最小生成树--Prim算法和Kruskal算法
1、最小生成树:一个有 n 个结点的连通图的生成树是原图的极小连通子图,且包含原图中的所有 n 个结点,并且有保持图连通的最少的边。
最小生成树包括三个重要的性质:
最小:边的权重和最小
生成:最小生成树是从原树生成的,包含所有顶点,|v|-1条边都在图里
树:最小生成树还必须是一棵树,无回路,V个顶点一定有|v|-1条边。
最小生成树是连通的,而连通的图一定有一个最小生成树,这是充分必要的。
2、贪心算法:无论是哪一种算法都属于贪心算法,所谓贪心算法,就是从最好的开始收纳,直到满足要求。
在这个问题当中,使用贪心算法计算最小生成树需要注意三点:
(1)、只能用图中有的边;
(2)、只能用掉|v|-1条边;
(3)、不能有回路。
3、Prim算法:从一个根节点开始,让小树慢慢的长大。
prim算法的例子:
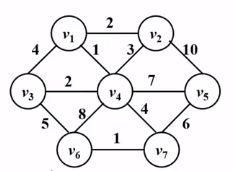
寻找最小生成树的步骤:
(1)这里选择V1为根结点,将v1收纳进来;
(2)然后选择一条最小的边,这条边满足在图中,并且和v1相连,显然,选择E(v1->v4),将v4收纳进来;
(3)然后选择跟V1.v4相关的边中最小的,并且不能构成回路。相关的边包括了与v1相连的边和与v4相连的边,这里将v1->v2收进来,将v4->v3也收进来,其次最小的边为v4->v2,但是收进来会构成回路所以不能收进来,v1->v3同理不能收进来。
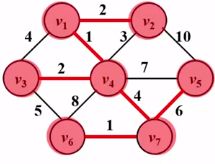
(4)以此类推,然后将v4->v7收进来 ,将v7->v6收进来,将v7->v5收进来,完成了最小生成树如图红色部分:
代码实现:
Vertex FindMinDist( MGraph Graph, WeightType dist[] )
{ /* 返回未被收录顶点中dist最小者 */
Vertex MinV, V;
WeightType MinDist = INFINITY;
for (V=0; VNv; V++) {
if ( dist[V]!=0 && dist[V]/* 若V未被收录,且dist[V]更小 */
MinDist = dist[V]; /* 更新最小距离 */
MinV = V; /* 更新对应顶点 */
}
}
if (MinDist < INFINITY) /* 若找到最小dist */
return MinV; /* 返回对应的顶点下标 */
else return ERROR; /* 若这样的顶点不存在,返回-1作为标记 */
}
int Prim( MGraph Graph, LGraph MST )
{ /* 将最小生成树保存为邻接表存储的图MST,返回最小权重和 */
WeightType dist[MaxVertexNum], TotalWeight;
Vertex parent[MaxVertexNum], V, W;
int VCount;
Edge E;
/* 初始化。默认初始点下标是0 */
for (V=0; VNv; V++) {
/* 这里假设若V到W没有直接的边,则Graph->G[V][W]定义为INFINITY */
dist[V] = Graph->G[0][V];
parent[V] = 0; /* 暂且定义所有顶点的父结点都是初始点0 */
}
TotalWeight = 0; /* 初始化权重和 */
VCount = 0; /* 初始化收录的顶点数 */
/* 创建包含所有顶点但没有边的图。注意用邻接表版本 */
MST = CreateGraph(Graph->Nv);
E = (Edge)malloc( sizeof(struct ENode) ); /* 建立空的边结点 */
/* 将初始点0收录进MST */
dist[0] = 0;
VCount ++;
parent[0] = -1; /* 当前树根是0 */
while (1) {
V = FindMinDist( Graph, dist );
/* V = 未被收录顶点中dist最小者 */
if ( V==ERROR ) /* 若这样的V不存在 */
break; /* 算法结束 */
/* 将V及相应的边收录进MST */
E->V1 = parent[V];
E->V2 = V;
E->Weight = dist[V];
InsertEdge( MST, E );
TotalWeight += dist[V];
dist[V] = 0;
VCount++;
for( W=0; WNv; W++ ) /* 对图中的每个顶点W */
if ( dist[W]!=0 && Graph->G[V][W]/* 若W是V的邻接点并且未被收录 */
if ( Graph->G[V][W] < dist[W] ) {
/* 若收录V使得dist[W]变小 */
dist[W] = Graph->G[V][W]; /* 更新dist[W] */
parent[W] = V; /* 更新树 */
}
}
} /* while结束*/
if ( VCount < Graph->Nv ) /* MST中收的顶点不到|V|个 */
TotalWeight = ERROR;
return TotalWeight; /* 算法执行完毕,返回最小权重和或错误标记 */
} 4、kruskal算法:如果图比较稀疏,就可以选择kruskal算法,在不形成回路的情况下逐渐收纳最小边,直到|v|-1条边被收纳进去就结束。它的时间复杂度为:T = O( |E| log |E| )
kruskal算法思路:先构造一个只含 n 个顶点,而边集为空的子图,若将该子图中各个顶点看成是各棵树上的根结点,则它是一个含有 n 棵树的一个森林。之后,从网的边集 E 中选取一条权值最小的边,若该条边的两个顶点分属不同的树,则将其加入子图,也就是说,将这两个顶点分别所在的两棵树合成一棵树;反之,若该条边的两个顶点已落在同一棵树上,则不可取,而应该取下一条权值最小的边再试之。依次类推,直至森林中只有一棵树,也即子图中含有 n-1条边为止。
代码实现:
typedef Vertex ElementType; /* 默认元素可以用非负整数表示 */
typedef Vertex SetName; /* 默认用根结点的下标作为集合名称 */
typedef ElementType SetType[MaxVertexNum]; /* 假设集合元素下标从0开始 */
void InitializeVSet( SetType S, int N )
{ /* 初始化并查集 */
ElementType X;
for ( X=0; X1;
}
void Union( SetType S, SetName Root1, SetName Root2 )
{ /* 这里默认Root1和Root2是不同集合的根结点 */
/* 保证小集合并入大集合 */
if ( S[Root2] < S[Root1] ) { /* 如果集合2比较大 */
S[Root2] += S[Root1]; /* 集合1并入集合2 */
S[Root1] = Root2;
}
else { /* 如果集合1比较大 */
S[Root1] += S[Root2]; /* 集合2并入集合1 */
S[Root2] = Root1;
}
}
SetName Find( SetType S, ElementType X )
{ /* 默认集合元素全部初始化为-1 */
if ( S[X] < 0 ) /* 找到集合的根 */
return X;
else
return S[X] = Find( S, S[X] ); /* 路径压缩 */
}
bool CheckCycle( SetType VSet, Vertex V1, Vertex V2 )
{ /* 检查连接V1和V2的边是否在现有的最小生成树子集中构成回路 */
Vertex Root1, Root2;
Root1 = Find( VSet, V1 ); /* 得到V1所属的连通集名称 */
Root2 = Find( VSet, V2 ); /* 得到V2所属的连通集名称 */
if( Root1==Root2 ) /* 若V1和V2已经连通,则该边不能要 */
return false;
else { /* 否则该边可以被收集,同时将V1和V2并入同一连通集 */
Union( VSet, Root1, Root2 );
return true;
}
}
/*并查集定义*/
void PercDown( Edge ESet, int p, int N )
{ /* 改编代码4.24的PercDown( MaxHeap H, int p ) */
/* 将N个元素的边数组中以ESet[p]为根的子堆调整为关于Weight的最小堆 */
int Parent, Child;
struct ENode X;
X = ESet[p]; /* 取出根结点存放的值 */
for( Parent=p; (Parent*2+1)2 + 1;
if( (Child!=N-1) && (ESet[Child].Weight>ESet[Child+1].Weight) )
Child++; /* Child指向左右子结点的较小者 */
if( X.Weight <= ESet[Child].Weight ) break; /* 找到了合适位置 */
else /* 下滤X */
ESet[Parent] = ESet[Child];
}
ESet[Parent] = X;
}
/* 边的最小堆定义*/
void InitializeESet( LGraph Graph, Edge ESet )
{ /* 将图的边存入数组ESet,并且初始化为最小堆 */
Vertex V;
PtrToAdjVNode W;
int ECount;
/* 将图的边存入数组ESet */
ECount = 0;
for ( V=0; VNv; V++ )
for ( W=Graph->G[V].FirstEdge; W; W=W->Next )
if ( V < W->AdjV ) { /* 避免重复录入无向图的边,只收V1
ESet[ECount].V1 = V;
ESet[ECount].V2 = W->AdjV;
ESet[ECount++].Weight = W->Weight;
}
/* 初始化为最小堆 */
for ( ECount=Graph->Ne/2; ECount>=0; ECount-- )
PercDown( ESet, ECount, Graph->Ne );
}
int GetEdge( Edge ESet, int CurrentSize )
{ /* 给定当前堆的大小CurrentSize,将当前最小边位置弹出并调整堆 */
/* 将最小边与当前堆的最后一个位置的边交换 */
Swap( &ESet[0], &ESet[CurrentSize-1]);
/* 将剩下的边继续调整成最小堆 */
PercDown( ESet, 0, CurrentSize-1 );
return CurrentSize-1; /* 返回最小边所在位置 */
}
int Kruskal( LGraph Graph, LGraph MST )
{ /* 将最小生成树保存为邻接表存储的图MST,返回最小权重和 */
WeightType TotalWeight;
int ECount, NextEdge;
SetType VSet; /* 顶点数组 */
Edge ESet; /* 边数组 */
InitializeVSet( VSet, Graph->Nv ); /* 初始化顶点并查集 */
ESet = (Edge)malloc( sizeof(struct ENode)*Graph->Ne );
InitializeESet( Graph, ESet ); /* 初始化边的最小堆 */
/* 创建包含所有顶点但没有边的图。注意用邻接表版本 */
MST = CreateGraph(Graph->Nv);
TotalWeight = 0; /* 初始化权重和 */
ECount = 0; /* 初始化收录的边数 */
NextEdge = Graph->Ne; /* 原始边集的规模 */
while ( ECount < Graph->Nv-1 ) { /* 当收集的边不足以构成树时 */
NextEdge = GetEdge( ESet, NextEdge ); /* 从边集中得到最小边的位置 */
if (NextEdge < 0) /* 边集已空 */
break;
/* 如果该边的加入不构成回路,即两端结点不属于同一连通集 */
if ( CheckCycle( VSet, ESet[NextEdge].V1, ESet[NextEdge].V2 )==true ) {
/* 将该边插入MST */
InsertEdge( MST, ESet+NextEdge );
TotalWeight += ESet[NextEdge].Weight; /* 累计权重 */
ECount++; /* 生成树中边数加1 */
}
}
if ( ECount < Graph->Nv-1 )
TotalWeight = -1; /* 设置错误标记,表示生成树不存在 */
return TotalWeight;
} 5、两个算法的比较:
(1)前者收集的是顶点,适合稠密图,而后者收集的是边适合稀疏图;
(2)Kruskal算法在效率上要比Prim算法快,因为Kruskal只需要对权重边做一次排序,而Prim算法则需要做多次排序。尽管Prim算法每次做的算法涉及的权重边不一定会涵盖连通图中的所有边,但是随着所使用的排序算法的效率的提高,Kruskal算法和Prim算法之间的差异将会清晰的显性出来。