使用tensorflow构建基础电影推荐系统
使用jupyter 可以方便调试
第一步:收集数据
https://grouplens.org/datasets/movielens/
第二步 准备数据
import pandas as pd
import numpy as np
import tensorflow as tf
ratings_df = pd.read_csv('ratings.csv')
ratings_df.tail()
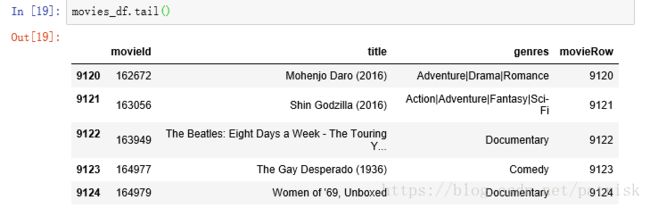
movies_df = pd.read_csv('movies.csv')
movies_df['movieRow'] = movies_df.index #添加电影行数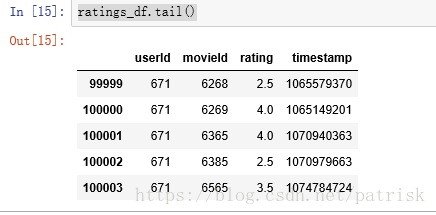
筛选movies_df中的特征
movies_df = movies_df[['movieRow','movieId','title']]
movies_df.to_csv('moviesProcessed.csv',index = False,header = True,encoding = 'utf-8')将ratings_df中的moviesId 替换成行号
ratings_df = pd.merge(ratings_df,movies_df,on = 'movieId')筛选ratings_df中的特征
ratings_df = ratings_df[['userId','movieRow','rating']]
ratings_df.to_csv('ratingsProcessed.csv',index = False,header = True,encoding = 'utf-8')创建电影评分矩阵rating和评分记录矩阵record
userNo = ratings_df['userId'].max()+1
movieNo = ratings_df['movieRow'].max()+1
rating = np.zeros((movieNo,userNo))
flag = 0 #记录处理进度
ratings_df_length = np.shape(ratings_df)[0]
for index,row in ratings_df.iterrows():#获取ratings_df的每一行
rating[int(row['movieRow']),int(row['userId'])] = row['rating']
flag += 1 #表示处理完一行
print('processed %d,%d left'%(flag,ratings_df_length-flag))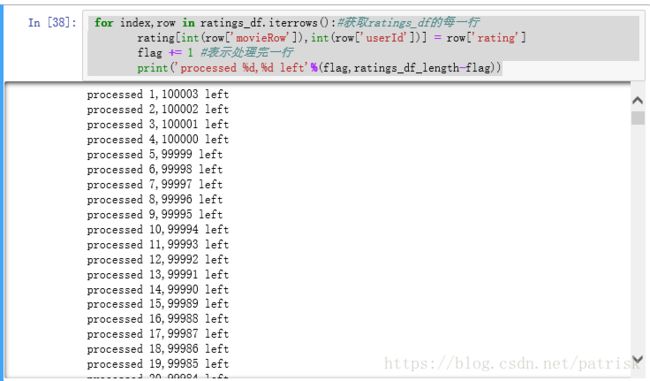
#将构建record矩阵并将矩阵中的Boolean值改成相应的数值
record = rating>0
record = np.array(record,dtype = int)
第三步:构建模型
def normalizeRatings(rating,record):#缩放评分矩阵范围
m,n = rating.shape#m为电影数量,n为用户数量
rating_mean = np.zeros((m,1))#初始化电影评分平均值为0
rating_norm = np.zeros((m,n))#保存处理后的数据
for i in range(m):
idx = record[i,:] != 0 #获取每部电影评分用户的下标,每部电影的评分
rating_mean[i] = np.mean(rating[i,idx])#表示第i行已经评过分的用户的平均值
rating_norm[i,idx] -= rating_mean[i]
return rating_norm,rating_meanrating_norm,rating_mean = normalizeRatings(rating,record) #由于数据中的某些行有这里会出现警告
#处理nan
rating_norm = np.nan_to_num(rating_norm)
rating_mean = np.nan_to_num(rating_mean)
#假设一共有10类电影
num_features = 10
#初始化电影内容矩阵和用户喜好矩阵,产生的参数都是随机数并且是正态分布的
X_parameters = tf.Variable(tf.random_normal([movieNo,num_features],stddev = 0.35))
Theta_parameters = tf.Variable(tf.random_normal([userNo,num_features],stddev = 0.35))
# 构建损失函数
loss = 1/2 * tf.reduce_sum(((tf.matmul(X_parameters,Theta_parameters,transpose_b = True)- rating_norm)*record)**2)+ 1/2 *(tf.reduce_sum(X_parameters**2) + tf.reduce_sum(Theta_parameters**2))
#将X_parameters,Theta_parameters矩阵相乘相乘之前将Theta_parameters转置
#创建优化器和优化目标
optimizer = tf.train.AdamOptimizer(1e-4)
train = optimizer.minimize(loss)第四步:训练模型
使用tensorboard查看loss经迭代后的改变
tf.summary.scalar('loss',loss)
summaryMerged = tf.summary.merge_all()
filename = 'movie_tensorboard'
writer = tf.summary.FileWriter(filename)
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
for i in range(5000):
_,movie_summary = sess.run([train,summaryMerged])
writer.add_summary(movie_summary, i)打开dos将目录切换到保存movie_tensorboard文件的目录下,运行如下命令:
tensorboard --logdir =./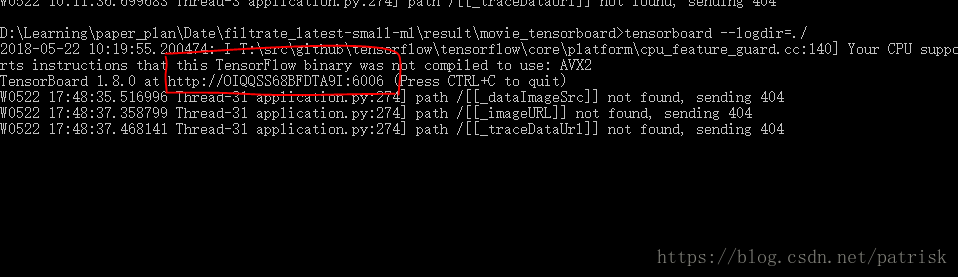
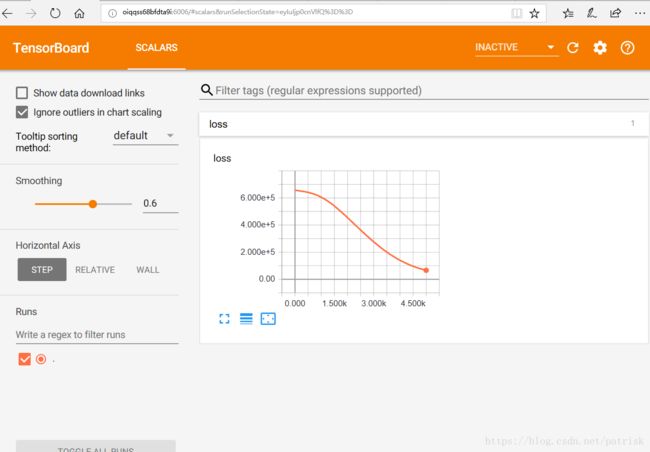
第五步:评估模型
Current_X_parameters,Current_Theta_parameters = sess.run([X_parameters,Theta_parameters])
predicts = np.dot(Current_X_parameters,Current_Theta_parameters.T)+rating_mean
errors = np.sqrt(np.sum((predicts-rating)**2))第六步:构建推荐系统
user_id = input('请输入要推荐的用户编号:')
sortedResult = predicts[:,int(user_id)].argsort()[::-1]#获取该用户的电影评分列表
idx =0
print('为该用户提供的推荐列表:'.center(80,'='))
for i in sortedResult:
print('评分:%.2f,电影名:%s'%(predicts[i,int(user_id)],movies_df.iloc[i]['title']))
idx +=1
if idx == 20:break