大数据之分布式协调服务——Zookeeper
一、什么是Zookeeper

ZooKeeper是Hadoop的正式子项目,是Google的Chubby一个开源的实现,为分布式应用提供高效,可靠的分布式协调服务,提供诸如统一命名、状态同步、集群管理、配置同步、分布式锁等分布式基础服务。
二、相关概念
1、事务
事务是Zookeeper系统中能够改变服务器状态的操作,一般包括数据节点的创建和删除,数据节点内容更新和客户端会话创建于失效等操作。对于每一个事务请求,Zookeeper都会分配一个全局唯一的事务ID,用zxid表示,通常是一个64位的16进制数字。
高32位:整个集群leader的节点信息 不变证明集群没有易主
低32位:标识事件的提交编号,全局事件的提交顺序
2、一致性
在解决分布式数据一致性方面,Zookeeper并没有直接采用Paxos算法,而是采用了一种称为ZAB(ZooKeeper Atomic Broadcast)的一致性协议。
CAP理论:一个分布式系统不可能同时满足C,A,P三个需求
C:Consistency,一致性:多个副本保持一致性=>强一致性
A:Availability,可用性:系统提供的服务必须一直处于可用,对于用户的每一个操作请求总是能在有限时间内返回有效结果(即成功或失败)
P:Partition Tolerance,分区容错性:分布式系统在遇到任何网络分区故障时,仍然需要能够保证对外提供满足一致性和可用性的服务
一致性:强一致性(实时)、弱一致性(有延迟)、最终一致性(一定时间内)
BASE理论:
BA:Basically Available,基本可以用:相应时间的损失,功能上的损失
S:Soft state,软状态:允许存在不同节点同步数据时出现延迟,且出现数据同步延迟时存在的中间状态也不会影响系统整体性能
E:Eventually consistent,最终一致性:系统中所以的数据副本,在经过一段时间后,都可以达到同步
3、运行模式
ZooKeeper基于ZAB协议实现,包括两种基本的运行模式:崩溃恢复模式和消息广播模式。
崩溃恢复模式:当整个服务在启动过程,或当leader服务器网络中断,出现崩溃退出与重启等异常情况时,就会进入恢复模式并选举产生新的leader服务器。当选举产生了新的leader服务器,并有过半的follower服务器与该leader服务器完成了状态同步(数据同步),就会退出恢复模式。
消息广播模式:当集群中过半的follower服务器完成了和leader服务器的状态同步,整个服务框架进入消息广播模式。当同样遵循ZAB协议的服务器加入集群时,如果集群存在leader负责进行消息广播,新加入的服务器自觉地进入数据恢复模式。
4、服务器角色
Leader:整个ZooKeeper集群工作机制中的核心,其主要工作有两个:第一,事务请求的唯一调度和处理者,保证集群事务处理的顺序性。第二,集群内部各个服务器的调度者。
Follower: ZooKeeper集群状态的跟随者,其主要工作有以下三个:第一,处理客户端非事务请求(如:查询),转发事务请求给Leader服务器。第二,参与事务请求建议(Proposal)的投票。第三,参与Leader选举投票。
Observer:扩展Zookeeper集群的性能,提高读取的吞吐量,其工作原理和Follower基本是一致的,区别在于Observer不参与任何形式的投票,且Observer不会将事务持久化到磁盘。
三、技术实现
1、选主机制
Zookeeper选主机制——FastLeaderElection算法
1) 全新集群的选主,没有任何其他数据,根据Zookeeper节点ID
2) 非全新集群的选主,集群有数据
(1) 逻辑时钟:就是发起选主的时候投票的轮数,从0开始记录,逻辑时钟最大的代表最近一次投票,小的直接忽略
(2) version——数据版本,数据版本越高证明数据越新
(3) serverid——ID
优先级:逻辑时钟>数据版本>serverid
一旦选主成功,所有的follower都要向leader注册,获取最新数据版本
(1)leader通过follower的心跳机制,等待follower数据更新请求;
(2)follower数据更新请求发给leader,leader记录当前follower的zxid获取follower需要同步的数据版本并发送给follower;
(3)follower开始进行数据同步,过程中不对外提供服务,同步完成后恢复服务。
2、ZooKeeper的设计特点
(1)最终一致性:所有的写操作只能leader进行,followe负责转发请求。写过程不是强一致性,只要半数以上节点写成功,leader就认为写成功,只是后面的请求处于阻塞状态,不对外提供服务。
(2)顺序一致性:请求和执行具有严格的顺序。
(3)原子性:要么成功,要么失败。
(4)单一视图:无论客户端连接的是哪个ZooKeeper服务器,其看到的服务端数据模型都是一致的。
(5)可靠性:一个事务所引起的状态改变,在下一个变更事务到来之前一直保留。
(6)实时性:保证在一定的时间段内,客户端最终一定能够从服务端读取到最新的数据状态。
3、核心架构
1、文件系统
Zookeeper的文件系统类似与linux根节点/,但寻址只能通过绝对路径,不能通过相对路径。同时linux路径下可能是文件,可能是目录,Zookeeper不存在文件,也不存在目录,而是具备目录和文件功能的Znode。
Znode按有无编号分为:顺序节点和非顺序节点
创建无编号节点:create path data
创建有编号节点:create –s path data
注意:编号有父节点维护,同一父节点维护的编号顺序增加,不管节点有无编号,都会顺序增加。
Znode按有无编号分为:临时节点和持久节点
创建持久节点:create path data
创建临时节点:create –e path data
注意:临时节点是在会话(客户端)结束后,自动删除;临时节点不能有子节点。
2、监听机制
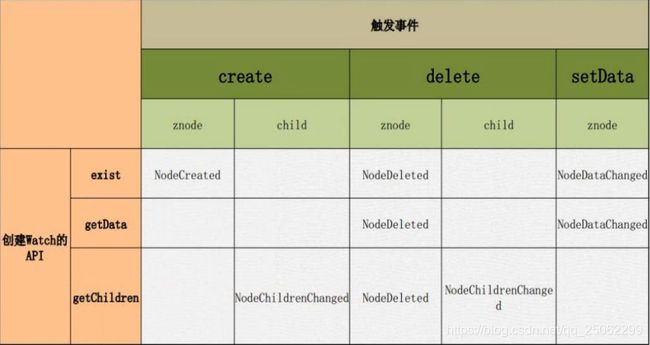
Zookeeper的监听对象是znode,通过监听机制,监听文件系统的数据内容和文件结构变化。监听事件分为:nodedatachanged(节点数据改变)、nodecreate(节点创建事件)、nodedelete(节点删除)、nodechildrenchanged(子节点变化事件)。
注意:监听添加一次,只生效一次
四、典型应用场景
1、 统一命名服务
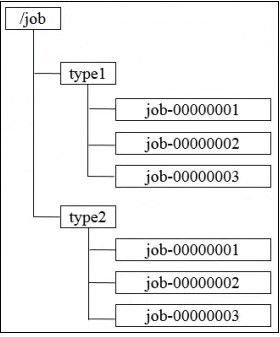
需求:在分布式环境下,经常需要对应用/服务进行统一命名,便于识别不同服务,如以下两种:
a)类似于域名与ip之间对应关系,ip不容易记住,而域名容易记住。
b)通过名称来获取资源,服务的地址或提供者等信息。
实现:按照层次结构组织服务/应用名称。
a)可将服务名称以及地址信息写到ZooKeeper上,客户端通过ZooKeeper获取可用服务列表类。
2、 配置文件管理

需求:分布式环境下,配置文件管理和同步。
a)一个集群中,所有节点的配置信息是一致的,比如 Hadoop 集群。
b)对配置文件修改后,希望能够快速同步到各个节点上。
实现:配置管理交由ZooKeeper。
a)配置文件当作znode的节点,配置文件的内容作为znode的数据。
b)各个节点监听这个Znode。
c)一旦Znode中的数据被修改,ZooKeeper将通知各个节点。
3、集群管理
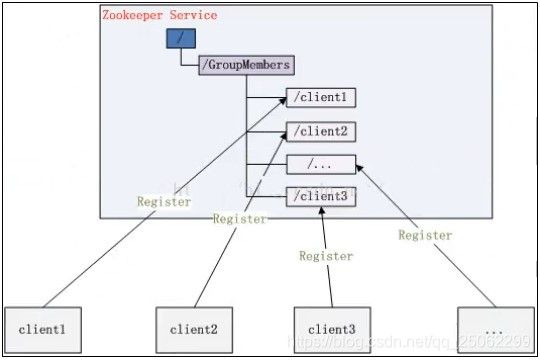
需求:分布式环境中,动态感知每个节点的状态,上下线信息。
a)可根据节点实时状态做出一些调整,如:HBase中Master状态监控与选举。
实现:可交由ZooKeeper实现。
a)可将节点信息写入ZooKeeper上的一个Znode。
b)监听这个Znode可获取它的实时状态变化。
4、分布式队列
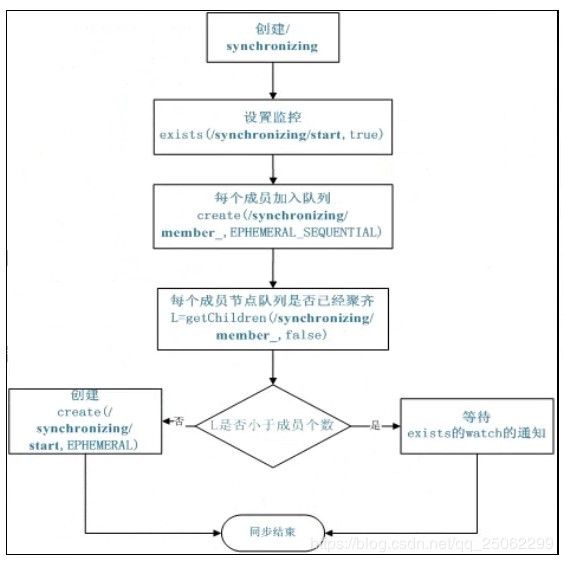
需求:同步队列,所有到齐后执行;FIFO方式入队出队,类似于时序锁。
实现:可交付Zookeeper实现
a)一个job由多个task组成,只有所有任务完成后,job才运行完成。
b)可为job创建一个/job目录,然后在该目录下,为每个完成的task创建一个临时的Znode,一旦临时节点数目达到task总数,则表明job运行完成。
5、分布式锁
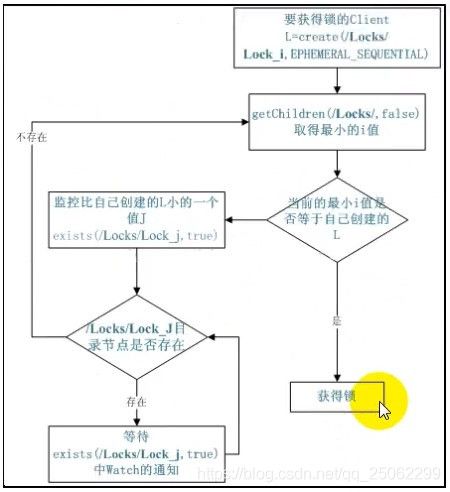
需求:处于不同节点上不同的服务,它们可能需要顺序的访问一些资源,这里需要一把分布式的锁。
实现:可交付Zookeeper实现读锁、写锁、时序锁
a)读锁,属于共享锁,锁作为一个有编号的临时节点,可以被不停的创建,读取结束后,自动删除。
b)写锁,属于排他锁,无编号的临时节点,不能被一直创建。只有创建Znode成功的那个客户端才能得到锁,其它客户端等待。当前客户端用完这个锁后,会删除这个Znode,其它客户端再尝试创建Znode,获取分布式锁。
c)时序锁,先后顺序的锁,有编号的节点。各个客户端在某个Znode下创建临时Znode,这个类型必须为CreateMode.EPHEMERAL_SEQUENTIAL,这样该Znode可掌握全局访问时序。
6、分布式通知与协调
需求:分布式环境中,经常存在一个服务需要知道它所管理的子服务的状态。
a)NameNode需知道各个Datanode的状态。
b)JobTracker需知道各个TaskTracker的状态。
实现:可交付Zookeeper实现心跳检测机制、消息推送
a)在Znode设置监听,当数据发生改变,推送信息,相当于一个发布/订阅系统。