【Go语言学习】(九)go语言实现简易的HashMap
哈希表(hash table)
也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,本文借鉴java中HashMap的实现,分析hash表的基本原理,并用Go语言进行实现。
一、什么是哈希表
在讨论哈希表之前,我们先大概了解下其他数据结构在新增,查找等基础操作执行性能
数组:采用一段连续的存储单元来存储数据。对于指定下标的查找,时间复杂度为O(1);通过给定值进行查找,需要遍历数组,逐一比对给定关键字和数组元素,时间复杂度为O(n),当然,对于有序数组,则可采用二分查找,插值查找,斐波那契查找等方式,可将查找复杂度提高为O(logn);对于一般的插入删除操作,涉及到数组元素的移动,其平均复杂度也为O(n)
线性链表:对于链表的新增,删除等操作(在找到指定操作位置后),仅需处理结点间的引用即可,时间复杂度为O(1),而查找操作需要遍历链表逐一进行比对,复杂度为O(n)
二叉树:对一棵相对平衡的有序二叉树,对其进行插入,查找,删除等操作,平均复杂度均为O(logn)。
哈希表:相比上述几种数据结构,在哈希表中进行添加,删除,查找等操作,性能十分之高,不考虑哈希冲突的情况下(后面会探讨下哈希冲突的情况),仅需一次定位即可完成,时间复杂度为O(1),接下来我们就来看看哈希表是如何实现达到惊艳的常数阶O(1)的。
我们知道,数据结构的物理存储结构只有两种:顺序存储结构和链式存储结构(像栈,队列,树,图等是从逻辑结构去抽象的,映射到内存中,也这两种物理组织形式),而在上面我们提到过,在数组中根据下标查找某个元素,一次定位就可以达到,哈希表利用了这种特性,哈希表的主干就是数组。
比如我们要新增或查找某个元素,我们通过把当前元素的关键字 通过某个函数映射到数组中的某个位置,通过数组下标一次定位就可完成操作。
这个函数可以简单描述为:存储位置 = f(关键字) ,这个函数f一般称为哈希函数,这个函数的设计好坏会直接影响到哈希表的优劣。举个例子,比如我们要在哈希表中执行插入操作:
插入过程如下图所示
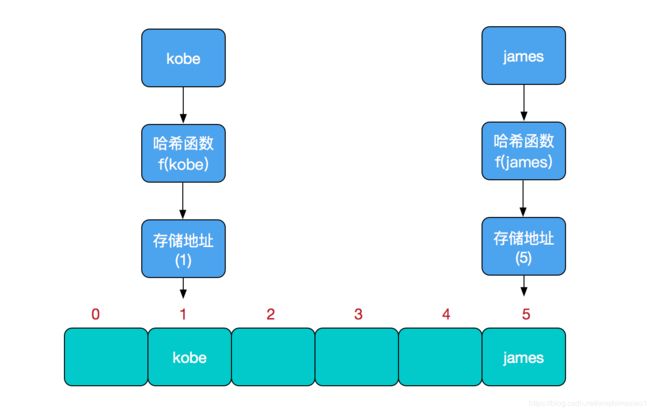
查找操作同理,先通过哈希函数计算出实际存储地址,然后从数组中对应地址取出即可。
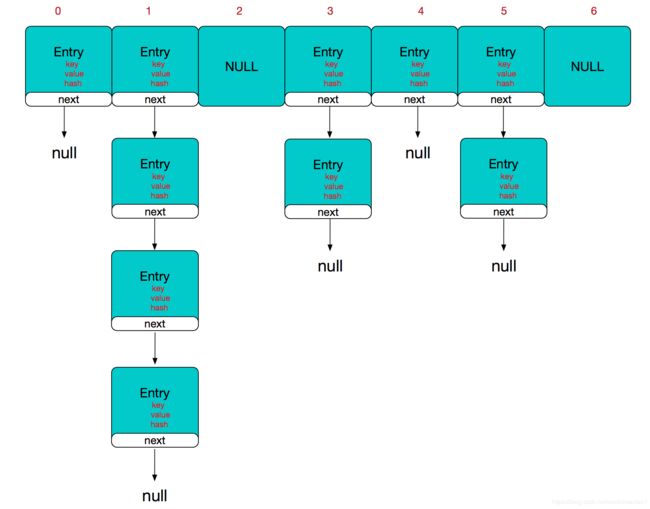
哈希冲突
然而万事无完美,如果两个不同的元素,通过哈希函数得出的实际存储地址相同怎么办?也就是说,当我们对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的哈希冲突,也叫哈希碰撞。前面我们提到过,哈希函数的设计至关重要,好的哈希函数会尽可能地保证 计算简单和散列地址分布均匀,但是,我们需要清楚的是,数组是一块连续的固定长度的内存空间,再好的哈希函数也不能保证得到的存储地址绝对不发生冲突。那么哈希冲突如何解决呢?哈希冲突的解决方案有多种:开放定址法(发生冲突,继续寻找下一块未被占用的存储地址),再散列函数法,链地址法,而HashMap即是采用了链地址法,也就是数组+链表的方式。
Go语言实现代码:
linkedNodes部分:
package gohash
import "fmt"
//Map 定义一个map结构
type Map struct {
k string
v string
}
//Node 链表节点
type Node struct {
data Map
next *Node
}
//CreatHeadNode 创建头节点
func creatHeadNode(k, v string) *Node {
//创建头节点
node := new(Node)
node.data.k = k
node.data.v = v
node.next = nil
/* //头指针和当前指针指向头节点
Head = node
Curr = node */
return node //返回node,作为hashmap数组中的头节点
}
//AddNode 新增节点
func addNode(k, v string, Curr *Node) {
node := new(Node)
node.data.k = k
node.data.v = v
node.next = nil
//挂接节点
Curr.next = node
//Curr = node
}
//PrintNode 遍历打印节点
func printNode(head *Node) {
p := head
for {
if p.next == nil {
fmt.Printf("%s:%s", p.data.k, p.data.v)
return
}
fmt.Printf("%s:%s->", p.data.k, p.data.v)
p = p.next
}
}
//CntNodes 计算节点个数
func cntNodes(head *Node) int {
cnt := 0
p := head
//若链表为空
if p == nil {
return cnt
}
//若不为空
for {
if p.next == nil {
cnt++
return cnt
}
cnt++
p = p.next
}
}
hashMap部分:
package gohash
import "fmt"
//HashArr 定义一个nodes的数组
var hashArr [16]*Node //[ ]
//PutData put value
func PutData(k, v string) {
var pos = hashCode(k)
//判断要插入的数组位置是否为空
if hashArr[pos] == nil {
//直接在hashArr[pos]中插入数据
hashArr[pos] = creatHeadNode(k, v)
return
}
//若不为空,遍历到该链表末尾指针位置
curr := getTail(hashArr[pos])
//插入末尾
addNode(k, v, curr)
return
}
//Get get value
func Get(k string) (string, bool) {
pos := hashCode(k)
p := hashArr[pos]
for {
if p == nil {
return "", false
}
if p.data.k == k {
return p.data.v, true
}
p = p.next
}
}
//GetAll 打印整个hashmap
func GetAll() {
for i := 0; i < 16; i++ {
if hashArr[i] == nil {
fmt.Printf("%d: \n", i)
} else {
fmt.Printf("%d: ", i)
printNode(hashArr[i])
fmt.Printf("\n")
}
}
}
//GetTail 找到末尾指针
func getTail(head *Node) *Node {
p := head
for {
if p.next == nil {
return p
}
p = p.next
}
}
//HashCode 将key转换成数组下标的散列算法,范围16之间
func hashCode(key string) int {
var index int = 0
index = int(key[0])
for k := 0; k < len(key); k++ {
index *= (1103515245 + int(key[k]))
}
index >>= 27
index &= 16 - 1
return index
}
测试:
package main
import (
"fmt"
"github.com/LeZeJ/Day6/gohash"
)
func main() {
gohash.PutData("1", "a")
gohash.PutData("2", "b")
gohash.PutData("3", "c")
gohash.PutData("4", "d")
gohash.PutData("5", "e")
gohash.PutData("6", "f")
gohash.PutData("7", "g")
gohash.PutData("8", "h")
gohash.PutData("9", "i")
gohash.PutData("10", "j")
gohash.PutData("11", "k")
gohash.PutData("12", "l")
gohash.PutData("13", "m")
gohash.PutData("14", "n")
gohash.PutData("15", "o")
gohash.PutData("16", "p")
gohash.PutData("17", "q")
gohash.PutData("18", "r")
v, _ := gohash.Get("3")
v1, _ := gohash.Get("8")
fmt.Println(v)
fmt.Println(v1)
gohash.GetAll()
}
运行结果:
c
h
0:
1: 11:k
2: 1:a->17:q
3: 3:c->5:e
4: 7:g->9:i->12:l
5: 18:r
6:
7: 13:m
8:
9: 14:n
10:
11: 2:b->4:d->6:f
12: 8:h->15:o
13:
14: 10:j
15: 16:p