自动化特征工程(featuretools)
一、特征是什么?
在机器学习中,特征可以描述为解释现象发生的一组特点。当这些特点转换为一些可测量的形式时,它们就称作特征。
二、特征工程
有这么一句话在业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
特征工程可以简单定义为从数据集的已有特征创建新特征的过程。
其本质是一项工程活动,目的是最大限度地从原始数据中提取特征以供算法和模型使用
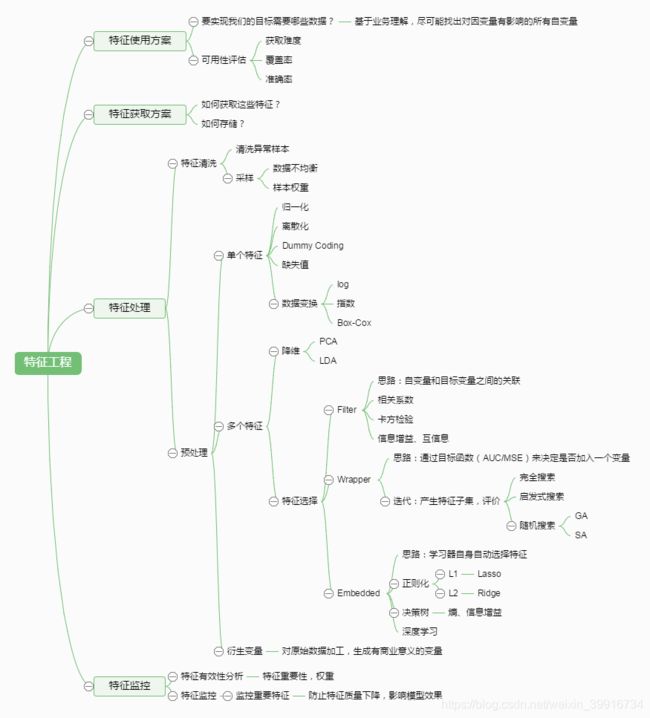
三、特征工程必要性
一个预测模型的性能很大程度上取决于训练该模型的数据集的特征质量。
如果能创建新特征来帮助向模型提供有关目标变量的更多信息,那么它的性能将会提升。
因此,当数据集中没有足够有用特征时,我们必须依靠特征工程。
四、Featuretools简介
Featuretools是一个用于执行自动特征工程的开源库,旨在快速推进特征生成过程,从而有更多时间专注于机器学习模型构建的其他方面。
三个主要组件:
· 实体Entities
实体可看作是Pandas中数据帧的表征,多个实体的集合称为实体集Entityset。
· 深度特征合成Deep Feature Synthesis
深度特征合成(DFS)与深度学习无关。作为一种特征工程方法,它实际上是Featuretools库的核心。
它支持从单个数据帧和多个数据帧中创建新特征。
· 特征基元Feature primitives
DFS通过把特征基元应用于实体集中的实体关系来创建特征。这些基元经常被用来手动生成特征,
比如,基元“mean”可在聚合级别找到变量均值。
五、Featuretools实现
1. featuretools安装
pip install featuretools
python包安装,参考地址:
https://blog.csdn.net/weixin_39916734/article/details/95345351
2. 构造数据集(Feature_Engineering_Data_Creation.py)
import pandas as pd
import numpy as np
from datetime import datetime
import random
# 生成1000条日期数据
rand_dates = []
for _ in range(1000):
year = random.choice(range(2000, 2015))
month = random.choice(range(1, 13))
day = random.choice(range(1, 29))
rdate = datetime(year, month, day)
rand_dates.append(rdate)
# 构造25位客户基本数据:客户号,加入日期,收入,信用评级
clients = pd.DataFrame(columns=['client_id', 'joined', 'income', 'credit_score'])
for _ in range(25):
clients = clients.append(
pd.DataFrame({'client_id': np.random.randint(25000, 50000, size=1)[0], 'joined': random.choice(rand_dates),
'income': np.random.randint(30500, 240000, size=1)[0],
'credit_score': np.random.randint(500, 850, size=1)[0]},
index=[0]), ignore_index=True)
# print(clients.head())
# 构造客户贷款数据:客户号,贷款类型,贷款数,是否偿还,贷款号,贷款开始日期,贷款结束日期,贷款利率
loans = pd.DataFrame(columns=['client_id', 'loan_type', 'loan_amount', 'repaid',
'loan_id', 'loan_start', 'loan_end', 'rate'])
for client in clients['client_id'].unique():
for _ in range(20):
time_created = pd.datetime(np.random.randint(2000, 2015, size=1)[0],
np.random.randint(1, 13, size=1)[0],
np.random.randint(1, 30, size=1)[0])
time_ended = time_created + pd.Timedelta(days=np.random.randint(500, 1000, size=1)[0])
loans = loans.append(
pd.DataFrame({'client_id': client, 'loan_type': random.choice(['cash', 'credit', 'home', 'other']),
'loan_amount': np.random.randint(500, 15000, size=1)[0],
'repaid': random.choice([0, 1]),
'loan_id': np.random.randint(10000, 12000, size=1)[0],
'loan_start': time_created,
'loan_end': time_ended,
'rate': round(abs(4 * np.random.randn(1)[0]), 2)}, index=[0]), ignore_index=True)
# print(loans.head())
# 构造客户还款信息:贷款号,还款数,还款日期,是否还款
payments = pd.DataFrame(columns=['loan_id', 'payment_amount',
'payment_date', 'missed'])
for _, row in loans.iterrows():
time_created = row['loan_start']
payment_date = time_created + pd.Timedelta(days=30)
loan_amount = row['loan_amount']
loan_id = row['loan_id']
payment_id = np.random.randint(10000, 12000, size=1)[0]
for _ in range(np.random.randint(5, 10, size=1)[0]):
payment_id += 1
payment_date += pd.Timedelta(days=np.random.randint(10, 50, size=1)[0])
payments = payments.append(pd.DataFrame({'loan_id': loan_id,
'payment_amount':
np.random.randint(int(loan_amount / 10), int(loan_amount / 5),
size=1)[0],
'payment_date': payment_date, 'missed': random.choice([0, 1])},
index=[0]), ignore_index=True)
# print(payments.head())
# 去掉客户基本信息中重复的客户数据,贷款信息中重复的贷款号数据
clients = clients.drop_duplicates(subset='client_id')
loans = loans.drop_duplicates(subset='loan_id')
# 将构造的数据保存到csv文件中
clients.to_csv('clients.csv', index=False)
loans.to_csv('loans.csv', index=False)
payments.to_csv('payments.csv', index=False)
3. 深度构造特征(Automated_Feature_Engineering.py)
基本思想:
- 加载外部库和数据
- 数据预处理
- 使用Featuretools执行特征工程
- 构建模型
# coding=utf8
import pandas as pd
import numpy as np
import featuretools as ft
import warnings
# 忽略pandas的告警
warnings.filterwarnings('ignore')
# 读取3个csv文件信息:客户基本信息,贷款信息,还款信息
clients = pd.read_csv('data/clients.csv', parse_dates=['joined'])
loans = pd.read_csv('data/loans.csv', parse_dates=['loan_start', 'loan_end'])
payments = pd.read_csv('data/payments.csv', parse_dates=['payment_date'])
# print(clients.head())
# print(loans.sample(10))
# print(payments.sample(10))
# 增加列join_month:加入月份
clients['join_month'] = clients['joined'].dt.month
# 增加列log_income:收入的对数
clients['log_income'] = np.log(clients['income'])
# print(clients.head())
# 根据客户分组,分别算出贷款数的平均值,最大值,最小值
stats = loans.groupby('client_id')['loan_amount'].agg(['mean', 'max', 'min'])
# print(stats.head())
stats.columns = ['mean_loan_amount', 'max_loan_amount', 'min_loan_amount']
# print(stats.head())
# 将数据插入到客户基本信息中
clients = clients.merge(stats, left_on='client_id', right_index=True, how='left')
# featuretools创建实体集
es = ft.EntitySet(id='clients')
es = es.entity_from_dataframe(entity_id='clients', dataframe=clients,
index='client_id', time_index='joined')
# print(es)
es = es.entity_from_dataframe(entity_id='loans', dataframe=loans,
variable_types={'repaid': ft.variable_types.Categorical},
index='loan_id',
time_index='loan_start')
# print(es)
es = es.entity_from_dataframe(entity_id='payments',
dataframe=payments,
variable_types={'missed': ft.variable_types.Categorical},
make_index=True,
index='payment_id',
time_index='payment_date')
# print(es)
# print(es['loans'])
# print(es['payments'])
# 创建实体集间的关系
r_client_previous = ft.Relationship(es['clients']['client_id'],
es['loans']['client_id'])
es = es.add_relationship(r_client_previous)
r_payments = ft.Relationship(es['loans']['loan_id'],
es['payments']['loan_id'])
es = es.add_relationship(r_payments)
# print(es)
# 特征基元
primitives = ft.list_primitives()
# print(primitives)
pd.options.display.max_colwidth = 100
# print(primitives[primitives['type'] == 'aggregation'].head(10))
# print(primitives[primitives['type'] == 'transform'].head(10))
# primitives[primitives['type'] == 'aggregation'].head(10)
# primitives[primitives['type'] == 'transform'].head(10)
# 使用featuretools执行特征工程
features, feature_names = ft.dfs(entityset=es, target_entity='clients',
agg_primitives=['mean', 'max', 'percent_true', 'last'],
trans_primitives=['year', 'month']) # , 'subtract', 'divide'
# print(pd.DataFrame(features['MONTH(joined)'].head()))
# print(pd.DataFrame(features['MEAN(payments.payment_amount)'].head()))
print(features.head())
# print(pd.DataFrame(features['MEAN(loans.loan_amount)'].head(10)))
# print(pd.DataFrame(features['LAST(loans.MEAN(payments.payment_amount))'].head(10)))
features, feature_names_1 = ft.dfs(entityset=es, target_entity='clients',
max_depth=2)
print(features.head())
print(features.iloc[:, 4:].head())
六、Featuretools可解释性
让数据科学模型具有可解释性是执行机器学习中一个很重要的方面。
Featuretools生成的特征甚至能很容易地解释给非技术人员,因为它们是基于容易理解的基元构建的。
这使得那些不是机器学习专家的使用者能够在他们的专业领域中理解和应用这个方法。
· 简短总结:
Featuretools库真正地改变了机器学习的游戏规则。
虽然它在工业领域的应用还十分有限,但是它在机器学习竞赛中很快地受到大家的欢迎。
它能在构建机器学习模型中节省很多时间,且产生的特征很有效果
参考文献:
手把手教你用Python实现自动特征工程
Feature Tools:可自动构造机器学习特征的Python库
使用sklearn做单机特征工程