neon memory copy
neon memory copy
1、问题的提出背景
为什么要用neon memory copy?
在用zynq做视频处理的时候会遇到一个关键的技术瓶颈,虽然我们知道zynq用FPGA硬件可以加速算法,而且速度是比传统的软件实现快几十甚至几百倍,具体的要看优化并行率。但是由于zynq异构平台对fpga和arm的数据交互支持不是特别的流畅,至少是不能做到特别实时。为什么呢?因为不管FPGA算法加速有多块,在你加速算法之前最重要的是数据流。一般我们用官方的方案就是走AXI_HP到VDMA-->算法IP--->VDMA回到AXI_HP,如下图1,用的AXI_STREAM。
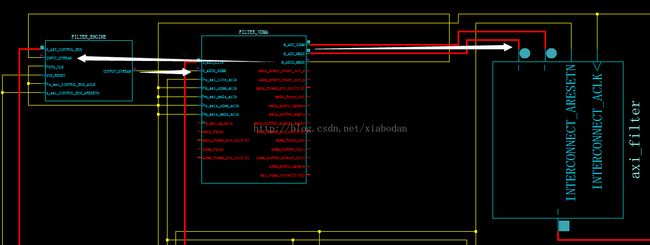
图1 视频数据流
然后我们会在LINUX中移植VDMA驱动,将LINUX采集的视频流通过VDMA送入FPGA中的算法IP,处理之后会将数据放在VDMA RAM中,我们只需要去读取处理好的视频流就OK。但问题就出在这里。拷贝视频到LINUX RAM中和从DMA RAM中读取视频恰恰是技术瓶颈。用传统的数据拷贝,也就是将视频帧中的像素一个一个拷贝到RAM中。下表中是用此方法整个系统实验的时间分配表1。720P视频
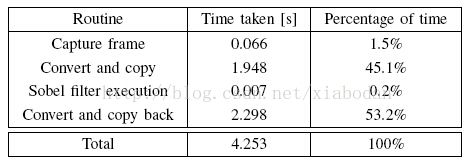
表1 系统时间实验数据
从上表中可以看出处理一帧数据用了4.253s,其中算法处理时间只用了0.007s,而格式变换和数据拷贝(包括进出)占用了98%的时间。所以我们认为视频的处理算法不是瓶颈,而是视频的输入输出瓶颈。所以我们要采用一种高效的方案去解决这个问题。
解决方案一
那为什么不用memcpy()呢?由于在LINUX中视频采集用Opencv,得到的视频用的MAT类,想要直接内存拷贝是不行的,要用memcpy之前就必须将MAT中的视频数据手动转换为虚拟的内存快。如下代码,但是两层的for循环时间是消耗非常多的。很明显效果不明显
uint8_t *rgb_px = rgb_in;
uint8_t *rgb_out_px = rgb_out;
//uint8_t *frame_px = frame.data;
// convert OpenCV BGR for RGB (32 bit aligned)
tmr_hw_conv = clock();
for (int i=0; i(i, j)[2];
rgb_px[1] = frame.at(i, j)[1];
rgb_px[2] = frame.at(i, j)[0];
rgb_px += 4;
//frame_px += 3;
}
}
unsigned char* virtual_addr_out;
virtual_addr_out = (unsigned char*)mmap(NULL, map_len, PROT_READ | PROT_WRITE, MAP_SHARED, fd, (off_t)in_buffer);
if(virtual_addr_out == MAP_FAILED)
{
perror("virtual_addr_in mapping for absolute memory access failed.\n");
return;
}
memcpy(img, virtual_addr_out, FRAME_HEIGHT*FRAME_WIDTH*4); 解决方案二
采用V4L2采集,OPENCV的cvMixChannels()混合通道的方法,完成数据的拷贝与格式转换。(OPENCV只能采集视频为BGR24,而V4L2能够采集RGB24,GBR24,MJPEG,YUV...).实验代码如下:
unsigned char* virtual_addr_in;
virtual_addr_in = (unsigned char*)mmap(NULL, map_len, PROT_READ | PROT_WRITE, MAP_SHARED, fd, (off_t)in_buffer);
if(virtual_addr_in == MAP_FAILED)
{
perror("virtual_addr_in mapping for absolute memory access failed.\n");
return;
}
CvMat* rgb32 = cvCreateMatHeader(img->rows, img->cols, CV_8UC4);
cvSetData(rgb32, virtual_addr_in, img->cols * 4);
CvMat* ch4 = cvCreateMat(img->rows, img->cols, CV_8UC1);
CvArr* in[] = { img, ch4 };
int from_to[] = { 0,0, 1,1, 2,2, 3,3 };
cvMixChannels((const CvArr**)in, 2, (CvArr**)&rgb32, 1, from_to, 4);
munmap((void *)virtual_addr_in, map_len);
解决方案三
NEON format conversion written directly to DMA RAM. Use the convert function from item 5 and write the result directly to DMA RAM. Only use the NEON copy to copy back from DMA RAM(用MEON进行模式转换,再用NEON copy直接写入到DMA RAM中。只有NEON 从DMARAM中拷贝出处理完的数据)
具体的编程方法 见ARM的官方手册 http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.faqs/ka13544.html
以下是将cvMat *img 中的数据转换为RGB32同时拷贝进入DMA RAM中
CvMat* rgb = cvCreateMatHeader(fmt.fmt.pix.height, fmt.fmt.pix.width, CV_8UC3);
函数调用情况 neonRGBtoRGBA_gas(rgb->data.ptr, virtual_addr_in, FRAME_WIDTH * FRAME_HEIGHT);
void __attribute__ ((noinline)) neonRGBtoRGBA_gas(unsigned char* src, unsigned char* dst, int numPix)
{
asm(
// numpix/8
" mov r2, r2, lsr #3\n" // numpix/8 逻辑左移三位再赋值,为什么要除以8下面会详解
// load alpha channel value
" vmov.u8 d3, #0xff\n" //额外增加的CvMat的第四通道alpha通道,这是在HLS中AXI转化为MAT结构,见图3
"loop1:\n" //循环开始
// load 8 rgb pixels with deinterleave //见图2,及分析
" vld3.8 {d0,d1,d2}, [r0]!\n"
// preload next values //预取在下一次循环中要用到的数据
" pld [r0,#40]\n"
" pld [r0,#48]\n"
" pld [r0,#56]\n"
// substract loop counter
" subs r2, r2, #1\n" //一次循环操作就可以取走24个8位单通道像素,也就是8个R,R个G,8个B,循环次数row*col/8
//" vswp d0, d2\n"
// store as 4*8bit values
" vst4.8 {d0-d3}, [r1]!\n" //将VLD的三通道数据D0-D2连同增加的alpha通道一同写入到目的地址r1(dst)中
// loop if not ready
" bgt loop1\n" //循环跳转判断
);
}
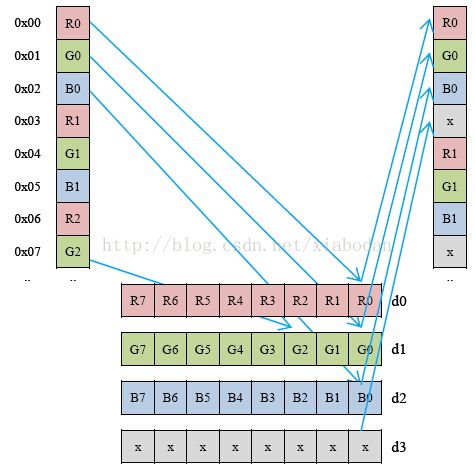
图2 VLD 指令拷贝流程图
VLDn (multiple n-element structures) 向量加载指令
Vector Load multiple n-element structures. It loads multiple n-element structures from memory into one or more NEON registers, with de-interleaving (unless n == 1). Every element of each register is loaded.
VLDn{cond}.datatypelist, [Rn{@align}]{!}
VLDn{cond}.datatypelist, [Rn{@align}],Rm
在 NEON 中,查看扩展寄存器组时可以将其视为:
-
十六个 128 位四字寄存器
Q0-Q15。 -
三十二个 64 位双字寄存器
D0-D31。 -
上述视图中的寄存器组合。
vld3.8 {d0,d1,d2}, [r0]!\n 也就是一次性将datatype 为8位的拷贝进入neon寄存器Dn中,如图2,这里拷贝到D0-D2三个寄存器中。由于Dn寄存器是64的,那么一个Dn可以装下8个uchar的数据,RGB三个通道总共一次就可以装载24个8位进入D1-D3寄存器。装的过程是这样的:由于CvMat结构中的数据指针是线性的,那么我们如果要增加一个alpha通道就必须重新拆分数据块,然后增加通道重新写入数据块,这个模式转换我们可以采用全手动copy或者OPENCV的cvMixChannels(),但是速度都比较慢,只有采用NEON指令,在VLD之后,添加一个通道,然后通过 vst4.8 {d0-d3}, [r1]!\n,其中d3寄存器为 vmov.u8 d3, #0xff\n ,d1-d2是vld3.8的数据。这就是为什么第一句汇编要将跳转比较寄存器右移3位(除以8)。

以下是从NEON中拷贝数据出来
void __attribute__ ((noinline)) neonMemCopy_gas(unsigned char* src, unsigned char* dst, int num_bytes)
{
// source http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.faqs/ka13544.html
asm(
"neoncopypld:\n"
" pld [r0, #0xC0]\n" //预取数据
" vldm r0!,{d0-d7}\n" //从参数一r0(src)加载8*8=64个单通道8位数据
" vstm r1!,{d0-d7}\n" //存储在目的地址r1(dst)中,同样是64个8位单通道8位数据
" subs r2,r2,#0x40\n" //循环跳转参数,每次减64,总共循环次数=row*col*4/64
" bge neoncopypld\n"
);
}通过NEON拷贝数据也是和上面一样,只不过不需要RGB24->RGB32,直接一次性拷贝出来
实验结果
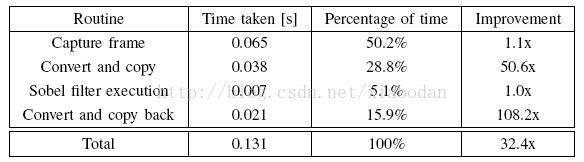
表二 NEON加速后的结果
从表中可以得出算法处理时间没有变化,但是拷贝时间大大降低。帧率达到7帧。
分析NEON
参考
REFERENCES
[1] H. Yabuta, K.; Kitazawa, “Optimum camera placement considering camera specification for security monitoring,” IEEE International Symposium on Circuits and Systems, pp. 2114 – 2117, 2008.
[2] C. Hughes, “Wide-angle camera technology for automotive applications:a review,” Intelligent Transport Systems, IET, vol. 1, no. 1, pp. 19 – 31,2009.
[3] Zedboard.org. (2013, September) Zedboard.org. [Online]. Available:http://www.zedboard.org/
[4] S. Fernando. (2012, December) Sobel filter application on the xilinx zynq
zedboard. Eindhoven University of Technology. [Online]. Available: http://shakithweblog.blogspot.nl/2012/12/getting-sobel-filter-application.html
[5] OpenCV.org. Opencv (open source computer vision). [Online]. Available:http://opencv.org/
[6] L.-P. Clausen. Linux with hdmi video output on the zed and zc702 boards. Analog Devices. [Online]. Available:http://wiki.analog.com/resources/tools-software/linux-drivers/platforms/zynq
[7] Logitech. Logitech hd webcam c270. Logitech. [Online]. Available:http://www.logitech.com/en-us/product/hd-webcam-c270
ARM NEON 指令:http://blog.csdn.net/tonyfield2015/article/details/8597549点击打开链接
ARM和NEON指令:http://blog.csdn.net/chshplp_liaoping/article/details/12752749
http://community.arm.com/groups/processors/blog/2012/03/13/coding-for-neon--part-5-rearranging-vectors
http://community.arm.com/groups/processors/blog/2010/03/17/coding-for-neon--part-1-load-and-stores
http://community.arm.com/groups/processors/blog/2010/09/01/coding-for-neon--part-4-shifting-left-and-right
GCC arm NEON指令:https://gcc.gnu.org/onlinedocs/gcc/ARM-NEON-Intrinsics.html
http://infocenter.arm.com/help/basic/help.jsp?topic=/com.arm.doc.dui0204ic/CJAJIIGG.html
ARM中C和汇编混合编程及示例 :http://blog.csdn.net/rockyqiu2002/article/details/100158