常用十大算法_KMP算法
KMP算法
FBI提示:KMP算法不好理解, 建议视频+本文+其他博客,别走马观花
KMP算法是用于文本匹配的算法,属于模式搜索(pattern Searching)问题的一种算法,在讲KMP算法之前,传统的匹配字符算法是暴力匹配(BF算法)。一个字一个字的匹配,直到出现完全匹配的情况。
代码实现:
package cn.dataStructureAndAlgorithm.demo.tenAlgorithm.KMP;
public class 暴力匹配算法_字符串匹配 {
public static void main(String[] args) {
String str1="auissuie Hello worll? hello worrowhhhello worldss ";
String str2="hello world";
System.out.println(violentMatch(str1,str2));
}
/**
* 暴力匹配字符
* @param str1 匹配字符区
* @param str2 待匹配字符
* @return 匹配成功返回字符串第一个字符下标,否则返回-1
*/
public static int violentMatch(String str1,String str2){
char[] str1Char=str1.toCharArray();
char[] str2Char=str2.toCharArray();
int str1Len=str1Char.length;
int str2Len=str2Char.length;
int i=0,j=0;//i指向str1,j指向str2
while (i36暴力匹配算法,在大量数据面前,将出现很多次主串索引的回溯(每遇到一个匹配失败就从头开始),极大的浪费时间。
KMP算法通过省略主串(待匹配的杂乱字符串)索引的回溯,尽可能减少反复次数,使字符匹配效率有了某种程度的提升
如何省略主串索引的回溯?这需要引入next数组(又称Profix数组)来记录从模式串(指定匹配的字符串)中提取的加速匹配信息
是不是有点懵,且看图说话。

上面演示的情景是使用了KMP算法后,失配(主串发现了与模式串不匹配)状况下,模式串的回溯情景
当发现失配时,已经匹配过的模式串片段“ABAB”存在有最长公共前后缀“AB”(最长公共前后缀的解释见下图),其最长公共前后缀长度为2。

那么如果将模式串的索引从匹配位置移动到下标为2的位置上,且主串索引不动(形象的看就是如图中,将公共前缀部分移动到公共后缀部分)时,就不需要像BF算法(暴力匹配)中回溯主串索引再对已经匹配过的模式串进行匹配判断(这句话可以画图理解一下),从而达到了我们省略主串索引回溯的目的。
随着匹配的进行,模式串会被切成很多段

每一段都有自己的最长公共前后缀,到这里你明白了吗?使用KMP的核心是什么?就是找每一段的最长公共前后缀,求出每段对应的最长公共前后缀长度
KMP算法将每段对应的最长公共前后缀,存放在next数组(又称Profix数组)中。换句话说求出next数组KMP就完成了一大半
第一阶段:求next数组
1,演示手动求next数组
有一个提示,模式串的第一段片段“A”,单字符是没有公共前后缀的,所以对应next值为0。即next[0]=0,这个我们不用求了,直接赋值

下图演示手动求各片段的最长公共前后缀

将求得的各片段最长公共前后缀,放入到对应next数组中,next数组求完了

2,演示程序求next数组
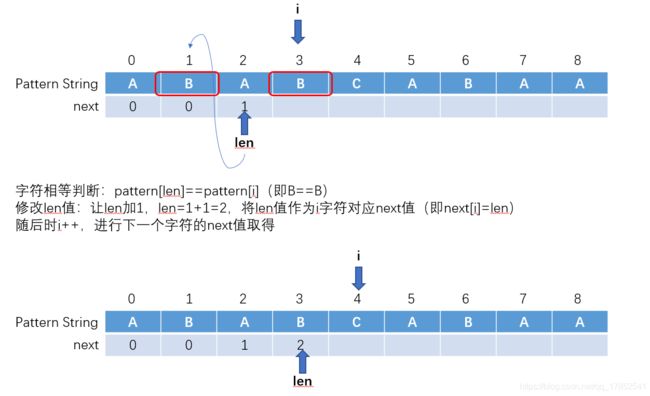
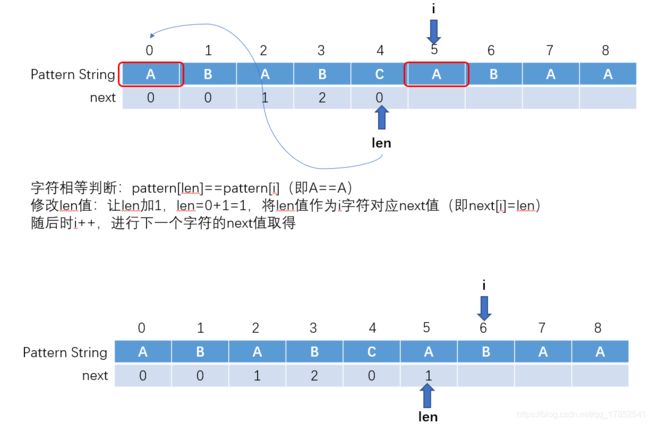
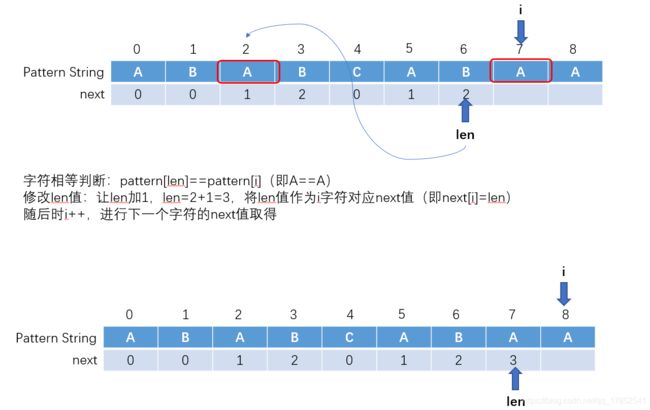
先看图中流程,后面详细说。其中i为模式串的索引,len保存索引前模式串片段的最长公共前后缀长度





制图不易,抬起你的小手手,关注我一下吧,给我点赞也好啊:>
可以看见,在整个过程中,明显的存在两步(字符相等判断,len值修改)一循环(字符不等且len不为0时重复操作)。其逻辑如下图

算法流程就是这样了,接下来说一下为什么怎么做?
3,算法分析
在求next数组过程中,首先第一个字符的next值一定为0
有一种情况,当 前一个字符的next值为n时,如果索引为n的模式串字符与当前字符串一致时,那么该字符会组成新的最长公共前后缀,自然的,可以将len++的值做为当前字符的next值。这叫继承。随后i++,进行下一字符判断

还有一种情况,在上种情况中,两个字符不等时,我们采用向前再移一位取其next值作为新len值的方式获取新的len值(这就是len=next[len-1]的由来)取得新的len值后,将进入循环重复字符判断,修改len值的操作。但要注意一点的是,当字符不等且len值为0时,不能再len-1了,否则将下标越界。这时,直接将0作为字符next的值就可以了,不需要再循环了。(如下图)随后i++,进行下一字符判断

上面这个情况下的操作,其实是在寻找前面模式串片段中可能存在的局部小最长公共前后缀(如下图)

4,代码实现:
/**
* 提取模式串对应的next数组
* @param str 模式字符串
* @return next数组
*/
public static int[] getNext(String str){
char[] pattern=str.toCharArray();
int[] next=new int[pattern.length];
next[0]=0;
int len=0;
int i=1;
while (i 0) {
len = next[len - 1];
} else {
next[i] = len;
i++;
}
}
}
return next;
} 若输入模式字符串为“ABABCABAA” ,输出的next数组为
[0, 0, 1, 2, 0, 1, 2, 3, 1]next数组的值反映了对应模式串片段的对称程度,如果模式串本身对称程度低,所得到的next数组就越趋近于0,KMP的匹配优化效果越差
如输入模式字符串为“hello world”,输出的next数组为
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]至此next数组告一段落,接下来做KMP算法就小case了
第二阶段:完成KMP算法主体
KMP流程示意图如下
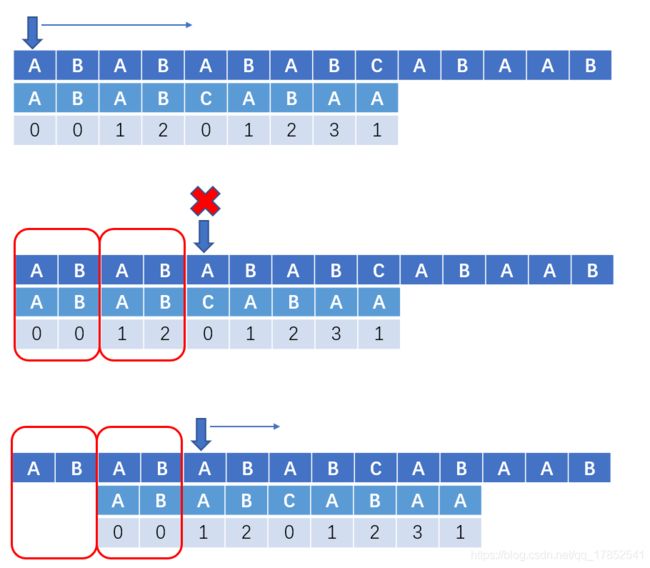

不用多说了吧,代码呈上
KMP匹配算法完整代码实现
package cn.dataStructureAndAlgorithm.demo.tenAlgorithm.KMP;
public class KMP匹配算法_字符串匹配 {
public static void main(String[] args) {
String str1="ABABABABCABAAB";
String str2="ABABCABAA";
System.out.println(KMP(str1,str2));
}
public static int KMP(String str1,String str2){
int[] next=getNext(str2);
char[] str=str1.toCharArray();
char[] pattern=str2.toCharArray();
int i=0;
int n=0;
while (i 0) {
len = next[len - 1];
} else {
next[i] = len;
i++;
}
}
}
return next;
}
}
费半天力气KMP完成了,现在回顾最开始的“KMP算法通过省略主串(待匹配的杂乱字符串)索引的回溯,尽可能减少反复次数,使字符匹配效率有了某种程度的提升”这句话,是不是有点感觉了。
有的朋友,为了方便将以上求得的next数组整体右移,在第一个位置添加-1。如“[0, 0, 1, 2, 0, 1, 2, 3, 1]”变为“[-1,0, 0, 1, 2, 0, 1, 2, 3 ]”这样是为了方便代码编写,len=next[len-1]变为len=next[len],这个看你想不想要了。
KMP中的next数组还可以升级为nextValue数组,该数组对next数组进行了优化。这个优化问题,以后我遇到了,我再填坑。
推荐几个有关KMP算法的博文
KMP算法的前缀next数组最通俗的解释,如果看不懂我也没辙了
KMP算法—终于全部弄懂了
其他常用算法,见下各链接
【常用十大算法_二分查找算法】
【常用十大算法_分治算法】
【常用十大算法_贪心算法】
【常用十大算法_动态规划算法(DP)】
【常用十大算法_普里姆(prim)算法,克鲁斯卡尔(Kruskal)算法】
【常用十大算法_迪杰斯特拉(Dijkstra)算法,弗洛伊德(Floyd)算法】
【常用十大算法_回溯算法】
【数据结构与算法整理总结目录 :>】<-- 宝藏在此(doge)