无向图广度优先遍历 并判断这个图是否是树
无向图广度优先遍历 并判断这个图是否是树
首先要遍历图, 我们就要创建一个图
再进行广度优先遍历
再判断是不是树
一.创建一个图
1. 准备工作
在小学二年级学离散的时候我们都知道,图上结点之间的关系可以用邻接矩阵来表示
因此我们也可以用邻接矩阵来建立各个节点之间的联系
我采用的方法是将这个图封装成一个 struct 结点
这个邻接矩阵采用二维数组的方法来储存
其中这个图中需要储存每个结点的数据,邻接矩阵,顶点数,同时记录边数
之前的准备工作除了封装这个图结点以外
我们还要设定两个数组
一个用来记录点是否被访问过
一个用来记录边是否被访问过
#define Max 100
int v_visited[Max]={0}; //标记结点是否被访问过
int a_visited[Max][Max]={0}; //标记边是否被访问过
struct Graph
{
char a[Max]; //数据
int arcs[Max][Max]; //邻接矩阵
int vexnum; //顶点数
int anum; //记录边数
};
这里图中的每个结点的数据我们全部储存在 char a[]中,提取结点数据时直接输出相应结点对应下表的子符就行了
比如 V1 结点,对应的数据就是 a[1];
2.创建图的函数
2.1首先我们要输入这个图共有多少个结点,方便后面输入邻接矩阵
2.2输入邻接矩阵确定结点之间的关系
2.3按 V1到 Vn 输入数据,将这个数据传入 char a[ ]中
void CreateGraph(Graph *&graph)//创造邻接矩阵建立关系
{
int i,j;
cout<<"输入图的顶点数"<<endl;
cin>>graph->vexnum;//给的信息是图的顶点数a,则矩阵就是aXa的矩阵
graph->anum=0; //边数初始化
cout<<"输入邻接矩阵"<<endl;
for(i=1;i<=graph->vexnum;i++)
{
for(j=1;j<=graph->vexnum;j++)
{
cin>>graph->arcs[i][j];//输入各个信息 0/1
}
}
cout<<"按V1到Vn输入结点数据"<<endl;
for (int i = 1; i <= graph->vexnum; i++)
cin>>graph->a[i];
}
注意这里的图结点 graph 是引用,我们在后面还要用这个节点的引用
不然这个函数就没用了,这个和之前的二叉树一个道理
二.广度优先遍历
2.1
广度优先遍历的核心其实就是层次遍历,但又有些不同
在之前的层次遍历时我们用到了队列
所以在这次广度优先遍历我们也使用队列
那这个队列里面存的是什么呢?
是每一层的结点,每访问完一个结点,我们就出队这个结点,再把他的邻接点入队,也就是这两个结点有边,而且这个邻接点是未被访问过的
因此这个入队的判断条件就是if(graph->arcs[d][i] && !v_visited[i])
再进行后面的访问操作
这个函数传入的参数为 graph 结点,同样是引用
另一个参数是 结点,这里的结点我们用 int 型的 v,意思是第 v 个结点。比如 v 是 1,那传入的结点就是 v1结点
2.2
在准备工作的时候,我们有一个数据 int v_visited[Max]={0};
这个是用来记录结点是否被访问过,输出就代表被访问过了,如果以访问,这个值就变成 1
比如第 v 个结点被访问过了,那么 v_visited[ v ] = 1
void BFS(Graph *&graph, int v) //子图的广度优先遍历
{
queue<int> Q;
cout<<graph->a[v]<<" ";
v_visited[v]=1;
Q.push(v);
while(!Q.empty())
{
int d=Q.front();
Q.pop();
for(int i=1;i<=graph->vexnum;i++)
{
if(graph->arcs[d][i] && !v_visited[i])
{
cout<<graph->a[i]<<" ";
v_visited[i]=1;
Q.push(i);
}
}
}
}
举个例子
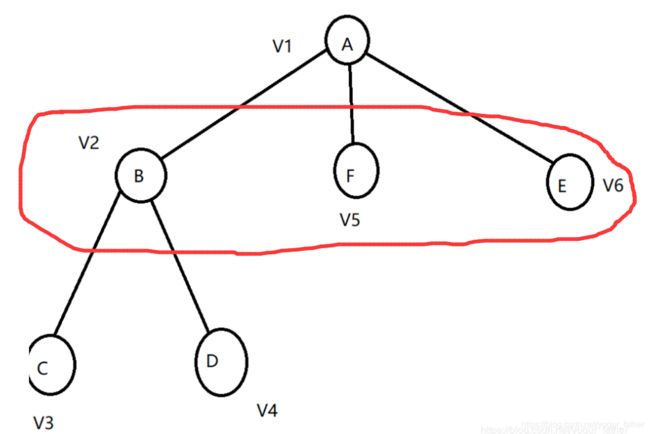
当我们遍历完V1,该到 v2 的时候,队列里的情况应该是

访问完V2,接下来我们要入队的应该是 v3,v4,因此队列的情况应该是
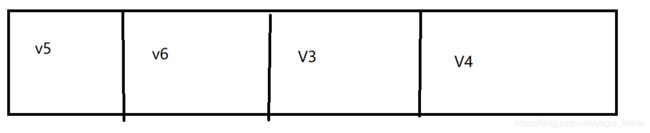
虽然v1 也是v2的邻接点,但v1 已经被方问过了
那接下来就该对V5访问,以此类推
2.3
仔细看的话你会发现我在这个函数后面写了一个注释
//子图的广度优先遍历
为什么这么说
因为你会发现如果这个图是个非连通图的话,就只能遍历一个子图,剩下的部分不能遍历到
因此我们就要写一个循环,先把他们所有的点都 未被访问 化,也就是把 v_visited[ ]全弄成0
再写一个循环,把每个结点都遍历一次,如果一个结点没有被访问过(非连通图中,第二个子图和第一个子图没有联系,也就不能北方问到),就对他进行深度遍历
这样我们就把每个子图都访问到了
void travel_bfs(Graph *&graph) //完整图的广度优先遍历
{
for (int i=1; i<=graph->vexnum; i++)
v_visited[i]=0;
for (int i=1; i<=graph->vexnum; i++)
{
if(!v_visited[i])
BFS(graph,i);
}
}
这样他才是一个完整的广度优先遍历
主函数只调用这个travel_bfs就行了
三.用广度优先遍历判断这个图是不是树
3.1
小学二年级我们在离散课上又学过如何判断一个图是不是树
如果一个图的 边 = 结点树 - 1,那么他就是树
因此我们要来求这个图的边
在广度遍历的函数中,我们发现只要两个结点之间有边 ,我们就给 graph 中的 anum 数加一
所以这个函数和广度优先遍历的内容差不多,只是稍有差异
void BFS_tree(Graph *&graph,int v) //子图的广度优先遍历 求边数
{
queue<int> Q;
Q.push(v);
while(!Q.empty())
{
int w=Q.size();
for(int i=1;i<=w;i++) //i 是每层的节点数
{
int d=Q.front();
Q.pop();
for(int j=1;j<=graph->vexnum;j++)
{
if(graph->arcs[d][j] && !a_visited[d][j]&&!a_visited[j][d])
{
Q.push(j);
a_visited[d][j]=1;
a_visited[j][d]=1;
(graph->anum)++;
}
}
}
}
}
在准备工作中,我们还设定了一个记录边是否被访问的数据
在判定条件那里,我们改成了if(graph->arcs[d][j] && !a_visited[d][j]&&!a_visited[j][d])
如果两个结点之间有边,而且这个边都没有被访问过
这里没有被访问过的意思是 v 到 i 没有访问,i 到 v 也没有被访问过
这样就避免了边重复计算的情况
至于为什么不用if(graph->arcs[d][i] && !v_visited[i])的判断方法了
我们来举个例子
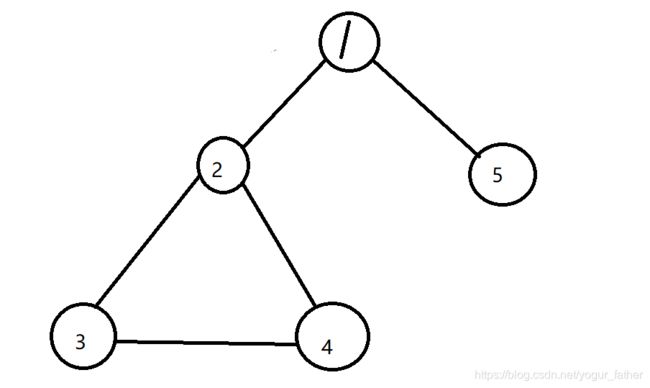
1 ,2, 5 遍历完了,该遍历3 ,4了
这个时候 3-4 有边,而且4未被访问
3-4边被记录
这时候到4
4-3有边,但是3被访问过,而且这条边也被记录过,合理
但是4-2有边,而且这个边没有被记录,但 2 被访问过,这样4-2边就不能被记录,从而导致计算边数时少算了一条边
但是判断条件if(graph->arcs[d][j] && !a_visited[d][j]&&!a_visited[j][d])就避免了这样的问题
结点2虽然被访问过,但是4-2边没有被访问过,因此这条边可以记录
3.2
同样上面那个函数只是子图的遍历求边
我们还需要对整个图进行遍历
void Anum(Graph *&graph) //完整图的边数
{
for (int i=1; i<=graph->vexnum; i++)
v_visited[i]=0;
for (int i=1; i<=graph->vexnum; i++)
{
if(!v_visited[i])
BFS_tree(graph,i);
}
}
3.3
最后这个函数我们要来对这个图是否是数来进行判断
已知边数,节点数
用小学二年级的离散知识来判断是否是数
bool istree(Graph *&graph) //判断是否为树
{
Anum(graph);
cout<<"这个图的边数为 :";
cout<<graph->anum<<endl;
if(graph->anum==graph->vexnum-1)
cout<<"这个图是树";
else
cout<<"这个图不是树";
}
在这个函数中我加了一个输出边数的语句
四.主函数
我们用节点创建的图,需要向系统申请一个空间
这里用到malloc函数,用来申请空间
同时要用到头文件库#include
int main()
{
Graph *graph;
graph=(Graph*)malloc(sizeof(Graph));
CreateGraph(graph);
cout<<"遍历结果是 : "<<endl;
travel_bfs(graph);cout<<endl;
istree(graph);
free(graph);
}
最后记得把这个空间释放掉,用free()函数
五.完整代码
#include六.测试结果
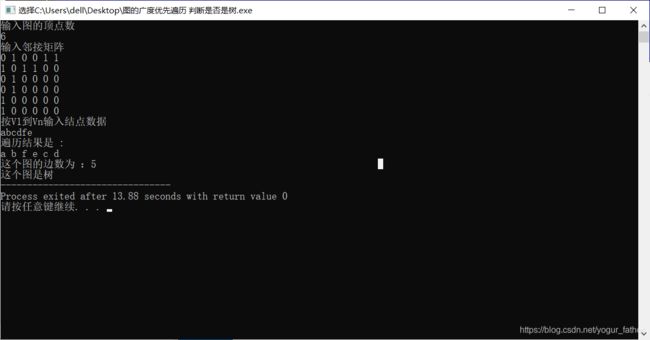
1. 树

邻接矩阵
0 1 0 0 1 1
1 0 1 1 0 0
0 1 0 0 0 0
0 1 0 0 0 0
1 0 0 0 0 0
1 0 0 0 0 0
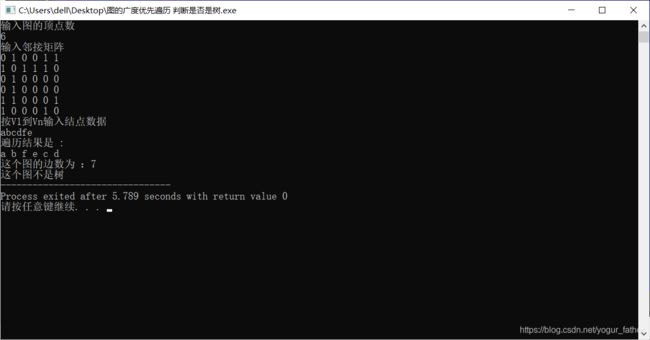
2.不是树
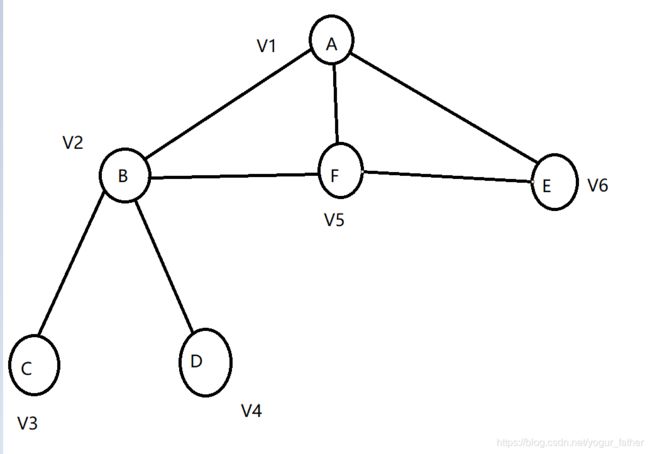
邻接矩阵
0 1 0 0 1 1
1 0 1 1 1 0
0 1 0 0 0 0
0 1 0 0 0 0
1 1 0 0 0 1
1 0 0 0 1 0
3.非连通图
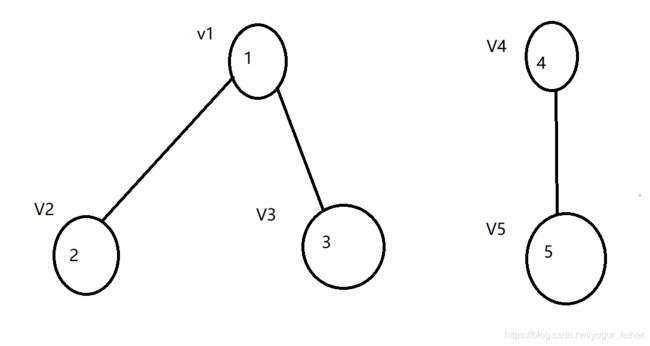
邻接矩阵
0 1 1 0 0
1 0 0 0 0
1 0 0 0 0
0 0 0 0 1
0 0 0 1 0

到这里,广度优先算法就介绍完了
图还有一种叫深度优先算法,我的上一篇博客也介绍了
深度优先算法
除了广度优先算法和深度优先算法那里不一样外,剩下的都是一样的
本来想一样的部分我直接发个链接,我就不再写重复的了,但是后来想了一下,要我看这篇博客,我都懒得再点开那个链接,后来就索性把重复的也写上去了,哈哈哈哈哈哈