提交spark yarn-cluster与yarn-client模式的致命区别
- 一、组件版本
- 二、提交方式
- 三、运行原理
- 四、分析过程
- 五、致命区别
- 六、总结
一、组件版本
调度系统:DolphinScheduler1.2.1
spark版本:2.3.2
二、提交方式
spark在submit脚本里提交job的时候,经常会有这样的警告
Warning: Master yarn-cluster is deprecated since 2.0. Please use master "yarn" with specified deploy mode instead.
这是因为你用了yarn-cluster的方式:
spark-submit \
--master yarn-cluster \
--executor-cores 2 \
--num-executors 3 \
--executor-memory 4g \
--driver-memory 1g \
test_spark.py
其实yarn-cluster与yarn-client分为两部分,分别对应spark内部的参数master-deployMode,不论你指定yarn-cluster还是yarn-client,master的值在源码里面都强制置为了YARN,在org.apache.spark.deploy.SparkSubmit类中源代码如下:
val clusterManager: Int = args.master match {
case "yarn" => YARN
case "yarn-client" | "yarn-cluster" =>
printWarning(s"Master ${args.master} is deprecated since 2.0." +
" Please use master \"yarn\" with specified deploy mode instead.")
YARN
case m if m.startsWith("spark") => STANDALONE
case m if m.startsWith("mesos") => MESOS
case m if m.startsWith("k8s") => KUBERNETES
case m if m.startsWith("local") => LOCAL
case _ =>
printErrorAndExit("Master must either be yarn or start with spark, mesos, k8s, or local")
-1
}
spark deployMode的默认值是client,但是在spark-submit脚本中,这个参数一般没人会去指定,所以就用它的默认值了。当所有人都适应默认值的时候,问题来了,如果在spark-submit脚本中设置了--master yarn-clsuter,源码里面会把deployMode的值修改为cluster,源代码如下:
(args.master, args.deployMode) match {
case ("yarn-cluster", null) =>
// 这里把原本的默认值改成了CLUSTER
deployMode = CLUSTER
args.master = "yarn"
case ("yarn-cluster", "client") =>
printErrorAndExit("Client deploy mode is not compatible with master \"yarn-cluster\"")
case ("yarn-client", "cluster") =>
printErrorAndExit("Cluster deploy mode is not compatible with master \"yarn-client\"")
case (_, mode) =>
args.master = "yarn"
}
简言之,spark-submit脚本指定–master参数,实际决定了两个值:
设为yarn/yarn-client时:yarn-client模式
设为yarn-cluster时:yarn-cluster模式
三、运行原理
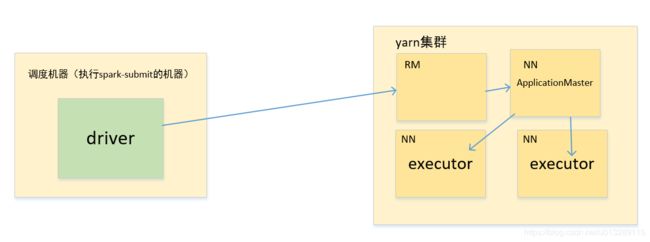
yarn/yarn-client模式如下:
yarn-cluster模式如下:
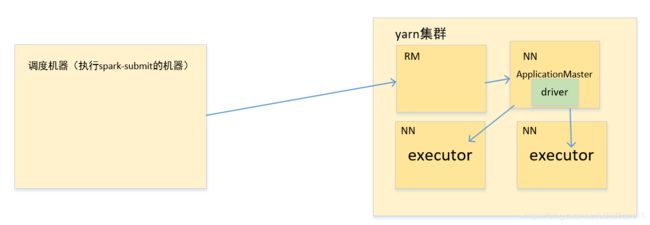
很明显,明面上唯一的区别就体现在driver在调度机器上还是在yarn
四、分析过程
我用py写了个简单的spark程序,基本就是读表、存表的操作
#!/usr/bin/env python3
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("yarn").enableHiveSupport().getOrCreate()
df = spark.sql("select item_type,count(*) as num from dw_db.dw_recessw_minipage_items_h group by item_type")
df.write.mode("overwrite").saveAsTable("dw_db.pyspark")
spark-submit脚本,--master参数分别设置为yarn或yarn-master
source /etc/profile
spark-submit \
--master yarn 或 yarn-master \
--executor-cores 2 \
--num-executors 3 \
--executor-memory 4g \
--driver-memory 1g \
test_pyspark.py
以两种模式分别运行后打开spark的web ui界面点击Environment导航栏

分别把上面的Spark Properties和System Properties的所有参数配置拷贝出来放文件里面,我这里把两种模式下的所有配置项拷出来之后去掉了所有相同配置对比图如下:

可以看到区别比较大的是spark.submit.deployMode分别为cluster和client,关键部分在下面的System Properties,里面包含了运行spark-submit脚本的路径和用户,还有实际执行java程序的调用类都不同!
五、致命区别
-
yarn(yarn-client):
-
带宽角度
这种模式由于driver在你的调度机器上,如果调度机器不在yarn集群机器上部署,driver与executor通信会导致大量的带宽流量产生,spark streaming实时程序或者程序比较多的情况下,网络带宽会打满撑爆,带宽打满的情况下,连锁反应的后果是集群上所有任务都会拖慢,线上事故妥妥的!如果调度机器跟yarn同一集群,推荐这种方式!也方便在调度系统上查看driver的日志。
-
权限控制角度
在上图中可以看到System Properties的
user.name是lijf,上面的代码最后会有写表的操作,写hdfs的用户也就是lijf,因为最后实际执行spark程序executor端的用户就是lijf,控制hdfs读写权限只需要控制lijf用户的读写权限就行了,这里使用的是ranger做权限控制,非常方便。
-
-
yarn-cluster
-
带宽角度
这种方式提交spark任务后,启动driver的节点是yarn上的随机节点,由AppMaster启动,无需关注调度机器是否与yarn集群部署在一块。
-
权限控制角度
这种方式致命的缺点,可以看到System Properties的
user.name是yarn,这是由于linux系统本地没有创建提交任务的用户,ugi无法识别用户,最后由yarn统一提交,意思是无论哪个用户提交spark任务,只要本地linux没有创建这个用户,最后executor端读写hdfs都是以yarn的身份,所以集群的权限管理根本没法控制!权限控制不好,删库跑路,完了别告诉我你是干大数据的,线上事故妥妥的!这里控制的是hdfs文件的权限,不要与hive表权限混为一谈,hive表的权限是在drive端去操作catlog控制ddl操作。
-
六、总结
综上所述,两种选择:
1.调度与yarn集群共同机器部署,spark的–master参数置为yarn,无需关心linux本地的用户创建问题
2.调度机器与yarn分离部署,调度有的用户需要在yarn集群所有linux系统上创建