ElitesAI·动手学深度学习PyTorch版Task05打卡
卷积神经网络
神经网络结构:
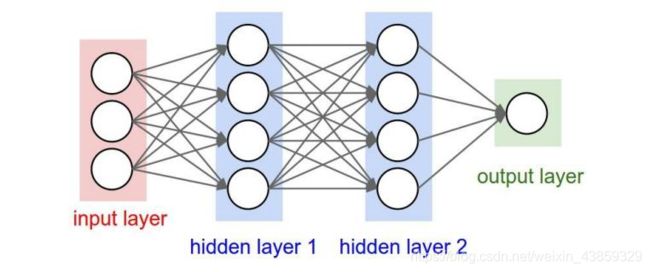
卷积神经网络是神经网络模型的改进版本,依旧是层级网络,只是层的功能和形式做了变化,如: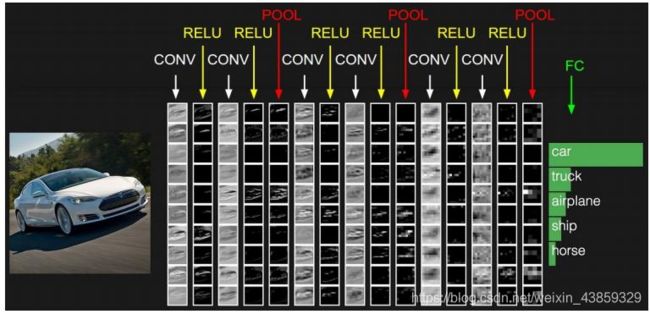
卷积神经网络的层级结构
• 数据输入层/ Input layer
• 卷积计算层/ CONV layer
• ReLU激励层 / ReLU layer
• 池化层 / Pooling layer
• 全连接层 / FC layer
卷积计算层
这一层就是卷积神经网络最重要的一个层次,也是“卷积神经网络”的名字来源。
在这个卷积层,有两个关键操作:
• 局部关联。每个神经元看做一个滤波器(filter)
• 窗口(receptive field)滑动, filter对局部数据计算
先介绍卷积层遇到的几个名词:
• 深度/depth(解释见下图)
• 步长/stride (窗口一次滑动的长度)
• 填充值/zero-padding
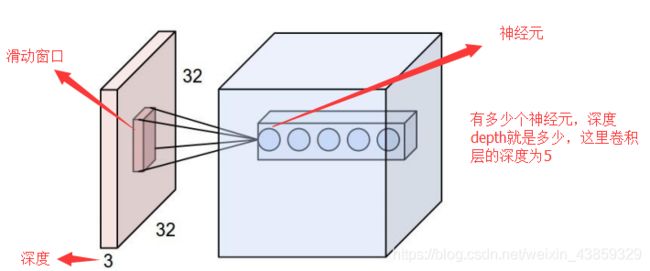
本次课程主要以最常见的二维卷积层为例展开介绍的,常用于处理图像数据。
二维互相关运算
参考链接
http://zh.d2l.ai/chapter_convolutional-neural-networks/conv-layer.html
二维互相关(cross-correlation)运算的输入是一个二维输入数组和一个二维核(kernel)数组,输出也是一个二维数组,其中核数组通常称为卷积核或过滤器(filter)。卷积核窗口(又称卷积窗口)的形状取决于卷积核的高和宽,即 2×2 。卷积核的尺寸通常小于输入数组,卷积核在输入数组上滑动,在每个位置上,卷积核与该位置处的输入子数组按元素相乘并求和,得到输出数组中相应位置的元素。图1展示了一个互相关运算的例子,阴影部分分别是输入的第一个计算区域、核数组以及对应的输出。输入是一个高和宽均为3的二维数组。我们将该数组的形状记为 3×33×3 或(3,3)。核数组的高和宽分别为2。图1阴影部分为第一个输出元素及其计算所使用的输入和核数组元素: 0×0+1×1+3×2+4×3=19
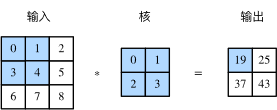
图1 二维互相关运算
在运算过程中,卷积核从输入数组最左上方开始,按顺序从左至右、从上至下依次在输入数组上滑动。上图的输出数组计算方式如下:
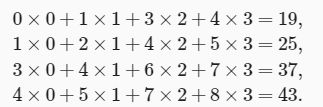
下面我们用corr2d函数实现二维互相关运算,它接受输入数组X与核数组K,并输出数组Y。
import torch
import torch.nn as nn
def corr2d(X, K):
H, W = X.shape
h, w = K.shape
Y = torch.zeros(H - h + 1, W - w + 1)
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i: i + h, j: j + w] * K).sum()
return Y
构造上图中的输入数组X、核数组K来验证二维互相关运算的输出。
X = torch.tensor([[0, 1, 2], [3, 4, 5], [6, 7, 8]])
K = torch.tensor([[0, 1], [2, 3]])
Y = corr2d(X, K)
print(Y)
tensor([[19., 25.],
[37., 43.]])
利用MXNet + Python实现二维互相关运算:
from mxnet import nd
# 定义二维互相关运算函数,接收输入数组x和核数组k,输出数组y
# 这里涉及到 MXNet中 NDArray的基本操作,不清楚的可参看笔者之前的文章或者 MXNet官方文档
def corr2d(x, k):
height, width = k.shape
y = nd.zeros((x.shape[0] - height + 1, x.shape[1] - width + 1))
for i in range(y.shape[0]):
for j in range(y.shape[1]):
y[i, j] = (x[i:i + height, j:j + width] * k).sum()
return y
二维卷积层
二维卷积层将输入和卷积核做互相关运算,并加上一个标量偏置来得到输出。卷积层的模型参数包括卷积核和标量偏置。在训练模型的时候,通常我们先对卷积核随机初始化,然后不断迭代卷积核和偏差。
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super(Conv2D, self).__init__()
self.weight = nn.Parameter(torch.randn(kernel_size))
self.bias = nn.Parameter(torch.randn(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias
下面我们看一个例子,我们构造一张 6×86×8 的图像,中间4列为黑(0),其余为白(1),希望检测到颜色边缘。我们的标签是一个 6×76×7 的二维数组,第2列是1(从1到0的边缘),第6列是-1(从0到1的边缘)。
X = torch.ones(6, 8)
Y = torch.zeros(6, 7)
X[:, 2: 6] = 0
Y[:, 1] = 1
Y[:, 5] = -1
print(X)
print(Y)
tensor([[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.]])
tensor([[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.]])
下面基于corr2d函数来实现一个自定义的二维卷积层。在构造函数__init__里我们声明weight和bias这两个模型参数。前向计算函数forward则是直接调用corr2d函数再加上偏差。
class Conv2D(nn.Block):
def __init__(self, kernel_size, **kwargs):
super(Conv2D, self).__init__(**kwargs)
self.weight = self.params.get('weight', shape=kernel_size)
self.bias = self.params.get('bias', shape=(1,))
def forward(self, x):
return corr2d(x, self.weight.data()) + self.bias.data()
卷积窗口形状为 p×qp×q 的卷积层称为 p×qp×q 卷积层。同样, p×qp×q 卷积或 p×qp×q 卷积核说明卷积核的高和宽分别为 pp 和 qq 。
填充和步幅
填充和步幅,它们可以对给定形状的输入和卷积核改变输出形状。
填充
填充(padding)是指在输入高和宽的两侧填充元素(通常是0元素),图2里我们在原输入高和宽的两侧分别添加了值为0的元素。
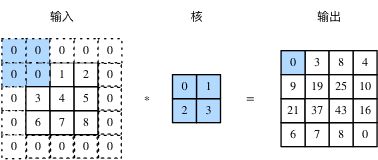
图2 在输入的高和宽两侧分别填充了0元素的二维互相关计算
如果原输入的高和宽是 nhnh 和 nwnw ,卷积核的高和宽是 khkh 和 kwkw ,在高的两侧一共填充 phph 行,在宽的两侧一共填充 pwpw 列,则输出形状为:![]()
我们在卷积神经网络中使用奇数高宽的核,比如 3×33×3 , 5×55×5 的卷积核,对于高度(或宽度)为大小为 2k+12k+1 的核,令步幅为1,在高(或宽)两侧选择大小为 kk 的填充,便可保持输入与输出尺寸相同。
步幅
在互相关运算中,卷积核在输入数组上滑动,每次滑动的行数与列数即是步幅(stride)。此前我们使用的步幅都是1,图3展示了在高上步幅为3、在宽上步幅为2的二维互相关运算。
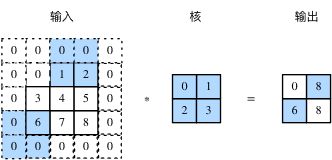
图3 高和宽上步幅分别为3和2的二维互相关运算
一般来说,当高上步幅为 shsh ,宽上步幅为 swsw 时,输出形状为:
多输入通道和多输出通道
之前的输入和输出都是二维数组,但真实数据的维度经常更高。例如,彩色图像在高和宽2个维度外还有RGB(红、绿、蓝)3个颜色通道。假设彩色图像的高和宽分别是 hh 和 ww (像素),那么它可以表示为一个 3×h×w3×h×w 的多维数组,我们将大小为3的这一维称为通道(channel)维。
多输入通道
卷积层的输入可以包含多个通道,图4展示了一个含2个输入通道的二维互相关计算的例子。
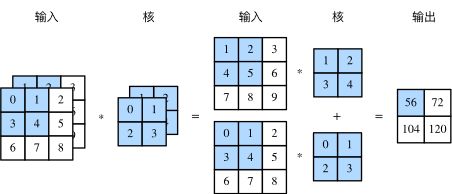
图4 含2个输入通道的互相关计算
假设输入数据的通道数为 cici ,卷积核形状为 kh×kwkh×kw ,我们为每个输入通道各分配一个形状为 kh×kwkh×kw 的核数组,将 cici 个互相关运算的二维输出按通道相加,得到一个二维数组作为输出。我们把 cici 个核数组在通道维上连结,即得到一个形状为 ci×kh×kwci×kh×kw 的卷积核。
多输出通道
卷积层的输出也可以包含多个通道,设卷积核输入通道数和输出通道数分别为 cici 和 coco ,高和宽分别为 khkh 和 kwkw 。如果希望得到含多个通道的输出,我们可以为每个输出通道分别创建形状为 ci×kh×kwci×kh×kw 的核数组,将它们在输出通道维上连结,卷积核的形状即 co×ci×kh×kwco×ci×kh×kw 。
对于输出通道的卷积核,我们提供这样一种理解,一个 ci×kh×kwci×kh×kw 的核数组可以提取某种局部特征,但是输入可能具有相当丰富的特征,我们需要有多个这样的 ci×kh×kwci×kh×kw 的核数组,不同的核数组提取的是不同的特征。
1x1卷积层
最后讨论形状为 1×11×1 的卷积核,我们通常称这样的卷积运算为 1×11×1 卷积,称包含这种卷积核的卷积层为 1×11×1 卷积层。图5展示了使用输入通道数为3、输出通道数为2的 1×11×1 卷积核的互相关计算。
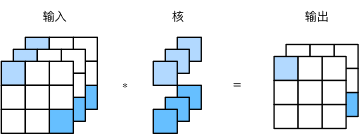
图5 1x1卷积核的互相关计算。输入和输出具有相同的高和宽
1×11×1 卷积核可在不改变高宽的情况下,调整通道数。 1×11×1 卷积核不识别高和宽维度上相邻元素构成的模式,其主要计算发生在通道维上。假设我们将通道维当作特征维,将高和宽维度上的元素当成数据样本,那么 1×11×1 卷积层的作用与全连接层等价。
卷积层与全连接层的对比
二维卷积层经常用于处理图像,与此前的全连接层相比,它主要有两个优势:
一是全连接层把图像展平成一个向量,在输入图像上相邻的元素可能因为展平操作不再相邻,网络难以捕捉局部信息。而卷积层的设计,天然地具有提取局部信息的能力。
二是卷积层的参数量更少。不考虑偏置的情况下,一个形状为 (ci,co,h,w)(ci,co,h,w) 的卷积核的参数量是 ci×co×h×wci×co×h×w ,与输入图像的宽高无关。假如一个卷积层的输入和输出形状分别是 (c1,h1,w1)(c1,h1,w1) 和 (c2,h2,w2)(c2,h2,w2) ,如果要用全连接层进行连接,参数数量就是 c1×c2×h1×w1×h2×w2c1×c2×h1×w1×h2×w2 。使用卷积层可以以较少的参数数量来处理更大的图像。
卷积层的简洁实现
我们使用Pytorch中的nn.Conv2d类来实现二维卷积层,主要关注以下几个构造函数参数:
in_channels (python:int) – Number of channels in the input imag
out_channels (python:int) – Number of channels produced by the convolution
kernel_size (python:int or tuple) – Size of the convolving kernel
stride (python:int or tuple, optional) – Stride of the convolution. Default: 1
padding (python:int or tuple, optional) – Zero-padding added to both sides of the input. Default: 0
bias (bool, optional) – If True, adds a learnable bias to the output. Default: True
池化
二维池化层
池化层主要用于缓解卷积层对位置的过度敏感性。同卷积层一样,池化层每次对输入数据的一个固定形状窗口(又称池化窗口)中的元素计算输出,池化层直接计算池化窗口内元素的最大值或者平均值,该运算也分别叫做最大池化或平均池化。图6展示了池化窗口形状为 2×22×2 的最大池化。
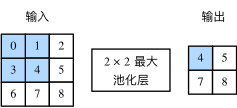
图6 池化窗口形状为 2 x 2 的最大池化
二维平均池化的工作原理与二维最大池化类似,但将最大运算符替换成平均运算符。池化窗口形状为 p×qp×q 的池化层称为 p×qp×q 池化层,其中的池化运算叫作 p×qp×q 池化。
池化层也可以在输入的高和宽两侧填充并调整窗口的移动步幅来改变输出形状。池化层填充和步幅与卷积层填充和步幅的工作机制一样。
在处理多通道输入数据时,池化层对每个输入通道分别池化,但不会像卷积层那样将各通道的结果按通道相加。这意味着池化层的输出通道数与输入通道数相等。
LeNet
Convolutional Neural Networks
使用全连接层的局限性:
图像在同一列邻近的像素在这个向量中可能相距较远。它们构成的模式可能难以被模型识别。
对于大尺寸的输入图像,使用全连接层容易导致模型过大。
*使用卷积层的优势:
卷积层保留输入形状。
卷积层通过滑动窗口将同一卷积核与不同位置的输入重复计算,从而避免参数尺寸过大。
LeNet 模型
LeNet分为卷积层块和全连接层块两个部分。下面我们分别介绍这两个模块。
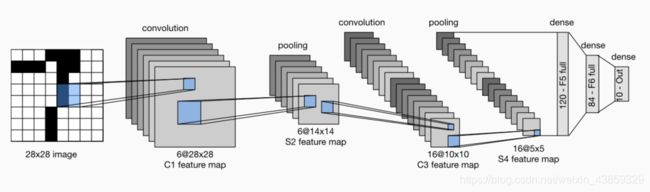
卷积层块里的基本单位是卷积层后接平均池化层:卷积层用来识别图像里的空间模式,如线条和物体局部,之后的平均池化层则用来降低卷积层对位置的敏感性。
卷积层块由两个这样的基本单位重复堆叠构成。在卷积层块中,每个卷积层都使用 5×55×5 的窗口,并在输出上使用sigmoid激活函数。第一个卷积层输出通道数为6,第二个卷积层输出通道数则增加到16。
全连接层块含3个全连接层。它们的输出个数分别是120、84和10,其中10为输出的类别个数。
下面我们通过Sequential类来实现LeNet模型。
可以看到,在卷积层块中输入的高和宽在逐层减小。卷积层由于使用高和宽均为5的卷积核,从而将高和宽分别减小4,而池化层则将高和宽减半,但通道数则从1增加到16。全连接层则逐层减少输出个数,直到变成图像的类别数10。

获取数据和训练模型
下面我们来实现LeNet模型。我们仍然使用Fashion-MNIST作为训练数据集。
总结:
卷积神经网络就是含卷积层的网络。 LeNet交替使用卷积层和最大池化层后接全连接层来进行图像分类。
课后习题:


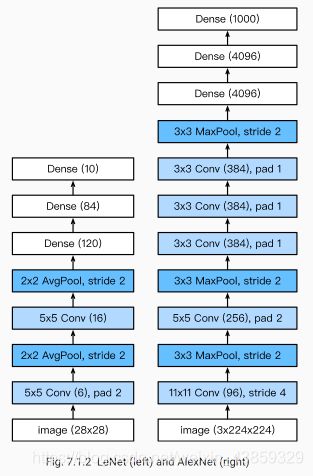
深度卷积神经网络(AlexNet)
LeNet: 在大的真实数据集上的表现并不尽如⼈意。
1.神经网络计算复杂。
2.还没有⼤量深⼊研究参数初始化和⾮凸优化算法等诸多领域。
机器学习的特征提取:手工定义的特征提取函数
神经网络的特征提取:通过学习得到数据的多级表征,并逐级表⽰越来越抽象的概念或模式。
神经网络发展的限制:数据、硬件
AlexNet
首次证明了学习到的特征可以超越⼿⼯设计的特征,从而⼀举打破计算机视觉研究的前状。
特征:
8层变换,其中有5层卷积和2层全连接隐藏层,以及1个全连接输出层。
将sigmoid激活函数改成了更加简单的ReLU激活函数。
用Dropout来控制全连接层的模型复杂度。
引入数据增强,如翻转、裁剪和颜色变化,从而进一步扩大数据集来缓解过拟合。
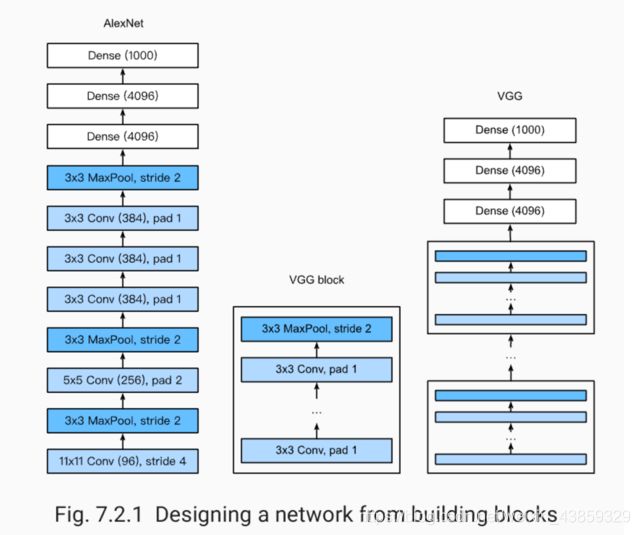
使用重复元素的网络(VGG)
VGG:通过重复使⽤简单的基础块来构建深度模型。
Block:数个相同的填充为1、窗口形状为 3×33×3 的卷积层,接上一个步幅为2、窗口形状为 2×22×2 的最大池化层。
卷积层保持输入的高和宽不变,而池化层则对其减半。
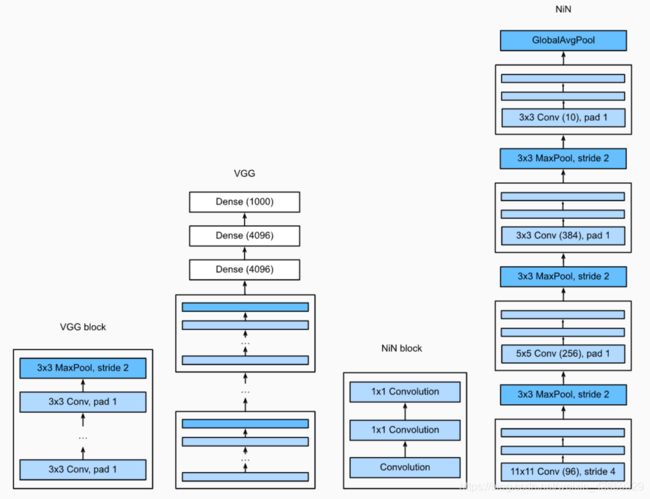
⽹络中的⽹络(NiN)
LeNet、AlexNet和VGG:先以由卷积层构成的模块充分抽取 空间特征,再以由全连接层构成的模块来输出分类结果。
NiN:串联多个由卷积层和“全连接”层构成的小⽹络来构建⼀个深层⽹络。
⽤了输出通道数等于标签类别数的NiN块,然后使⽤全局平均池化层对每个通道中所有元素求平均并直接⽤于分类。
1×1卷积核作用
1.放缩通道数:通过控制卷积核的数量达到通道数的放缩。
2.增加非线性。1×1卷积核的卷积过程相当于全连接层的计算过程,并且还加入了非线性激活函数,从而可以增加网络的非线性。
3.计算参数少
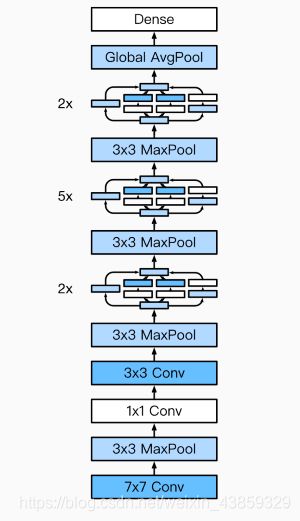
GoogLeNet
由Inception基础块组成。
Inception块相当于⼀个有4条线路的⼦⽹络。它通过不同窗口形状的卷积层和最⼤池化层来并⾏抽取信息,并使⽤1×1卷积层减少通道数从而降低模型复杂度。
可以⾃定义的超参数是每个层的输出通道数,我们以此来控制模型复杂度。

GoogLeNet模型
完整模型结构
参考资料:
http://zh.d2l.ai/chapter_convolutional-neural-networks/conv-layer.html