基于随机森林的医疗费用分析与建模预估
一、随机森林简介:
1、bagging装袋法策略:
1、有放回的重采样;
2、相互独立地并行学习这些弱学习器(KNN,逻辑回归,决策树,SVM等等);
3、对于分类问题,根据分类器进行投票(软投票和硬投票)来确定最终的分类结果;对于预测性问题将回归结果进行平均,最终用于样本的预测值。
硬投票:少数服从多数的原则;
硬投票:各自分类器的概率值进行加权平均。
2、随机森林
bagging+CART树
随机森林在bagging基础上做了修改
从样本集中用Bootstrap采样选出n个样本;
从所有属性中随机选择k个属性,选择最佳分割 属性作为节点建立CART决策树;
重复以上两步m次,即建立了m棵决策树
针对m棵CART树的随机森林,对分类问题利用投票法,将最高得票的类别用于最终的判断结果;对于回归问题利用均值法,将其用作预测样本的最终结果。
二、 基于随机森林的医疗费用分析与建模预估
1、利用随机森林集成算法进行项目实战,使用的数据集是关于患者的医疗费用;首先加载数据,预览一下数据的前几行信息:
# 加载数据集,并进行分析
df=pd.read_csv(r"C:\Users\Administrator\Desktop\insurance.csv")
# 查看数据前五行
df.head()
age sex bmi children smoker region charges
0 19 female 27.900 0 yes southwest 16884.92400
1 18 male 33.770 1 no southeast 1725.55230
2 28 male 33.000 3 no southeast 4449.46200
3 33 male 22.705 0 no northwest 21984.47061
4 32 male 28.880 0 no northwest 3866.85520
2、数据清洗
2.1 删除缺失值,查看一下数据基本信息。
# 剔除缺失值
df=df.dropna()
# 查看数据基本信息
df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1338 entries, 0 to 1337
Data columns (total 7 columns):
age 1338 non-null int64
sex 1338 non-null object
bmi 1338 non-null float64
children 1338 non-null int64
smoker 1338 non-null object
region 1338 non-null object
charges 1338 non-null float64
dtypes: float64(2), int64(2), object(3)
memory usage: 83.6+ KB
2.2 拿到的数据很干净,去掉缺失值,数据没有什么异常值需要处理,查看一下数据的分布状况(age:年龄 sex:性别 bmi:身体质量指数 children:小孩个数 region:地区 charges:医疗费用)
# 查看数据分布状况
df.describe()

从年龄看出,平均在39岁。
2.3 变量Sex,region,smoker为类别变量,在建模之前需要对其进行重编码,如独热编码(one-hot)或者LabelEncoder ,下面对数据集中的变量使用LabelEncoder编码
# 对类别变量进行编码
le_sex=LabelEncoder()
le_smoker=LabelEncoder()
le_region=LabelEncoder()
df['sex']=le_sex.fit_transform(df['sex'])
df['smoker']=le_smoker.fit_transform(df['smoker'])
df['region']=le_smoker.fit_transform(df['region'])
2.4 对数据进行标准化处理
variables=['sex','smoker','region','age','bmi','children']
X=df[variables]
sc=StandardScaler()
X=sc.fit_transform(X)
Y=df['charges']
3、构建决策树模型
3.1 将数据拆分为训练集和测试集:
# 分割数据集
X_train,X_test,y_train,y_test=train_test_split(X,Y,test_size=0.2,random_state=1234)
3.2 利用网格交叉验证来获取最佳的超参数组合
# 预设各参数的不同选项值
max_depth=[10,11,12,13,14,15]
min_samples_split=[2,4,6,8]
min_samples_leaf=[2,4,8,10,12]
parameters={'max_depth':max_depth,'min_samples_split':min_samples_split,'min_samples_leaf':min_samples_leaf}
# 网格搜索法,测试不同的参数值
grid_dtcateg=GridSearchCV(estimator=DecisionTreeRegressor(),param_grid=parameters,cv=10)
# 模型拟合
grid_dtcateg.fit(X_train,y_train)
# 返回最佳组合的参数值
grid_dtcateg.best_params_
{'max_depth': 10, 'min_samples_leaf': 12, 'min_samples_split': 2}
如代码所示,经过10重交叉验证的网格搜索,得到各参数的最佳组合值为10,12,2.接下来利用这个参数值构建回归决策树。
3.3 构建用于回归的决策树
# 构建用于回归的决策树,默认使用均方误差选择节点的最佳分割字段
CART_Reg=DecisionTreeRegressor(max_depth=12,min_samples_leaf=12,min_samples_split=2,random_state=1234)
# CART_Reg=DecisionTreeRegressor()
# 回归树拟合
CART_Reg.fit(X_train,y_train)
# 回归树在测试集上的预测
pred=CART_Reg.predict(X_test)
# 计算衡量模型好坏的MAE值
print(sklearn.metrics.mean_absolute_error(y_test,pred))
2579.3568483513386
计算得到的MAE值为2579,该指标越小说明模型的预测效果越好。
4、构建随机森林模型
4.1接下来使用随机森林算法,重新对数据集进行建模
# 构建用于回归的随机森林,默认使用均方误差来选择节点的最佳分割字段
regressor=RandomForestRegressor(n_estimators=1000)
regressor.fit(X_train,y_train)
y_test_pred=regressor.predict(X_test)
# 计算衡量模型好坏的MAE值
print(sklearn.metrics.mean_absolute_error(y_test,y_test_pred))
2424.8362558463846
如上结果显示,随机森林算法在测试集上的MAE值为2425,比单棵决策树的MAE值要小,可以说明随机森林的拟合效果要比单棵回归树理想。
4.2基于随机森林计算的变量重要性绘制条形图
# 构建变量重要性的序列
regressor.feature_importances_
importance=pd.Series(regressor.feature_importances_,index=variables)
# print(importance)
importance.sort_values().plot('barh')
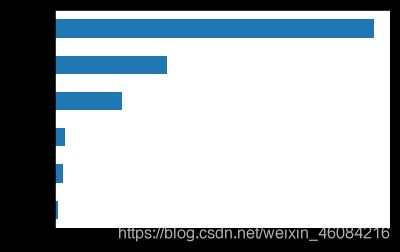
影响模型预测准确率的三个主要因素分别是是否吸烟、身体质量指数、年龄。
三、小结:
上面的案例分别使用决策树和随机森林集成算法来解决预测问题,对于单一决策树算法很容易过拟合,需要考虑剪枝技术,可惜的是sklearn模块没有提供后剪枝的运算函数或‘方法’。使用集成的随机森林算法,可以很好的避免单棵决策树过拟合的可能,将多棵树的回归结果进行平均,最终用于样本的预测值。上边的案例模型预测效果并不理想:主要原因在于源数据集与医疗费用之间没有很强的相关性,需要有更多的相关变量,来进行特征选择;更多的考虑是使用多元线性回归来解决预测问题。
数据源链接:https://pan.baidu.com/s/16lvMOHnrJM8FrwlKhLEHBg
提取码:30h3