30天搞定spark源码系列-RDD番外篇-shuffledRDD
阅读这篇文章,你应该能得到这样几个问题的答案:
- 什么是spark的shuffle?
- 典型的shuffle类算子
- spark shuffle在实战中的优化方向
- shuffledRDD的基本流程和代码框架是什么
1、spark shuffle
相信对于使用过spark的童鞋来说,不管是spark sql或者spark core,除了写业务逻辑之外如果你涉及到spark调优的话,就必须深入了解spark的shuffle原理了。。。
要害怕,让我们拿好我们解牛刀,一步一步的剖析一下
1.1、定义
先翻译一下shuffle的中文意思,shuffle直译为清洗,混洗的意思,不过spark的设计人员有点搞事!在spark体系或者hadoop体系里面,都把shuffle作为数据规整的意思,简单理解就是做了一个分组聚合。。。
还不好理解?再举个简单例子:啪,一箩筐的豆类(包括红豆,绿豆,黄豆)撒到了地上,妈妈让你和姐姐、哥哥在5分钟内把地上的豆子捡起来并按照颜色分类放到不同的簸箕中。你们商量了一下,一人负责一种颜色,这样可以快速完成任务,于是,你瞪着你的大眼睛只专注于地上的红豆,并一粒一粒捡起来放在你手上的簸箕中,相同的,你的哥哥姐姐也在做同样的事情,很快就完成了任务并获得了妈妈的雪糕奖励~~~~
==========================================================================
好了,你已经在脑海中在现实世界中找到了spark的设计源泉,接下来我们就专业一点进行shuffle的定义的解释
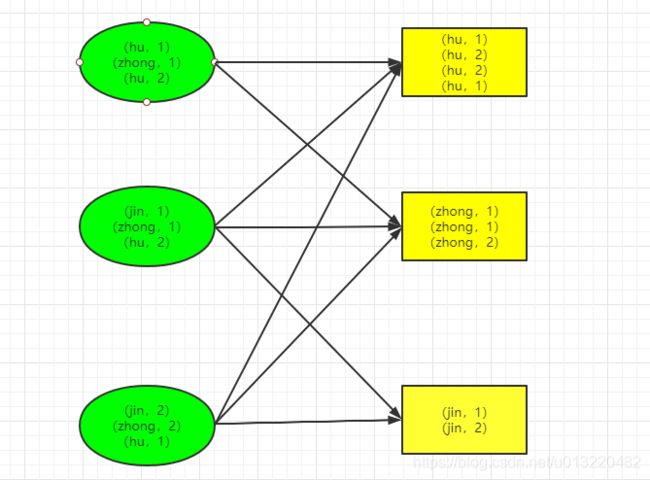
如上图所示,这是一个典型的GroupByKey算子,需要统计出每个单词出现的次数,一共有3个节点,每个节点从其他节点拉取key相同的数据到本地节点并进行汇总;
既然到这里了,结合上面的图示,就顺便也说明一下spark在实际项目中非常有用的优化方法----shuffle优化
我们刚才说了,上面的图示其实是一个groupByKey的算子,我们结合实际情况想一下,对于每个需要进行聚合的节点,需要不断的去其他的节点上把数据一个一个的拉取的本地再进行计算,类比举得捡豆子的事情,假设你身高1米8,你端着你的簸箕每次弯腰到地上挑选你想要的豆子,这样时间长了,你的腰也会疼起来,你的整个运作的效率也会相应的下降。。。 这就是spark优化中的一个原则:尽量减少spark对于数据层面的传输。
这里引入reduceByKey的算子,就是一个比较高效的方法
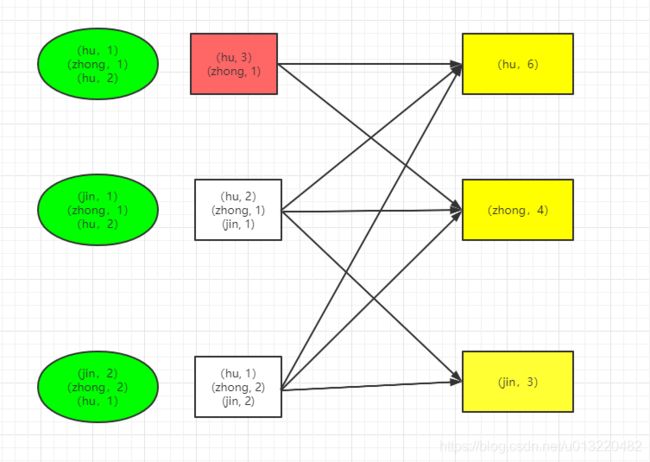
发现了什么?图中红色框里面相同key的数据被先做了一个计算合并,相比于之前节点的元素,元素个数减少了1个,那就说明在输出传输的过程中,就会少传输一个数据,这样性能也会提高了。
结论:在spark实际开发中,尽量使用map-side的shuffle算子,这里使用reduceByKey效果就比groupByKey的效果好;
如果了解shuffle原理的话,看到这里就可以跪安了,如果您想有更大的发展,不需要996,继续看下面的源码,帮助你更进一步;
2、shuffledRDDPartition
2.1 为什么先说这个?
仔细分析spark RDD的子类可以发现,shuffledRDDPartition是基石,也正好符合我们这篇文章的主题;
2.1 望
先对整个这个类的形态做个大致了解:

整个类文件中包含两个类:
- ShuffledRDDPartition,内部类
- ShuffledRDD,公共类
其中ShuffledRDDPartition比较简单,只接受一个参数->该rdd在父RDD中的partition分区索引;他继承Partition类:

2.2 闻
了解了大致的结构后,就需要更加深入的了解内部构成和外部表现,我们展开ShuffledRDD类:
主要实现了一下的函数:
- setSerializer
- setKeyOrdering
- setAggregator
- setMapSideCombine
其他的都是重写了RDD类的方法,完成功能;

仅仅指定rdd在shuffle过程中的序列化方式,常用的不就是默认的java序列化和kylo两种嘛,不指定的使用spark.serializer参数指定的序列化方式,一般我们都会使用这个参数进行全局范围内指定;

指定rdd key的排序方式

指定合并的方式

指定是否需要在map端进行预聚合
2.3、问
那么shuffledRDD这个类继承了RDD类,除了上面的自己特有的外貌外,到底怎么样实现了自己的功能呢?

获取rdd的依赖关系:
先确定序列化的方式—>判断是否需要在map端聚合->获取对应的k-v的序列化的方式—>返回rdd的shuffle依赖
这里对于每个rdd根据上下文的定义了一个全局自增的shuffleID,同时对于每个task返回一个shuffle的句柄用于操作。

其他的这几个函数和RDD父类的东西差别不大,这里就不详细说明了;
总结一下:
spark在shuffle的时候,按照以下的顺序进行:
- 获取数据序列化的方式
- 判断需不需要在map端进行预聚合
- 如果需要预聚合,生成key和聚合后的value类型的序列化器
- 如果不需要预聚合,生成key和原始value类型的序列化器
- 获取shuffle前父rdd的partition的个数以及数据存储的位置
- 进行reduce计算:更加生成的shuffle句柄和partition的位置,进行合并或者其他的计算
- 清理依赖关系