深度学习与PyTorch入门实战(一)简介
1 简介
1.1 pyTorch 介绍
2016.10 正式发布 0.1 版本,THNN 后端
0.3 到 0.4 发生一个比较大的改变,所以代码需要响应改变才能运行
2018.12 发布 1.0,以 CAFFE2后端,弥补在工业部署上的不足
2019.5 发布1.1
深度学习同类型的框架

google :开发 theano ----》tensorflow。keras,被google收购,相当于一个高层接口,可以调用底层计算库(tensorflow或mxnet)
facebook:caffe ----》caffe2,caffe2和pytorch融合----》pytorch1.0 torch----》pytorch
Amazon:mxnet
Microsoft:CNTK

现阶段:pytorch 和 tensorflow 的使用率比较多
差别在于:动态图优先还是静态图优先
pytorch :动态图
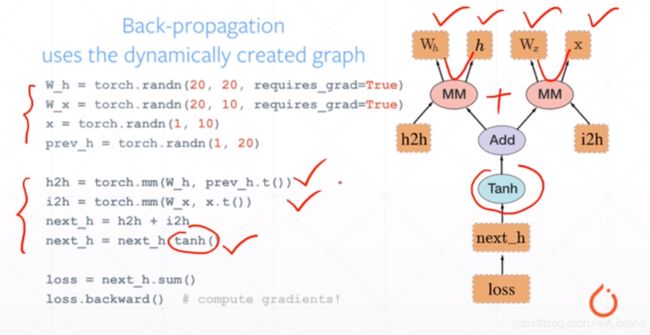
每一条语句,对应右边图动态“插入”
tensorflow:
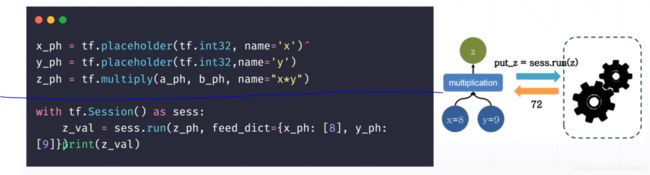
以蓝线为基准,向上需要事先构造出“静态图”,然后在 session 中进行赋值运算
以上就是 pytorch 和 tensorflow 的主要区别
下图为龙龙老师给出的评价,大家仅作为参考即可
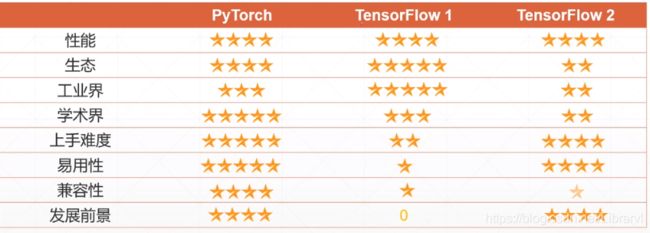
总结:
tensorflow:由于出现较早,企业中大量使用,但是由于静态图的缘故,相较于 pytorch 和 tensorflow2 开发难度比较高
pytorch:开发容易,融入caffe2后工业界占有量也有所提高,由于开发容易,现在学术界设计新算法时,使用较多
1.2 pytorch 常用功能
1、GPU加速
通过代码,对比 cpu 计算速度和 cuda 计算速度
import torch
import time
print(torch.__version__)
print(torch.cuda.is_available())
a = torch.randn(10000, 1000)
b = torch.randn(1000, 2000)
# cpu
t0 = time.time()
c = torch.matmul(a, b)
t1 = time.time()
print(a.device, t1 - t0, c.norm(2))
#gpu
device = torch.device('cuda')
a = a.to(device)
b = b.to(device)
t0 = time.time()
c = torch.matmul(a, b)
t2 = time.time()
print(a.device, t2 - t0, c.norm(2))
t0 = time.time()
c = torch.matmul(a, b)
t2 = time.time()
print(a.device, t2 - t0, c.norm(2))
结果:

我们发现,第一次 cuda 所用时间要大于 cpu,这是因为 从cpu内存到cuda中需要时间,但是第二次也就是数据完成加载,cuda 的速度要秒杀 cpu
2、自动求导
import torch
from torch import autograd
x = torch.tensor(1.)
a = torch.tensor(1., requires_grad = True)
b = torch.tensor(2., requires_grad = True)
c = torch.tensor(3., requires_grad = True)
y = a**2 * x + b * x + c
print('before:', a.grad, b.grad, c.grad) # a, b, c 的梯度
grad = autograd.grad(y, [a, b, c]) # 用自动求导,y 对 a,b,c 进行求导
print('after:',grad[0], grad[1],grad[2]) # a,b,c 的偏微分
结果:
![]()
3、常用网络层
层:
nn.Linearnn.Conv2dnn.LSTM
激活函数
nn.ReLunn.Sigmoid
Loss 函数:
nn.Softmaxnn.CrossEntropyLossnn.MSE