TCP/IP协议详解卷一:Chapter21 笔记
TCP/IP协议详解卷一:Chapter21 笔记
- Chapter 21 TCP的超时与重传
- 21.3 往返时间测量
- 21.5 拥塞举例
- 21.6 拥塞避免算法
- 21.7 快速重传与快速恢复算法
- 21.8 拥塞举例(续)
- 21.9 按每条路由进行度量
- 21.10 ICMP的差错
- 21.11 重新分组
Chapter 21 TCP的超时与重传
TCP提供可靠的运输层。它使用的方法之一就是确认从另一端收到的数据。但数据和确认都有可能会丢失。TCP通过在发送时设置一个定时器来解决这种问题。如果当定时器溢出时还没有收到确认,它就重传该数据。对任何实现而言,关键之处就在于超时和重传的策略,即怎样决定超时间隔和如何确定重传的频率。
对每个连接,TCP管理4个不同的定时器:
- 重传定时器使用于当希望收到另一端的确认。本章将详细讨论这个定时器以及一些相关的问题,如拥塞避免。
- 坚持(persist)定时器使窗口大小信息保持不断流动,即使另一端关闭了其接收窗口(见第22章)。
- 保活(keepalive)定时器可检测到一个空闲连接的另一端何时崩溃或重启(见第23章)。
- 2MSL定时器测量一个连接处于TIME_WAIT状态的时间(参考18.6节)。
21.3 往返时间测量
TCP超时与重传中最重要的部分就是对一个给定连接的往返时间(RTT)的测量。由于路由器和网络流量均会变化,因此我们认为这个时间可能经常会发生变化, TCP应该跟踪这些变化并相应地改变其超时时间。
首先TCP必须测量在发送一个带有特别序号的字节和接收到包含该字节的确认之间的RTT。用M表示所测量到的RTT。最初的TCP规范使TCP使用低通过滤器来更新一个被平滑的RTT估计器(记为O)。 R ← α R + ( 1 − α ) M R \leftarrow {\alpha}R+(1-\alpha)M R←αR+(1−α)M这里的 α \alpha α是一个推荐值为0.9的平滑因子。每次进行新测量的时候,这个被平滑的RTT将得到更新。每个新估计的90%来自前一个估计,而10%则取自新的测量。该算法在给定这个随RTT的变化而变化的平滑因子的条件下, RFC 793推荐的重传超时时间(Retransmission TimeOut, RTO)的值应该设置为 R T O = R β RTO = R\beta RTO=Rβ这里的 β \beta β是一个推荐值为2的时延离散因子。
除了被平滑的RTT估计器,所需要做的还有跟踪RTT的方差。在往返时间变化起伏很大时,基于均值和方差来计算RTO,将比作为均值的常数倍数来计算RTO能提供更好的响应。正如[Jacobson 1988]所描述的,均值偏差是对标准偏差的一种好的逼近,但却更容易进行计算(计算标准偏差需要一个平方根)。这就引出了下面用于每个RTT测量M的公式。 E r r = M − A Err = M-A Err=M−A A ← A + g E r r A \leftarrow A+gErr A←A+gErr D ← D + h ( ∣ E r r ∣ − D ) D \leftarrow D+h(|Err|-D) D←D+h(∣Err∣−D) R T O = A + 4 D RTO = A+4D RTO=A+4D 这里的A是被平滑的RTT(均值的估计器),而D则是被平滑的均值偏差。Err是刚得到的测量结果与当前的RTT估计器之差。A和D均被用于计算下一个重传时间(RTO)。增量g起平均作用,取为1/8(0.125)。偏差的增益是h,取值为0.25。当RTT变化时,较大的偏差增益将使RTO快速上升。
Karn算法
在一个分组重传时会产生这样一个问题:假定一个分组被发送。当超时发生时, RTO正如21.2节中显示的那样进行指数退避,分组以更长的RTO进行重传,然后收到一个确认。那么这个ACK是针对第一个分组的还是针对第二个分组呢?这就是所谓的重传多义性问题。
[Karn and Partridge 1987]规定,当一个超时和重传发生时,在重传数据的确认最后到达之前,不能更新RTT估计器,因为我们并不知道ACK对应哪次传输(也许第一次传输被延迟而并没有被丢弃,也有可能第一次传输的ACK被延迟)。
并且,由于数据被重传, RTO已经得到了一个指数退避,我们在下一次传输时使用这个退避后的RTO。对一个没有被重传的报文段而言,除非收到了一个确认,否则不要计算新的RTO。
21.5 拥塞举例
图21-6显示了报文段中数据的起始序号与该报文段发送时间的对比图。它提供了一种较好的数据传输的可视化方法。通常代表数据的点将向上和向右移动,这些点的斜率就表示传输速率。当这些点向下和向右移动则表示发生了重传。
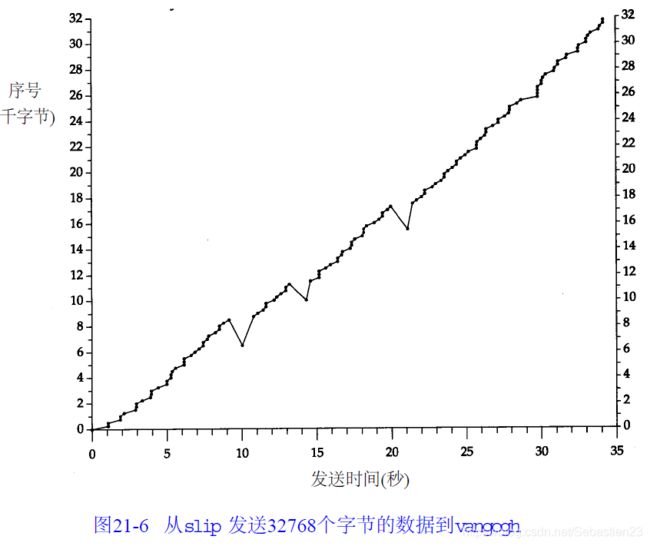 可以立即看到图21-6中发生在时刻10,14和21附近的3个重传。我们还可以看到在这3个点中只进行了一次报文段的重传,因为只有一个点下垂低于向上的斜率。仔细检查一下这几个下垂点中的第1个点(在10秒标记处的附近)。整理tcpdump的输出结果可以得到下图。
可以立即看到图21-6中发生在时刻10,14和21附近的3个重传。我们还可以看到在这3个点中只进行了一次报文段的重传,因为只有一个点下垂低于向上的斜率。仔细检查一下这几个下垂点中的第1个点(在10秒标记处的附近)。整理tcpdump的输出结果可以得到下图。
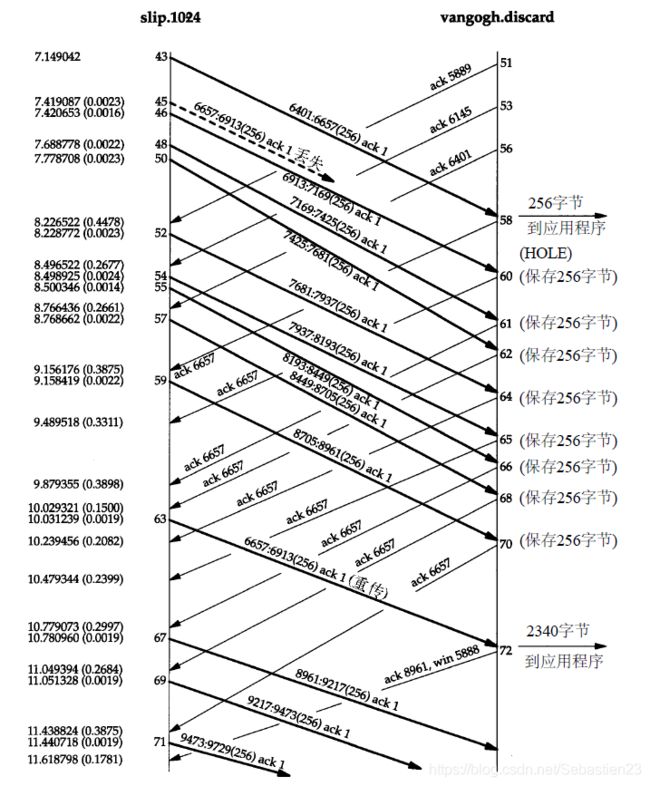 看来报文段45丢失或损坏了。能够在主机slip上看到的是对第6657字节(报文段58)以前数据的确认(不包括字节6657在内)。紧接着的是带有相同序号的8个ACK。正是接收到报文段62,也就是第3个重复ACK,才引起自序号6657开始的数据报文段(报文段63)进行重传。源于伯克利的TCP实现对收到的重复ACK进行计数,当收到第3个时,就假定一个报文段已经丢失并重传自那个序号起的一个报文段。这就是Jacobson的快速重传算法,该算法通常与他的快速恢复算法一起配合使用。
看来报文段45丢失或损坏了。能够在主机slip上看到的是对第6657字节(报文段58)以前数据的确认(不包括字节6657在内)。紧接着的是带有相同序号的8个ACK。正是接收到报文段62,也就是第3个重复ACK,才引起自序号6657开始的数据报文段(报文段63)进行重传。源于伯克利的TCP实现对收到的重复ACK进行计数,当收到第3个时,就假定一个报文段已经丢失并重传自那个序号起的一个报文段。这就是Jacobson的快速重传算法,该算法通常与他的快速恢复算法一起配合使用。
在接收端,当按序收到正常数据(报文段43)后,接收TCP将255个字节的数据交给用户进程。但下一个收到的报文段(报文段46)是失序的:数据的开始序号(6913)并不是下一个期望的序号(6657)。TCP保存256字节的数据,并返回一个已成功接收数据的最大序号加1(6657)的ACK。被vangogh接收到的后面7个报文段(48, 50, 52, 54, 55, 57和59)也是失序的,接收方TCP保存这些数据并产生重复ACK。
21.6 拥塞避免算法
在第20.6节介绍的慢启动算法是在一个连接上发起数据流的方法,但有时我们会达到中间路由器的极限,此时分组将被丢弃。拥塞避免算法是一种处理丢失分组的方法。该方法的具体描述见[Jacobson 1988]。
该算法假定由于分组受到损坏引起的丢失是非常少的(远小于1 %),因此分组丢失就意味着在源主机和目的主机之间的某处网络上发生了拥塞。有两种分组丢失的指示:发生超时和接收到重复的确认。
拥塞避免算法和慢启动算法是两个目的不同、独立的算法。但是当拥塞发生时,我们希望降低分组进入网络的传输速率,于是可以调用慢启动来作到这一点。在实际中这两个算法通常在一起实现。拥塞避免算法和慢启动算法需要对每个连接维持两个变量:一个拥塞窗口 cwnd 和一个慢启动门限 ssthresh。算法的工作过程如下:
- 对一个给定的连接,初始化cwnd为1个报文段, ssthresh为65535个字节。
- TCP输出例程的输出不能超过cwnd和接收方通告窗口的大小。拥塞避免是发送方使用的流量控制,而通告窗口则是接收方进行的流量控制。前者是发送方感受到的网络拥塞的估计,而后者则与接收方在该连接上的可用缓存大小有关。
- 当拥塞发生时(超时或收到重复确认),ssthresh被设置为当前窗口大小的一半(cwnd和接收方通告窗口大小的最小值,但最少为2个报文段)。此外,如果是超时引起了拥塞,则cwnd被设置为1个报文段(即慢启动)。
- 当新的数据被对方确认时,就增加cwnd,但增加的方法依赖于我们是否正在进行慢启动或拥塞避免。如果cwnd小于或等于ssthresh,则正在进行慢启动,否则正在进行拥塞避免。慢启动一直持续到我们回到当拥塞发生时所处位置的半时候才停止(因为记录了步骤2中制造麻烦的窗口大小的一半),然后转为执行拥塞避免。
慢启动算法初始设置cwnd为1个报文段,此后每收到一个确认就加1。这会使窗口按指数方式增长:发送1个报文段,然后是2个,接着是4个⋯⋯。拥塞避免算法要求每次收到一个确认时将cwnd增加1/cwnd。与慢启动的指数增加比起来,这是一种加性增长(additive increase)。我们希望在一个往返时间内最多为cwnd增加1个报文段(不管在这个RTT中收到了多少个ACK),然而慢启动将根据这个往返时间中所收到的确认的个数增加cwnd。
21.7 快速重传与快速恢复算法
拥塞避免算法的修改建议1990年提出[Jacobson 1990b]。在介绍修改之前,我们认识到在收到一个失序的报文段时, TCP立即需要产生一个ACK(一个重复的ACK)。这个重复的ACK不应该被迟延。该重复的ACK的目的在于让对方知道收到一个失序的报文段,并告诉对方自己希望收到的序号。
由于不知道一个重复的ACK是由一个丢失的报文段引起的,还是由于仅仅出现了几个报文段的重新排序,因此我们等待少量重复的ACK到来。假如这只是一些报文段的重新排序,则在重新排序的报文段被处理并产生一个新的ACK之前,只可能产生1~2个重复的ACK。如果一连串收到3个或3个以上的重复ACK,就非常可能是一个报文段丢失了。于是我们就重传丢失的数据报文段,而无需等待超时定时器溢出。这就是快速重传算法。接下来执行的不是慢启动算法而是拥塞避免算法。这就是快速恢复算法。
在这种情况下没有执行慢启动的原因是由于收到重复的ACK不仅仅告诉我们一个分组丢失了。由于接收方只有在收到另一个报文段时才会产生重复的ACK,而该报文段已经离开了网络并进入了接收方的缓存。也就是说,在收发两端之间仍然有流动的数据,而我们不想执行慢启动来突然减少数据流。
这个算法通常按如下过程进行实现:
- 当收到第3个重复的ACK时,将ssthresh设置为当前拥塞窗口cwnd的一半。重传丢失的报文段。设置cwnd为ssthresh加上3倍的报文段大小。
- 每次收到另一个重复的ACK时, cwnd增加1个报文段大小并发送1个分组(如果新的cwnd允许发送)。
- 当下一个确认新数据的ACK到达时,设置cwnd为ssthresh(在第1步中设置的值)。这个ACK应该是在进行重传后的一个往返时间内对步骤1中重传的确认。另外,这个ACK也应该是对丢失的分组和收到的第1个重复的ACK之间的所有中间报文段的确认。这一步采用的是拥塞避免,因为当分组丢失时我们将当前的速率减半。
21.8 拥塞举例(续)
结合上文提到的慢启动算法、拥塞避免算法、快速重传与快速恢复算法,我们再次回顾21.4节中的例子。在21.4节的例子中,运行时发生了4次拥塞。为建立连接而发送的初始SYN有一个因超时而引起的重传(图21-5),接着在数据传输过程中有3个分组丢失(图21-6)。下图显示了当初始SYN重传并接着发送了前7个数据报文段时变量cwnd和ssthresh的值。
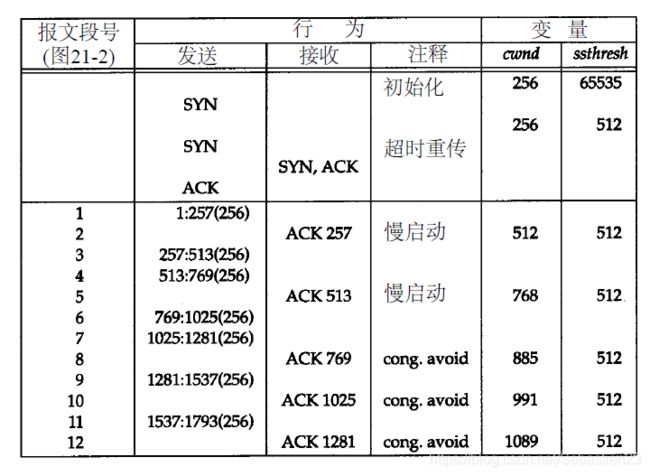 当SYN的超时发生时, ssthresh被置为其最小取值(512字节,在本例中表示2个报文段)。为进入慢启动阶段,cwnd被置为1个报文段(256字节,与当前值一致)。当收到SYN和ACK时,没有对这两个变量做任何修改,因为新的数据还没有被确认。当ACK 257到达时,因为cwnd小于等于ssthresh,因此仍然处于慢启动阶段,于是将cwnd增加256字节。当收到ACK 513时,进行同样的处理。当ACK 769到达时,我们不再处于慢启动状态,而是进入了拥塞避免状态。新的cwnd值按以下方法计算: c w n d ← c w n d + s e g s i z e × s e g s i z e c w n d + s e g s i z e 8 cwnd \leftarrow cwnd + \frac{segsize \times segsize}{cwnd} + \frac{segsize}{8} cwnd←cwnd+cwndsegsize×segsize+8segsize 考虑到cwnd实际上以字节而非以报文段来维护,因此这就是我们前面提到的增加1/cwnd。
当SYN的超时发生时, ssthresh被置为其最小取值(512字节,在本例中表示2个报文段)。为进入慢启动阶段,cwnd被置为1个报文段(256字节,与当前值一致)。当收到SYN和ACK时,没有对这两个变量做任何修改,因为新的数据还没有被确认。当ACK 257到达时,因为cwnd小于等于ssthresh,因此仍然处于慢启动阶段,于是将cwnd增加256字节。当收到ACK 513时,进行同样的处理。当ACK 769到达时,我们不再处于慢启动状态,而是进入了拥塞避免状态。新的cwnd值按以下方法计算: c w n d ← c w n d + s e g s i z e × s e g s i z e c w n d + s e g s i z e 8 cwnd \leftarrow cwnd + \frac{segsize \times segsize}{cwnd} + \frac{segsize}{8} cwnd←cwnd+cwndsegsize×segsize+8segsize 考虑到cwnd实际上以字节而非以报文段来维护,因此这就是我们前面提到的增加1/cwnd。
在此例中计算拥塞窗口大小为: c w n d = 768 + 256 × 256 768 + 256 8 = 885 cwnd = 768 + \frac{256 \times 256}{768} + \frac{256}{8} = 885 cwnd=768+768256×256+8256=885 字节。当下一个ACK 1025到达时,计算拥塞窗口大小为: c w n d = 885 + 256 × 256 885 + 256 8 = 991 cwnd = 885 + \frac{256 \times 256}{885} + \frac{256}{8} = 991 cwnd=885+885256×256+8256=991 字节。(注:所有的4.3BSD版本和4.4BSD都在拥塞避免中将增加值不正确地设置为1个报文段的一小部分,即一个报文段的大小除以8,这是错误的,并在以后的版本中不再使用[Floyd 1994]。为了和不正确的实现的结果对应,此处的计算中给出了这个细节。)
cwnd的值一直持续增加,从上图中对应于报文段12的最终取值(1089)到下图中对应于报文段58的第一个取值(2426),而ssthresh的值则保持不变(512),这是因为在此过程中没有出现过重传。
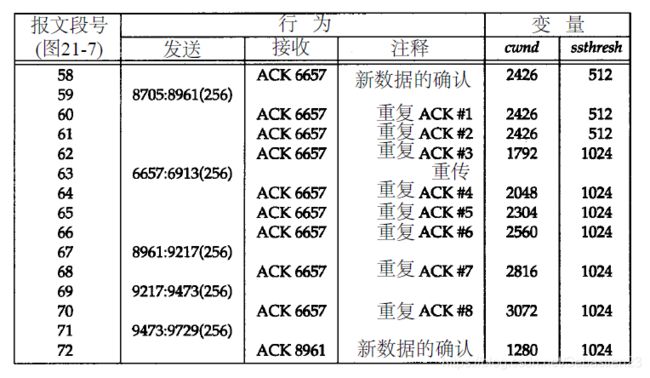 当最初的2个重复的ACK(报文段60和61)到达时它们被计数,而cwnd保持不变。然而,当第3个重复的ACK到达时,ssthresh被置为cwnd的一半(1213四舍五入到报文段大小的下一个倍数,即1024),而cwnd被置为ssthresh加上所收到的重复的ACK数乘以报文段大小(也即1024加上3倍的256),然后发送重传数据。 1792 = 1024 + 3 × 256 1792 = 1024 + 3 \times 256 1792=1024+3×256 又有5个重复的ACK到达(报文段64~66, 68和70),每次cwnd增加1个报文段长度。最后一个新的ACK(报文段72段)到达时,cwnd被置为ssthresh(1024)并进入正常的拥塞避免过程。由于cwnd等于ssthresh(慢启动),因此报文段的大小增加一个报文段(1024 + 256 = 1280),取值为1280。当下一个新的ACK到达时,cwnd大于ssthresh(拥塞避免),取值为1363。 1280 + 256 × 256 1280 + 256 8 = 1363 1280 + \frac{256 \times 256}{1280} + \frac{256}{8} = 1363 1280+1280256×256+8256=1363
当最初的2个重复的ACK(报文段60和61)到达时它们被计数,而cwnd保持不变。然而,当第3个重复的ACK到达时,ssthresh被置为cwnd的一半(1213四舍五入到报文段大小的下一个倍数,即1024),而cwnd被置为ssthresh加上所收到的重复的ACK数乘以报文段大小(也即1024加上3倍的256),然后发送重传数据。 1792 = 1024 + 3 × 256 1792 = 1024 + 3 \times 256 1792=1024+3×256 又有5个重复的ACK到达(报文段64~66, 68和70),每次cwnd增加1个报文段长度。最后一个新的ACK(报文段72段)到达时,cwnd被置为ssthresh(1024)并进入正常的拥塞避免过程。由于cwnd等于ssthresh(慢启动),因此报文段的大小增加一个报文段(1024 + 256 = 1280),取值为1280。当下一个新的ACK到达时,cwnd大于ssthresh(拥塞避免),取值为1363。 1280 + 256 × 256 1280 + 256 8 = 1363 1280 + \frac{256 \times 256}{1280} + \frac{256}{8} = 1363 1280+1280256×256+8256=1363
21.9 按每条路由进行度量
较新的TCP实现在路由表项中维持许多我们在本章已经介绍过的指标。当一个TCP连接关闭时,如果已经发送了足够多的数据来获得有意义统计资料,且目的结点的路由表项不是一个默认的表项,那么下列信息就保存在路由表项中以备下次使用:被平滑的RTT、被平滑的均值偏差以及慢启动门限。所谓“足够多的数据”是指16个窗口的数据,这样就可得到16个RTT采样,从而使被平滑的RTT过滤器能够集中在正确结果的5%以内。
21.10 ICMP的差错
TCP能够遇到的最常见的ICMP差错就是源站抑制、主机不可达和网络不可达。当前基于伯克利的实现对这些错误的处理是:
- 一个接收到的源站抑制引起拥塞窗口cwnd被置为1个报文段大小来发起慢启动,但是慢启动门限ssthresh没有变化,所以窗口将打开直至它或者开放了所有的通路(受窗口大小和往返时间的限制)或者发生了拥塞。
- 一个接收到的主机不可达或网络不可达实际上都被忽略,因为这两个差错都被认为是短暂现象。这有可能是由于中间路由器被关闭而导致选路协议要花费数分钟才能稳定到另一个替换路由。在这个过程中就可能发生这两个ICMP差错中的一个,但是连接并不必被关闭。相反, TCP试图发送引起该差错的数据,尽管最终有可能会超时。当前基于伯克利的实现记录发生的ICMP差错,如果连接超时,ICMP差错被转换为一个更合适的的差错码而不是“连接超时”。
21.11 重新分组
当TCP超时并重传时,它不一定要重传同样的报文段。TCP允许进行重新分组而发送一个较大的报文段,这将有助于提高性能(当然,这个较大的报文段不能够超过接收方声明的MSS)。在协议中这是允许的,因为TCP是使用字节序号而不是报文段序号来进行识别它所要发送的数据和进行确认。