tf.nn,tf.layers, tf.contrib模块介绍
一、tf.nn,tf.layers, tf.contrib概述
我们在使用tensorflow时,会发现tf.nn,tf.layers, tf.contrib模块有很多功能是重复的,尤其是卷积操作,在使用的时候,我们可以根据需要现在不同的模块。但有些时候可以一起混用。
下面是对三个模块的简述:
(1)tf.nn:提供神经网络相关操作的支持,包括卷积操作(conv)、池化操作(pooling)、归一化、loss、分类操作、embedding、RNN、Evaluation。
(2)tf.layers:主要提供的高层的神经网络,主要和卷积相关的,个人感觉是对tf.nn的进一步封装,tf.nn会更底层一些。
(3)tf.contrib:tf.contrib.layers提供够将计算图中的 网络层、正则化、摘要操作、是构建计算图的高级操作,但是tf.contrib包含不稳定和实验代码,有可能以后API会改变。
1) 如果只是想快速了解一下大概,不建议使用tf.nn.conv2d类似的函数,可以使用tf.layers和tf.contrib.layers高级函数
2) 当有了一定的基础后,如果想在该领域进行深入学习,建议使用tf.nn.conv2d搭建神经网络,此时会帮助你深入理解网络中参数的具体功能与作用,而且对于loss函数需要进行正则化的时候很便于修改。
且能很清晰地知道修改的地方。而如果采用tf.layers和tf.contrib.layers高级函数,由于函数内部有正则项,此时,不利于深入理解。而且如果编写者想自定义loss,此时比较困难,如如果读者想共享参数时,此时计算loss函数中的正则项时,应该只计算一次,如果采用高级函数可能不清楚到底如何计算的。
二、在神经网络构建中几个模块的函数对比
| 功能 | tf.nn | tf.layers | tf.contrib | 功能介绍 |
| 卷积运算(conv) | conv2d(...) | conv2d(...) | layers.convolution2d | 2D卷积层的功能界面 |
| 池化(pooling) | avg_pool(...) max_pool(...) |
average_pooling2d(...) max_pooling2d(...) |
layers.avg_pool2d layers.max_pool2d |
2D输入的平均和最大池层(例如图像) |
| 全连接(dense) | dense(...) | layers.fully_connection |
密集连接层的功能接口 | |
| 退出率 | dropout(...) | dropout(...) | 有助于防止过度拟合 | |
| 展平 | flatten(...) | layers.flatten | 在保留axis (axis 0)的同时平移输入张量 | |
| 批量标准化(BN) | batch_normalization(...) | BN通过一定的规范化手段,把每层神经网络任意神经元输入值的分布强行拉回到均值为0方差为1的标准正态分布 | ||
| 本地响应规范化(LRN) | local_response_normalization(...) | 局部响应归一化就是借鉴侧抑制的思想来实现局部抑制 |
1、卷积运算(conv)
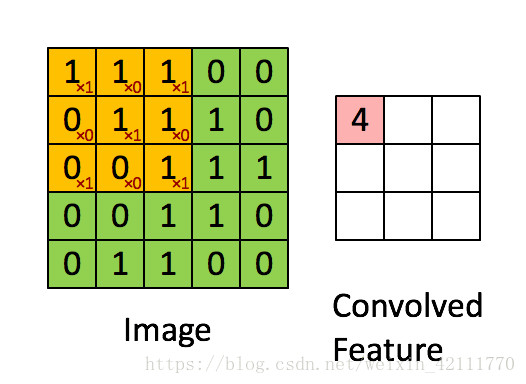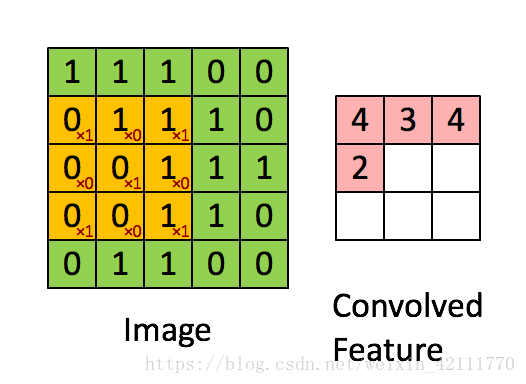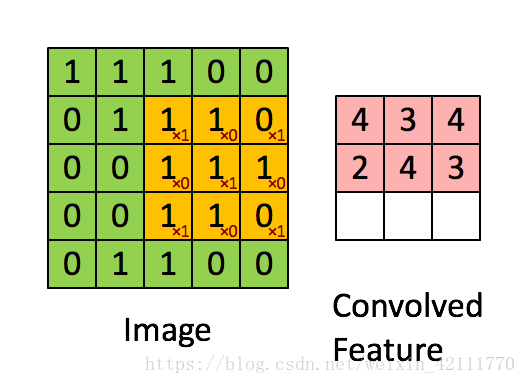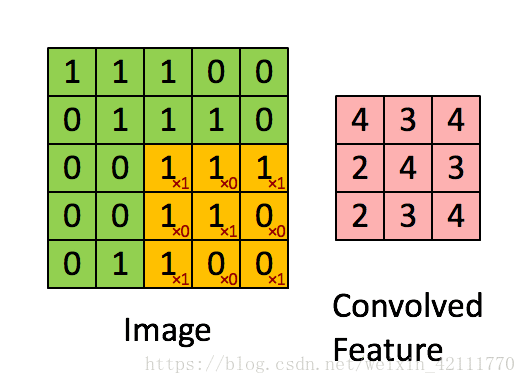
(1)tf.nn.conv2d函数
tf.nn.conv2d(
input,
filter,
strides,
padding,
use_cudnn_on_gpu=True,
data_format='NHWC',
dilations=[1, 1, 1, 1],
name=None
)函数作用:对输入数据进行二维卷积操作
参数说明:
- input:输入,A 4-D tensor,shape为[batch_size, input_height, input_width, input_channels],数据类型必须为float32或者float64
- filter: 卷积核,A 4-D tensor,shape为[filter_height, filter_width, input_channels, output_channels], 和input有相同的数据类型
- strides: 步长,一个长度为4的一维列表,每一位对应input中每一位对应的移动步长,在使用中,由于input的第一维和第四维不参与卷积运算,所以strides一般为[1, X, X, 1]
- padding: 填充方式,一个字符串,取值‘SAME’或者‘VALID’. 当padding = ‘SAME’时,tensorflow会自动对原图像进行补零操作,从而使得输入和输出的图像大小一致;当padding = ‘VALID’时, 采用不填充的方式,会根据计算公式缩小原图像的大小,计算公式为(W-F+2P)/S+1, W是图像大小,F为卷积核大小,P是填充数量,S是步长。
- use_cudnn_on_gpu=None : 可选布尔值,默认为True
- data_format:一个字符串,表示输入中维度的顺序.支持channels_last(默认)和channels_first;channels_last对应于具有形状(batch, height, width, channels)的输入,而channels_first对应于具有形状(batch, channels, height, width)的输入.
- name:字符串,图层的名称.
返回:
输出张量。
(2)tf.layers.conv2d
conv2d(inputs, filters, kernel_size,
strides=(1, 1),
padding='valid',
data_format='channels_last',
dilation_rate=(1, 1),
activation=None,
use_bias=True,
kernel_initializer=None,
bias_initializer=,
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
trainable=True,
name=None,
reuse=None)
函数作用:
2D卷积层(例如,图像上的空间卷积)。
该层创建卷积内核,该卷积内核与层输入卷积混合(实际上是交叉关联)以产生输出张量.如果use_bias为True(并且提供了bias_initializer ),则创建偏置向量并将其添加到输出。最后,如果activation不是None,它也会应用于输出。
参数说明:
- input:Tensor 输入
- filters:整数,输出空间的维数(即卷积中的滤波器数).
- kernel_size:2个整数的整数或元组/列表,指定2D卷积窗口的高度和宽度.可以是单个整数,以指定所有空间维度的相同值.
- strides:一个整数,或者包含了两个整数的元组/队列,表示卷积的纵向和横向的步长。如果是一个整数,则横纵步长相等。另外,
strides不等于1 和dilation_rate不等于1 这两种情况不能同时存在。 - padding:可以是"valid"或"same"(不区分大小写).
"valid"表示不够卷积核大小的块就丢弃,"same"表示不够卷积核大小的块就补0。 - data_format:一个字符串,可以是channels_last(默认)或channels_first,表示输入中维度的顺序,channels_last对应于具有形状(batch, height, width, channels)的输入,而channels_first对应于具有形状(batch, channels, height, width)的输入。
- dilation_rate:一个整数,或者包含了两个整数的元组/队列,表示使用扩张卷积时的扩张率。如果是一个整数,则所有方向的扩张率相等。另外,
strides不等于1 和dilation_rate不等于1 这两种情况不能同时存在。 - activation:激活功能,将其设置为“None”以保持线性激活.
- use_bias:Boolean,该层是否使用偏差.
- kernel_initializer:卷积内核的初始化程序.
- bias_initializer:偏置向量的初始化器,如果为None,将使用默认初始值设定项.
- kernel_regularizer:卷积内核的可选正则化器.
- bias_regularizer:偏置矢量的可选正则化器.
- activity_regularizer:输出的可选正则化函数。
- kernel_constraint:映射函数,当核被
Optimizer更新后应用到核上。Optimizer用来实现对权重矩阵的范数约束或者值约束。映射函数必须将未被影射的变量作为输入,且一定输出映射后的变量(有相同的大小)。做异步的分布式训练时,使用约束可能是不安全的。 - bias_constraint:由Optimizer更新后应用于偏差的可选投影函数.
- trainable:Boolean,如果为True,还将变量添加到图集合GraphKeys.TRAINABLE_VARIABLES中(请参阅参考资料tf.Variable).
- name:字符串,图层的名称.
返回:
输出张量。
2、池化(pooling)
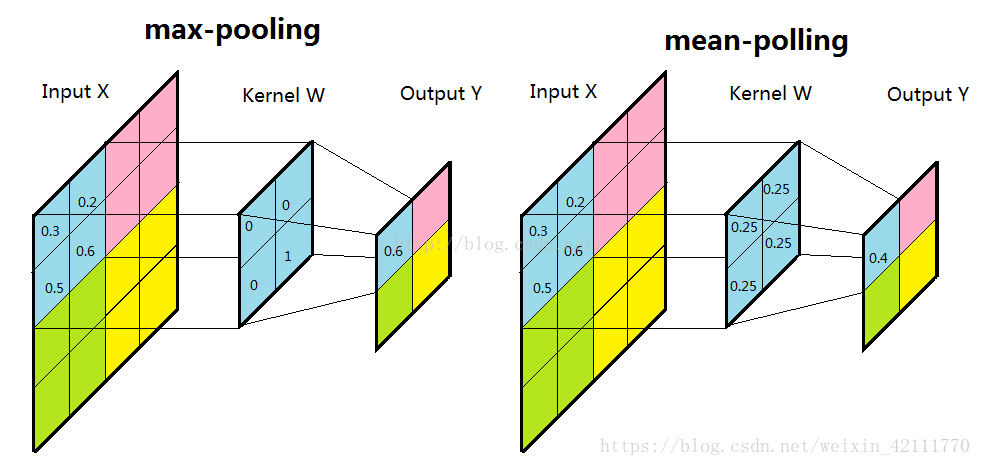
池化:池化层的主要目的是通过降采样的方式,在不影响图像质量的情况下,压缩图片,减少参数。子采样有两种形式,一种是均值子采样,即是对一个区域里的元素求平均值;另一种就是最大值采样,即是在一个区域中寻找最大值,如下图所示。
(1)tf.nn.avg_pool和tf.nn.max_pool
# 平均池化
tf.nn.avg_pool(value, ksize, strides, padding, data_format='NHWC', name=None)
# 最大化池化
tf.nn.max_pool(value, ksize, strides, padding, data_format='NHWC', name=None)
函数作用:
对输入进行池化操作
参数说明:
- value:池化输入,A 4-D tensor,shape为[batch_size, input_height, input_width, input_channels],数据类型为float32,float64,qint8,quint8,qint32
- ksize:池化窗口大小,A 4-D tensor,一般为[1, X, X, 1],输入张量的每个维度的窗口大小
- strides:步长,一般为[1, X, X, 1],输入张量的每个维度的滑动窗口的步幅.
- padding:填充,一个字符串取值‘SAME’或者‘VALID’,同上述卷积运算的padding,填充算法。
- data_format:一个字符串.支持'NHWC','NCHW'和'NCHW_VECT_C'。
- name:字符串,图层的名称.
返回:
由data_format指定格式的Tensor,池化输出张量。
(2)tf.layers.max_pooling2d和tf.layers.average_pooling2d
#最大池化
tf.layers.max_pooling2d(inputs,pool_size,strides,padding='valid',data_format='channels_last',name=None)
#平均池化
tf.layers.average_pooling2d(inputs,pool_size,strides,padding='valid',data_format='channels_last',name=None)函数作用:
用于2D输入的池化层(例如图像)。
参数:
- inputs: 进行池化的数据。
- pool_size: 池化的核大小(pool_height, pool_width),如[3,3]. 如果长宽相等,也可以直接设置为一个数,如pool_size=3.
- strides: 池化的滑动步长。可以设置为[1,1]这样的两个整数. 也可以直接设置为一个数,如strides=2
- padding: 边缘填充,’same’ 和’valid‘选其一。默认为valid
- data_format: 输入数据格式,默认为channels_last ,即 (batch, height, width, channels),也可以设置为channels_first 对应 (batch, channels, height, width).
- name: 层的名字。
返回:
输出张量。
3、全链接层(dense)
(1)tf.layers.dense
dense(
inputs,
units,
activation=None,
use_bias=True,
kernel_initializer=None,
bias_initializer=tf.zeros_initializer(),
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
trainable=True,
name=None,
reuse=None
)参数:
- inputs: 输入数据,2维tensor.
- units:整数或长整数,输出空间的维数.
- activation:激活函数(可调用),将其设置为“None”以保持线性激活.
- use_bias:Boolean,表示该层是否使用偏差.
- kernel_initializer:权重矩阵的初始化函数;如果为None(默认),则使用tf.get_variable使用的默认初始化程序初始化权重.
- bias_initializer:偏置的初始化函数,默认初始化为0
- kernel_regularizer:权重矩阵的正则化函数.
- bias_regularizer:正规函数的偏差.
- activity_regularizer:输出的正则化函数.
- kernel_constraint:由Optimizer更新后应用于内核的可选投影函数(例如,用于实现层权重的范数约束或值约束).该函数必须将未投影的变量作为输入,并且必须返回投影变量(必须具有相同的形状).在进行异步分布式训练时,使用约束是不安全的.
- bias_constraint:由Optimizer更新后应用于偏置的可选投影函数.
- trainable:Boolean,如果为True,还将变量添加到图集合GraphKeys.TRAINABLE_VARIABLES中(请参阅参考资料tf.Variable).
- name:String,图层的名称;具有相同名称的图层将共享权重,但为了避免错误,在这种情况下,我们需要reuse=True.
- reuse:Boolean,是否以同一名称重用前一层的权重.
该层实现了操作:outputs = activation(inputs * kernel + bias),其中activation是作为activation参数传递的激活函数(如果不是None),是由层创建的权重矩阵,kernel是由层创建的权重矩阵,并且bias是由层创建的偏差向量(只有use_bias为True时).
(2)tf.contrib.layers.fully_connection
tf.contrib.layers.fully_connection(F,num_output,activation_fn)这个函数就是全链接成层,F是输入,num_output是下一层单元的个数,activation_fn是激活函数
4、优化网络
(1)dropout
1)tf.nn.dropout
tf.nn.dropout( x, keep_prob, noise_shape=None, seed=None, name=None )该函数用于计算dropout.
使用概率keep_prob,输出按照1/keep_prob的比例放大输入元素,否则输出0.缩放是为了使预期的总和不变.
默认情况下,每个元素都是独立保留或删除的。如果已指定noise_shape,则必须将其广播为x的形状,并且只有具有noise_shape[i] == shape(x)[i]的维度才作出独立决定.
例如,如果shape(x) = [k, l, m, n]并且noise_shape = [k, 1, 1, n],则每个批处理和通道组件将独立保存,并且每个行和列将保留或不保留在一起.
参数:
- x:一个浮点型Tensor.
- keep_prob:一个标量Tensor,它与x具有相同类型.保留每个元素的概率.
- noise_shape:类型为int32的1维Tensor,表示随机产生的保持/丢弃标志的形状.
- seed:一个Python整数.用于创建随机种子.
- name:此操作的名称(可选).
返回:
该函数返回与x具有相同形状的Tensor.
2)tf.layers.dropout
tf.layers.dropout(inputs,rate=0.5,noise_shape=None,seed=None,training=False,name=None)
将Dropout(退出率)应用于输入.
Dropout包括在每次更新期间随机将输入单位的分数rate设置为0,这有助于防止过度拟合(overfitting).保留的单位按比例1 / (1 - rate)进行缩放,以便在训练时间和推理时间内它们的总和不变.
参数:
- inputs:必须,即输入数据。
- rate:可选,默认为 0.5,即 dropout rate,如设置为 0.1,则意味着会丢弃 10% 的神经元。
- noise_shape:可选,默认为 None,int32 类型的一维 Tensor,它代表了 dropout mask 的 shape,dropout mask 会与 inputs 相乘对 inputs 做转换,例如 inputs 的 shape 为 (batch_size, timesteps, features),但我们想要 droput mask 在所有 timesteps 都是相同的,我们可以设置 noise_shape=[batch_size, 1, features]。
- seed:可选,默认为 None,即产生随机熟的种子值。
- training:可选,默认为 False,布尔类型,即代表了是否标志位 training 模式。
- name:可选,默认为 None,dropout 层的名称。
返回: 经过 dropout 层之后的 Tensor。
对于这两个方法有一下几点区别:
- tf.nn.dropout 中参数 keep_prob :每一个元素被保存下的概率。而 tf.layer.dropout 中参数 rate :每一个元素丢弃的概率。所以,keep_prob = 1 - rate。
- 在 tf.layer.dropout 中有一个 training 参数:在training模式中,返回应用dropout后的输出;或者在非training模式下,正常返回输出(没有dropout)。这里说的training模式也即是training参数为True的时候。