Wormhole、MergeDelta优化
mergedelta优化点
1.不带分区的全量hive表,如果wormhole传输数据量为0,即没有更新数据时,不需要进行merge操作
2.优化hive log输出
---------------------------------------------------------------------------------------------------------------------------------------
说明:经统计, 目前全量且wormhole传输量为0的任务实例,一天大概在350个左右。一般merge操作需要5-20分钟,数据量越大越耗时,集群忙碌时越耗时(merge是个MapReduce程序)。对于全量表,如果没有更新数据,执行merge操作是多余的,因此可以优化掉这一过程,能节约时间和集群资源。
方案:在运行完wormhole时,如果是全量表,获取delta表对应hdfs目录下文件大小,如果是0则直接返回即可。有一个问题,由于wormhole一般使用LZO格式写入,使得即使传输数据量为0,在目录下然后会产生多个LZO文件,虽然里面没有实际数据但每一个文件仍会占用40字节大小,导致即使没数据目录下文件大小还是不为0,因此需要修改wormhole相关代码来配合此优化。
wormhole优化点
1.重构HdfsWriter;延迟建立文件,有数据要写入hdfs时才创建文件;调整建LZO索引、add partition失败重试逻辑。
2.创建缓存行时,允许指定包含的字段数;从mysql读取时,根据ResultSet包含的字段数创建相应大小的行
3.重构MysqlReader;分段时存储所有分段完整SQL优化为只需存储上下限值;使用PreparedStatement替代Statement
4.解决创建LZO索引时因为存在.tmp文件报错退出,任务重跑依旧无法成功的问题
5.调整zebra连接参数(主要是调整底层c3p0连接池相关参数)
6.优化日期时间类型数据格式化的逻辑,避免重复计算
7.记录读取行数的变量的同步由synchronized改成AtomicLong
8.为reader、writer的线程池设定名称,遇到问题时方便定位
9. HiveReader、MysqlReader、MysqlWriter清理历史遗留参数,精简代码
10.JVM启动参数调整
---------------------------------------------------------------
每个优化点相应的说明:
下面提到的测试任务是一个约5000万数据量的mysql2hive任务。
第1点:延迟建立文件主要是配合mergedelta的优化,当传输数据为0时不会再生成任何文件。建LZO索引、add partition失败原先重试次数为10次,重试太多次没必要,已调整为3次,原先10秒钟重试一次,调整为5秒。
第2点:wormhole读写时每一行数据都会存入一个1024大小的String数组,对于字段数少的传输任务会浪费大量空间。优化后,测试任务String[]的堆占用率从50+%下降到了20%左右。
第3点:mysql分段读取时,原先会将所有分段sql完整的语句存储起来,当数据量大时可能存储上万个sql语句,例如select .... from table where id >= x and where id < y这种sql语句,优化为只存储x和y这2个范围值,减少空间占用。由于目前采用1W条记录为一个分段进行读取,当表中数据量较大时,会执行非常多次where id >= x and where id < y 这种sql语句,目前每次都是使用Statement来执行,分段读取时,使用预编译的PreparedStatement可以提高效率。
第4点:创建LZO索引时会检查目录下是否存在.tmp临时文件,如果存在则会报错退出,一般出现在分库分表的任务中。由于.tmp文件一直存在,即使重跑仍然会在建LZO索引时报错。因此增加了自动删除.tmp文件的逻辑,这样重跑时就不会再检测到上一次的.tmp文件。
第5点:zebra默认使用c3p0连接池,数据库会有个默认参数,如DWOutput的c3p0参数如下:
initialPoolSize=5&maxPoolSize=20&minPoolSize=5&idleConnectionTestPeriod=60&acquireRetryAttempts=50&acquireRetryDelay=300&
maxStatements=0&numHelperThreads=6&maxAdministrativeTaskTime=5&preferredTestQuery=SELECT 1&checkoutTimeout=1000&
maxStatementsPerConnection=100
部分数据库可能修改了默认参数,为了统一,在wormhole中获取连接时进行了统一的调整设置如下。
initialPoolSize=4,maxPoolSize=10,minPoolSize=4,acquireRetryAttempts=5,acquireRetryDelay=5000,maxStatements=20,maxStatementsPerConnection=5
mysql非分段读,只会有1个线程读,分段情况大部分是2个线程,少量大数据量任务为4个线程,因此initialPoolSize、minPoolSize调整为4,mysql读线程最大限制是10,故maxPoolSize调整为10。在0点高峰期,mysql连接获取经常会失败,因此调整了获取连接失败相关的参数acquireRetryAttempts和acquireRetryDelay。maxStatements和maxStatementsPerConnection是配合PreparedStatement的性能优化。
第6点:每一行读取从sqlserver或mysql读取的数据,如果是时间日期类型,则需要格式化,比如数据库本身可能精确到毫秒需要忽略掉毫秒值。原先的代码逻辑是每一次读取得到ResultSet后都需要计算一次一行包含的字段数,以及其中包含的时间日期字段各有哪些,然后在写入之前进行替换。对于分段读取情况下,每次分段读都会重复计算,优化为只在第一次得到ResultSet后计算一次即可。
第7点:wormhole的reader、writer线程数大概10个左右,此量级的多线程竞争时,CAS性能高于synchronized方式。
第8点:默认情况下,线程池中的线程名称为pool-x-thread-y,分别为reader、writer定义名称方便排查问题。
第9点:HiveReader支持3种mode:READ_FROM_LOCAL、READ_FROM_HIVESERVER、READ_FROM_HDFS,目前后两种已经完全废弃,删除了以hive server方式读取hive数据的相关代码逻辑。MysqlReader原先支持MysqlLoad方式从特定路径load数据,属于历史遗留,删除MysqlLoad相关2个类,清理了相关的判断逻辑。MysqlWriter也清理了无用参数和load相关的逻辑。
第10点:调整的JVM参数如下(jdk1.7 64bit为前提):
原先的参数为-Xms1g -Xmx4g -Xmn256m -Xss2048k -XX:PermSize=128m -XX:MaxPermSize=512m
新生代大小原先固定为256M,由于wormhole绝大部分是临时对象,YGC非常频繁(部分数据量大的任务1秒10次YGC)。老年代实际上占用空间并不多,我认为最大堆设置为4G没什么意义,因此调整了新生代和老年代的比例为1:1(此处较保守,实际新生代比例可以更高),默认值为2:1即新生代占用三分之一。
另外,永久代空间原先设置为初始128M,最大512M也不合理,据测试,永久代占用空间一般不会超过50M,因此调整为初始64M,最大128M。
调整后为-Xms512m -Xmx2g -Xss2048k -XX:NewRatio=1 -XX:PermSize=64m -XX:MaxPermSize=128m ,调整后测试任务的YGC次数为原先的25%左右,GC耗时为原先20%以下
UseBiasedLocking:偏向锁设置,默认开启,wormhole会包含多个reader、writer,线程竞争较多,不适宜开启偏向锁,将其禁用。
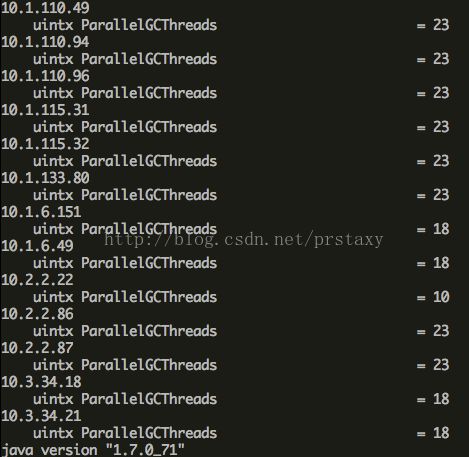
ParallelGCThreads:GC线程数,默认值和CPU的核数有关,各执行机默认值如下面图,调整后统一改成了4。由于执行机上会运行多个wormhole进程,如果每个进程包含GC线程太多会占用较多CPU。
最终JVM参数为:
-Xms512m -Xmx2g -XX:NewRatio=1 -Xss2048k -XX:PermSize=64m -XX:MaxPermSize=128m -XX:ParallelGCThreads=4 -XX:-UseBiasedLocking