利用LSTM(长短期记忆网络)来处理脑电数据
目录
- LSTM 原理介绍
- LSTM的核心思想
- 一步一步理解LSTM
- 代码案例
本分享为脑机学习者Rose整理发表于公众号:脑机接口社区(微信号:Brain_Computer).QQ交流群:903290195

Rose小哥今天介绍一下用LSTM来处理脑电数据。
LSTM 原理介绍
LSTMs(Long Short Term Memory networks,长短期记忆网络)简称LSTMs,很多地方用LSTM来指代它。本文也使用LSTM来表示长短期记忆网络。LSTM是一种特殊的RNN网络(循环神经网络)。想要说清楚LSTM,就很有必要先介绍一下RNN。下面我将简略介绍一下RNN原理。
所有循环神经网络都具有神经网络的重复模块链的形式。在标准的RNN中,该重复模块将具有非常简单的结构,比如单个tanh层。标准的RNN网络如下图所示:
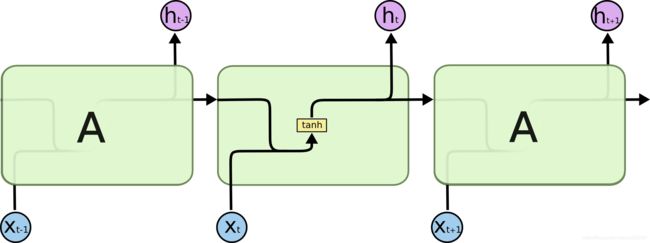
LSTM也具有这种链式结构,不过它的重复单元与标准RNN网络里的单元只有一个网络层不同,它的内部有四个网络层。LSTM的结构如下图所示。
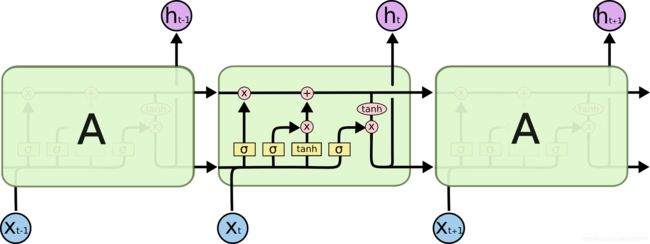
在解释LSTM的详细结构时先定义一下图中各个符号的含义,符号包括下面几种,图中黄色类似于CNN里的激活函数操作,粉色圆圈表示点操作,单箭头表示数据流向,箭头合并表示向量的合并(concat)操作,箭头分叉表示向量的拷贝操作。

LSTM的核心思想
LSTM的核心是细胞状态,用贯穿细胞的水平线表示。
细胞状态像传送带一样。它贯穿整个细胞却只有很少的分支,这样能保证信息不变的流过整个RNNs。细胞状态如下图所示。
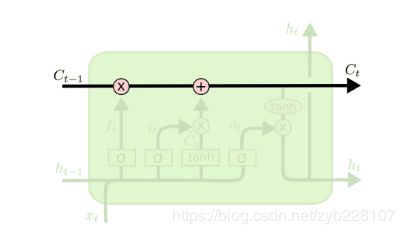
LSTM网络能通过一种被称为门的结构对细胞状态进行删除或者添加信息。
门能够有选择性的决定让哪些信息通过。
而门的结构很简单,就是一个sigmoid层和一个点乘操作的组合。如下图所示

因为sigmoid层的输出是0-1的值,这代表有多少信息能够流过sigmoid层。0表示都不能通过,1表示都能通过。
一个LSTM里面包含三个门来控制细胞状态。
一步一步理解LSTM
前面提到LSTM由三个门来控制细胞状态,这三个门分别称为忘记门、输入门和输出门。下面将分别讲述。
LSTM的第一步就是决定细胞状态需要丢弃哪些信息。这部分操作是通过一个称为忘记门的sigmoid单元来处理的。它通过查看 h t − 1 h_{t-1} ht−1和 x t x_t xt信息来输出一个0-1之间的向量,该向量里面的0-1值表示细胞状态 C t − 1 C_{t-1} Ct−1中的哪些信息保留或丢弃多少。
其中0表示不保留,1表示都保留。忘记门如下图所示。

这一步是决定给细胞状态添加哪些新的信息。
该步又分为两个步骤,首先,利用 h t − 1 h_{t-1} ht−1和 x t x_t xt通过一个称为输入门的操作来决定更新哪些信息。然后利用 h t − 1 h_{t-1} ht−1和 x t x_t xt通过一个tanh层得到新的候选细胞信息 C ~ t \tilde C_{t} C~t,这些信息可能会被更新到细胞信息中。这两步描述如下图所示。
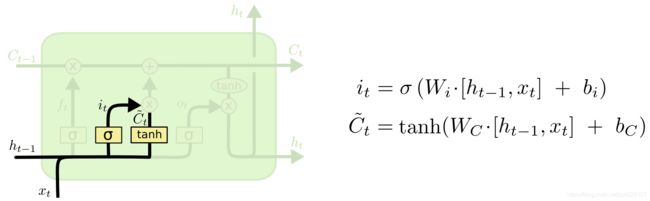
下面将更新旧的细胞信息 C t − 1 C_{t-1} Ct−1,变为新的细胞信息 C t C_{t} Ct。
更新的规则就是通过忘记门选择忘记旧细胞信息的一部分,通过输入门选择添加候选细胞信息 C ~ t \tilde C_{t} C~t的一部分得到新的细胞信息 C t C_{t} Ct。更新操作如下图所示。
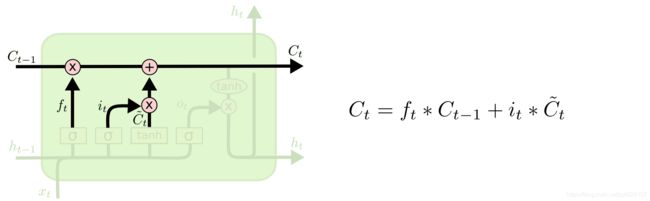
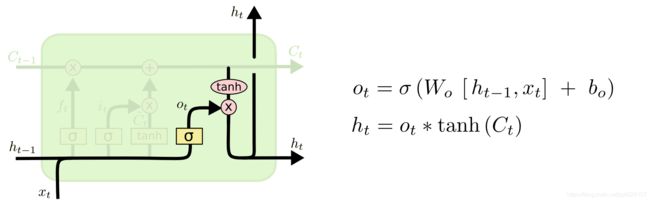
更新完细胞状态后需要根据输入的 h t − 1 h_{t-1} ht−1和 x t x_t xt来判断输出细胞的哪些状态特征,这里需要将输入经过一个称为输出门的sigmoid层得到判断条件,然后将细胞状态经过tanh层得到一个-1~1之间值的向量,该向量与输出门得到的判断条件相乘就得到了最终该RNN单元的输出。该步骤如下图所示。
代码案例
上面描述的是最普通的LSTM结构。随着研究人员对LSTM的研究,在实际的文章中提出了很多LSTM结构的各种变式,这里就不讨论了。
下面将从代码的角度来看一下LSTM对脑电数据进行分类效果。
数据集来源于BCI Competition II。使用的深度学习框架为Keras。
# 导入工具包
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.layers import Embedding
from keras.layers import SimpleRNN, LSTM, GRU
from keras.optimizers import SGD, Nadam, Adam, RMSprop
from keras.callbacks import TensorBoard
from keras.utils import np_utils
import scipy.io
import numpy as np
第一步:导入数据
data = scipy.io.loadmat('F:\BCI Competition II\sp1s_aa_1000Hz.mat')
y_test = np.loadtxt('F:\BCI Competition II\labels_data_set_iv.txt',encoding="utf-8")
第二步:预处理数据
"""
将训练数据调整为LSTM的正确输入尺寸
并将数据转换为float 32
"""
x_train = data['x_train'].reshape((316,500,28))
x_train /= 200
x_train = x_train.astype('float32')
"""
将测试数据调整为LSTM的正确输入尺寸
并将数据转换为float 32
"""
x_test = data['x_test'].reshape((100,500,28))
x_test /= 200
x_test = x_test.astype('float32')
"""
将标签数据调整为LSTM的正确输入尺寸
并将数据转换为float 32
"""
y_train = data['y_train'].reshape(316,1)
tmp_train = []
for i in y_train:
if i == 1:
tmp_train.append(1)
elif i == 0:
tmp_train.append(-1)
y_train = np.array(tmp_train)
y_train = np_utils.to_categorical(y_train, 2)
y_train = y_train.astype('float32')
y_test = y_test.reshape(100,1)
tmp_test = []
for i in y_test:
if i == 1:
tmp_test.append(1)
elif i == 0:
tmp_test.append(-1)
y_test = np.array(tmp_test)
y_test = np_utils.to_categorical(y_test, 2)
y_test = y_test.astype('float32')
第三步:构建训练模型
model = Sequential()
model.add(LSTM(10, return_sequences = True, input_shape=(500, 28)))
model.add(LSTM(10, return_sequences = True))
model.add(LSTM(5))
model.add(Dense(2, activation = 'softmax'))
model.summary()
"""
优化器设置
学习率为0.001
"""
optim = Nadam(lr = 0.001)
# 设置损失函数为交叉熵损失函数
model.compile(loss = 'categorical_crossentropy', optimizer = optim, metrics = ['accuracy'])
第四步:训练模型
"""
epochs设置为10
batch_size设置为20
"""
model.fit(x_train, y_train, epochs=15, batch_size=20)
第五步:计算最后得分和精度
score, acc = model.evaluate(x_test, y_test,
batch_size=1)
print('测试得分:', score)
print('测试精度:', acc)


参考:
利用LSTM(长短期记忆网络)来处理脑电数据
1.https://www.jianshu.com/p/95d5c461924c
2.http://colah.github.io/posts/2015-08-Understanding-LSTMs/
3.https://github.com/kevinchangwang
本文章由脑机学习者Rose笔记分享,QQ交流群:903290195
更多分享,请关注公众号
