快速学习-Sentinel 流量控制
6、Sentinel 流量控制
6.1 概述
FlowSlot 会根据预设的规则,结合前面NodeSelectorSlot、ClusterNodeBuilderSlot、StatistcSlot 统计出来的实时信息进行流量控制。限流的直接表现是在执行Entry nodeA = SphU.entry(资源名字) 的时候抛
出FlowException 异常。FlowException 是BlockException 的子类,您可以捕捉BlockException 来自定义被限流之后的处理逻辑。
同一个资源可以对应多条限流规则。FlowSlot 会对该资源的所有限流规则依次遍历,直到有规则触发限流或者所有规则遍历完毕。
一条限流规则主要由下面几个因素组成,我们可以组合这些元素来实现不同的限流效果:
- resource:资源名,即限流规则的作用对象
- count: 限流阈值
- grade: 限流阈值类型,QPS 或线程数
- strategy: 根据调用关系选择策略
6.2 基于QPS/并发数的流量控制
流量控制主要有两种统计类型,一种是统计线程数,另外一种则是统计QPS。类型由FlowRule.grade 字段来定义。其中,0 代表根据并发数量来限流,1 代表根据QPS 来进行流量控制。其中线程数、QPS 值,都是由StatisticSlot 实时统计获取的。
可以通过下面的命令查看实时统计信息:
curl http://localhost:8719/cnode?id=resourceName
输出内容格式如下:
idx id thread pass blocked success total Rt 1m-pass 1m-block1m-all exeption
2 abc647 0 46 0 46 46 1 2763 0 27630
其中:
- thread: 代表当前处理该资源的线程数;
- pass: 代表一秒内到来到的请求;
- blocked: 代表一秒内被流量控制的请求数量;
- success: 代表一秒内成功处理完的请求;
- total: 代表到一秒内到来的请求以及被阻止的请求总和;
- RT: 代表一秒内该资源的平均响应时间;
- 1m-pass: 则是一分钟内到来的请求;
- 1m-block: 则是一分钟内被阻止的请求;
- 1m-all: 则是一分钟内到来的请求和被阻止的请求的总和;
- exception: 则是一秒内业务本身异常的总和。
6.2.1 并发线程数流量控制
线程数限流用于保护业务线程数不被耗尽。例如,当应用所依赖的下游应用由于某种原因导致服务不稳定、响应延迟增加,对于调用者来说,意味着吞吐量下降和更多的线程数占用,极端情况下甚至导致线程池耗尽。为应对高线程占用的情况,业内有使用隔离的方案,比如通过不同业务逻辑使用不同线程池来隔离业务自身之间的资源争抢(线程池隔离),或者使用信号量来控制同时请求的个数(信号量隔离)。
这种隔离方案虽然能够控制线程数量,但无法控制请求排队时间。当请求过多时排队也是无益的,直接拒绝能够迅速降低系统压力。Sentinel 线程数限流不负责创建和管理线程池,而是简单统计当前请求上下文的线程个数,如果超出阈值,新的请求会被立即拒绝。
例子参见:ThreadDemo
6.2.2 QPS 流量控制
当QPS 超过某个阈值的时候,则采取措施进行流量控制。流量控制的手段包括下面3 种,对应FlowRule 中的controlBehavior 字段:
-
直接拒绝(RuleConstant.CONTROL_BEHAVIOR_DEFAULT)方式。该方式是默认的流量控制方式,当QPS 超过任意规则的阈值后,新的请求就会被立即拒绝,拒绝方式为抛出FlowException。这种方式适用于对系统处理能力确切已知的情况下,比如通过压测确定了系统的准确水位时。具体的例子参见FlowqpsDemo。
-
冷启动(RuleConstant.CONTROL_BEHAVIOR_WARM_UP)方式。该方式主要用于系统长期处于低水位的情况下,当流量突然增加时,直接把系统拉升到高水位可能瞬间把系统压垮。通过"冷启动",让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限,给冷系统一个预热的时间,避免冷系统被压垮的情况。具体的例子参见WarmUpFlowDemo。通常冷启动的过程系统允许通过的QPS 曲线如下图所示:
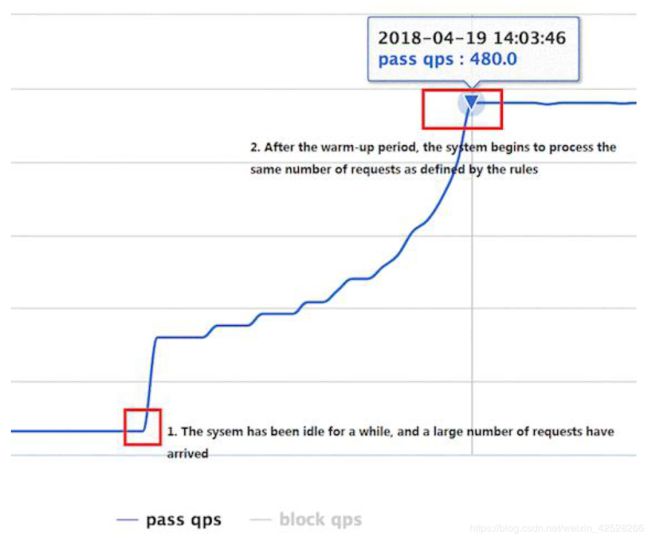
-
匀速器(RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER)方式。这种方式严格控制了请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法。具体的例子参见PaceFlowDemo。该方式的作用如下图所示:
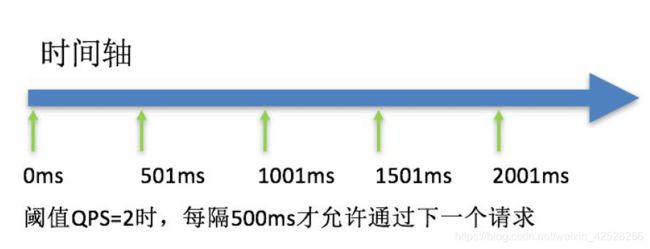
这种方式主要用于处理间隔性突发的流量,例如消息队列。想象一下这样的场景,在某一秒有大量的请求到来,而接下来的几秒则处于空闲状态,我们希望系统能够在接下来的空闲期间逐渐处理这些请求,而不是在第一秒直接拒绝多余的请求。
6.3 基于调用关系的流量控制
调用关系包括调用方、被调用方;方法又可能会调用其它方法,形成一个调用链路的层次关系。Sentinel 通过NodeSelectorSlot 建立不同资源间的调用的关系,并且通过ClusterNodeBuilderSlot 记录每个资源的实时统计信息。有了调用链路的统计信息,我们可以衍生出多种流量控制手段。
6.3.1 根据调用方限流
ContextUtil.enter(resourceName, origin) 方法中的origin 参数标明了调用方身份。这些信息会在ClusterBuilderSlot 中被统计。可通过以下命令来展示不同的调用方对同一个资源的调用数据:
curl http://localhost:8719/origin/id=nodeA
调用数据示例:
id: nodeA
idx origin threadNum passedQps blockedQps totalQps aRt 1m-passed 1m-blocked
1m-total
1 caller1 0 0 0 0 0 0 0 0
2 caller2 0 0 0 0 0 0 0 0
上面这个命令展示了资源名为nodeA 的资源被两个不同的调用方调用的统计。限流规则中的limitApp 字段用于根据调用方进行流量控制。该字段的值有以下三种选项,分别对应不同的场景:
- default:表示不区分调用者,来自任何调用者的请求都将进行限流统计。如果这个资源名的调用总和超过了这条规则定义的阈值,则触发限流。
{some_origin_name}:表示针对特定的调用者,只有来自这个调用者的请求才会进行流量控制。例如NodeA 配置了一条针对调用者caller1 的规则,那么当且仅当来自caller1 对NodeA 的请求才会触发流量控制。- other:表示针对除{some_origin_name} 以外的其余调用方的流量进行流量控制。例如,资源NodeA 配置了一条针对调用者caller1 的限流规则,同时又配置了一条调用者为other 的规则,那么任意来自非caller1 对NodeA 的调用,都不能超过other 这条规则定义的阈值。
同一个资源名可以配置多条规则,规则的生效顺序为:{some_origin_name} >other > default
6.3.2 根据调用链路入口限流:链路限流
NodeSelectorSlot 中记录了资源之间的调用链路,这些资源通过调用关系,相互之间构成一棵调用树。这棵树的根节点是一个名字为machine-root 的虚拟节点,调用链的入口都是这个虚节点的子节点。
一棵典型的调用树如下图所示:

上图中来自入口Entrance1 和Entrance2 的请求都调用到了资源NodeA,Sentinel允许只根据某个入口的统计信息对资源限流。比如我们可以设置FlowRule.strategy 为RuleConstant.CHAIN,同时设置FlowRule.ref_identity 为Entrance1 来表示只有从入口Entrance1 的调用才会记录到NodeA 的限流统计当中,而对来自Entrance2 的调用漠不关心。
调用链的入口是通过API 方法ContextUtil.enter(name) 定义的。
6.3.3 具有关系的资源流量控制:关联流量控制
当两个资源之间具有资源争抢或者依赖关系的时候,这两个资源便具有了关联。比如对数据库同一个字段的读操作和写操作存在争抢,读的速度过高会影响写得速度,写的速度过高会影响读的速度。如果放任读写操作争抢资源,则争抢本身带来的开销会降低整体的吞吐量。可使用关联限流来避免具有关联关系的资源之间过度的争抢,举例来说,read_db 和write_db 这两个资源分别代表数据库读写,我们可以给read_db 设置限流规则来达到写优先的目的:设置FlowRule.strategy 为RuleConstant.RELATE 同时设
置FlowRule.ref_identity 为write_db。这样当写库操作过于频繁时,读数据的请求会被限流。