读v_JULY_v整理笔试题博客有感,整理些答案。
这些题目来自v_JULY_v大神博客:http://blog.csdn.net/v_july_v/article/details/7974418
-
9月11日, 京东:谈谈你对面向对象编程的认识
整理答案:
面向对象可以理解为对待每一个问题,都是首先要确定这个问题由几个本分组成,而每一个部分其实就是一个对象。然后再分别设计这些对象,最后得到整个程序。传统的程序设计多是基于功能的思想来进行考虑和设计的,而面向对象的程序设计则是基于对象的角度来考虑问题。这样做能够使得程序更加简洁,清晰。
面向对象深入理解请看这里。
2. 8月20日,金山面试,题目如下:
数据库1中存放着a类数据,数据库2中存放着以天为单位划分的表30张(比如table_20110909,table_20110910,table_20110911),总共是一个月的数据。表1中的a类数据中有一个字段userid来唯一判别用户身份,表2中的30张表(每张表结构相同)也有一个字段userid来唯一识别用户身份。如何判定a类数据库的多少用户在数据库2中出现过?
思路1:
建立一张用户表,UserInMonth(userid)表里面只放不重复的用户Id,把(table_20110909,table_20110910,table_20110911)的用户Id放到一张User表里面userid都统一放到这个表里面去。判断的时候select count(1) from user u inner join UserInMonth um on u.userid=um.userid.
思路2:
还是怎么办都逃不过30张表的查询:
1.建立id表用来存放30张表的userid
create table id(userid varchar2(20)) 不用设主键
2.插入数据可以不去重复
insert in to id (select userid from table_20110909) 就插吧 30个挨个插
现在id表已经具备30天所有userid了
现在有两种选择
3.1把表id数据导出再导入到数据库1就可以查了
select distinct userid from a where userid in(select userid from id)
或者3.2 数据库1与数据库2建立连接 用@实现查询
select distinct userid from a where userid in(select userid from id@数据库2)
其实两种操作都差不多,都是将30张表数据提取出来,再与a中数据比较,考数据库操作(我是一点不会啊,该恶补了)。
3. 百度实习笔试题(2012.5.6)
1、一个单词单词字母交换,可得另一个单词,如army->mary,成为兄弟单词。提供一个单词,在字典中找到它的兄弟。描述数据结构和查询过程。
思路总结:
既可以用素数乘积法,也可用hash判别法,即逐个将一个字符串hash到另一个字符串的hash表中,全中则true,否则false。
关于这类试题请看程序员编程艺术:第二章、字符串是否包含及匹配/查找/转换/拷贝问题。
2、线程和进程区别和联系。什么是“线程安全”。
答案总结:
(1)定义:
一、进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,是系统进行资源分配和调度的一个独立单位。
二、线程是进程的一个实体,是CPU调度和分派的基本单位,他是比进程更小的能独立运行的基本单位,线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),一个线程可以创建和撤销另一个线程;
进程和线程的关系:
(1)一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
(2)资源分配给进程,同一进程的所有线程共享该进程的所有资源。
(3)线程在执行过程中,需要协作同步。不同进程的线程间要利用消息通信的办法实现同步。
(4)处理机分给线程,即真正在处理机上运行的是线程。
(5)线程是指进程内的一个执行单元,也是进程内的可调度实体。
线程与进程的区别:
(1)调度:线程作为调度和分配的基本单位,进程作为拥有资源的基本单位。
(2)并发性:不仅进程之间可以并发执行,同一个进程的多个线程之间也可以并发执行。
(3)拥有资源:进程是拥有资源的一个独立单位,线程不拥有系统资源,但可以访问隶属于进程的资源。
(4)系统开销:在创建或撤销进程的时候,由于系统都要为之分配和回收资源,导致系统的明显大于创建或撤销线程时的开销。但进程有独立的地址空间,进程崩溃后,在保护模式下不会对其他的进程产生影响,而线程只是一个进程中的不同的执行路径。线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间,一个线程死掉就等于整个进程死掉,所以多进程的程序要比多线程的程序健壮,但是在进程切换时,耗费的资源较大,效率要差些。
线程的划分尺度小于进程,使得多线程程序的并发性高。
另外,进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大的提高了程序运行效率。
线程在执行过程中,每个独立的线程有一个程序运行的入口,顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,有应用程序提供多个线程执行控制。
从逻辑角度看,多线程的意义子啊与一个应用程序中,有多个执行部分可以同时执行。但操作系统并没有将多个线程看做多个独立的应用,来实现进程的调度和管理以及资源分配。这就是进程和线程的重要区别。
(2)线程安全
如果代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。
3、C和C++怎样分配和释放内存,区别是什么?
C使用malloc和free来创建和释放内存,C++则一般使用malloc和free库函数。
区别:
(1)new,delete是操作符,可以重载,只能在C++中使用。
(2)malloc,free是函数,可以覆盖,C,C++都可以使用
(3)new 可以调用对象的构造函数,对应的delete调用相应的析构函数。
(4)malloc仅仅分配内存,free仅仅回首内存,并不执行构造和析构函数。
(5)new,delete返回的某种数据类型的指针,malloc,free返回的是void*类型的指针。
4、一个url指向的页面里面有另一个url,最终有一个url指向之前出现过的url或空,这两种情形都定义为null。这样构成一个单链表。给两条这样单链表,判断里面是否存在同样的url。url以亿级计,资源不足以hash。
情况一:两条单链表均无环
最简单的一种情况,由于两条链表如果交叉,他们的尾节点必然相等(Y字归并),所以只需要判断他们的尾节点是否相等即可。
情况二:两条单链表均有环
这种情况只需要拆开一条环路(注意需要保存被设置成null的节点),然后判断另一个单链表是否仍然存在环路,如果存在,说明无交叉,反之,则有交叉的情况。
情况三:两条单链表,一条有环路,一条无环路
这种情况显然他们是不可能有交叉的
这里有个解答,经验证可行: 数组al[0,mid-1]和al[mid,num-1]是各自有序的,对数组al[0,num-1]的两个子有序段进行merge,得到al[0,num-1]整体有序。
6、系统设计题
百度搜索框的suggestion,比如输入“北京”,搜索框下面会以北京为前缀,展示“北京爱情故事”、“北京公交”、“北京医院”等等搜索词,输入“结构之”,会提示“结构之法”,“结构之法 算法之道”等搜索词。请问,如何设计此系统,使得空间和时间复杂度尽量低。
大神直接给出了解答:
老题,直接上Trie树「Trie树的介绍见:从Trie树(字典树)谈到后缀树」+TOP K「hashmap+堆,hashmap+堆 统计出如10个近似的热词,也就是说,只存与关键词近似的比如10个热词」? or Double-array trie tree?同时,StackOverflow上也有两个讨论帖子:http://stackoverflow.com/questions/2901831/algorithm-for-autocomplete,http://stackoverflow.com/questions/1783652/what-is-the-best-autocomplete-suggest-algorithm-datastructure-c-c。此外,这里有一篇关于“拼写错误检查”问题的介绍,或许对你有所启示:http://blog.afterthedeadline.com/2010/01/29/how-i-trie-to-make-spelling-suggestions/。
我自己也写了一个基于Trie树的处理字符串的自动匹配系统,代码如下:
/*
* Date:2012-11-8
* functions:Manage a system that can handle suggestion problem in serach engine.
* While user is inputing words,the system gives a list of posible words that the user may want to input displayed in a list
* that automaticlly.
* The solution is to create and manage a trie tree.
* @copyright:Chen Qin
*/
#include
#include
#include
#include
using namespace std;
//Trie tree node
typedef struct _TrieNode
{
string value;//word of the node
char added_char;//the charactor added to the parent word value
vector child_list;//child pointers list
int match_count;//the count of the words match to the node value
int level;//level int the tree
}TrieNode,*pTrieNode;
//Trie tree root
typedef struct _TrieRoot
{
vector child_list;//child pointers list of root of the Trie tree
}TrieTree,*pTrieTree;
class SuggestionSystem
{
public:
SuggestionSystem()
{
cout<<"construct system."<child_list=vector();
}
SuggestionSystem(const vector &words)
{
cout<<"construct system with data."<child_list=vector();
for(vector::const_iterator it=words.begin();it &words);
void DisplayTree();//display the tree node
void FindSubsequencesOfGivenString(const string& str);//find the possible subsequencs of the given string
private:
void InsertWordIntoTrieTree(const string &word,bool search=false);
void InsertSubstringIntoNode(const string &word,pTrieNode pNode,bool serach=false);
void DeleteSystem();//clear the hole system
void FreeNode(pTrieNode pNode);//free trie node
void VisitNode(const pTrieNode pNode);
void DisplayTreeFromNode(const pTrieNode pNode);
private:
pTrieTree mpTree;
};
void SuggestionSystem::CreateSystemFromWordList(const vector &words)
{
if(mpTree!=NULL)
{
DeleteSystem();
mpTree=new TrieTree;
mpTree->child_list=vector();
}
for(vector::const_iterator it=words.begin();it::const_iterator it=mpTree->child_list.begin();itchild_list.end();it++)
{
if((*it)->added_char==c)//alredy exits the path of the first charactor
{
if(word.size()==1)
{
(*it)->match_count++;
if(search)
{
DisplayTreeFromNode(*it);
}
}else
{
string sub=string(word.begin()+1,word.end());
InsertSubstringIntoNode(sub,*it,search);
}
return;
}
}
//create a new path of the charactor
pTrieNode pn=new TrieNode();
mpTree->child_list.push_back(pn);
pn->added_char=c;
pn->value=c;
pn->level=1;
if(word.size()==1)
{
pn->match_count=1;
}else
{
pn->match_count=0;
string sub=string(word.begin()+1,word.end());
InsertSubstringIntoNode(sub,pn,search);
}
}
void SuggestionSystem::InsertSubstringIntoNode(const string &word,pTrieNode pNode,bool search)
{
if(word.size()<=0) return;
char c=*word.begin();
for(vector::const_iterator it=pNode->child_list.begin();itchild_list.end();it++)
{
if(c==(*it)->added_char)//find the path math the first charactor of the word
{
if(word.size()==1)
{
(*it)->match_count++;
if(search)
{
DisplayTreeFromNode(*it);
}
}else
{
string sub=string(word.begin()+1,word.end());
InsertSubstringIntoNode(sub,*it,search);
}
return;
}
}
pTrieNode pn=new TrieNode();
pNode->child_list.push_back(pn);
pn->added_char=c;
string val=pNode->value;
val.push_back(c);
pn->value=val;
pn->level=pNode->level+1;
if(word.size()==1)
{
pn->match_count=1;
}else
{
pn->match_count=0;
string sub=string(word.begin()+1,word.end());
InsertSubstringIntoNode(sub,pn,search);
}
}
void SuggestionSystem::FindSubsequencesOfGivenString(const string& str)//find the possible subsequencs of the given string
{
InsertWordIntoTrieTree(str,true);
}
void SuggestionSystem::DeleteSystem()
{
if(mpTree->child_list.size()>=1)
{
for(vector::iterator it=mpTree->child_list.begin();itchild_list.end();it++)
{
FreeNode(*it);
}
}
delete mpTree;
}
void SuggestionSystem::FreeNode(pTrieNode pNode)
{
if(pNode->child_list.size()>=1)//has children
{
for(vector::iterator it=pNode->child_list.begin();itchild_list.end();it++)
{
FreeNode(*it);
}
}
delete pNode;
pNode=NULL;
}
void SuggestionSystem::DisplayTree()
{
if(mpTree->child_list.size()<=0) return;
cout<<"------the hole tree nodes display------"< que=queue();
for(vector::iterator it=mpTree->child_list.begin();itchild_list.end();it++)
{
que.push(*it);
}
//begin visit by queue
cout<<"root-->"<level)
{
cout<<"-->"<child_list.size()>0)
{
for(vector::const_iterator it=pNode->child_list.begin();itchild_list.end();it++)
{
que.push(*it);
}
}
}
cout< que=queue();
que.push(pNode);
//begin visit by queue
int cur_lev=pNode->level;
while(!que.empty())
{
pTrieNode pNode=que.front();
que.pop();
if(cur_levlevel)
{
cout<<"-->"<child_list.size()>0)
{
for(vector::const_iterator it=pNode->child_list.begin();itchild_list.end();it++)
{
que.push(*it);
}
}
}
cout<value<<" ";
}
int main(int argc,char *argv[])
{
cout<<"developed: chen qin"< words;
words.push_back("abc");
words.push_back("bcdf");
words.push_back("abde");
words.push_back("bce");
words.push_back("ad");
words.push_back("abcf");
words.push_back("abce");
words.push_back("bcef");
words.push_back("bcde");
SuggestionSystem ss(words);
ss.DisplayTree();
cout<<"find subquences of ab:"< 4. 人搜笔试题
1,快排每次以第一个作为主元,问时间复杂度是多少?(O(N*logN))2,T(N) = N + T(N/2)+T(2N), 问T(N)的时间复杂度是多少? 点评: O(N*logN) or O(N)?
求解数列T通项?
典型求解递归式时间复杂度题目,可以看看这里:http://www.cnblogs.com/web-application-security/archive/2012/06/15/how_to_solve_recurrences.html
3,链表相邻元素翻转,如a->b->c->d->e->f-g,翻转后变为:b->a->d->c->f->e->g。
我写了一个,复杂度为O(n)。
/*
* reverse two near nodes in a link list,for expample:
* a->b->c->d->e->f to b->a->d->c->f->e
*/
#include
#include
typedef struct _Node
{
char data;
struct _Node *next;
}Node,*pNode;
void reverse_node(pNode pre,pNode first,pNode second);
pNode reverse(pNode list)
{
if(NULL==list||NULL==list->next) return list;
pNode first=list,second=list->next,pre=NULL;
list=list->next;
while(first&&second)
{
reverse_node(pre,first,second);
pre=first;
first=first->next;
if(NULL==first) break;
second=first->next;
}
return list;
}
void reverse_node(pNode pre,pNode first,pNode second)
{
if(NULL==pre)
{
first->next=second->next;
second->next=first;
}else
{
pre->next=second;
first->next=second->next;
second->next=first;
}
}
pNode create_list()
{
char dat;
pNode list=NULL,last=NULL;
while(1)
{
scanf("%c",&dat);
if('#'==dat) break;
pNode pn=(pNode)malloc(sizeof(Node));
pn->data=dat;
pn->next=NULL;
if(NULL==list)
{
list=pn;
last=pn;
}else
{
last->next=pn;
last=pn;
}
}
return list;
}
void show_list(const pNode list)
{
if(NULL==list) return;
printf("list data:");
pNode p=list;
while(p)
{
printf("%c->",p->data);
p=p->next;
}
printf("NULL\n");
}
int main(int argc,char *arv[])
{
pNode list=create_list();
printf("list before reverse.\n");
show_list(list);
list=reverse(list);
printf("list after reverse.\n");
show_list(list);
}
4,编程题:
一棵树的节点定义格式如下:
struct Node{
Node* parent;
Node* firstChild; // 孩子节点
Node* sibling; // 兄弟节点
}
要求非递归遍历该树。
思路:采用队列存储,来遍历节点。与树的层序遍历相似,算法过层如下:
首先将树根节点压入队列,然后队列弹出一个节点,访问该节点,如果这个节点有兄弟节点,则将兄弟节点压入队列,有孩子节点则将孩子节点压入队列。
队列再次弹出一个节点,按照上述步骤处理,直到对空为止。
5,有N个节点,每两个节点相邻,每个节点只与2个节点相邻,因此,N个顶点有N-1条边。每一条边上都有权值wi,定义节点i到节点i+1的边为wi。
求:不相邻的权值和最大的边的集合。
解答:
动态规划求解,这里有完美解答:http://blog.csdn.net/realxie/article/details/8063885
5.人搜面试,所投职位:搜索研发工程师:面试题回忆
1,删除字符串开始及末尾的空白符,并且把数组中间的多个空格(如果有)符转化为1个。
我写了一个,时间复杂度为O(n):
/*
* trim the space before and after a string,and change the spaces more than two inner the stirng into one.
* for example,input:"___a__bc__d_e__fgh_____"
* output should be:"a_bc_d_e_fgh".
*/
#include
#include
char * const trim_space(char * const str)
{
if(NULL==str) return NULL;
char *first=str,*last=str;
//find the first charactor that is not a space
while(*first=='_'&&*first!='\0') first++;
if('\0'==*first) return "_";
//trim the space before the string
while('\0'!=*first) *last++=*first++;
*last='\0';
first=str;
last=str;
//trim the space inner and after the string
while('\0'!=*first)
{
while('_'!=*first&&'\0'!=*first) first++;
if('\0'==*first)
{
return str;
}
//first point to the first space inner the string
last=first;
while('_'==*last&&'\0'!=*last) last++;
if('\0'==*last)//end with *(--first) and spaces
{
*first='\0';
return str;
}
if(last-first>1)//more than one spaces
{
//trim spaces between first and last,leave one
first++;
while('\0'!=*last&&'_'!=*last)
{
*first++=*last;
*last='_';
last++;
}
if('\0'==*last)
{
*first='\0';
return str;
}
}else
{
first=last+1;
}
}
return str;
}
int main(int argc,char *argv[])
{
char str[]="___a__bc__d_e__fgh_____";
printf("original string: %s\n",str);
printf("after trim spaces: %s\n",trim_space(str));
char str2[]="___a_b__c_d_e__fgh";
printf("original string: %s\n",str2);
printf("after trim spaces: %s\n",trim_space(str2));
char str3[]="a__bc__d_e__fgh_____";
printf("original string: %s\n",str3);
printf("after trim spaces: %s\n",trim_space(str3));
return 0;
}
2,求数组(元素可为正数、负数、0)的最大子序列和。
思路,比较简单就是连续求和,碰到和低于零再从下一个开始重新求和,我写了一个:
/*
* get the max sum of the sub sunmbers of a array.
* for example: 5 -6 1 2 4 -9 1 3
* the sub max sum array is 1 2 4,sum is 7
*/
#include
int get_max_sub_sum(int data[],int length,int *start,int *end)
{
int sum=0,max=0;
int s=0,e=0,l=0,r=0;
while(rmax)
{
max=sum;
s=l;
e=r;
}
if(sum<=0)
{
l=r+1;
sum=0;
}
r++;
}
*start=s;
*end=e;
return max;
}
int main(int argc,char *argv[])
{
int d[10]={3,5,-6,1,2,4,-9,1,3};
int s=0,e=0,max=0;
max=get_max_sub_sum(d,9,&s,&e);
printf("max array:\n");
int i;
for(i=s;i<=e;i++)
{
printf("%d ",d[i]);
}
printf("the max sum:%d\n",max);
return 0;
}
思路:数学功底
让我们先来看一个更简单的问题:任取两个 0 到 1 之间的实数,它们的和小于 1 的概率有多大?容易想到,满足 x+y<1 的点 (x, y) 占据了正方形 (0, 1)×(0, 1) 的一半面积,因此这两个实数之和小于 1 的概率就是 1/2 。类似地,三个数之和小于 1 的概率则是 1/6 ,它是平面 x+y+z=1 在单位立方体中截得的一个三棱锥。这个 1/6 可以利用截面与底面的相似比关系,通过简单的积分求得:
∫(0..1) (x^2)*1/2 dx = 1/6
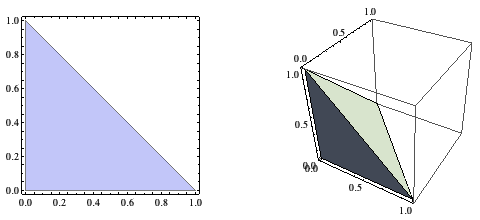
可以想到,四个 0 到 1 之间的随机数之和小于 1 的概率就等于四维立方体一角的“体积”,它的“底面”是一个体积为 1/6 的三维体,在第四维上对其进行积分便可得到其“体积”
∫(0..1) (x^3)*1/6 dx = 1/24
依此类推, n 个随机数之和不超过 1 的概率就是 1/n! ,反过来 n 个数之和大于 1 的概率就是 1 - 1/n! ,因此加到第 n 个数才刚好超过 1 的概率就是
(1 - 1/n!) - (1 - 1/(n-1)!) = (n-1)/n!
因此,要想让和超过 1 ,需要累加的期望次数为
∑(n=2..∞) n * (n-1)/n! = ∑(n=1..∞) n/n! = e
解:根据公式, ∑(n=0...∞)1/n!=e,可得∑(n=1...∞)1/n!=e-1,故原试∑(n=1..∞) n/n!=1+∑(n=2..∞) 1/(n-1)!=1+∑(n=1..∞)1/n!=1+e-1=e,大功告成!
4,链表克隆。链表的结构为:typedef struct list {
int data; //数据字段
list *middle; //指向链表中某任意位置元素(可指向自己)的指针
list *next;//指向链表下一元素
} list;
思路:复杂链表的复制,采用交错复制法达到O(n)时间复杂度,这里有完美解答:复杂链表复制
5,100万条数据的数据库查询速度优化问题,解决关键点是:根据主表元素特点,把主表拆分并新建副表,并且利用存储过程保证主副表的数据一致性。(不用写代码)
6,求正整数n所有可能的和式的组合(如;4=1+1+1+1、1+1+2、1+3、2+1+1、2+2)。点评:这里有一参考答案:http://blog.csdn.net/wumuzi520/article/details/8046350。
看过后我也写了一个:
/*
* find the possible combination of a integer.
* for example:4=1+1+1+1=1+2+1=1+3=2+2
*/
#include
void find_combination_by_num(int sum,int num,int *pdata,int depth)
{
if(sum<0||pdata==NULL) return;
if(num==1)
{
pdata[depth]=sum;
int i=0;
for(;i<=depth;i++)
{
printf("%d ",pdata[i]);
}
printf("\n");
return;
}
int i=0;
if(depth==0)
{
i=1;//index form 1 when start.
}else//index from the last i
{
i=pdata[depth-1];
}
for(;i<=sum/num;i++)
{
pdata[depth]=i;
find_combination_by_num(sum-i,num-1,pdata,depth+1);
}
}
void find_all_combinations(int sum,int *pdata)
{
printf("all combinatins of %d:\n",sum);
int i=2;
for(;i<=sum;i++)
{
find_combination_by_num(sum,i,pdata,0);
}
}
int main(int argc,char *argv[])
{
int data[10]={0};
find_all_combinations(10,data);
return 0;
} 7,求旋转数组的最小元素(把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。输入一个排好序的数组的一个旋转,输出旋转数组的最小元素。例如数组{3, 4, 5, 1, 2}为{1, 2, 3, 4, 5}的一个旋转,该数组的最小值为1)。
思路:
除了正常情况,还要注意考虑三种特殊情况:
(1). 数组是没有发生过旋转的 {1,2,3,4,5,6}
(2). 全相等的数组 {1,1,1,1,1,1}
(3). 大部分都相等的数组 {1,0,1,1,1,1}
二分查找的思路,最开始 如果数组没有旋转过,直接返回第一个元素,就是最小的元素; 如果旋转过,再按后续
首先获得 mid。 此时 ,若
(1) 如果 ar[mid] > ar[left], 代表最小值肯定在后半区 left = mid + 1
(2) 如果 ar[mid] < ar[left], 代表最小值肯定是在前半区到mid之间的(mid也有可能是最小值), right = mid
(3) 如果 ar[mid] == ar[left], 这种情况不好说了,需要进一步分析:
(1)若 ar[mid] == ar[right] , 最麻烦的情况,前中后都相等,只好排除首尾,继续找 left++ right--
(2)若 ar[mid] < ar[right], 代表最小值肯定在前半区, right = mid
(3)若 ar[mid] > ar[right], 代表最小值肯定在后半区, left = mid + 1
基于次我写了一个:/*
* find min number in a sorted array after change.
* for example:345612,the min is 1
* the complexity of time shold be under O(n).
*/
#include
int find(const int data[],int length)
{
if(data==NULL) return -1;
int i=0;
printf("the original data:\n");
for(;idata[start])
{
start=mid+1;
}else if(data[mid]data[end])
{
start=mid+1;
}else if(data[mid] 8,找出两个单链表里交叉的第一个元素
思路:求出两个链表长度L1和L2,假设L1>L2,长的链表先移动L2-L1次,然后两个链表分别比较相应元素直到相等或结束为止。
写代码时注意边界问题即可,十分简单代码略。
9,字符串移动(字符串为*号和26个字母的任意组合,把*号都移动到最左侧,把字母移到最右侧并保持相对顺序不变),要求时间和空间复杂度最小
与第一题类似,不过比它简单,只要维护两个指针,一指向字符串第一个非*字符,一个指向其后的第一个*字符,然后二者交换并且都右移一位即可。
我写了一个:
/*
* move all the '*' in a string to the left
* for example: "a*fc*3**fdj*3" the result is "*****afc3fdj3"
*/
#include
void foo(char *str)
{
printf("string before foo:%s\n",str);
if(str==NULL) return ;
int left=0,right=0;
while(str[left]!='\0'&&str[right]!='\0')
{
while(str[left]!='\0'&&str[left]=='*') left++;
if(str[left]=='\0') break;
right=left+1;
while(str[right]!='\0'&&str[right]!='*') right++;
if(str[right]=='\0') break;
char temp=str[left];
str[left]=str[right];
str[right]=temp;
left++;
right++;
}
printf("string after foo:%s\n",str);
}
int main(int argc,char *argv[])
{
char str[20]="***ad*h**f****";
foo(str);
char str1[20]="a*d**h***f";
foo(str1);
char str2[20]="***a*d*h**fhg";
foo(str2);
char str3[20]="a*d*h**f**g***";
foo(str3);
return 0;
} 10,时间复杂度为O(1),怎么找出一个栈里的最大元素
思路:比较简单,新建一个辅助栈即可,里面存放当前栈中最大元素,当数据栈中压入一个数时如果这个数比辅助栈栈顶元素大则同步压入辅助栈,否则压入辅助栈栈顶元素,弹出时辅助栈弹出一个元素即可,那么数据栈中当前最大元素就是辅助栈中的栈顶元素。
代码简单略。
11,线程、进程区别
答案见3.百度笔试题第二小题。
12,static在C和C++里各代表什么含义
对于局部变量和全局变量(函数)而言static的作用C和C++一样。
(1)局部变量
在C/C++中, 局部变量按照存储形式可分为三种auto, static, register
与auto类型(普通)局部变量相比, static局部变量有三点不同
1. 存储空间分配不同
auto类型分配在栈上, 属于动态存储类别, 占动态存储区空间, 函数调用结束后自动释放, 而static分配在静态存储区, 在程序整个运行期间都不释放. 两者之间的作用域相同, 但生存期不同.
2. static局部变量在所处模块在初次运行时进行初始化工作, 且只操作一次
3. 对于局部静态变量, 如果不赋初值, 编译期会自动赋初值0或空字符, 而auto类型的初值是不确定的. (对于C++中的class对象例外, class的对象实例如果不初始化, 则会自动调用默认构造函数,不管是否是static类型)
特点: static局部变量的”记忆性”与生存期的”全局性”
所谓”记忆性”是指在两次函数调用时, 在第二次调用进入时, 能保持第一次调用退出时的值.
(2)外部(全局)静态变量/函数在C中 static有了第二种含义:用来表示不能被其它文件访问的全局变量和函数。但为了限制全局变量/函数的作用域, 函数或变量前加static使得函数成为静态函数。但此处“static”的含义不是指存储方式,而是指对函数的作用域仅局限于本文件(所以又称内部函 数)。注意此时, 对于外部(全局)变量, 不论是否有static限制, 它的存储区域都是在静态存储区,
生存期都是全局的. 此时的static只是起作用域限制作用, 限定作用域在本模块(文件)内部.使用内部函数的好处是:不同的人编写不同的函数时,不用担心自己定义的函数,是否会与其它文件中的函数同名.
(3)C++中静态数据成员/成员函数
C+ +重用了这个关键字,并赋予它与前面不同的第三种含义:表示属于一个类而不是属于此类的任何特定对象的变量和函数. 这是与普通成员函数的最大区别,
也是其应用所在, 比如在对某一个类的对象进行计数时, 计数生成多少个类的实例,
就可以用到静态数据成员. 在这里面, static既不是限定作用域的, 也不是扩展生存期的作用, 而是指示变量/函数在此类中的唯一性. 这也是”属于一个类而不是属于此类的任何特定对象的变量和函数”的含义. 因为它是对整个类来说是唯一的,
因此不可能属于某一个实例对象的. (针对静态数据成员而言, 成员函数不管是否是static, 在内存中只有一个副本, 普通成员函数调用时, 需要传入this指针, static成员函数调用时, 没有this指针. )
13,const 在C/C++里什么意思
在C中,const可以用来修饰常量,函数参数和函数返回值,C++const除了C中用法外还可以用来修饰常成员函数。
具体可以看着里:http://blog.csdn.net/kevinguozuoyong/article/details/5904627
14,常用linux命令
hostname:显示主机名
uname:显示系统信息
cut:用来移除文件的部分内容。
diff:用来找出两个文件的不同之处。
du: 用来显示磁盘的剩余空间的大小。
file:用来显示文件的类型。
find:用来在目录中搜索文件,并执行指定的操作。
head:只查看文件的头
source:使得刚修改的文件生效
read:从标准设备读入
cat:可以显示文件的内容(经常和more搭配使用),或将多个文件合并成一个文件。
chgrp:用来改变文件或目录所属的用户组,命令的参数以空格分开的要改变属组的文件列表,文件名支持通配符,如果用户不是该文件的所有者,则不能改变该文件的所属组。
chmod:用于改变文件或目录的访问权限,该命令有两种用法:一种是使用图形化的方法,另一种是数字设置法。
chown:用来将指定用户或组为特定的所有者。用户可以设置为用户名或用户ID,组可以是组名或组ID。特定的文件是以空格分开的可以改变权限的文件列表,文件名支持通配符。
clear:用来清除终端屏幕。
cd directory 进入指定的目录
cd .. 进入上一级目录
cd /directory 进入目录
cd 进入用户自己的目录
cp file_from file_to 拷贝文件
ln [-s] source linkname 为一个文件建立连结
ls [directory] 查看指定目录下的文件
ls -l [directory] 查看指定目录下文件的详细
ls -a [directory] 查看指定目录下的所有文件
mkdir new_directory 建一个新目录
more file 查看一个文本文件的内容
rm file 删除一个文件
rm -r directory 删除一个目录
rmdir directory 删除一个目录
find . -name "file" 从当前目录开始查找指定的文件
adduser 创建新用户
alias 设置别名或替代名
bg fg 使挂起的进程继续运行
ps ax 查询当前进程
mount 连接文件系统
more less 浏览文件内容
chown chgrp 改变文件的拥有者
chmod 改变文件属性
halt 关闭系统
man 显示手册页
passwd 改变用户口令
grep 查找字符串
find 查找文件
dd 复制磁盘或文件系统
kill 杀掉一个进程
killall 杀掉进程
15,解释Select/Poll模型
I/O复用模型(Select/Poll)
I/O复用模型会用到select或者poll函数,这两个函数也会使进程阻塞,但是和阻塞I/O所不同的的,这两个函数可以同时阻塞多个I/O操作。而且可以同时对多个读操作,多个写操作的I/O函数进行检测,直到有数据可读或可写时,才真正调用I/O操作函数。
详细信息请看:http://hi.baidu.com/nivrrex/item/54f782cfe821ef09c710b2a6
6,网易有道二面
判断一个数字序列是BST【二叉排序树(Binary Search Tree:BST)】后序遍历的结果,现场写代码。
思路:采用递归判断,一颗二叉树包含左子树,右子树以及根结点,根据二叉排序树的特新,左子树的所有结点均小于根结点,而右子树的所有结点均大于根结点,利用这个特新可以用来递归判断是否是二叉树的序列。对于后序遍历,最后一个数是根结点,其中要点是找到左子树与右子树的分界点,由二叉树的性质可知第一个大于根节点的数即是右子树中的节点,由此可以区分左子树与右子树。
我写了一个:
/*
* judge an array whether is a post order of a binary search tree.
* for example:4 8 7 11 14 12 9 is yes,4 11 7 8 14 12 9 is no!
*/
#include
bool judge_post_of_BST(const int data[],int start,int end);
void judge(const int data[],int length)
{
if(data==NULL) return;
printf("the array is:\n");
int i=0;
while(i=end) return true;
int index_right=-1,i=0;
for(i=start;i<=end;i++)
{
if(index_right!=-1&&data[i]data[end]) index_right=i;
}
bool l=false,r=false;
l=judge_post_of_BST(data,start,index_right-1);
r=judge_post_of_BST(data,index_right,end-1);
return l&&r;
}
int main(int argc,char *argv[])
{
int data[7]={4,8,7,11,14,12,9};
judge(data,7);
int data2[7]={4,11,7,8,14,12,9};
judge(data2,7);
return 0;
} 7,8月30日,网易有道面试题
var tt = 'aa';
function test()
{
alert(tt);
var tt = 'dd';
alert(tt);
}
test();
什么意思?要求干嘛?是写出打印结果还是改错?
8,8月31日,百度面试题:不使用随机数的洗牌算法
这里有一堆大牛的讨论:http://bbs.csdn.net/topics/390195922
9,9月6日,阿里笔试题:平面上有很多点,点与点之间有可能有连线,求这个图里环的数目。
可以看看这里:http://blog.csdn.net/chinaczy/article/details/5730601
10,9月7日,一道华为上机题:
题目描述: 选秀节目打分,分为专家评委和大众评委,score[] 数组里面存储每个评委打的分数,judge_type[] 里存储与 score[] 数组对应的评委类别,judge_type == 1,表示专家评委,judge_type == 2,表示大众评委,n表示评委总数。打分规则如下:专家评委和大众评委的分数先分别取一个平均分(平均分取整),然后,总分 = 专家评委平均分 * 0.6 + 大众评委 * 0.4,总分取整。如果没有大众评委,则 总分 = 专家评委平均分,总分取整。函数最终返回选手得分。
函数接口 int cal_score(int score[], int judge_type[], int n)
上机题目需要将函数验证,但是题目中默认专家评委的个数不能为零,但是如何将这种专家数目为0的情形排除出去。
思路:比较简单,只要注意只有专家评委和只有大众评委的情况,代码略。
11,9月8日,腾讯面试题:
假设两个字符串中所含有的字符和个数都相同我们就叫这两个字符串匹配,
比如:abcda和adabc,由于出现的字符个数都是相同,只是顺序不同,
所以这两个字符串是匹配的。要求高效!
又是跟上述第3题中简单题一的兄弟节点类似的一道题,我想,你们能想到的,这篇blog里:http://blog.csdn.net/v_JULY_v/article/details/6347454都已经有了。
12,阿里云,搜索引擎中5亿个url怎么高效存储;
思路:B+数,分布式存储
13,一道C++笔试题,求矩形交集的面积:
在一个平面坐标系上,有两个矩形,它们的边分别平行于X和Y轴。
其中,矩形A已知, ax1(左边), ax2(右边), ay1(top的纵坐标), ay2(bottom纵坐标). 矩形B,类似,就是 bx1, bx2, by1, by2。这些值都是整数就OK了。
要求是,如果矩形没有交集,返回-1, 有交集,返回交集的面积。
int area(rect const& a, rect const& b)
{
...
}
点评:
healer_kx:
补齐代码,最好是简洁的,别用库。你可以写你的辅助函数,宏定义,代码风格也很重要。
ri_aje:
struct rect
{
// axis alignment assumed
// bottom left is (x[0],y[0]), top right is (x[1],y[1])
double x [2];
double y [2];
};
template T const& min (T const& x, T const& y) { return x T const& max (T const& x, T const& y) { return x>y ? x : y; }
// return type changed to handle non-integer rects
double area (rect const& a, rect const& b)
{
// perfectly adjacent rects are considered having an intersection of 0 area
double const dx = min(a.x[1],b.x[1]) - max(a.x[0],b.x[0]);
double const dy = min(a.y[1],b.y[1]) - max(a.y[0],b.y[0]);
return dx>=0&&dy>=0 ? dx*dy : -1;
} 对于平行于坐标轴的矩形 r,假设其左下角点坐标为 (rx0,ry0),右上角点坐标为 (rx1,ry1),那么由 r 定义的无限有界点集为:{(x,y)|x in [rx0,rx1] && y in [ry0,ry1]}。
根据交集的定义,则任意二维点 (x,y) 在矩形 a,b 的交集内等价于
{(x,y)|(x,y) in a 并且 (x,y) in b} <==>
{(x,y)|x in [ax0,ax1] && x in [bx0,bx1] 并且 y in [ay0,ay1] && y in [by0,by1]} <==>
{(x,y)|x in [max(ax0,bx0),min(ax1,bx1)] 并且 y in [max(ay0,by0),min(ay1,by1)]}
因此,交集矩形的边长分别为 min(ax1,bx1)-max(ax0,bx0) 和 min(ay1,by1)-max(ay0,by0)。注意当交集为空时(a,b 不相交),则经此法计算出来的交集边长为负值,此事实可用于验证 a,b 的相交性。
鉴于笛卡尔积各个维度上的不相关性,此方法可扩展到任意有限维线性空间,比如,三维空间中平行于坐标轴的长方体的交集体积可以用类似的方法计算。
来源:http://topic.csdn.net/u/20120913/18/bc669d60-b70a-4008-be65-7c342789b925.html。
14,2012年创新工场校园招聘最后一道笔试题:工场很忙
创新工场每年会组织同学与项目的双选会,假设现在有M个项目,编号从1到M,另有N名同学,编号从1到N,每名同学能选择最多三个、最少一个感兴趣的项目。选定之后,HR会安排项目负责人和相应感兴趣的同学一对一面谈,每次面谈持续半小时。由于大家平时都很忙,所以咱们要尽量节约时间,请你按照以下的条件设计算法,帮助HR安排面试。
1)同学很忙。项目负责人一次只能与一名同学面谈,而同学会在自己第一个面试开始时达到工场,最后一个面试结束后离开工场,如果参加一个项目组的面试后不能立即参加下一个项目组的面试,就必须在工场等待。所以请尽可能让同学的面试集中在某一时间段,减少同学在工场等待的时间。
2)项目负责人很忙。众所周知,创业团队的负责人会有很多事情要做,所以他们希望能够将自己参与的面试集中在某一段时间内,请在保证1)的情况下,使得项目负责人等待的时间最少。
3)HR很忙。从第一轮面试开始以后,所有HR都必须等到最后一轮面试结束,所以需要在保证1)和2)的同时,也能尽快解放掉所有的HR,即让第一轮面试到最后一轮面试之间持续的时间最短。
输入(以文件方式输入,文件名为iw,例如iw.in):
第1行...第n行:同学的编号 项目的编号
样例(数据间用空格隔开,两个0表示输入结束):
1 1
1 2
1 3
2 1
3 1
3 2
0 0
表示M=3,N=3,编号为1的同学选择了项目1,2和3,编号为2的同学选择了项目1,编号为3的同学选了项目1和2
输出(以文件方式输出,文件名为iw,例如iw.out):
第1行:编号为1的项目依次面试新同学的编号序列
第2行:编号为2的项目依次面试新同学的编号序列
...
第n行:编号为n的项目依次面试新同学的编号序列
样例(数据间用空格隔开,0表示没有面试):
1 3 2
3 1 0
0 0 1
表示编号为1的项目在第一轮面试编号为1的同学,第二轮面试编号为3的同学,第三轮面试编号为2的同学
编号为2的项目在第一轮面试编号为3的同学,第二轮面试编号为1的同学,第三轮不用面试
编号为3的项目在第一轮和第二轮都不用面试,第三轮面试编号为1的同学
链接:http://t.qq.com/p/t/108332110988802。
我的思路:
按顺序分别安排每一个同学,安排一个同学面试的算法如下:
设项目组为个数为M,同学个数为N,同学编号为i,每一个项目设置一个二维矩阵matrix[M][3*N],表示每个项目安排同学面试的序列,矩阵初始为空,其中数字代表学生编号,每个项目序列数组初始大小为N*3,设置一个大小为[N][M]的数组data,保存每个同学选择面试的项目序列。
1)i取值0...N-1,对于编号为i的同学,从1...3*M取值k遍历
2)matrix[x][y],x取值0...M-1,y取值k,依次遍历matrix[x][y],记录下其中x值为data[k]非0值的元素且matrix[x][y]为空的位置对应项目,没找到则k++
3)k>3*M则动态扩展matrix对应序列的大小。
3)在这些项目中选择面试序列数组中剩下空位最多的一个s,将其分配给i同学面试,matrix[s][k]=0,同时把i同学对应项目的值设为0表示已安排:data[i][s]=0,直到data[i]中数组值全为0即该同学所有项目面试都安排了为止,再i++回到1)。
我写了一个(时间和空间复杂度较高,假如有更好的解法欢迎指正):
#include
#include
#include
#include
using namespace std;
typedef struct _Project
{
int no;//the number of project
int *stuArray;//the array of the student arrangment
int size;//the size of the array
//int size_left;//the left size of the array
}Project,*pProject;
typedef struct _Student
{
int no;//the number of the student
int *proArray;//the array of the projects that he chose
int size;//
int size_left;//
}Student,*pStudent;
class Match
{
public:
Match(const char *filename,int _M,int _N);
private:
void Init();
void LoadDataFromFile(FILE* fp);
void StartMatch();
void StoreResult(FILE *fp);
int M,N;//the number of projects and students
pProject mpProjects;//the total projects
pStudent mpStudents;//the total students
};
Match::Match(const char *filename,int _M,int _N):M(_M),N(_N)
{
Init();
if(filename==NULL) return;
FILE *fp;
if((fp=fopen(filename,"r"))==NULL)
{
cout<<"open file failed!"<='0'&&ch<='9')
{
if(!change)//input the first number whitch represents student
{
if(s==-1) s=ch-'0';
else s=s*10+ch-'0';
}else//input the second number whitch represent project
{
if(p==-1) p=ch-'0';
else p=p*10+ch-'0';
}
}else if(ch==' ')
{
change=true;
}
}
}
}
void Match::StartMatch()
{
int i;
for(i=0;i0)
{
int j;
match=0;
for(j=0;j0)//find match projects
{
if(match==1)//only one project match
{
int p=chose[0];
mpProjects[p].stuArray[order]=i;
mpProjects[p].size++;
int k=0;
while(mpStudents[i].proArray[k]!=p) k++;
mpStudents[i].proArray[k]=-2;//arrange this project,set 0
mpStudents[i].size_left--;
}else//more than one matched,chose the one whitch left_size is max
{
int i_min=0;
int k,min=0;
for(k=0;k 15,4**9 的笔试题,比较简单:
1,求链表的倒数第二个节点
思路:两个指针,一前一后,不多说。
2,有一个整数数组,求数组中第二大的数
思路:维护两个数,每次把数组中的数与这两个数比较,比它们中小的大则相互替换,一次类推。
16,阿里巴巴二道题
1,对于给定的整数集合S,求出最大的d,使得a+b+c=d。a,b,c,d互不相同,且都属于S。集合的元素个数小于等于2000个,元素的取值范围在[-2^28,2^28 - 1],假定可用内存空间为100MB,硬盘使用空间无限大,试分析时间和空间复杂度,找出最快的解决方法。
点评:
@绿色夹克衫:两两相加转为多项式乘法,比如(1 2 4 6) + (2 3 4 5) => (x + x^2 + x^4 + x^6)*(x^2 + x^3 + x^4 + x^5) 。更多思路请见这:
http://www.51nod.com/answer/index.html#!answerId=569
2,原题大致描述有一大批数据,百万级别的。数据项内容是:用户ID、科目ABC各自的成绩。其中用户ID为0~1000万之间,且是连续的,可以唯一标识一条记录。科目ABC成绩均在0~100之间。有两块磁盘,空间大小均为512M,内存空间64M。
1) 为实现快速查询某用户ID对应的各科成绩,问磁盘文件及内存该如何组织;
2) 改变题目条件,ID为0~10亿之间,且不连续。问磁盘文件及内存该如何组织;
3) 在问题2的基础上,增加一个需求。在查询各科成绩的同时,获取该用户的排名,问磁盘文件及内存该如何组织。
思路:1),1000W个数据记录,每个记录采用6个字节存储,大约需要60M,因此可以全部放入内存,又因为ID连续,因此在内存中可以采用数组进行存取数据。
2),采用hash方法,将大量记录hash到两块磁盘上,查询时直接求出hash值找到对应的磁盘记录进行查询。
3),
3,代码实现计算字符串的相似度。
点评:和计算两字符串的最长公共子序列相似。
设Ai为字符串A(a1a2a3 … am)的前i个字符(即为a1,a2,a3 …ai)
设Bj为字符串B(b1b2b3 … bn)的前j个字符(即为b1,b2,b3 …bj)
设 L(i , j)为使两个字符串Ai和Bj相等的最小操作次数。
当ai等于bj时 显然L(i, j)=L(i-1, j-1)
当ai不等于bj时
若将它们修改为相等,则对两个字符串至少还要操作L(i-1, j-1)次
若删除ai或在Bj后添加ai,则对两个字符串至少还要操作L(i-1, j)次
若删除bj或在Ai后添加bj,则对两个字符串至少还要操作L(i, j-1)次
此时L(i, j)=min( L(i-1, j-1), L(i-1, j), L(i, j-1) ) + 1
显然,L(i, 0)=i,L(0, j)=j, 再利用上述的递推公式,可以直接计算出L(i, j)值。具体代码请见这:
http://blog.csdn.net/flyinghearts/article/details/5605996
17,9月14日,小米笔试
给一个浮点数序列,取最大乘积子序列的值,例如 -2.5,4,0,3,0.5,8,-1,则取出的最大乘积子序列为3,0.5,8。
点评:
解法一、
或许,读者初看此题,自然会想到最大乘积子序列问题类似于最大子数组和问题:http://blog.csdn.net/v_JULY_v/article/details/6444021,然实则具体处理起来诸多不同,为什么呢,因为乘积子序列中有正有负也还可能有0。
既如此,我们可以把问题简化成这样:数组中找一个子序列,使得它的乘积最大;同时找一个子序列,使得它的乘积最小(负数的情况)。因为虽然我们只要一个最大积,但由于负数的存在,我们同时找这两个乘积做起来反而方便。也就是说,不但记录最大乘积,也要记录最小乘积。So,
我们让maxCurrent表示当前最大乘积的candidate,
minCurrent反之,表示当前最小乘积的candidate。
(用candidate这个词是因为只是可能成为新一轮的最大/最小乘积),
而maxProduct则记录到目前为止所有最大乘积candidates的最大值。
由于空集的乘积定义为1,在搜索数组前,maxCurrent,minCurrent,maxProduct都赋为1。
假设在任何时刻你已经有了maxCurrent和minCurrent这两个最大/最小乘积的candidates,新读入数组的元素x(i)后,新的最大乘积candidate只可能是maxCurrent或者minCurrent与x(i)的乘积中的较大者,如果x(i)<0导致maxCurrent
具体代码如下:
- template <typename Comparable>
- Comparable maxprod( const vector
&v) - {
- int i;
- Comparable maxProduct = 1;
- Comparable minProduct = 1;
- Comparable maxCurrent = 1;
- Comparable minCurrent = 1;
- //Comparable t;
- for( i=0; i< v.size() ;i++)
- {
- maxCurrent *= v[i];
- minCurrent *= v[i];
- if(maxCurrent > maxProduct)
- maxProduct = maxCurrent;
- if(minCurrent > maxProduct)
- maxProduct = minCurrent;
- if(maxCurrent < minProduct)
- minProduct = maxCurrent;
- if(minCurrent < minProduct)
- minProduct = minCurrent;
- if(minCurrent > maxCurrent)
- swap(maxCurrent,minCurrent);
- if(maxCurrent<1)
- maxCurrent = 1;
- //if(minCurrent>1)
- // minCurrent =1;
- }
- return maxProduct;
- }
本题除了上述类似最大子数组和的解法,也可以直接用动态规划求解( 其实,上述的解法一本质上也是动态规划,只是解题所表现出来的具体形式与接下来的解法二不同罢了。这个不同就在于下面的解法二会写出动态规划问题中经典常见的状态转移方程,而解法一是直接求解)。具体解法如下:
假设数组为a[],直接利用动归来求解,考虑到可能存在负数的情况,我们用Max[i]来表示以a[i]结尾的最大连续子序列的乘积值,用Min[i]表示以a[i]结尾的最小的连续子序列的乘积值,那么状态转移方程为:
Max[i]=max{a[i], Max[i-1]*a[i], Min[i-1]*a[i]};
Min[i]=min{a[i], Max[i-1]*a[i], Min[i-1]*a[i]};
初始状态为Max[1]=Min[1]=a[1]。代码如下:
- /*
- 给定一个整数数组,有正有负数,0,正数组成,数组下标从1算起
- 求最大连续子序列乘积,并输出这个序列,如果最大子序列乘积为负数,那么就输出-1
- 用Max[i]表示以a[i]结尾乘积最大的连续子序列
- 用Min[i]表示以a[i]结尾乘积最小的连续子序列 因为有复数,所以保存这个是必须的
- */
- void longest_multiple(int *a,int n){
- int *Min=new int[n+1]();
- int *Max=new int[n+1]();
- int *p=new int[n+1]();
- //初始化
- for(int i=0;i<=n;i++){
- p[i]=-1;
- }
- Min[1]=a[1];
- Max[1]=a[1];
- int max_val=Max[1];
- for(int i=2;i<=n;i++){
- Max[i]=max(Max[i-1]*a[i],Min[i-1]*a[i],a[i]);
- Min[i]=min(Max[i-1]*a[i],Min[i-1]*a[i],a[i]);
- if(max_val
- max_val=Max[i];
- }
- if(max_val<0)
- printf("%d",-1);
- else
- printf("%d",max_val);
- //内存释放
- delete [] Max;
- delete [] Min;
- }
此外,此题还有另外的一个变种形式,即给 定一个长度为N的整数数组,只允许用乘法,不能用除法,计算任意(N-1)个数的组合中乘积最大的一组,并写出算法的时间复杂度。
我们可以把所有可能的(N-1)个数的组合找出来,分别计算它们的乘积,并比较大小。由于总共有N个(N-1)个数的组合,总的时间复杂度为O(N2),显然这不是最好的解法。
OK,以下解答来自编程之美
解法1

解法2
此外,还可以通过分析,进一步减少解答问题的计算量。假设N个整数的乘积为P,针对P的正负性进行如下分析(其中,AN-1表示N-1个数的组合,PN-1表示N-1个数的组合的乘积)。
1.P为0 那么,数组中至少包含有一个0。假设除去一个0之外,其他N-1个数的乘积为Q,根据Q的正负性进行讨论:
Q为0
说明数组中至少有两个0,那么N-1个数的乘积只能为0,返回0;
Q为正数
返回Q,因为如果以0替换此时AN-1中的任一个数,所得到的PN-1为0,必然小于Q;
Q为负数
如果以0替换此时AN-1中的任一个数,所得到的PN-1为0,大于Q,乘积最大值为0。
2. P为负数
根据“负负得正”的乘法性质,自然想到从N个整数中去掉一个负数,使得PN-1为一个正数。而要使这个正数最大,这个被去掉的负数的绝对值必须是数组中最小的。我们只需要扫描一遍数组,把绝对值最小的负数给去掉就可以了。
3. P为正数
类似地,如果数组中存在正数值,那么应该去掉最小的正数值,否则去掉绝对值最大的负数值。上面的解法采用了直接求N个整数的乘积P,进而判断P的正负性的办法,但是直接求乘积在编译环境下往往会有溢出的危险(这也就是本题要求不使用除法的潜在用意),事实上可做一个小的转变,不需要直接求乘积,而是求出数组中正数(+)、负数(-)和0的个数,从而判断P的正负性,其余部分与以上面的解法相同。
在时间复杂度方面,由于只需要遍历数组一次,在遍历数组的同时就可得到数组中正数(+)、负数(-)和0的个数,以及数组中绝对值最小的正数和负数,时间复杂度为O(N)。
18,9月15日,中兴面试:
小端系统
union{
int i;
unsigned char ch[2];
}Student;
int main()
{
Student student;
student.i=0x1420;
printf("%d %d",student.ch[0],student.ch[1]);
return 0;
} 答案:32,20
19,一道有趣的Facebook面试题:
给一个二叉树,每个节点都是正或负整数,如何找到一个子树,它所有节点的和最大?
点评:
答案:后序遍历,每一个节点保存左右子树的和加上自己的值。额外一个空间存放最大值。
补充:同学们,如果你面试的是软件工程师的职位,一般面试官会要求你在短时间内写出一个比较整洁的,最好是高效的,没有什么bug的程序。所以,光有算法不够,还得多实践。
写完后序遍历,面试官可能接着与你讨论,a). 如果要求找出只含正数的最大子树,程序该如何修改来实现?b). 假设我们将子树定义为它和它的部分后代,那该如何解决?c). 对于b,加上正数的限制,方案又该如何?总之,一道看似简单的面试题,可能能变换成各种花样。
比如,面试管可能还会再提两个要求:第一,不能用全局变量;第一,有个参数控制是否要只含正数的子树。其它的,随意,当然,编程风格也很重要。
20,谷歌面试题:
有几百亿的整数,分布的存储到几百台通过网络连接的计算机上,你能否开发出一个算法和系统,找出这几百亿数据的中值?就是在一组排序好的数据中居于中间的数。显然,一台机器是装不下所有的数据。也尽量少用网络带宽。
思路:
m1:
将0-2^32划分为若干个桶,每个电脑放一个桶,每个桶内有个计数器,记录有多少数放在桶内
从第一个桶的计数器开始加,一直加到大于n/2
所以中位数肯定在这个桶内
m2:
http://matpalm.com/median/distributing.html
http://matpalm.com/median/erlang_multi.html
利用快排的思想,但是只计数不交换位置,节省移动操作。
in the multi process implementation splits the list of numbers to consider into a sub lists
each sub list can be handled by a seperate erlang process, potentially across different machines
(these lists don't have to be the same size)
single [1,2,3,4,5,6,7,8,9] multi [[1,2,3,4],[5,6],[7,8,9]]
recall there a number of operations required in distributed case
includes things like determining total number of elements, determining minimum value, etc
each of these operations can be done against each sub list individually with the results aggregated
eg to determine total number of elements
single -> length( [1,2,3,4,5,6,7,8,9] ) = 9 multi -> sum ( length([1,2,3,4]), length([5,6]), length([7,8,9]) ) = sum([4,2,3]) = 9
eg to determine minimum value
single -> min( [1,2,3,4,5,6,7,8,9] ) = 1 multi -> min( min([1,2,3,4]), min([5,6]), min([7,8,9]) ) = min([1,5,7]) = 1
other changes required
rotation
in the single list case we pick the pivot as the first value.
in the multi list case we pick the pivot as the first value of the first list.
recall in the algorithm that rotation is sometimes required.
this is to ensure all potential values for a pivot are explored.
so in the multi list case the rotation needs to operate at two levels; rotate the first list and then rotate the list of lists
before [[1,2,3],[4,5,6],[7,8,9]] after [[4,5,6],[7,8,9],[2,3,1]]
21,小米,南京站笔试(原第20题):
一个数组里,数都是两两出现的,但是有三个数是唯一出现的,找出这三个数。
点评:
3个数唯一出现,各不相同。由于x与a、b、c都各不相同,因此x^a、x^b、x^c都不等于0。具体答案请参看这两篇文章:1、http://blog.csdn.net/w397090770/article/details/8032898,2、http://zhedahht.blog.163.com/blog/static/25411174201283084246412/。
22,9月19日,IGT面试:
你走到一个分叉路口,有两条路,每个路口有一个人,一个说假话,一个说真话,你只能问其中一个人仅一个问题,如何问才能得到正确答案?
点评:答案是,问其中一个人:另一个人会说你的路口是通往正确的道路么?
23,9月19日,创新工厂笔试题:
给定一整型数组,若数组中某个下标值大的元素值小于某个下标值比它小的元素值,称这是一个反序。
即:数组a[]; 对于i < j 且 a[i] > a[j],则称这是一个反序。
给定一个数组,要求写一个函数,计算出这个数组里所有反序的个数。
点评:归并排序,至于有的人说是否有O(N)的时间复杂度,我认为答案是否定的,正如老梦所说,下限就是nlgn,n个元素的数组的排列共有的排列是nlgn,n!(算法导论里面也用递归树证明了:O(n*logn)是最优的解法,具体可以看下这个链接:)。然后,我再给一个链接,这里有那天笔试的两道题目:http://blog.csdn.net/luno1/article/details/8001892。
24 ,9月20日,创新工厂南京站笔试:
已知字符串里的字符是互不相同的,现在任意组合,比如ab,则输出aa,ab,ba,bb,编程按照字典序输出所有的组合。
点评:非简单的全排列问题(跟全排列的形式不同,abc 全排列的话,只有6个不同的输出:http://blog.csdn.net/v_july_v/article/details/6879101)。本题可用递归的思想,设置一个变量表示已输出的个数,然后当个数达到字符串长度时,就输出。
//假设str已经有序,from 一直很安静
void perm(char *str, int size, int resPos)
{
if(resPos == size)
print(result);
else
{
for(int i = 0; i < size; ++i)
{
result[resPos] = str[i];
perm(str, size, resPos + 1);
}
}
} 25,9月21日,小米,电子科大&西安交通大学笔试题:

我写了一个:
#include
#include
using namespace std;
bool isValidSeq(char* str)
{
char *input=str;
if(input==NULL) return false;
vector v;
while(*input!='\0')
{
if(v.size()<=0)
{
v.push_back(*input);
}else
{
switch(*input)
{
case '{':
case '(':
case '[':
v.push_back(*input);
break;
case '}':
if(*(v.end()-1)=='{')
{
v.pop_back();
}else
{
return false;
}
break;
case ')':
if(*(v.end()-1)=='(')
{
v.pop_back();
}else
{
return false;
}
break;
case ']':
if(*(v.end()-1)=='[')
{
v.pop_back();
}else
{
return false;
}
break;
}
}
input++;
}
if(v.size()>0) return false;
else return true;
}
char* fixSeq(char* str)
{
char *input=str;
if(input==NULL) return false;
vector v;
char *ret=new char[50];
int count=0;
while(*input!='\0')
{
if(v.size()<=0)
{
v.push_back(*input);
ret[count++]=*input;
}else
{
switch(*input)
{
case '{':
case '(':
case '[':
v.push_back(*input);
ret[count++]=*input;
break;
case '}':
if(*(v.end()-1)=='{')
{
v.pop_back();
ret[count++]='}';
}else
{
ret[count++]='{';
ret[count++]='}';
}
break;
case ')':
if(*(v.end()-1)=='(')
{
v.pop_back();
ret[count++]=')';
}else
{
ret[count++]='(';
ret[count++]=')';
}
break;
case ']':
if(*(v.end()-1)=='[')
{
v.pop_back();
ret[count++]='[';
}else
{
ret[count++]='[';
ret[count++]=']';
}
break;
}
}
input++;
}
return ret;
}
int main(int argc,char *argv[])
{
char str[20]="({[({})]})";
cout< 2,问:最后程序输出是多少?点评:此题有陷阱,答题需谨慎!
void fun()
{
unsigned int a = 2013;
int b = -2;
int c = 0;
while (a + b > 0)
{
a = a + b;
c++;
}
printf("%d", c);
} 解答:无限循环,因为a是无符号类型,a+b的结果也是无符号类型,又因为a+b不可能等于0,所以a+b的结果永远大于0。
测试代码:
int main(int argc,char *argv[])
{
unsigned int a=1;
a-=2;
printf("a:%d,a>0:%d\n",a,a>0);
return 0;
}a:-1,a>0:1
【科普:C运算转换规则】
自动转换遵循以下规则:
1)若参与运算量的类型不同,则先转换成同一类型,然后进行运算。
2)转换按数据长度增加的方向进行,以保证精度不降低。如int型和long型运算时,先把int量转成long型后再进行运算。
a.若两种类型的字节数不同,转换成字节数高的类型
b.若两种类型的字节数相同,且一种有符号,一种无符号,则转换成无符号类型
3)所有的浮点运算都是以双精度进行的,即使仅含float单精度量运算的表达式,也要先转换成double型,再作运算。
4) char型和short型参与运算时,必须先转换成int型。
5)在赋值运算中,赋值号两边量的数据类型不同时,赋值号右边量的类型将转换为左边量的类型。如果右边量的数据类型长度左边长时,将丢失一部分数据,这样会降低精度,丢失的部分按四舍五入向前舍入。
隐式转换
隐式类型转换分三种,即算术转换、赋值转换和输出转换。
1.算术转换
进行算术运算(加、减、乘、除、取余以及符号运算)时,不同类型数招必须转换成同一类型的数据才能运算,算术转换原则为:
在进行运算时,以表达式中最长类型为主,将其他类型位据均转换成该类型,如:
(1)若运算数中有double型或float型,则其他类型数据均转换成double类型进行运算。
(2)若运算数中最长的类型为long型.则其他类型数均转换成long型数。
(3)若运算数中最长类型为int型,则char型也转换成int型进行运算。算术转换是在运算过程中自动完成的。
2.赋值转换
进行赋值操作时,赋值运算符右边的数据类型必须转换成赋值号左边的类型,若右边的数据类型的长度大于左边,则要进行截断或舍入操作。
下面用一实例说明:
charch;
inti,result;
floatf;
doubled;
result=ch/i+(f*d-i);
(1)首先计算ch/i,ch→int型,ch/i→int型。
(2)接着计算f*d-i,由于最长型为double型,故f→double型,i→double型,f*d-i→double型。
(3)(ch/i)和(f*d-i)进行加运算,由于f*d-i为double型,故ch/i→double型,ch/i+(f*d-i)→double型。
(4)由于result为int型,故ch/i+(f*d-i)→double→int,即进行截断与舍入,最后取值为整型。
3.输出转换
在程序中将数据用printf函数以指定格式输出时,当要输出的盐据类型与输出格式不符时,便自动进行类型转换,如一个long型数据用整型格式(%d)输出时,则相当于将long型转换成整型(int)数据输出;一个字符(char)型数据用整型格式输出时,相当于将char型转换成int型输出。
注意:较长型数据转换成短型数据输出时,其值不能超出短型数据允许的值范围,否则转换时将出错。如:
longa=80000;
printf("%d",a);
运行结果为14464,因为int型允许的最大值为32767,80000超出此值,故结果取以32768为模的余数,即进行如下取余运算:
(80000-32768)-32768=14464;
输出的数据类型与输出格式不符时常常发生错误,如:
intd=9;
printf("%f",d);
或
floatc=3.2;
printf("%d",c);
将产生错误的结果。
同一句语句或表达式如果使用了多种类型的变量和常量(类型混用),C会自动把它们转换成同一种类型。以下是自动类型转换的基本规则:
1.在表达式中,char和short类型的值,无论有符号还是无符号,都会自动转换成int或者unsignedint(如果short的大小和int一样,unsignedshort的表示范围就大于int,在这种情况下,unsignedshort被转换成unsignedint)。因为它们被转换成表示范围更大的类型,故而把这种转换称为“升级(promotion)”。
2.按照从高到低的顺序给各种数据类型分等级,依次为:longdouble, double, float, unsigned long long, long long, unsigned long,long, unsigned int 和int。这里有一个小小的例外,如果long和int大小相同,则unsignedint的等级应位于long之上。char和short并没有出现于这个等级列表,是因为它们应该已经被升级成了int或者unsignedint。
3.在任何涉及两种数据类型的操作中,它们之间等级较低的类型会被转换成等级较高的类型。
4.在赋值语句中,=右边的值在赋予=左边的变量之前,首先要将右边的值的数据类型转换成左边变量的类型。也就是说,左边变量是什么数据类型,右边的值就要转换成什么数据类型的值。这个过程可能导致右边的值的类型升级,也可能导致其类型降级(demotion)。所谓“降级”,是指等级较高的类型被转换成等级较低的类型。
5.作为参数传递给函数时,char和short会被转换成int,float会被转换成double。使用函数原型可以避免这种自动升级。
见17题。


填空:
1;s*c/(a+b),2:625,3:88,4:n*log(n):B
编程:
3:这里有一个解决方案,时间复杂度是m*m,空间复杂度是m:
#include
#include
int Friends(int n, int m , int* r[]);
int main(int argc,char** argv)
{
int r[5][2] = {{1,2},{4,3},{6,5},{7,8},{7,9}};
printf("有%d个朋友圈。\n",Friends(0,5,(int**)r));
return 0;
}
int Friends(int n, int m, int* r[]) // 注意这里的参数很奇葩
{
int *p = (int*)malloc(sizeof(int)*m*3);
memset(p,0,sizeof(int)*m*3);
int i = 0;
int iCount = 0;
int j = 0;
int * q = (int*)r; // 这里很巧妙 将二维指针 强转为一维指针
for (i=0;i 26,9月21日晚,海豚浏览器笔试题:
1、有两个序列A和B,A=(a1,a2,...,ak),B=(b1,b2,...,bk),A和B都按升序排列,对于1<=i,j<=k,求k个最小的(ai+bj),要求算法尽量高效。
思路:a1+b1必为最小,记录两个递增序列,分别是ai+a[aj]和bj+b[bi],aj和bi分别是两个a和b在b和a中维护的下移个相加值的索引,具体实现见代码:
#include
void findMinSum(int k,int a[],int b[])
{
int count=1,i=0,j=0,aj=1,bi=1;
printf("a%d+b%d=%d ",0,0,a[0]+b[0]);
while(countb[aj+1]-b[aj]) aj++;
else i++;
}else
{
printf("a%d+b%d=%d ",j,bi,sum2);
if(b[j+1]-b[j]>a[bi+1]-a[bi]) bi++;
else j++;
}
count++;
}
printf("\n");
}
int main(int argc,char *argv[])
{
int a[10]={1,3,5,7,8,9,11,12,13,16};
int b[10]={2,4,6,8,9,13,15,17,19,21};
findMinSum(10,a,b);
return 0;
} 2、输入:
L:“shit”“fuck”“you”
S:“shitmeshitfuckyou”
输出:S中包含的L一个单词,要求这个单词只出现一次,如果有多个出现一次的,输出第一个这样的单词
怎么做?
简单解法:保存一个大小与L中字符串数量一样的数组,用来记录对应字符串出现在S中的次数。
将S从头至尾扫一遍,每读入一个字符,判断以这个字符开头的字符串有没有出现在L中的字符串,有则相应的数组值+1,最后输出第一个数组值为1对应的L中的字符串。
27,9月22日上午,百度西安站全套笔试题如下:

简答题:
1,
数据库是以一定组织方式储存在一起的,能为多个用户共享的,具有尽可能小的冗余度的、与应用彼此独立的相互关联的数据集合。包括关系,网状,层次等类型的数据库。
死锁是指在一组进程中的各个进程均占有不会释放的资源,但因互相申请被其他进程所站用不会释放的资源而处于的一种永久等待状态。
线程产生死锁的原因:系统资源不足;进程运行推进的顺序不合适;资源分配不当等
死锁的四个必要条件:
互斥条件(Mutual exclusion):资源不能被共享,只能由一个进程使用。
请求与保持条件(Hold and wait):已经得到资源的进程可以再次申请新的资源。
非剥夺条件(No pre-emption):已经分配的资源不能从相应的进程中被强制地剥夺。
循环等待条件(Circular wait):系统中若干进程组成环路,该环路中每个进程都在等待相邻进程正占用的资源。
死锁避免方法包括有序资源分配法和银行家算法等等。
2,
三个要素 : 封装, 继承,多态
面向对象设计不外乎遵循五大原则:
第一、单一职责原则,即一个类应该只负责单一的职责,而将其余的职责让其他类来承担,这样每个类之间相互协调来完成一件任务。第二、开闭原则,即对扩展是开放的,对修改是封闭的,因此需要注重抽象的运用
第三、替换原则 ,子类应该可以替换在父类出现的任何地方
第四、依赖倒置原则,依赖于抽象。具体而言就是高层模块不依赖于底层模块,二者都同依赖于抽象;抽象不依赖于具体,具体依赖于抽象。
第五、接口分离原则,不要将一大堆方法都糅合在一个接口里面形成一个大而全的接口,要将他们按照职责和功能分离到多个小接口中去
3,
(1)块式管理。把主存分为一大块、一大块的,当所需的程序片段不在主存时就分配一块主存空间,把程序片段加载到主存,就算所需要的程序片段只有几个字节也只能把这块分配给它。优点:易于管理;缺点:浪费空间。
(2)页式管理。把主存分为一页一页的,每一页的空间要比一块一块的空间小很多,显然这种方式的空间利用率要比块式管理高出很多。
(3)段式管理。把主存分为一段一段的,每一段的空间又要比一页一页的空间小很多,这种方法在空间利用率上比页式管理高出很多,但也有另外一个缺点,一个程序片段可能会被分为几十个段,这样很多时间就会浪费在计算每一段的物理地址上。(I/O操作)
(4)段页式管理。结合了段式管理和页式管理的优点。把主存分为若干页,每一页又分为若干段。
算法设计:
1,1000场?
2,10盏:1,4,9,16,25,36,49,64,81,100
原理:状态改变奇数次的灯最后是开的,而灯的改变次数等于它的约数,例如10的约数是1,2,5,10,因此在第1,2,5,10次被改变,最后是灭的,所以最后开的灯其编号约数是奇数,而约数为奇数的数是完全平方数,因此最后编号为平方数的10盏灯开着。
3,
系统设计题:

28,9月22日,微软笔试:
T(n)=1(n<=1),T(n) = 25*T(n/5) + n^2,求算法的时间复杂度。
思路:T(n)=25*(25*T(n/25)+(n/5)^2)+n^2=25^2*T(n/(5^2))+2*n^2=25^(log(n)/log5)+(log(n)/log5)*n^2=O(n^2*log(n))
更多题目请参见:http://blog.csdn.net/wonderwander6642/article/details/8008209。
29,9月23日,腾讯校招部分笔试题


解答:
11:C,12:C(一样?),13:B,14:A,15:D,16:A,17:C,18:A,19:B
25:O(nlog(n)),O(n)
26:42(计算公式:[1/(n+1)]*C(n-2n),即2n取n的组合数除以n+1)
27:abcd-*e/+f-
三,1:不会javascript
2:建立n个256大小的数组用来保存每个字符串中的字符相应的重复个数,之后按重复度大小排序,接着再利用这n个数组对原字符串数组排序。
时间复杂度:O(n*n*logn),空间复杂度O(n)。
四:1:哈希分桶+最小堆
2:数据库设计,可以采用HBase
30,9月23日,搜狗校招武汉站笔试题:
已知计算机有以下原子操作
1、 赋值操作:b = a;
2、 ++a和a+1;
3、for( ){ ***}有限循环;
操作数只能为0或者正整数,定义函数,实现加减乘操作
解答:加法和乘法利用循环可以实现,减法如下:
sub(int a,int b)
{
int c=0;
for(int i=b;i>a;i--)
c++;
}
附:9月15日,搜弧校招笔试题:http://blog.csdn.net/hackbuteer1/article/details/8015964。
31,搜狗校招笔试题:
100个任务,100个工人每人可做一项任务,每个任务每个人做的的费用为t[100][100],求一个分配任务的方案使得总费用最少。
点评:匈牙利算法,可以看看这篇文章:http://www.byvoid.com/blog/hungary/,及这个链接:http://www.51nod.com/question/index.html#!questionId=641。
32,9月24日,Google南京等站全套笔试题如下:
1.1:B,亲测,我自己的电脑运行了3秒
1.2:D
1.3:B
1.4:A
就是求x1+x2+x3+x4=25的大于等于0的解,相当于将25个相同的求放进4个盒子里,盒子不一样,求所有可能的放法:
笨办法:只有1个数不为零0解的个数:4
方便书写,规定C(a,b)为对b中取a的的组合数。
有2个数不为零0解的个数:C(2,4)*C(1,24)
有3个数不为零0解的个数:C(3,4)*C(2,24)
全不为0:C(3,24)
最后结果:4+144+1104+2024=3276;所以选A
1.5:D
1.6:B
1.7:D
1.8:C
1.9:A
1.10:D
2.1:
if (a <= b) {
if (b <= c)
return b;
else {
if (a <=c)
return c;
else
return a;
}
}
else {
if (a <= c)
return a;
else {
if (b <= c)
return c;
else
return b;
}
}
2.2:本质上采用快速排序,比较函数时候有些变化,需考虑比较元素在哦key里的次序,代码如下:
#include "stdio.h"
#include "stdlib.h"
#include "string.h"
void quick_sort(char* data,int s,int e,const char *key,int lk);
int partition(char* data,int s,int e,const char *key,int lk);
void sort(char *data,int ld,const char *key,int lk);
int compare(char a,char b,const char *key,int lk);
void main()
{
char data[256]={"aaakhlqkxcvhiuosadkjdfmbnvcjkszghkljeawhfmkbdsaklgh"};
char key[7]={"zxonm"};
sort(data,strlen(data),key,strlen(key));
printf("after sort:%s\n",data);
}
//对data用key进行排序
void sort(char *data,int ld,const char *key,int lk)
{
quick_sort(data,0,ld-1,key,lk);
}
//判断a和b在key里位置的大小
int compare(char a,char b,const char *key,int lk)
{
int pos_a=-1,pos_b=-1;
for(int i=0;ie) return;
int p=partition(data,s,e,key,lk);
quick_sort(data,s,p-1,key,lk);
quick_sort(data,p+1,e,key,lk);
}
int partition(char* data,int s,int e,const char *key,int lk)
{
int l=s-1,r=s;
while(r 空间复杂度O(1),时间复杂度O(nlongn).
2.3:
思路:由于题目只强调时间复杂度尽可能低,且n的取值范围相对较小[1,1000], 考虑用空间换时间。
设置一个大小为1000×1000的二维数组: int num[1000][1000](内存开销为4MB)
预处理阶段,每输入一个矩形:[x1,y1],[x2,y2],则 for i from x1 to x2
for j from y1 to y2
num[i][j]++;
预处理阶段完毕,则对每一个query:[x,y],直接返回num[x][y]的值,使得查询时间复杂度为O(1).
33,读者来信,提供的几个hulu面试题:
9月19号,hulu电面:
问题1 两个骰子,两个人轮流投,直到点数和大于6就停止,最终投的那个人获胜。问先投那个人获胜概率?
我也不会.....
问题2 平面上n个圆,任意两个都相交,是否有一条直线和所有的圆都有交点。
好吧好吧...9月22号,上午hulu面试问题1 100个人,每人头上戴一顶帽子,写有0..99的一个数,数可能重复,每个人都只能看到除自己以外其他人的帽子。每个人需要说出自己的帽子的数,一个人说对就算赢。
点评:参考答案请看这个链接:http://www.51nod.com/question/index.html#!questionId=642。
问题2 n台机器,每台有负载,以和负载成正比的概率,随机选择一台机器。「原题是希望设计O(1)的算法(预处理O(n)不可少,要算出每台机器的比例),因为非O(1)的话,就trivial了:可以产生随机数例如[0,1)然后,根据负载比例,2分或者直接循环检查落入哪个区间,决定机器。 面试官想问,有没更好的办法,避免那种查找。即能否多次(常数次)调用随机函数,拟合出一个概率分布」
问题3 行列都递增的矩阵,求中位数。
点评:http://www.51nod.com/question/index.html#!questionId=643,http://blog.csdn.net/v_july_v/article/details/7085669(杨氏矩阵查找问题)。
总结:二分查找,线性统计
34,西安百度软件研发工程师:
一面(2012.9.24):
问的比较广,涉及操作系统、网络、数据结构。比较难的就2道题。
(1)10亿个int型整数,如何找出重复出现的数字;
大数据分段哈希进文件,然后小数据读入内存哈希统计重复
(2)有2G的一个文本文档,文件每行存储的是一个句子,每个单词是用空格隔开的。问:输入一个句子,如何找到和它最相似的前10个句子。(提示:可用倒排文档)。
二面(2012.9.25):
(1)一个处理器最多能处理m个任务。现在有n个任务需要完成,每个任务都有自己完成所需的时间。此外每个任务之间有依赖性,比如任务A开始执行的前提是任务B必须完成。设计一个调度算法,使得这n这任务的完成时间最小;
思路:根据任务顺序和时间画出AOE图,求出关键路径,使用多个处理器集中完成关键活动及周边的活动,使任务完成时间最短。
(2)有一个排序二叉树,数据类型是int型,如何找出中间大的元素;
思路:从根节点开始无限求右孩子,直到右孩子为空为止。
(3)一个N个元素的整形数组,如何找出前K个最大的元素。
思路:利用k个元素的最小堆
(4)给定一个凸四边形,如何判断一个点在这个平面上。
http://www.51nod.com/question/index.html#!questionId=669
运维部(2012.9.27):
(1)堆和栈的区别;
- -!这种题就不回答了
(2)问如何数出自己头上的头发。
- -!这种非人类的题目就不回答了
35:9月25日,人人网笔试题:

点评:参考答案请见,http://www.51nod.com/question/index.html#!questionId=671。
36,9月25日晚,创新工场校园招聘北邮站笔试:




选择:
1:D,2:B,3:B,4:C(哲学家进餐问题),5:B ,6:A(http://www.cnblogs.com/mycapple/archive/2012/08/09/2629608.html)
简答:
1:Tire树
2:#define EXB(arg) (((arg)&0xaaaaaaaa)>>1)|(((arg)&0x55555555)<<1)
3:创新工厂
创新工厂
(引用与指针问题)
4:ABCDGHFE
编程题:
1:思路:先单个单词翻转,再整个字符串翻转。
我写了一个:
#include "stdafx.h"
#include "string.h"
void Reverse(char *data,int start,int end);
void ReverseString(char *data,int n)
{
int start=0,end=0;
while(start2:我的思路:用vit[i]/hap[i],计算出每种食品平均一点体力带来多少欢乐,记为avr[i],并按ave[i]从大到小排序,每种食品只带一次,因此从大到小依次取食品,同时体力m减去对应消耗值,体力不够时取下一个食品直到体力为0或者遍历完所有食品为止,时间复杂度为O(nlog(n))。
代码很简单略过。
37,9月25日,小米大连站笔试题:
1一共有100万,抽中的2万,每月增加4万,问20个月能抽中的概率为:?
不明题意,4万加的是啥?
2 for(int i=0;i
3 手机wifi(A)….wifi ap….局域网(B)…..路由器…ADSL(C)…..互联网…..服务器
断掉上述ABC哪些点TCP链接会立刻断掉?
我的答案:A(B或C断开可能发生重连)
4 12345入栈,出栈结果 21543 31245 43215 12534 可能的为?(第一个和第三个)
答案:21543和43215不解释,括号里已经给出了答案- -#
5 x^n+a1x^n-1+…+an-1x+an,最少要做—乘法?题目中a1,a2,an为常数。
(n-1)+(n-1)+(n-2)+...+2+1=(n*n+n-2)/2.
38,9月26日,百度一二面:
1、给定一数组,输出满足2a=b(a,b代表数组中的数)的数对,要求时间复杂度尽量低。

- 点评:请看链接:http://blog.csdn.net/Lost_Painting/article/details/6457334。
public static int[,] Calculate(char[] First, char[] Second)
{
int lenFirst = First.Length + 1;
int lenSecond = Second.Length + 1;
int[,] matrixResult = new int[lenFirst, lenSecond];
for (int i = 0; i < lenFirst; i++) matrixResult[i, 0] = i;
for (int j = 0; j < lenSecond; j++) matrixResult[0, j] = j;
for (int i = 1; i < lenFirst; i++)
{
for (int j = 1; j < lenSecond; j++)
{
if (First[i - 1] == Second[j - 1])
{
matrixResult[i, j] = matrixResult[i - 1, j - 1];
}
else
{
matrixResult[i, j] = new int[] {matrixResult[i - 1, j] + 1
, matrixResult[i , j-1] + 1
, matrixResult[i - 1, j-1] + 1
}.Min();
}
}
}
for (int i = 0; i < lenFirst; i++) matrixResult[i, 0] = i;
for (int j = 0; j < lenSecond; j++) matrixResult[0, j] = j;
这两行是初始化,代表最坏情况下的编辑次数,即从无到有直接插入N或M次
matrixResult[i, j] = new int[] {matrixResult[i - 1, j] + 1
, matrixResult[i , j-1] + 1
, matrixResult[i - 1, j-1] + 1
}.Min(); 这是递归式,即动态规划里的最优解,意思是从A[0->i]变化到B[0->j]的次数是下面三个数里面的最小值
1)
matrixResult[i - 1, j] + 1
即由A[0->i-1]通过插入一个数变化到B[0->j]的次数,迭代表现为加上1
2)
matrixResult[i , j-1] + 1
即由A[0->i]通过删除一个数变化到B[0->j-1]的次数,迭代表现为加上1
3)
matrixResult[i - 1, j-1] + 1
即由A[0->i-1]通过修改一个数变化到B[0->j-1]的次数,迭代表现为加上1。
#include
using namespace std;
typedef struct Node_
{
int data;
struct Node_* left;
struct Node_* right;
}TreeNode,*pTreeNode;
typedef struct Tree_
{
pTreeNode root;
}Tree,*pTree;
int deep(pTreeNode pn,int num);
int getDeepth(pTree pt)
{
if(!pt||!pt->root) return 0;
return deep(pt->root,0);
}
int deep(pTreeNode pn,int num)
{
if(!pn) return num;
int a=deep(pn->left,num+1);
int b=deep(pn->right,num+1);
return a>b?a:b;
}
int main()
{
TreeNode right3={3,NULL,NULL};
TreeNode right2={2,NULL,&right3};
TreeNode right1={1,NULL,&right2};
TreeNode left1={1,NULL,NULL};
TreeNode root={1,&left1,&right1};
Tree tree={&root};
int d=getDeepth(&tree);
cout<<"deep:"< 39,9月26日晚,优酷土豆笔试题一道:
优酷是一家视频网站,每天有上亿的视频被观看,现在公司要请研发人员找出最热门的视频。
该问题的输入可以简化为一个字符串文件,每一行都表示一个视频id,然后要找出出现次数最多的前100个视频id,将其输出,同时输出该视频的出现次数。
1.假设每天的视频播放次数为3亿次,被观看的视频数量为一百万个,每个视频ID的长度为20字节,限定使用的内存为1G。请简述做法,再写代码。
2.假设每个月的视频播放次数为100亿次,被观看的视频数量为1亿,每个视频ID的长度为20字节,一台机器被限定使用的内存为1G。
我的思路:海量数据问题,
1:1G大约能存放5000万个ID,所以3亿的记录得分6次读取,再分桶哈希,将所有ID哈希到一定量不同的桶中,这样相同视频的记录就被分在相同的桶中,在对这些桶排序,利用大小为100的最小堆求这些桶中前一百ID的最大值即可。
2:将原文件再细分即可
原作者点评:有关海量数据处理的题目,请到此文中找方法(无论题目形式怎么变,基本方法不变,当然,最最常用的方法是:分而治之/Hash映射 + Hash统计 + 堆/快速/归并排序):http://blog.csdn.net/v_july_v/article/details/7382693。
注:上题第二问文件太大,则可如模1000,把整个大文件映射为1000个小文件再处理 ....
40,9月26日,baidu面试题:
1.进程和线程的区别
简单来说,进程是资源分配的基本单位,进程之间是独立的,各自有不同的资源环境。
线程是CPU调度的基本单位,是轻量级进程,一个进程内部的多个线程共享静态和全局资源以及上下文。
2.一个有序数组(从小到大排列),数组中的数据有正有负,求这个数组中的最小绝对值
二分查找,当找到数为正数时往左边继续二分,反之右边,直到二分结束找到那个最接近0的数
3.链表倒数第n个元素
典型快慢指针问题,快指针先遍历n个元素,然后和慢指针一起遍历,结束时满指针就指向倒数第n个元素
4.有一个函数fun能返回0和1两个值,返回0和1的概率都是1/2,问怎么利用这个函数得到另一个函数fun2,使fun2也只能返回0和1,且返回0的概率为1/4,返回1的概率为3/4。(如果返回0的概率为0.3而返回1的概率为0.7呢)
第一问:
int fun2()
{
int ret=fun1();
if(!ret) return fun1();
return ret;
}。。。。
5.有8个球,其中有7个球的质量相同,另一个与其他球的质量不同(且不知道是比其他球重还是轻),请问在最坏的情况下,最少需要多少次就能找出这个不同质量的球
我的思路:5次
二二分组比两次,把不一样重分组里的四个球左右分组单独比一次,再把不一样重的两个球分别与其他球比一次,与一般球不一样重的那个即所求,共6次。
6.数据库索引
数据库索引好比是一本书前面的目录,能加快数据库的查询速度。
索引是对数据库表中一个或多个列的值进行排序的结构。如果想按特定职员的姓来查找他或她,则与在表中搜索所有的行相比,索引有助于更快地获取信息。
例如这样一个查询:select * from table1 where id=10000。如果没有索引,必须遍历整个表,直到ID等于10000的这一行被找到为止;有了索引之后(必须是在ID这一列上建立的索引),在索引中查找,但索引是经过某种算法优化过的,查找次数要少的多的多。可见,索引是用来定位的。
索引分为聚簇索引和非聚簇索引两种,聚簇索引 是按照数据存放的物理位置为顺序的,而非聚簇索引就不一样了;聚簇索引能提高多行检索的速度,而非聚簇索引对于单行的检索很快。
7.有一个数组a,设有一个值n。在数组中找到两个元素a[i]和a[j],使得a[i]+a[j]等于n,求出所有满足以上条件的i和j。
思路:先排序,再二分查找n-a[i],时间复杂度O(nlog(n)).
当然,也可以直接hash,判断n-a[i]是否在hash表中,时间复杂度O(n),空间复杂度O(n)
8.1万个元素的数组,90%的元素都是1到100的数,10%的元素是101--10000的数,如何高效排序。
建立一个100大小的hash表,每个表元素里有一个标记,用于记录该数在数组里有多少个,数组里将1到100的数hash到这个hash表中,每次hash对应标记加1,非1-100的数就用一个大小为1000的数组存起来,这样90%的数都在hash表的标记里了,只需对1000个大于100的数排序再和hash表里的数连结起来即可完成排序。
41,小米的web开发笔试题:
1 一场星际争霸比赛,共8个人,每个人的实力用分数表示,要分成两队,如何保证实力最平均?
从小到达排序,最大和最小的一组,次大和次小的另一组,以此类推
2 给定一个浮点数的序列,F1,F2,……,Fn(1<=n<=1000),定义P(s,e)为子序列Fi(s<=i<=e)的积,求P的最大值。
之前有过类似的题,求出最大的正数和最小的负数,类似动态规划思想。
42 9月27日,趋势科技面试题:
马路口,30分钟内看到汽车的概率是95%,那么在10分钟内看不到汽车的概率是?
设10分钟内看到汽车概率为x,则10分钟内看不到汽车概率为1-x,那么30分钟内看不到汽车概率就是(1-x)*(1-x)*(1-x)=1-0.95=0.05,解出x即可
43 9月27日晚,IGT笔试题:
给定一个字符串里面只有"R" "G" "B" 三个字符,请排序,最终结果的顺序是R在前 G中 B在后。要求:空间复杂度是O(1),且只能遍历一次字符串。
点评:本质是荷兰国旗问题,类似快排中partition过程,具体思路路分析及代码可以参考此文第8节:http://blog.csdn.net/v_july_v/article/details/6211155。
44 9月27日,人人两面:
一面
1 实现atoi
这个应该不难
2 单链表变形 如 1 2 3 4 5 变为 1 3 5 4 2 如1 2 3 4 变为 1 3 4 2
(就是拆分链表 把偶数位反过来接在奇数位后面)
思路:偶数位拆分的同时逆序,再接在奇数链表末尾
二面
1 二叉树查找不严格小于一个值的最大值(返回节点)。
啥意思,直接求出树里的最大值?
2 有序数组里二分查找一个数(如果有相同的找最后一次出现的)。
int find(char *data,int n,int val)
{
if(!data||n<=0) return -2;
findSub(data,0,n-1,val,n);
}
int findSub(char *data,int l,int r,int val,int n)
{
if(l>r) return -1;
int mid=l+r/2;
if(data[mid]==val) return getLast(data,mid,val,n);
else if(data[mid]>val) return findSub(data,l,mid-1);
else return findSub(data,mid+1,r);
}
int getLast(char *data,int pos,int val,int n)
{
while(data[pos]==val&&pos++
3 等价于n*n的矩阵,填写0,1,要求每行每列的都有偶数个1 (没有1也是偶数个),问有多少种方法。
评论:开始以为是算法题,想了狂搜,递推(dp,可以用xor表示一行的列状态,累加),分治,(拆两半,然后上半段下半段的列有相同的奇偶性)。后来,自己算了几个发现n = 1 n = 2 n = 3 的结果,他告诉了我n = 4是多少,然后发现f(n) = 2^((n - 1) ^2) 。最后我给出了一个巧妙的证明。然后发现如果是m*n的矩阵也是类似的答案,不局限于方阵。此外,题目具体描述可以看看这里:http://blog.himdd.com/?p=2480。
45,9月27日,小米两面:
- 一面:
除了聊研究,就一道题
1 数组里找到和最接近于0的两个值。
二面:
1 行列有序的矩阵查找一个数
老题目,可以分块查找,也可以按规律从右上角元素开始,大则下,小则左
2 直方图最大矩形。
点评:这里有此题的具体表述及一份答案:http://blog.csdn.net/xybsos/article/details/8049048。
3 next_permutation(全排列)
http://blog.csdn.net/aipb2008/article/details/2227490
4 字符串匹配 含有* ? (写代码)
5 实现strcpy memmove (必须写代码)
//void * memmove ( void * destination, const void * source, size_t num );)
//是的标准函数,其作用是把从source开始的num个字符拷贝到destination。
//最简单的方法是直接复制,但是由于它们可能存在内存的重叠区,因此可能覆盖了原有数据。
//比如当source+count>=dest&&source= (source + count))
{
//正向拷贝
//copy from lower addresses to higher addresses
while (count --)
*dest++ = *source++;
}
else
{
//反向拷贝
//copy from higher addresses to lower addresses
dest += count - 1;
source += count - 1;
while (count--)
*dest-- = *source--;
}
return ret;
} 更多,还可以参见此文第三节节末:http://blog.csdn.net/v_july_v/article/details/6417600,或此文:http://www.360doc.com/content/11/0317/09/6329704_101869559.shtml。6 读数 (千万亿,百万亿……)变为数字 (说思路即可,字符串查找,填写各个权值的字段,然后判断是否合法,读前面那些×权值,累加)。
45. 9月27日,Hulu 2013北京地区校招笔试题
1、中序遍历二叉树,结果为ABCDEFGH,后序遍历结果为ABEDCHGF,那么前序遍历结果为?
FCBADEGH
2、对字符串HELL0_HULU中的字符进行二进制编码,使得字符串的编码长度尽可能短,最短长度为?
哈夫曼编码:H2个,E1个,L3个,O1个,U2个,_1个
根据哈夫曼树,L:00,E:011,_:0100,O:0101,H:10,U:11
因此对应字符串为10 011 00 00 0101 0100 10 11 00 11,长度为2*2+3+2*3+4+2*2+4=25
3、对长度12的有序数组进行二分查找,目标等概率出现在数组的每个位置上,则平均比较次数为?
算期望?(3*4+4*5+2*2+1)/12=37/12=3
4、一副扑克(去王),每个人随机的摸两张,则至少需要多少人摸牌,才能保证有两个人抽到同样的花色。
每种花色13张,四种花色,最还情况每个人拿同色,则至少5人
5、x个小球中有唯一一个球较轻,用天平秤最少称量y次能找出这个较轻的球,写出y和x的函数表达式y=f(x)
y=1+log(x)(以2为底)
6、3的方幂及不相等的3的方幂的和排列成递增序列1,3,4,9,10,12,13……,写出数列第300项
子集总数,3的最大次幂为X对应的序列里数的总数是其非空子集的个数,即2的x次幂-1
2*x-1=300->x=log(301)=8....44
因此x为9,记C(a,b)为对a取b的组合数
C(9,1)+C(9,2)+C(9,3)+C(9,4)=255,因此序列里第300个数是3*0-3*8这9个数中取5个数组合的集合里第45个....头痛....
7、无向图G有20条边,有4个度为4的顶点,6个度为3的顶点,其余顶点度小于3,则G有多少个顶点
8、桶中有M个白球,小明每分钟从桶中随机取出一个球,涂成红色(无论白或红都涂红)再放回,问小明将桶中球全部涂红的期望时间是?
9、煤矿有3000吨煤要拿到市场上卖,有一辆火车可以用来运煤,火车最多能装1000吨煤,且火车本身需要烧煤做动力,每走1公里消耗1吨煤,如何运煤才能使得运到市场的煤最多,最多是多少?
10、1,2,3,4…..n,n个数进栈,有多少种出栈顺序,写出递推公式(写出通项公式不得分)
11、宇宙飞船有100,000位的存储空间,其中有一位有故障,现有一种Agent可以用来检测故障,每个Agent可以同时测试任意个位数,若都没有故障,则返回OK,若有一位有故障,则失去响应。如果有无限多个Agent可供使用,每个Agent进行一次检测需要耗费1小时,现在有2个小时时间去找出故障位,问最少使用多少个Agent就能找出故障。
(总共12道填空题,还有一道太复杂,题目很长,还有示意图,这里没有记录下来)
大题:
1、n个数,找出其中最小的k个数,写出代码,要求最坏情况下的时间复杂度不能高于O(n logk)
2、写程序输出8皇后问题的所有排列,要求使用非递归的深度优先遍历
3、有n个作业,a1,a2…..an,作业aj的处理时间为tj,产生的效益为pj,最后完成期限为dj,作业一旦被调度则不能中断,如果作业aj在dj前完成,则获得效益pj,否则无效益。给出最大化效益的作业调度算法。
点评:参考答案请看这个链接:http://www.51nod.com/question/index.html#!questionId=645。
46 有道的一个笔试题,1-9,9个数组成三个三位数,且都是完全平方数(三个三位数 占据 9个数)求解法。
(a*10+b)(a*10+b)100a^2+20ab+b^2
a 属于 [1,2,3]
a=3,b=1 31 961,
a=2,b=3 23 529 400+40b+b^2
25 625
27 729
28 784
29 841
a=1,b=3 13 169 100+20b+b^2
14 196
16 256
17 289
18 324
19 361
=>最终唯一解 529 784 361
具体代码如下(3个for循环,然后hash):
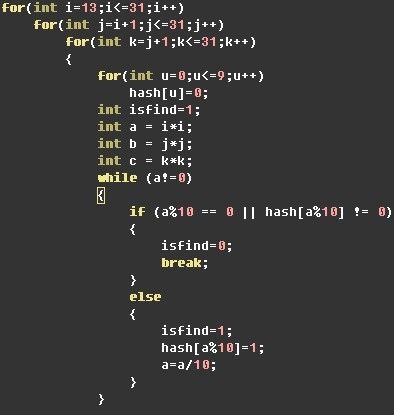
47 9月28日,大众点评北京笔试题目:
48.9月28日,网易笔试题:
从1级升到2级,有1/3的可能成功;1/3的可能停留原级;1/3的可能下降到0级;
从2级升到3级,有1/9的可能成功;4/9的可能停留原级;4/9的可能下降到1级。
每次升级要花费一个宝石,不管成功还是停留还是降级。
求英雄从0级升到3级平均花费的宝石数目。
点评:题目的意思是,从第n级升级到第n+1级成功的概率是(1/3)^n(指数),停留原级和降级的概率一样,都为[1-(1/3)^n]/2)。
定义f(n)为从n-1级升到n级平均花费的宝石数
habbafgh
输出h,abba,f,g,h。
有回文字符串就输出最长的,没有回文就输出一个一个的字符。
49,10月9日,腾讯一面试题:
有一个log文件,里面记录的格式为:
QQ号: 时间: flag:
如123456 14:00:00 0
123457 14:00:01 1
其中flag=0表示登录 flag=1表示退出
问:统计一天平均在线的QQ数。
50,10月9日,腾讯面试题:
1.有一亿个数,输入一个数,找出与它编辑距离在3以内的数,比如输入6(0110),找出0010等数,数是32位的。
2.每个城市的IP段是固定的,新来一个IP,找出它是哪个城市的,设计一个后台系统。
哈希分桶
51,10月9日,YY笔试题:
1 输出一个字符串中没有重复的字符。如“baaca”输出“bac”。
建立一个256大小的数组,每个元素对应一个ASCII码的字符,遍历数组,对应字符元素自增,输出值为1的数组元素对应的字符,
时间复杂度是O(n),空间复杂度是O(256)
也可以先排序,再输出,时间复杂度是O(nlogn)
2 对于一个多叉树,设计TreeNode节点和函数,返回先序遍历情况下的下一个节点。
函数定义为TreeNode* NextNode(TreeNode* node)
父节点指针+第一个孩子节点指针+右边兄弟节点指针
tydef struct _TreeNode
{
struct _TreeNode* parent;
struct _TreeNode* first_child;
struct _TreeNode* subline;
}TreeNode,*pTreeNode;
...
3 分割字符串。
对于一个字符串,根据分隔符seperator,把字符串分割,如果存在多个分隔符连在一起,则当做一个分隔符。如果分隔符出现在" "符号之间,则不需要分割" "之间的字符。
比如a++abc ,分隔符为+,输出a abc
a+"hu+" 输出a hu+
a++"HU+JI 输出a "HU JI。
请根据上述需求完成函数:void spiltString(string aString,char aSeperator)。
我写了一个:
#include
using namespace std;
void spiltString(string str,char sep,bool care)//a+"hu+"
{
int left=0, right=0,pos_q=0;
bool quote=false;
for(right=0;right
52 10月9日,赶集网笔试

bool judge(int *data,int n)
{
if(n>1)
{
if(data[0]<=data[1])
{
return judge(data+1,n-1)
}else
{
return false;
}
}else
{
return true;
}
}
2:略
53,10月9日,阿里巴巴2013校园招聘全套笔试题(注:下图中所标答案不代表标准答案,有问题,欢迎留言评论)
4:我觉得选C
5:感觉BD都不对
6:A
7:D

8:A
9:C
11:D
13:C