Caffe Layer Library及理解
Convolution layer
# convolution
layer {
name: "loss1/conv"
type: "Convolution"
bottom: "loss1/ave_pool"
top: "loss1/conv"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
kernel_size: 1
stride:1 # default: stride=1
pad: 1
weight_filler {
# xavier type
type: "xavier"
# gaussian type
#type: "gaussian"
#std: 0.01
}
bias_filler {
type: "constant"
value: 0.2
}
}
}参数:bottom(输入),top(输出),num_output(通道数,卷积的个数),Kernel_size(卷积核的大小),stride(滑动步长),pad(填充),特征输出大小为out_h = image_h + 2*pad_h – kernel_h)/stride_h+ 1,out_w = image_w +2*pad_w – kernel_w)/stride_w + 1。
Deconvolution
layer {
name: "score2"
type: "Deconvolution"
bottom: "score"
top: "score2"
param {
lr_mult: 1
}
convolution_param {
num_output: 21
kernel_size: 4
stride: 2
weight_filler: { type: "bilinear" }
}
}参数与卷积相同,out_h = (in_h - 1) * stride_h + kernel_h,out_w = (in_w - 1) * stride_w + kernel_w。
Dilation Convolution
layer {
name: "conv5_3"
type: "Convolution"
bottom: "conv5_2"
top: "conv5_3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 512
kernel_size: 3
pad: 2
dilation: 2 # Actually pad = dilation
}
}相对卷积层,多了参数dilation,dilation表示hole size,空洞卷积的特性。
Pooling
max pool
layer {
name: "pool1_3x3_s2"
type: "Pooling"
bottom: "conv1_3_3x3"
top: "pool1_3x3_s2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
pad: 1
}
}参数与卷积相近
ave pool
layer {
name: "conv5_3_pool1"
type: "Pooling"
bottom: "conv5_3"
top: "conv5_3_pool1"
pooling_param {
pool: AVE
kernel_size: 60
stride: 60
}
}Upsample
layer {
name: "upsample4"
type: "Upsample"
bottom: "conv5_1_D"
top: "pool4_D"
bottom: "pool4_mask"
upsample_param {
scale: 2
upsample_w: 60
upsample_h: 45
}
}参数增加upsample_w和upsample_h,如果该层设定了该参数则输出特征图大小为upsample_w*upsample_h。
Eltwise
layer {
bottom: "conv4_3"
bottom: "res_conv4"
top: "fusion_res_cov4"
name: "fusion_res_cov4"
type: "Eltwise"
eltwise_param { operation: SUM } # PROD SUM MAX
} 将两个特征特征加和,参数包含两个输入bottom和一个输出top。
Concat
layer {
name: "inception_4a/output"
type: "Concat"
bottom: "inception_4a/1x1"
bottom: "inception_4a/3x3"
bottom: "inception_4a/5x5"
bottom: "inception_4a/pool_proj"
top: "inception_4a/output"
}在使模型变宽时,常需要把多个分支合并起来作为后续层的输入,参数包括多个输入bottom(输入至少为2)和一个输出。
InnerProduct
layer {
name: "imagenet_fc"
type: "InnerProduct"
bottom: "fc7"
top: "imagenet_fc"
param {
lr_mult: 1
decay_mult: 250
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: ${NUM_LABELS}
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0.7
}
}
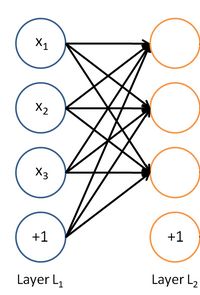
}inner_product_layer也即全连接层,如下示意图,每个输出都连接到所有的输入。
Dropout
layer {
name: "drop6"
type: "Dropout"
bottom: "fc6"
top: "fc6"
dropout_param {
dropout_ratio: 0.5
}
}参数dropout_ratio即为一个神经元被保留的概率。
Batch Normaliztion
# BatchNorm2
layer {
name: "BatchNorm2"
#type: "LRN"
type: "BatchNorm" include { phase: TRAIN}
bottom: "Concat1"
top: "BatchNorm2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
batch_norm_param {
use_global_stats: false
}
}# BatchNorm
layer {
name: "bn3"
type: "BatchNorm"
bottom: "conv3"
top: "bn3"
param {
lr_mult: 0
}
param {
lr_mult: 0
}
param {
lr_mult: 0
}
}# BN
layer {
name: "spp3_bn"
type: "BN"
bottom: "conv_spp_3_ave_pool"
top: "spp3_bn"
param {
lr_mult: 1
decay_mult: 0
}
param {
lr_mult: 1
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
bn_param {
slope_filler {
type: "constant"
value: 1
}
bias_filler {
type: "constant"
value: 0
}
frozen: true
momentum: 0.95
}
}LRN
layer {
name: "norm1"
type: "LRN"
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}caffe中有一个LRN 层,全称为Local Response Normalization,即局部响应归一化层。
该层参数有:
normal_region:选择对相邻通道间归一化还是对通道内的空间区域归一化,默认为ACROSS_CHANNELS,
即通道间归一化;
local_size:两种表示,(1):通道间归一化是表示求和的通道数;(2):通道内归一化示表示归一化操作的
区间的边长;local_size的默认值为5;
alpha:缩放因子,默认值为1;
beta:指数项,默认值为5;
局部响应归一化层完成一种“临近抑制”操作,对局部输入区域归一化。
在通道间归一化模式中,局部区域范围在相邻通道间,但没有空间上的扩张(即尺寸为local_sizeX1X1);
在通道内归一化模式中,局部区域范围在当前通道内,有空间上的扩张(即1XlocalXloacl);
对输入值都将除以;其中n为局部尺寸大小:local_size;alpha和beta前面已经经定义。
求和将在当前处于中间的位置的局部区域内进行(如有必要将进行补零);
Scale
layer {
name: "slice"
type: "Slice"
bottom: "input"
top: "output1"
top: "output2"
top: "output3"
top: "output4"
slice_param {
axis: 1
slice_point: 1
slice_point: 3
slice_point: 4
}
}N*5*H*W
,tops输出的维度分别为
N*1*H*W
N*2*H*W
N*1*H*W
N*1*H*W
。
这里需要注意的是,如果有slice_point,slice_point的个数一定要等于top的个数减一。
axis表示要进行分解的维度。
slice_point的作用是将axis按照slic_point 进行分解。
slice_point没有设置的时候则对axis进行均匀分解。
label interpolation(差值)
Threshold
layer {
name: "threshold"
type: "Threshold"
bottom: "soft_prob_s1"
top: "threshold"
threshold_param {
threshold: 1e-36
}
}SigmoidGateLayer
layer {
name: "gate"
type: "SigmoidGate"
bottom: "soft_prob_s1"
top: "gate"
gate_param {
threshold: 0.5
}
}ReLU
layer {
name: "relu1_1"
type: "ReLU"
bottom: "conv1_1"
top: "conv1_1"
}PReLU
layer {
name: "relu6"
bottom: "fc6"
top: "relu6"
type: "PReLU"
prelu_param {
filler {
type: "constant"
value: 0.3
}
channel_shared: false
}
}interpolation
layer{
bottom:"input"
top:"output"
name:"interp_layer"
type:"Interp"
interp_param{
shrink_factor:4
zoom_factor:3
pad_beg:0
pad_end:0
}#读入图片的高度和宽度
height_in_ = bottom[0]->height();
width_in_ = bottom[0]->width();
#根据设定参数调整后的高度,pad_beg,pad_end只能设置成0及0以下。
height_in_eff_ = height_in_ + pad_beg_ + pad_end_;
width_in_eff_ = width_in_ + pad_beg_ + pad_end_;
#interp的顺序是先缩小,再放大
height_out_ = (height_in_eff_ - 1) / shrink_factor + 1;
width_out_ = (width_in_eff_ - 1) / shrink_factor + 1;
height_out_ = height_out_ + (height_out_ - 1) * (zoom_factor - 1);
width_out_ = width_out_ + (width_out_ - 1) * (zoom_factor - 1);参考:
https://blog.csdn.net/grief_of_the_nazgul/article/details/62043799