tensorflow实现CIFAR-10图片的分类
本篇文章主要是利用tensorflow来构建卷积神经网络,利用CIFAR-10数据集来实现图片的分类。数据集主要包括10类不同的图片,一共有60000张图片,50000张图片作为训练集,10000张图片作为测试集,每张图片的大小为32×32×3(彩色图片)。

在构建CIFAR-10卷积神经网络中,采用了几个trick,对权重进行正则化、数据增强、和LRN层来提高模型的性能和泛化能力。
一、下载数据
通过tensorflow官方提供的cifar10来下载CIFAR-10数据
#下载解压数据
cifar10.maybe_download_and_extract()二、权重的正则化
对于权重的初始化,还是采用截断的正态分布来随机初始化卷积和的权重。在权重初始化的时候,会给权重增加一个L2的损失,相当于做了一个L2的正则化处理。在建立模型的时候,无论是回归还是分类,都有可能因为特征过多而导致模型过拟合,通常可以通过减少特征或者惩罚不重要的特征的权重来降低模型的过拟合。然而,我们并不知道那些权重是不重要的,通过正则化可以将权重也作为损失函数的一部分,当我们在使用某个特征的同时也要增加损失函数,如果在增加这个特征的权重还不足以抵消它带来的损失,算法就会自动降低这部分特征的权重来减少损失,这样我们就能给筛选出重要的特征。L2正则化会让权重的值不会太大,趋于0。L1正则化会产生稀疏特征,即大部分的无用特征都会被至为0。
下面通过tensorflow来实现对权重的L2正则化,通过设置参数w2来决定特征带来损失的大小
'''
初始化权重函数
'''
def variable_with_weight_loss(shape,std,w1):
var = tf.Variable(tf.truncated_normal(shape,stddev=std),dtype=tf.float32)
if w1 is not None:
weight_loss = tf.multiply(tf.nn.l2_loss(var),w1,name="weight_loss")
tf.add_to_collection("losses",weight_loss)
return var三、数据增强
利用工具类cifar10_input来进行数据增强,对32×32的图片进行随机裁剪、翻转、对比度、亮度的设置,裁剪后的图片由32×32变成了28 ×28,所以后面在设置卷积神经网络的时候,输入图片的大小为28×28×3。在进行数据增强的时候需要消耗大量的CPU,在distorted_inputs内部使用了16个独立的线程来加速任务,函数内部会产生线程池,在需要使用的时候会通过TensorFlow queue来调度。
在进行测试的时候,通过裁剪图片的中间部分,将32×32的图片转变成为28×28之后才能预测图片的类别。
#获取数据增强后的训练集数据
images_train,labels_train = cifar10_input.distorted_inputs(cifar10_dir,batch_size)
#获取数据裁剪后的测试数据
images_test,labels_test = cifar10_input.inputs(eval_data=True,data_dir=cifar10_dir
,batch_size=batch_size)四、卷积神经网络
整个卷积神经网络主要由两层卷积层和三层全连接层所组成,最后模型在测试集上的top1准确率可以达到80%。
1、第一层卷积层
第一层卷积是由64个5×5的卷积核组成,步长为1,padding为SAME使得卷积之后的图片输入和输出的大小保持一致。将卷积之后的结果加上偏置,然后在通过RELU激活函数,再经过最大池化,需要注意的是采用的是池化的核为3×3,步长为2×2,池化的尺寸和步长不一致目的是为了增加数据的丰富性。最后再经过Lrn层,LRN层模仿了生物神经系统的“侧抑制”机制,对于局部神经元的活动创建竞争环境,使得其中响应较大的值变得更大,并抑制反馈较小的神经元,提高了模型的泛化能力。Relu激活函数是没有边界的,所以lrn层对于没有边界的激活函数会比较有用,它会从多个卷积核的响应中挑选比较大的反馈。对于有固定边界且能抑制过大值的激活函数sigmoid不太适应。
#设计第一层卷积
weight1 = variable_with_weight_loss(shape=[5,5,3,64],std=5e-2,w1=0)
kernel1 = tf.nn.conv2d(image_holder,weight1,[1,1,1,1],padding="SAME")
bais1 = tf.Variable(tf.constant(0.0,dtype=tf.float32,shape=[64]))
conv1 = tf.nn.relu(tf.nn.bias_add(kernel1,bais1))
pool1 = tf.nn.max_pool(conv1,[1,3,3,1],[1,2,2,1],padding="SAME"),
norm1 = tf.nn.lrn(pool1,4,bias=1.0,alpha=0.001 / 9,beta=0.75)2、第二层卷积层
第二层卷积与第一层卷积的总体结构相差不大,相对于第一层卷积,第二层将lrn层和最大池化层的顺序进行了调换,先通过lrn层之后,再使用最大池化。
#设计第二层卷积
weight2 = variable_with_weight_loss(shape=[5,5,64,64],std=5e-2,w1=0)
kernel2 = tf.nn.conv2d(norm1,weight2,[1,1,1,1],padding="SAME")
bais2 = tf.Variable(tf.constant(0.1,dtype=tf.float32,shape=[64]))
conv2 = tf.nn.relu(tf.nn.bias_add(kernel2,bais2))
norm2 = tf.nn.lrn(conv2,4,bias=1.0,alpha=0.01 / 9,beta=0.75)
pool2 = tf.nn.max_pool(norm2,[1,3,3,1],[1,2,2,1],padding="SAME")3、第三层全连接层
在进行全连接操作之前,需要先将卷积后的图片进行flatten,将图片变成一个行向量,一行代表一张图片,所有有bath_size行。在这一层全连接中对权重使用L2正则化,正则化的系数为0.004。通过relu激活函数之后输出一个384维的向量。
#第一层全连接层
reshape = tf.reshape(pool2,[batch_size,-1])
dim = reshape.get_shape()[1].value
weight3 = variable_with_weight_loss([dim,384],std=0.04,w1=0.004)
bais3 = tf.Variable(tf.constant(0.1,shape=[384],dtype=tf.float32))
local3 = tf.nn.relu(tf.matmul(reshape,weight3)+bais3)
4、第四层全连接层
这一层全连接层和上一层差不多,将输入的384维向量变成了192维向量的输出,也使用了L2正则化。
#第二层全连接层
weight4 = variable_with_weight_loss([384,192],std=0.04,w1=0.004)
bais4 = tf.Variable(tf.constant(0.1,shape=[192],dtype=tf.float32))
local4 = tf.nn.relu(tf.matmul(local3,weight4)+bais4)5、第五层全连接层
这一层将192维的向量转变为10维向量的输出,代表着十个不同种类的图片,输出的并没有经过softmax。
#最后一层
weight5 = variable_with_weight_loss([192,10],std=1/192.0,w1=0)
bais5 = tf.Variable(tf.constant(0.0,shape=[10],dtype=tf.float32))
logits = tf.add(tf.matmul(local4,weight5),bais5)6、损失函数的计算
使用交叉熵作为损失函数,在这里我们通过sparse_softmax_cross_entropy_with_logits来实现softmax和交叉熵的计算。最后还需要加上之前的权重的损失作为最后总的损失函数进行优化。
'''
损失函数
'''
def loss_func(logits,labels):
labels = tf.cast(labels,tf.int32)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits,
labels=labels,name="cross_entropy_per_example")
cross_entropy_mean = tf.reduce_mean(tf.reduce_sum(cross_entropy))
tf.add_to_collection("losses",cross_entropy_mean)
return tf.add_n(tf.get_collection("losses"),name="total_loss")7、训练和预测
在训练的过程中,会输出每秒能够处理多少图片,每迭代1000次输出一次损失值。需要注意的是,在进行预测的时候需要将测试集分成一块一块batch_size大小的图片进行预测,统计top1准确率,最后计算出top1的平均值,top1是指分类准确率最高的那类图片。
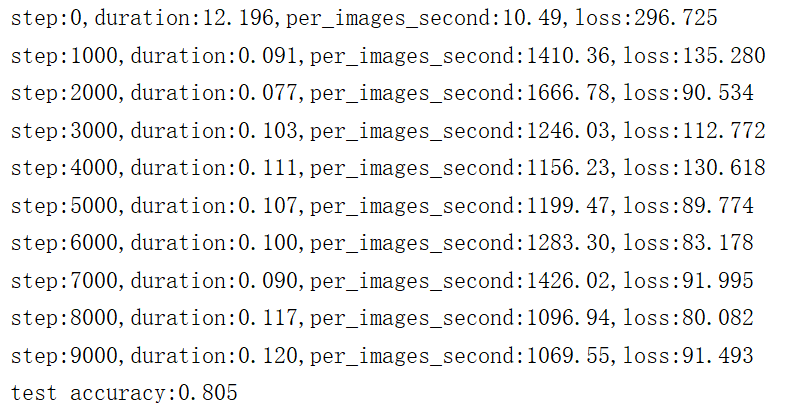
迭代10000次后的准确率可以达到80%,如果还想提高准确率,可以增加迭代的次数,然后在降低学习率。
完整代码链接