_index, :, bbx1:bbx2, bby1:bby2]
# adjust lambda to exactly match pixel ratio
"""5.根据剪裁区域坐标框的值调整lam的值"""
lam = 1 - ((bbx2 - bbx1) * (bby2 - bby1) / (input.size()[-1] * input.size()[-2]))
# compute output
"""6.将生成的新的训练样本丢到模型中进行训练"""
output = model(input)
"""7.按lamda值分配权重"""
loss = criterion(output, target_a) * lam + criterion(output, target_b) * (1. - lam)
else:
# compute output
output = model(input)
loss = criterion(output, target)
差不多就这样。
END.
————————————————
版权声明:本文为CSDN博主「花噜噜酱」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_38715903/article/details/103999227
CNN中的数据增强简单总结
data aug是防止overfit一种重要手段,在实际应用中,data aug往往带来出乎意料的涨点。
首先分享两篇不错的材料。一是19年6月份一篇关于data aug的综述文章。
A survey on Image Data Augmentation for Deep Learningwww.researchgate.net
二是海康威视研究院ImageNet2016数据增强经验分享。
【高手之道】海康威视研究院ImageNet2016竞赛经验分享mp.weixin.qq.com
以下进入正题。
最常见的data aug是crop、expand、color jitter等等。这些操作SSD用的比较溜,具体可参考SSD的data部分代码,我以前也记录过相关笔记。
SSD代码解读(二)--Data Augmentationblog.csdn.net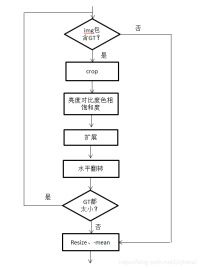
这里推荐一个适用于data aug的库imgaug,各种操作非常全面且例程多还容易上手。
https://github.com/aleju/imgauggithub.com
除了这些常见的空间变换和色彩抖动等操作外,笔者自行总结主要还有以下几类工作。
生成遮挡类
这类方法通过生成mask,然后遮挡原图片部分区域,并不改变label 进行训练。
当目标discriminative部位被遮挡后,网络会被迫使根据遗留的部分去寻找其它关键性部位,从而提升模型性能。
Cutout [1] 和 Random Erase [2]是比较类似的方法,如下图所示。这类方法要注意的是,生成的mask区域有可能会完全覆盖掉目标,这种情况可能会给模型训练带来坏处。

Random Erase示意图
Cutout代码链接
uoguelph-mlrg/Cutoutgithub.com
Random Erase代码链接
zhunzhong07/Random-Erasinggithub.com
HaS[3] 通过将图片划分为S*S个格子,在每个epoch内,对每个格子以一定概率随机进行遮挡,如下图。相较于Cutout,HaS生成多个遮挡块,产生更多类型的遮挡形式,对遮挡的鲁棒性更强。
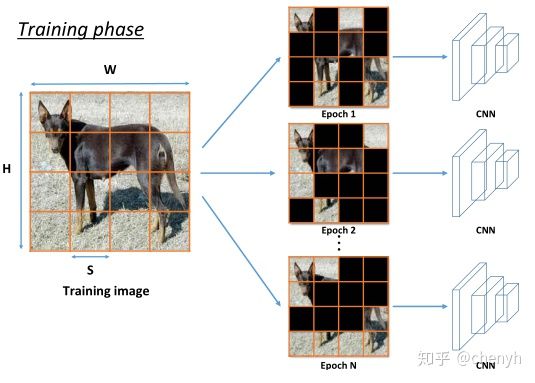
HaS示意图
HaS代码链接
kkanshul/Hide-and-Seekgithub.com
GridMask [4]通过定量计算生成多个遮挡块来提升模型性能,如下图。这样做一可以避免类似于Cutout生成一个大的遮挡块从而完全覆盖掉目标,二相对于HaS可以更好的控制原图片中遮挡与保留的比例。GridMask 在多个task和benchmark上都表现出了SOTA的水平。

GridMask示意图
GridMask 代码链接
https://github.com/akuxcw/GridMaskgithub.com
图片混合类
这类方法中最出名的便数Mixup [5],通过线性叠加两张图片生成新的图片,对应label也进行线性叠加用以训练,多个benchmark上证明了Mixup 的有效性。同期还有个SamplePairing [6]工作,直接对两幅图片像素相加求平均,监督的label不变。训练时间歇使用SamplePairing,待精度稳定后,停止使用SamplePairing。本质上来说,SamplePairing和Mixup区别还是比较大的,Mixup是在训练集不涵盖的空间用线性关系去约束模型,SamplePairing则更像是人为引入错误样本,相当于定期添加噪声来防止过拟合。遗憾的是,SamplePairing没有被ICLR2018录用。
Mixup代码链接
hongyi-zhang/mixupgithub.com
基于Mixup,后续涌现出一些很棒的工作。Mixmatch [7]将Mixup引入到半监督学习中,仅用少量的标记数据,就使半监督学习的预测精度逼近监督学习。Manifold mixup [8]通过对Hidden States进行插值,取得了优于Mixup的效果。
Manifold mixup代码链接
https://github.com/vikasverma1077/manifold_mixupgithub.com
CutMix [9]可以说是图片混合类工作,也可以说是生成遮挡类工作。不同于遮挡类工作一般使用零像素"黑布"来遮挡图片,CutMix使用另一张图片的一个区域来覆盖遮挡区域。因此CutMix可以看成Cutout和Mixup的结合体,既使用了遮挡的思想,又使用了mixup的逐像素线性叠加,当然此处的线性矩阵只含有0,1两个元素。生成图片的标签,和mixup一样,也使用线性叠加的label。CutMix 在多个task和benchmark上也都展现了杰出的效果。

CutMix 示意图
CutMix 代码链接
https://github.com/clovaai/CutMix-PyTorchgithub.com
搜索类
这一块的工作目前还算比较多。推荐Quoc V. Le大神的两篇工作[10]和 [11].
这两篇工作比较类似,[10]主要用于分类任务,[11]则是用在目标检测中。

AutoAugment数据增强policy
变换方法:[10]定义了16中图像变换操作,包括PIL库中提供的14个操作和Cutout和SamplePairing。[11]从 Color operations、 Geometric operations和 Bounding box operations三个角度定义了22中图像变换操作。
搜索空间:预测的data aug policy共包含K个sub-policy,每个sub-policy包含N个图像变换方法,每个方法有两个属性:概率P和幅度magnitude。其中P离散为M个值,magnitude离散为L个值。因此[10][11]搜索空间分别为 和 。
[10]和[11]均使用了常见的 RNN 控制器+RL的方法,proximal policy optimization (PPO) 算法。
AutoAugment代码链接
tensorflow/modelsgithub.com
[11]代码链接
https://github.com/tensorflow/tpu/tree/master/models/official/detectiongithub.com
除了对train data进行aug,还有很多通过学习generator来生成data达到aug的搜索工作。
除了本文总结的几类方法,还有一些GAN_based等方法,本人在实际应用中并未涉及到,暂时便不做归纳总结,以后若有需要再添加上,读者可自行参阅前面分享的综述文。