Alpha-Refine:Boosting Tracking Performance by Precise Bouding Box Estimation
好久没有写博客了,今天分享一篇新的目标跟踪论文。最后更新日期:2020.08.03
论文链接:https://arxiv.org/abs/2007.02024
代码链接:https://github.com/MasterBin-IIAU/AlphaRefine 2020.08.03作者目前还没发布
摘要:目前的目标跟踪算法大多采用多阶段(multiple-stage)的策略,即先对目标进行粗定位,再利用refinement modules对目标进行精细定位。作者认为现有的refinement modules的可移植性和准确性较差,因此作者提出了一种更为准确灵活的refinement module——Alpha-Refine,也就是本文的主角啦。Alpha-Refine利用pixel-wise correlation和spatial-aware non-local层来融合特征,并且可以预测出三种输出:bounding box、corners和mask。那么利用哪个输出结果作为最终的跟踪结果呢?作者在此提出了一个轻量的branch selector module进行选择。作者在现在大热的DiMP、ATOM、SiamRPN++、RTMDNet和ECO算法上进行了大量的实验,表明了所提模块的有效性。
引言:准确的目标尺度估计对于目标跟踪是十分重要的,早期的跟踪器通过多尺度搜索(multi-scale search,如SiameseFC、UPDT、ECO)或先抽样后回归的方法进行尺度估计,这些方法准确度不够高。近些年,有很多表现很好的新尺度估计方法,如DiMP和ATOM中的IoUNet、SiamMask等。
作者所提出的回归模块是单独训练好的,因此可以即插即用!!即插即用!!即插即用!!
不想了解相关工作的可以跳过这段,直接看方法!
相关工作:
- 现在的尺度估计:现有的高性能尺度估计方法包括RPN-based、Mask-based、IoU-based和Anchor-free-based四类。RPN-based方法学习region proposal网络,该网络判断当前anchor是否为目标,并对anchor回归。相比之下,Mask-based类方法更为准确。IoU-based类方法学习一个能够预测候选bbox和groundtruth之间重叠度的网络。Anchor-free-based类方法。。。
- 回归模块:DiMP和ATOM中的IoU-Net是可以单独训练的,可移植性较好,但精度有待提升。SiamMask方法也可以和任何跟踪器结合。
Alpha-Refine:单目标跟踪任务可以被分解为目标定位和尺度估计两部分。在本文的工作中,基准跟踪器用于定位目标,Alpha-Refine用于准确的尺度估计。当基准跟踪器获得粗略的跟踪结果后,裁剪跟踪结果的两倍大小作为搜索区域,并输入Alpha-Refine,然后Alpha-Refine输出更为准确的bbox作为最终跟踪的结果。下一帧将基于上一帧的结果剪裁搜索区域。
网络结构:Alpha-Refine有两个输入分支:reference分支和test分支。这两个分支分别以第一帧和当前帧中的搜索区域为输入,主干网络为参数共享(啥意思?)的ResNet-50。特征提取后,利用PrRoI Pooling层获得reference分支的目标特征。现有的方法大多采用correlation或depth-wise correlation来融合特征,Alpha-Refine则利用pixel-wise correlation和spatial-aware non-local层来整合特征,从而获得由reference引导的目标特征。此外,跟踪结果有三种输出类型:bounding box、corners和mask,利用branch selector进行选择。网络结构如Figure1所示。

特征聚合:
1、准确的Pixel-wise Correlation:设![]() 和
和![]() 分别为模板(template)和搜索区域的特征。Pixel-wise correlation分为以下几步 (1)将
分别为模板(template)和搜索区域的特征。Pixel-wise correlation分为以下几步 (1)将 分解成
分解成![]() 个子核
个子核![]() (2)利用每个子核与
(2)利用每个子核与 分别计算相关性(correlation),从而得到相关图
分别计算相关性(correlation),从而得到相关图![]() 。这个过程可以用下面这个公式来描述:
。这个过程可以用下面这个公式来描述:![]() ,其中
,其中 表示naive correlation。与navie correlation和depth-wise correlation不同的是,pixel-wise correlation以目标中的每一个部分作为核,从而使得相关图中可以编码目标局部区域的信息。得益于更小的核尺寸和更多样化的目标表达,相关图包含了更多的目标边缘和尺度信息,这有利于后续的预测。Figure2(a)展示了三种correlation的计算过程。由于矩形标注的不准确性,一些子核就包含了判别力弱的背景像素,因此作者在pixel-wise correlation层后添加了channel-wise attention,增强用于尺度估计的最具有判别力区域的特征。
表示naive correlation。与navie correlation和depth-wise correlation不同的是,pixel-wise correlation以目标中的每一个部分作为核,从而使得相关图中可以编码目标局部区域的信息。得益于更小的核尺寸和更多样化的目标表达,相关图包含了更多的目标边缘和尺度信息,这有利于后续的预测。Figure2(a)展示了三种correlation的计算过程。由于矩形标注的不准确性,一些子核就包含了判别力弱的背景像素,因此作者在pixel-wise correlation层后添加了channel-wise attention,增强用于尺度估计的最具有判别力区域的特征。
2、Spatial-aware Non-local Fusion:为了准确定位目标边界,使用全局上下文信息是十分重要的。Non-local模块可以很好的实现该目标,因为它可以捕获长序列(?)依赖关系。公式: ,其中
,其中 表示输入特征图,
表示输入特征图, 表示输出特征图,
表示输出特征图,![]() 特征图上不同位置间的关系,并返回向量。
特征图上不同位置间的关系,并返回向量。 是归一化因子,等于
是归一化因子,等于![]() 。
。![]() (高斯形式),
(高斯形式),![]() ,
,![]() 。因此可以用softmax表示non-local模块
。因此可以用softmax表示non-local模块![]() ,如Figure2(b)所示。(我有个问题,g(xj)是啥?没看到论文里提出,Figure2(b)yi出来后的那块是在干什么?)
,如Figure2(b)所示。(我有个问题,g(xj)是啥?没看到论文里提出,Figure2(b)yi出来后的那块是在干什么?)

互补预测分支:输出分支有三个,分别输出一个bbox、两个corners(左上角和右下角)和一个mask,corners和mask可以转换为bbox。所有的分支都以non-local特征为输入 。
1、BBox分支:目标位于搜索区域中心的附近,因此本方法只需要使用一个anchor box,归一化坐标![]() 为
为![]() 。该分支包含两个Conv-BN-ReLU层,后面是global average pooling层和全连接层。在训练阶段,GIoU损失被用于最大化预测的box和groundtruth之间的重叠度。
。该分支包含两个Conv-BN-ReLU层,后面是global average pooling层和全连接层。在训练阶段,GIoU损失被用于最大化预测的box和groundtruth之间的重叠度。
![]() ,
,![]()
其中,![]() 和
和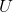 分别表示预测bbox和groundtruth的最小封闭区域和并集。
分别表示预测bbox和groundtruth的最小封闭区域和并集。
2、Corner分支:SATIN算法将角点检测引入跟踪领域,但该算法只为角点预测了低分辨率的热力图,并学习偏移来refine坐标。本文的方法利用重复的Conv-BN-ReLU-Bilinear(双线性插值)模块预测和搜索区域相同大小的高分辨率热力图,从而增强特征的分辨率。对两个角点的热力图采用soft-argmax操作,从而获得角点坐标。在训练过程中,利用mean squared error损失来优化参数。与SATIN相比,我们的方法有两个优势:(1)热力图分辨率高,没有量化误差;(2)我们的回归方法不会遇到使用高斯标签所带来的不平衡问题。
3、Mask分支:通过FPN整合主干网络的低层特征,从而恢复细节信息来产生高质量的mask。SiamMask将mask限制为和template相同大小,本文的方法预测的mask和搜索区域大小相同,因此质量更高。该分支利用binary cross-entropy损失来训练。在训练阶段,首先将mask二值化,然后转换为bbox。


分支选择模块:如Figure3所示,三个预测分支输出不同的bbox结果。该分支输入为non-local特征,并对三个分支的输出质量进行评估。我们利用Conv-BN-ReLU层和Max-Pooling层来降低通道数量和空间分辨率,利用两个全连接层预测三个分支的分数,具体结构如Table1所示。这个模块的作用就是在任何一个分支运行之前预测会产生最准确结果的分支,因此只需要运行一个分支。
训练:
1、训练集构建:LaSOT、GOT-10K、VID、DET、COCO、Youtube-VOS等
给定一个视频序列,首先选择两个间隔小于50帧的随机帧![]() 和
和![]() ;然后通过随机translation和scaling处理上述帧的groundtruth,从而产生reference和test boxes。
;然后通过随机translation和scaling处理上述帧的groundtruth,从而产生reference和test boxes。
![]()
![]()
![]()
 和
和 是分别与尺度和中心相关的标量因子。
是分别与尺度和中心相关的标量因子。 和分别代表2维标准正态分布和2维均匀分布。对于reference帧,
和分别代表2维标准正态分布和2维均匀分布。对于reference帧,![]() ;对于test帧,
;对于test帧,![]() 。获得boxes后,我们剪裁bbox的
。获得boxes后,我们剪裁bbox的 倍为搜索区域,并将其resize为
倍为搜索区域,并将其resize为 ,输入Alpha-Refine。
,输入Alpha-Refine。
2、训练方法:整个训练分为两个阶段。在第一阶段,由于三个分支的预测质量是动态变化的,因此我们在不引入分支选择模块的情况下训练Alpha-Refine。这种情况不能为分支选择模块提供可靠的标签。bbox、corner和mask分支的损失分别为![]() ,
,![]() 和
和![]() 。最终loss如下:
。最终loss如下:
![]()
其中,![]() ,
,![]() ,
,![]() 。训练Alpha-Refine 40个epochs,每个epoch包含batch size大小为32的4000次迭代。由于训练数据充足,没有freeze主干的任何参数。
。训练Alpha-Refine 40个epochs,每个epoch包含batch size大小为32的4000次迭代。由于训练数据充足,没有freeze主干的任何参数。
在第二阶段,我们只训练分支选择模块,并将其他所有参数freeze。计算预测结果![]() 、
、 、
、 和groundtruth
和groundtruth![]() 之间的IoU,argmax函数被用于获得分支选择模块的标签。
之间的IoU,argmax函数被用于获得分支选择模块的标签。
![]()
我们利用cross-entropy损失训练分支选择模40个epochs,每个epoch包含batchsize大小为128的200次迭代。
在两个训练阶段,利用Adam优化器,学习率每8个epochs减半。
实验:
与SOTA对比:
TrackingNet上的结果

LaSOT上的结果

VOT2018上的结果 ,注意VOT2018的bbox是旋转bbox。

与IoU-Net和SiamMask的比较: Alpha-Refine以ResNet50为主干网络,这与IoU-Net和SiamMask一致。

Ablation实验:
Pixel-wise corraltion vs Naive and Depth-wise correlation:

Non-local模块:如Table5所示。
选择分支模块:如Table5所示。
进一步的分析:
速度:加上Alpha-Refine后,算法仍然可以real time。

多分支:Figure3和5
